盡管自然語言處理( NLP )的研究在過去兩年取得了重大進展,并取得了商業上的成功,但很少有人致力于將這種能力應用于其他重要語言,如印度教、阿拉伯語、葡萄牙語或西班牙語。顯然,用 6500 多種語言來滿足全人類的需求是一項挑戰。同時,僅支持 40 種語言就能滿足 60% 以上人口的自然語言規劃需求。
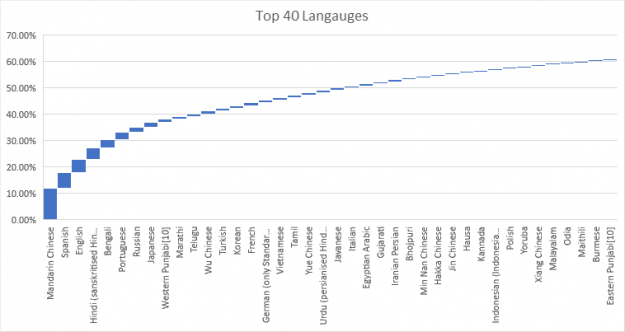
圖 2 顯示,即使在最常用的語言中,語言模型的性能也有很大的不同。請記住,這種比較并不完美,因為這些語言確實具有不同的語言熵。更重要的是,對最有能力的大規模語言模型的研究似乎僅限于少數高資源語言(公開提供大量文檔的語言),如英語或漢語。
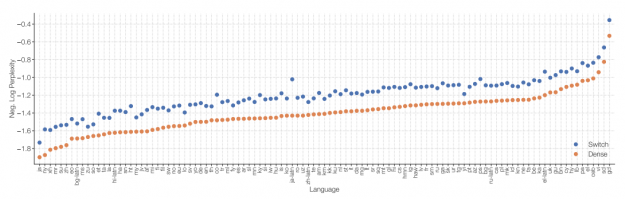
當您考慮特定于領域的語言(如醫學、技術或法律術語)時,情況就更加復雜了,除了英語之外,還存在一些高質量的模型。令人遺憾的是,這些領域特定的語言模型目前正在改變臨床醫生、工程師、研究人員或其他專家獲取信息的方式。
- 像 GaTortron 這樣的模型正在改變臨床醫生獲取醫療記錄的方式。
- 像 bioMegatron 這樣的模型改變了醫學研究人員識別影響人體的藥物或化學相互作用的方式。
- sci BERT 等模型改變了工程師發現科學信息并與之交互的方式。
不幸的是,英語以外的等效模型數量有限。幸運的是,跨其他語言復制英語語言模型的成功不再是一項研究任務,而主要是一項工程活動。它不再需要發明新的模型和訓練方法,而是需要系統和迭代的數據集工程、模型訓練及其持續驗證。
這并不意味著設計這些模型是微不足道的。由于現代自然語言處理中使用的模型和數據集的大小,訓練過程需要大量的計算能力。其次,要使用大型模型,必須收集大型文本數據集。第三,由于使用的模型大小相同,因此需要新的訓練和推理方法。
NVIDIA 不僅在構建大規模語言模型(從 10 億到 1750 億個參數)方面擁有豐富的經驗,而且在將它們部署到生產環境中也有豐富的經驗。這個職位的目標是分享我們關于項目組織、基礎設施需求和預算的知識,并支持這個領域的項目。
大型模型的誕生
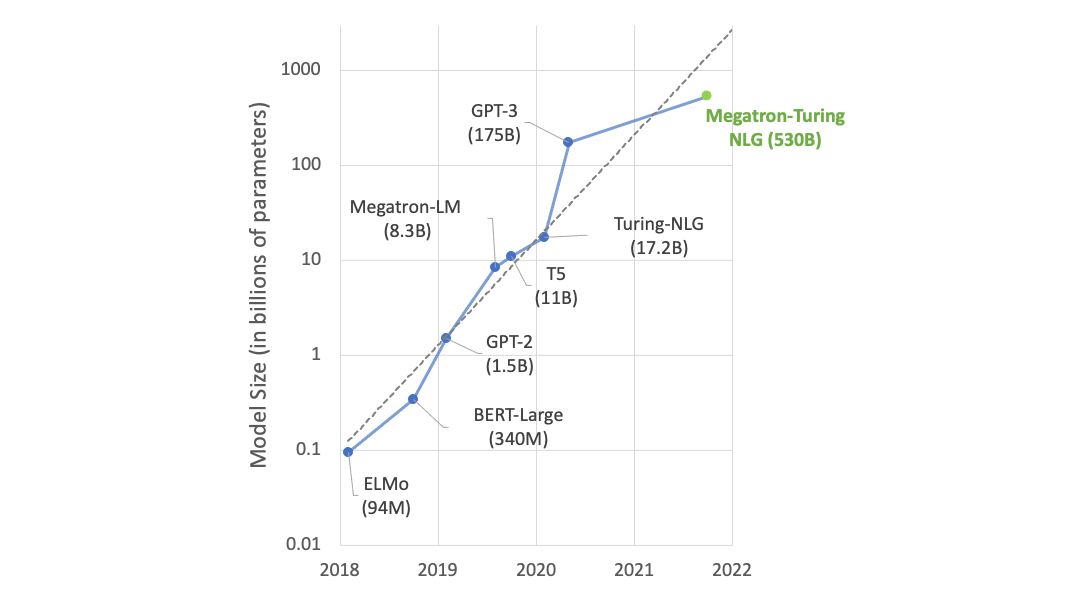
正如 從經驗上看,深度學習規模是可以預測的 中所假設的那樣, NLP 模型的性能在模型大小和用于訓練的數據量方面似乎都遵循冪律。隨著模型和數據集變大,性能也會不斷提高。 神經語言模型的標度律 中的下圖不僅說明了這種關系,而且更重要的是,它適用于九個數量級的計算。
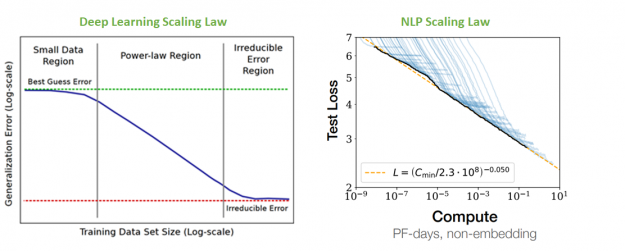
在 NLP 比例定律中,盡管最右邊的模型達到多達 1750 億個參數(大于 BERT 大的 500 倍以上),但這種關系沒有停止的跡象。這表明,更大的模型可能會有進一步的改進。事實上,當開關變壓器擴展到 1 . 6 萬億個參數(大約比 BERT 大 5000 倍)時,仍然顯示出前面提到的行為。
更重要的是,大型 NLP 模型似乎生成了更健壯的特性,能夠解決復雜的問題,即使沒有大規模的微調數據集。圖 4 顯示了三個數量級模型的這種能力。
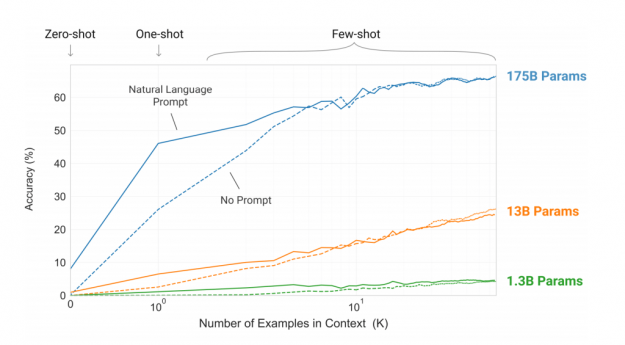
由于這一能力,盡管其開發成本相對較高,但大型 NLP 模型可能不僅繼續主導 NLP 處理領域,而且還會繼續增長,至少會再增長一個數量級,接近萬億個參數。
模型大小、數據集大小和模型性能之間的這種關系不是 NLP 獨有的。我看到了自動語音識別和計算機視覺模型的相同行為,以及作為會話人工智能支柱的許多其他學科。
同時,在為其他語言開發大規模數據集和模型方面投入了有限的工作。事實上,大多數專注于英語以外的語言的工作都利用了較小的模型和較少管理的數據集。例如, NLP 使用來自常規數據集(如原始公共爬網)的子集。
支持以下任何一項的努力更少:
- 更本地化的模式,如阿拉伯語方言和變體或漢語子群和方言。
- 特定領域的模型,例如用于臨床筆記、科學出版物、財務報告分析、工程文檔解釋、通過法律文本進行解析,甚至用于 Twitter 等平臺的語言變體。
目前的狀況為愿意投資模型培訓的本地公司創造了一個機會,以領導該地區 NLP 技術的發展。
構建本地語言模型
由于許多原因,構建大規模的語言模型并非易事。首先,大規模數據集的管理并非微不足道。在原始格式中,它們實際上很容易獲得。其次,培訓這些大型模型所需的基礎設施需要大量的系統知識來建立。最后,他們需要廣泛的研究專業知識來培訓和優化。
人們不太了解的是,訓練如此大的模型需要軟件工程的努力。最有趣的模型不僅比單個 GPU 服務器的內存容量大,而且比許多多 GPU 服務器的內存容量大。訓練它們所需的數學運算的數量也會使訓練時間變得難以管理,即使在相當大的系統上,也要用幾個月來衡量。模型和管道并行等方法克服了其中一些挑戰。然而,以一種幼稚的方式應用它們可能會導致伸縮問題,加劇已經很長的訓練時間。
與諸如微軟和斯坦福大學這樣的組織一起, NVIDIA 一直致力于開發工具來簡化最大語言模型的開發過程,并提供計算效率和可擴展性以允許成本效益的培訓。因此,現在可以使用各種各樣的工具來抽象大型模型開發的復雜性,包括:
- NVIDIA 威震天 LM – 一個計算效率高的模型和流水線并行實現的自我注意和多層感知器,連同實現的模型,如 GPT-3 , T5 ,甚至視覺變壓器。特別是, GPT-3 代碼用多達 1 萬億個參數進行了測試。有關詳細信息,請參閱 威震天 LM :使用模型并行性訓練數十億參數語言模型 和 GPU 機群上高效的大規模語言模型訓練 。
- 微軟 DeepSpeed – 不僅支持 MigaTron LM 作為模型和流水線并行性的基礎的庫,還進一步優化了零冗余優化器(零)、 1 位亞當和 Lamb 或稀疏注意的實現。
- Facebook FairScale —通過實施模型并行訓練(基于 NVIDIA Megatron LM )、分片訓練或 AdaScale 優化器來解決大規模訓練的庫。
通過這些努力,我看到大型模型的訓練時間大大縮短。事實上,使用 1024 NVIDIA A100 張量核 GPU s 在 3000 億個代幣上訓練 1750 億個參數的 GPT-3 模型今天可以在 34 天內訓練(如 GPU 機群上高效的大規模語言模型訓練 所示)。基于實驗, NVIDIA 估計,使用 3072 A100 GPU s ,大約 84 天就可以訓練出 1 萬億個參數模型。盡管這些模型的培訓成本很高,但大多數大型組織并不能望其項背。隨著軟件的進一步發展,它可能會進一步減少。
由于大型語言模型的開發需要可擴展的基礎設施, NVIDIA 還將構建內部 硒原子團 (用于 NLP 內部研究 并在 MLPerf 訓練與推理 基準測試中提供創紀錄的性能)的知識整合到一個名為 NVIDIA DGX SuperPOD 的完整打包產品中。這個集群不僅僅是一個系統參考設計。事實上,它可以與 NVIDIA 數據科學家和應用研究人員的軟件和支持一起整體購買,類似于 Naver 克隆 的 NLP 重點部署。
這種方法已經對自然語言處理領域產生了重大影響,因為它使具有廣泛自然語言處理專門知識的組織能夠快速擴展其工作。更重要的是,它使具有有限系統、 HPC 或大規模 NLP 工作負載專業知識的組織能夠在數周內開始迭代,而不是數月或數年。

生產部署
構建大型語言模型的能力只是一項學術成就,因為無法通過將模型部署到生產環境中來利用您的工作成果。部署 GPT-3 這樣的模型所面臨的挑戰與它們的龐大規模(超過了 GPU 的內存容量)和計算復雜性有關。這兩個因素都會導致吞吐量降低和推理延遲增加。這是一個被廣泛理解的問題,目前有一系列的工具和解決方案可以使服務于最大的語言模型變得簡單和經濟高效。
- NVIDIA Triton ?聲波風廓線儀推斷服務器
- NVIDIA TensorRT 等模型優化技術
NVIDIA Triton ?聲波風廓線儀推斷服務器
NVIDIA Triton ?聲波風廓線儀推斷服務器 是為 CPU s 和 GPU s 優化的開源云和邊緣推斷解決方案。它可以有效地托管分布式模型。要使用管道并行性部署大型模型,必須將模型分成幾個部分,例如,使用 ONNX 圖形 等工具操作 ONNX 圖。每個部件都必須足夠小,以適合單個 GPU 的內存空間。
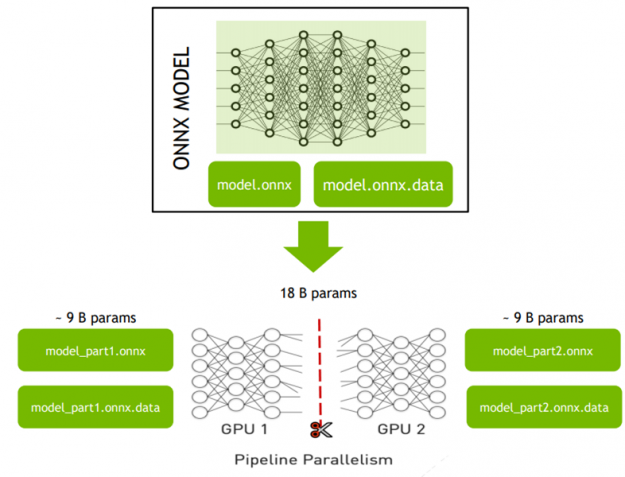
在細分模型之后,它可以分布在多個 GPU 上,而無需開發任何代碼。創建一個 NVIDIA Triton YAML 配置文件,定義模型的各個部分應如何連接。
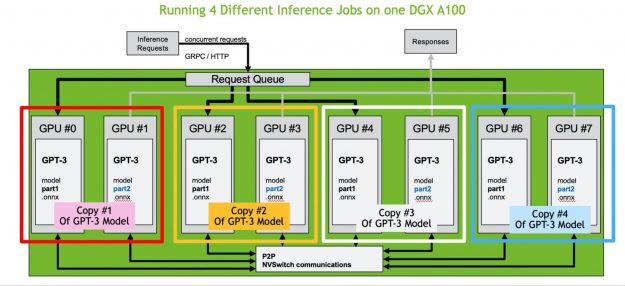
Triton 推理服務器可以自動管理各個模型部件之間的通信量及其負載平衡。由于 Triton ?聲波風廓線儀利用了最新的 NVIDIA NVSwitch 和第三代 NVIDIA NVLink 技術,提供了 600 GB / sec GPU – GPU 直接帶寬,比 PCIe gen4 高 10 倍,因此通信開銷也保持在最低水平。這意味著您不僅可以高效地部署數十億參數的中型模型,甚至可以部署最大的模型,包括具有萬億參數的 GPT-3 。
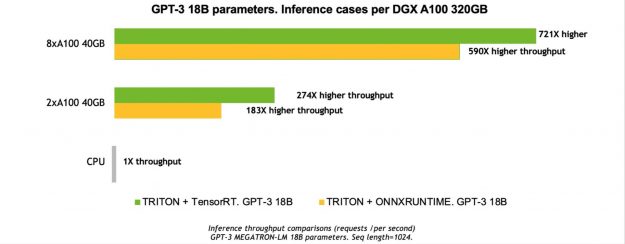
有關更多信息,請參閱 基于 Triton 和 ONNX 運行時的威震天 GPT-3 大模型推理 ( GTC21 會話)。
NVIDIA TensorRT 等模型優化技術
除了托管經過訓練的大型模型之外,研究優化技術也很重要。這些技術可以通過量化和剪枝來減少模型的內存占用;大幅度加快執行速度;并通過優化內存訪問、利用 TensorCores 或稀疏加速來減少延遲。
像 TensorRT 這樣的實用程序為執行基于轉換器的體系結構提供了廣泛的優化內核。它們可以自動進行半精度( FP16 )或在某些情況下進行 INT8 量化。 TensorRT 還支持量化感知訓練,并為硬件加速稀疏性提供早期支持。
NVIDIA FasterTransformer 庫專門用于變壓器神經網絡的推理,可與 BERT 或 GPT-2 / 3 等模型一起使用。該庫包括一個張量并行推理后端,可在 DGX A100 系統內的多個 GPU 上并行推理大型 GPT-3 模型。這使您可以根據模型大小將推理延遲減少 1 . 2 – 3 倍。使用 FasterTransformer ,您可以用一行代碼部署最大的威震天型號。
微軟的 DeepSpeed 庫有許多特性 專注于推理 ,包括支持混合量化( MoQ )、高性能 INT8 內核或 DeepFusion 。
由于所有這些進步,大型語言模型不再局限于學術研究,因為它們正在向基于人工智能的商業產品發展。
確定挑戰的大小
正確確定挑戰的大小對于 NLP 計劃的成功至關重要。所需的工程和研究人員以及培訓和推理基礎設施的數量會顯著影響您的業務案例。以下因素對開發總成本有重大影響:
- 支持的語言和方言數
- 正在開發的應用程序數(命名實體識別、翻譯等)
- 開發計劃(為了訓練更快,你需要更多的計算機)
- 對模型精度的要求(由數據集大小和模型大小驅動)
在解決了基本的業務問題之后,就可以估計開發所需的工作量和計算。當您了解了您的模型必須有多好才能容納產品或服務時,就可以估計所需的模型大小。語言模型的性能與數據量和模型大小之間的關系已被廣泛理解(圖 9 )。
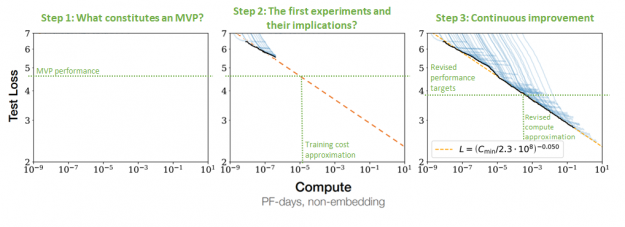
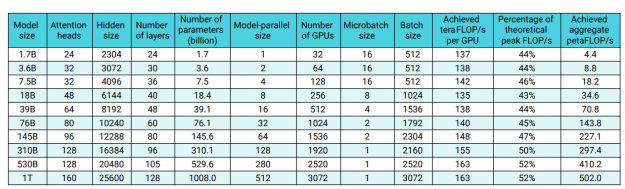
了解了所需的模型和數據集的大小之后,就可以估計所需的基礎結構數量和培訓時間。有關詳細信息,請參閱 GPU 機群上高效的大規模語言模型訓練 。此外,大型語言模型的縮放比例為 superlinear ,這意味著訓練性能不會隨著模型大小的增加而降低,而是實際增加(圖 10 )。
以下是初始基礎設施規模考慮的關鍵因素:
- 支持的語言、方言和特定于域的變體的數量
- 每種語言的應用程序數
- 項目時間表
- 模型必須實現的性能指標和目標,以創建最小可行的產品
- 積極參與每個應用程序或語言培訓的數據科學家、研究人員和工程師的數量
- 最少的周轉時間和訓練頻率,包括預訓練和微調
- 大致了解應用程序的推理需求、每天或每小時的平均或最大請求數及其季節性
- 訓練管道性能,或者單個訓練周期需要多長時間,以及管道實現離理論上的最高性能有多遠(圖 10 顯示了一個基于威震天 GPT-3 的示例)
大型模型是 NLP 的現在和未來
大型語言模型具有吸引人的特性,將有助于在全球范圍內擴展 NLP 的可用性。它們在大量 NLP 任務中表現得更好,但它們的樣本效率也更高。它們被稱為“少數鏡頭學習者”,在某些方面更容易設計,因為它們的精確超參數配置與它們的大小相比似乎并不重要。因此, NLP 模型可能會繼續增長。我看到經驗證據證明至少有一個或兩個數量級的增長是合理的。
幸運的是,構建和部署它們的技術已經相當成熟。訓練他們所需的軟件也已經相當成熟,并且可以廣泛使用,例如基于 NVIDIA 開源威震天的 GPT-3 實現。質量正在不斷提高,從而縮短了訓練時間。在這一領域訓練模型所需的基礎設施也得到了很好的理解和商用( DGX SuperPOD )。現在可以使用 Triton 推斷服務器等工具將最大的 NLP 模型部署到生產環境中,因此,每個人都可以使用大的 NLP 模型來追求它們。
概括
NVIDIA 積極支持客戶確定大型培訓和推理系統的范圍和交付,并支持他們建立 NLP 培訓能力。如果您正在努力建立 NLP 能力,請聯系您當地的 NVIDIA 客戶團隊。
您也可以加入我們的 深度學習培訓中心?NLP 課程 之一。在本課程中,您將學習如何使用現代 NLP 模型,如何使用 TensorRT 對其進行優化,以及如何使用 Triton 推理服務器進行部署以實現經濟高效的生產。
有關更多信息,請參閱以下任何與 NLP 相關的 GTC 演示文稿:
- 自然語言處理:新的機遇[E32293]
- 使用 Triton ?聲波風廓線儀和 ONNX 運行時的威震天 GPT-3 大模型推斷[S31578]
- 使用 Selene DGXA100 SuperPOD 和并行文件系統存儲[S31522]加速大規模人工智能
- S32030 : Gatortron –最大的臨床語言模型
- 設計和優化用于高吞吐量和低延遲生產部署的深層神經網絡[E31970]
?