有些編程情況要求異步報告“軟”錯誤。雖然printf可以是一個有用的工具,它可以增加寄存器的使用并影響性能。在這篇文章中,我們提出了一個替代方案,包括一個頭庫,用于在 GPU 上生成自定義錯誤和警告消息,而無需對內核進行硬停止。
錯誤報告往往會影響性能。雖然有些錯誤必須立即處理,但其他錯誤可以以警告和軟錯誤的形式出現,稍后可以報告和解決。
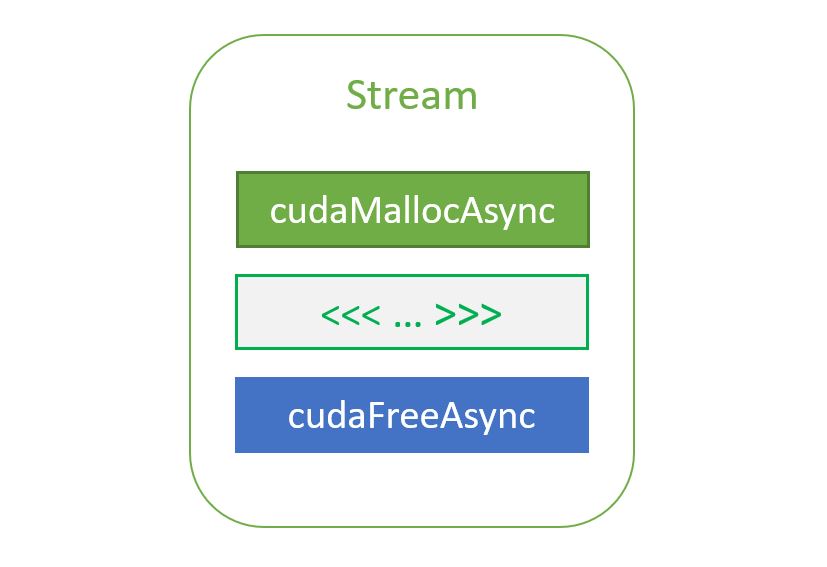
對于 GPU 來說,這通常是一個很好的策略,因為不同的內核可以在不同的流上啟動。如果出現任何錯誤,您可以異步查詢并解決。
例如,在一些物理模擬代碼中,可能存在物理上不可行的數值解決方案,例如負質量。您可能需要改變運行參數以獲得可行的解決方案,如設置較小的時間步長。
雖然有時可以創建誤差估計器,但在極少數情況下,估計器仍可能失敗。
在 GPU 的上下文中, CUDA 用戶可能傾向于檢查偶爾出現的不可行解決方案,然后使用printf以在屏幕上提醒最終用戶。此解決方案有幾個潛在的缺點:
- 如果有幾個流異步運行,那么輸出可能會變得復雜。發生錯誤時,必須重新啟動某些操作。額外的調試反饋沒有那么有用。
- 在寄存器受限內核的情況下,您可能希望增加占用率,使用
printf不分青紅皂白地可能會迫使編譯器將許多寄存器專用于代碼的一個分支,而該分支只能在偶爾觸發。 - 您對何時查詢錯誤和何時報告錯誤的控制較少。
我們在一些情況下遇到了這個錯誤報告問題,并使用atomicCAS以幫助高性能地檢測軟錯誤。然后,我們使用固定系統內存來協調主機端查詢和軟錯誤報告。
我們在一個僅限標頭的小型庫中提供了此解決方案,該庫提供了基礎設施,以便您可以將此異步錯誤報告解決方案放入代碼中。模板的使用使您能夠自定義錯誤報告有效負載,而我們的庫處理創建和映射系統固定和設備端錯誤信息。
此外,我們的庫使用 lambda 函數為您在 GPU 內核中觸發錯誤提供了足夠的靈活性。它為查詢和報告錯誤提供了靈活的幫助功能。
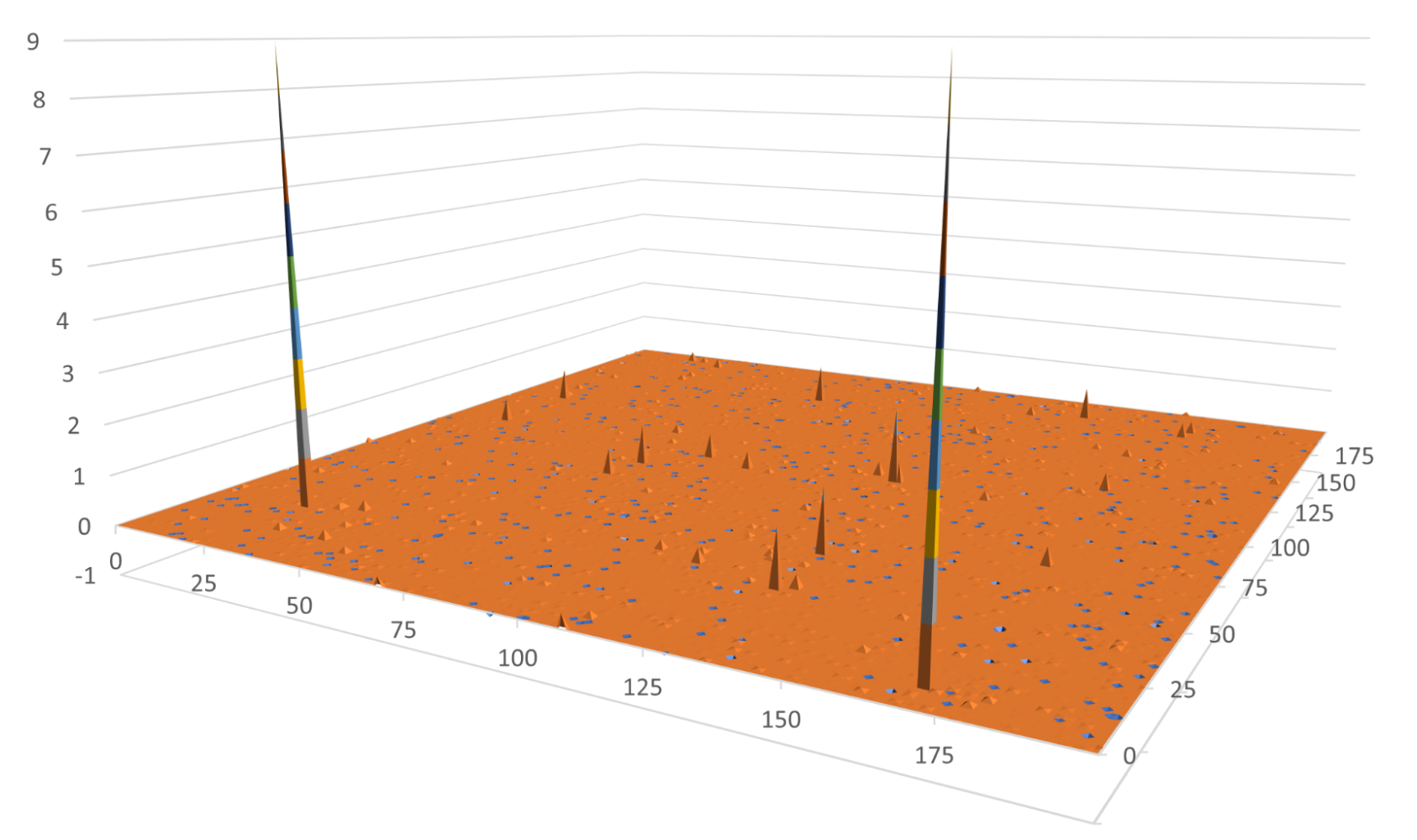
工作量示例
作為演示,我們使用下面的內核來模擬一個工作負載,該工作負載可以產生平滑變化的結果,但在罕見的邊緣情況下除外。內核生成一些介于 0 和 7210 之間的偽隨機整數。然后,它將該整數傳遞到一個函數中,該函數在 100 左右達到峰值。在極少數情況下,此內核會生成 1e6 。在剩下的時間里,這些值都小于 1 . 0 。
#include <iostream>
#include <stdio.h>
#include <assert.h>
#include <cuda.h>
__global__ void randomSpikeKernel(float* out, int sz)
// Generate a pseudo-random number
// Pass it into f(x) = 1/(x-100+1e-6)
// Write result to out
{
for (int idx = threadIdx.x + blockIdx.x * blockDim.x;
idx < sz;
idx += blockDim.x * gridDim.x)
{
const int A = 187;
const int M = 7211;
int ival = ((idx + A) * A) % M;
ival = (ival*A) % M;
ival = (ival*A) % M;
float val = 1.f/(ival-100+1e-6);
//assert(val < 10000);
out[idx] = val;
}
}
我們對的呼叫進行了評論assert,可在 GPU 或 CPU 上調用的函數,該函數會立即停止執行并返回錯誤。這是一種無法恢復的錯誤解決方案。
在許多情況下,最好讓內核運行并稍后報告軟錯誤。如果發生任何錯誤,您可能有興趣得到通知,但不想停止工作。你的第一反應可能是添加一個 printf 語句,如下所示:
__global__ void randomSpikeKernelwError(float* out, int sz)
// Generate a pseudo-random number
// Pass it into f(x) = 1/(x-100+1e-6)
// Write result to out
// In the case of a large value (>1e5) print and error, but continue
{
for (int idx = threadIdx.x + blockIdx.x * blockDim.x;
idx < sz;
idx += blockDim.x * gridDim.x)
{
const int A = 187;
const int M = 7211;
int ival = ((idx + A) * A) % M;
ival = (ival*A) % M;
ival = (ival*A) % M;
float val = 1.f/(ival-100+1e-6);
if (val >= 10000) {
printf("val (%f) out of range for idx = %d\n",
val, idx);
}
out[idx] = val;
}
}
這通常是一個可以接受的解決方案。但對于占用率受寄存器使用限制的內核來說,這可能會產生不希望的后果。即使printf語句很少被執行,編譯器必須分配寄存器以防萬一。
寄存器是僅在線程中使用的快速內存。寄存器中的數據可以低延遲讀取和寫入,但一個線程中的寄存器對任何其他線程都不可見。您可以通過添加-Xptxas=-v到編譯行,或者使用 NVIDIA Nsight Compute 來評測內核。
按照如下方式編譯以前的代碼:
nvcc -c -arch=sm_80 -Xptxas=-v kernel.cu
在編譯過程中,您會看到以下消息:
ptxas info : 36 bytes gmem
ptxas info : Compiling entry function '_Z17randomSpikeKernelPfi' for 'sm_80'
ptxas info : Function properties for _Z17randomSpikeKernelPfi
0 bytes stack frame, 0 bytes spill stores, 0 bytes spill loads
ptxas info : Used 14 registers, 364 bytes cmem[0], 8 bytes cmem[2]
ptxas info : Compiling entry function '_Z23randomSpikeKernelwErrorPfi' for 'sm_80'
ptxas info : Function properties for _Z23randomSpikeKernelwErrorPfi
16 bytes stack frame, 0 bytes spill stores, 0 bytes spill loads
ptxas info : Used 24 registers, 364 bytes cmem[0], 8 bytes cmem[2]
第一個內核沒有錯誤報告,使用了 14 個寄存器。第二個內核添加了printf語句,寄存器計數跳到 24 。
由于每個 SM 都有固定的內核寄存器空間,內核對寄存器的更高要求可能會限制每個 SM 上可以活動的線程塊的數量。這可能會導致暴露的延遲和較差的性能。此示例內核僅用于演示,不太可能出現寄存器壓力問題。
在 HPC 代碼中,與高寄存器數作斗爭是很常見的。在編譯過程中,寄存器計數通常會受到人為限制,但這可能會對性能產生其他負面影響。我們將在下一節對此進行討論。
此外,通過依賴控制臺流來報告信息,您放棄了對何時查詢和報告潛在軟錯誤的一些控制。在報告同時運行的幾個內核或設備功能的軟錯誤時,使用共享控制臺流可能會使輸出復雜化。
小的改進
如果寄存器壓力降低了內核的性能,因為printf消耗了保留但通常未使用的額外寄存器,一個潛在的解決方案是告訴編譯器通過設置-maxregcount編譯標志或使用__launch_bounds__在代碼中。
這會限制寄存器的數量,從而溢出多余的寄存器。只有在極少數情況下,你才會獲得表演上的成功printf發生。這是緩解登記冊壓力問題的一個重要提示,但它們可能是一個生硬的工具,并干擾其他減少登記冊的工作。
擬議的替代方案:比較和交換
報告此類錯誤的更好方法是使用atomicCAS起到異步屏障的作用,以檢測軟錯誤的第一個實例。
CASatomicCAS代表比較和交換,也稱為比較交換.
atomicCAS獲取一個內存位置、一個比較值和一個新值,并且只有當內存位置與比較值匹配時才將該值寫入內存位置。如果從存儲器讀取的值等于所提供的比較值,atomicCAS將新值寫入內存位置。否則,它將保持值不變。在任何一種情況下,它都會返回最初從內存位置讀取的值。
最重要的是,如果線程之間存在爭用,那么一次只有一個線程進行完全讀取、比較和交換。剩下的線程從內存中讀取更改后的值,然后跳過寫入。 CUDA 支持atomicCAS用于 32 位有符號整數和 16 位、 32 位或 64 位無符號整數。
在這個解決方案中,您使用atomicCAS以確保只有一個線程可以寫入錯誤消息。在清除錯誤之前,不會報告以后檢測到的所有錯誤。這避免了寫入錯誤消息的不同線程之間的競爭條件,并與本機 CUDA 錯誤的行為相匹配。
當檢測到錯誤時,應用程序通常必須記錄一些額外的數據——行號、錯誤代碼等等。在本例中,您可以寫入這些額外的數據,稱為錯誤“有效負載”zero copy,作為從 GPU 內核到系統固定的 CPU 內存的直接寫入。因為軟錯誤的有效負載通常很小,所以可以跳過顯式內存拷貝直接寫入有效負載。
您還可以在系統固定內存中跟蹤此錯誤的狀態。這使 CPU 主機知道在 GPU 上生成的錯誤。使用__threadfence_system以提供系統范圍的屏障,以確保在狀態標志改變之前有效載荷被完全寫入。這使主機能夠異步查詢狀態。當主機看到狀態發生變化時,可以確保錯誤負載包含適當的數據。
庫
由于解決方案的設置和初始化可能有點麻煩,我們提供了templated header-only library這簡化了這個過程,并使您能夠指定自定義的錯誤有效載荷。
我們引入了兩種基本模板類型,PinnedMemory<ErrorType>和DeviceStatus<T>,為錯誤有效負載以及設備端和固定狀態分配分配和銷毀系統固定內存。DeviceStatus還有一個僅限主機的狀態 getter ,使您能夠使用查詢固定狀態cuda::atomics.
與您交互的主要類是MappedErrorType,使用PinnedMemory和DeviceStatus類,以便輕松地協調狀態和有效負載組件。MappedErrorType處理底層類型的初始化、異步查詢錯誤、異步查詢有效負載、清除錯誤以及同步設備端和主機固定狀態。
以下代碼示例顯示類型為的錯誤RandomSpikeError可以使用結構進行記錄RandomSpikeError.
struct RandomSpikeError
{
int code;
int line;
int filenum;
int block;
int thread;
// payload information
int idx;
float val;
};
__global__ void randomSpikeKernelFinal(float* out, int sz, MappedErrorType<RandomSpikeError> device_error_data)
// This kernel generates a pseudo-random number
// then puts it into 1/num-100+1e-6. That curve is
// sharply peaked at num=100 where the value is 1e6.
// In the case of a large value, you want to report an
// error without stopping the kernel.
{
for (int idx = threadIdx.x + blockIdx.x * blockDim.x;
idx < sz;
idx += blockDim.x * gridDim.x)
{
const int A = 187;
const int M = 7211;
int ival = ((idx + A) * A) % M;
ival = (ival*A) % M;
ival = (ival*A) % M;
float val = 1.f/(ival-100+1e-6);
if (val >= 10000) {
report_first_error(device_error_data, [&] (auto &error){
error = RandomSpikeError {
.code = LARGE_VALUE_ERROR,
.line = __LINE__,
.filenum = 0,
.block = static_cast<int>(blockIdx.x),
.thread = static_cast<int>(threadIdx.x),
.idx = idx,
.val = val
};
});
}
out[idx] = val;
}
}
類型的錯誤負載RandomSpikeError在用戶提供的 lambda 函數中直接在設備上設置 in pined 內存
函數 report _ first _ error 的定義如下:
template <typename ErrorType, typename FunctionType>
inline __device__ void report_first_error(
MappedErrorType<ErrorType> & error_dat,
FunctionType func){
if(atomicCAS(reinterpret_cast<int*>(error_dat.deviceData.device_status),
static_cast<int>(ATOMIC_NO_ERROR),
static_cast<int>(ATOMIC_ERROR_REPORTED)) ==
static_cast<int>(ATOMIC_NO_ERROR) ) {
func(*error_dat.deviceData.host_data);
__threadfence_system();
error_dat.synchronizeStatus();
}
}
正如您所看到的,使用atomicCAS其中首先執行設備側狀態。如果成功,則執行用戶提供的 lambda 函數并將其寫入固定內存。之后,使用系統范圍的線程圍欄來保證在將主機固定狀態與設備側狀態同步之前已執行該功能。
然后,主機可以使用查詢并報告錯誤MappedErrorType<RandomSpikeError>直接地
int reportError( MappedErrorType<RandomSpikeError> & error_dat)
{
int retval = NO_ERROR;
if (error_dat.checkErrorReported()) {
auto & error = error_dat.get();
retval = error.code;
std::cerr << "ERROR " << error.code
<< ", line " << error.line
<< ". block " << error.block
<< ", thread " << error.thread;
if (retval == LARGE_VALUE_ERROR)
std::cerr << ", value = " << error.val;
std::cerr << std::endl;
}
return retval;
}
auto async_err = reportError(mapped_error);
if (async_err != NO_ERROR) std::cout << "ERROR! " << "code: " << async_err << std::endl;
else std::cout << "No error" << std::endl;
由于錯誤可能異步發生,您的應用程序可能必須正確同步或等待特定事件,以確保內核已經完成。這與本機 CUDA 錯誤的行為類似。
把它們放在一起
雖然我們的庫簡化了許多必要的工作,但以下是幕后發生的事情,以便您可以根據需要擴展和調整錯誤報告。
在執行內核之前,我們初始化MappedErrorType<T>主機端和設備端狀態自動初始化的對象 (ATOMIC_NO_ERROR = 0) . 當在內核中檢測到錯誤時,report_first_error使用atomicCAS標記設備端狀態 (ATOMIC_ERROR_REPORTED=1) 然后執行用戶提供的 lambda 函數以在應用前面提到的線程圍欄和主機設備狀態同步之前將有效載荷寫入系統固定存儲器。
線程只能在以下情況下寫入錯誤數據atomicCAS退貨ATOMIC_NO_ERROR,這意味著沒有其他線程已經記錄到錯誤。除非您將狀態重置為ATOMIC_NO_ERROR,沒有記錄此錯誤的其他實例。接收的線程ATOMIC_NO_ERROR寫入其錯誤代碼和相關數據。
為了清除數據,我們提供了clear(cudaStream_t)將狀態設置為的方法ATOMIC_NO_ERROR主機端和設備端狀態。
為了檢查主機是否出現錯誤reportError使用checkErrorReported,僅檢查主機側狀態是否設置為ATOMIC_ERROR_REPORTED。然后我們打電話get在錯誤類型的有效負載上 (struct RandomSpikeError) 并讀取錯誤信息。
在內核執行期間檢測到錯誤既不會停止內核,也不會停止主機。與本機 CUDA 錯誤一樣,主機可能會在檢測到此內核中的錯誤之前啟動幾個內核。
int main(void)
{
…
// Create pinned flags/data and device-side atomic flag for CAS
auto mapped_error =
CASError::MappedErrorType<RandomSpikeError>();
auto mapped_error2 = CASError::MappedErrorType<OtherError>();
…
int async_err; // error query result
// Allocate memory and a stream
float *out, *h_out;
h_out = (float*)malloc(sizeof(float)*MAX_IDX);
cudaMalloc((void**)&out, sizeof(float)*MAX_IDX);
cudaStream_t stream; cudaStreamCreate(&stream);
CASError::checkCuda(
cudaEventCreate(&finishedRandomSpikeKernel) );
// Launch the kernel. This launch causes a
// LARGE_VALUE_ERROR
randomSpikeKernel<<<100,32,0,stream>>>(out, MAX_IDX);
randomSpikeKernelFinal<<<100,32,0,stream>>>(out, MAX_IDX,
mapped_error);
CASError::checkCuda(
cudaEventRecord(finishedRandomSpikeKernel, stream) );
// Check the error message from err_data
async_err = reportError(mapped_error);
if (async_err != NO_ERROR) std::cout << "ERROR! " << "code: "
<< async_err << std::endl;
else std::cout << "No error" << std::endl;
// Launch another kernel
otherKernel<<<100,32,0,stream>>>(out, MAX_IDX,
mapped_error2);
…
async_err = reportError(mapped_error2, stream);
if (async_err != NO_ERROR)
std::cout << "ERROR! " << "code: " << async_err <<
std::endl;
else std::cout << "No error" << std::endl;
std::cout << "Launch memcpy" << std::endl;
cudaMemcpyAsync(h_out, out, sizeof(float)*MAX_IDX,
cudaMemcpyDeviceToHost, stream);
cudaStreamSynchronize(stream);
async_err = reportError(mapped_error);
if (async_err != NO_ERROR) std::cout << "ERROR! " << "code: "
<< async_err << std::endl;
else std::cout << "No error" << std::endl;
mapped_error.clear(stream);
async_err = reportError(mapped_error2, stream);
if (async_err != NO_ERROR) std::cout << "ERROR! " << "code: "
<< async_err << std::endl;
else std::cout << "No error" << std::endl;
int final_err = reportError(mapped_error);
if (final_err != NO_ERROR) std::cout << "ERROR! " << "code: "
<< final_err << std::endl;
else std::cout << "No error" << std::endl;
// Free memory, stream
cudaFree(out);
free(h_out);
cudaStreamDestroy(stream);
return 0;
}
在測試中,您首先啟動生成錯誤的內核。然后檢查主機線程上的錯誤。在此檢查之前,您沒有同步主機和設備。當同步影響性能時,您可能需要在同步之前排隊等待更多的 GPU 工作。
您正在檢查此示例代碼中的錯誤,以演示異步錯誤報告。如果您不介意性能命中,并且希望按順序報告錯誤,請添加cudaStreamSynchronize在呼叫之前呼叫reportError.
檢查錯誤后,啟動另一個內核,otherKernel,然后再次檢查錯誤。使用將生成的數據復制回主機cudaMemcpyAsync。同步流以確保主機上的數據是正確的,并再次檢查是否有錯誤。現在,您一定會發現自己的錯誤。
接下來,清除錯誤,并檢查第二種類型的錯誤,也保證會被捕獲。最后,為了顯示錯誤已被清除,請最后一次檢查錯誤。
當編譯并執行此代碼時,您可能會看到以下輸出:
No error No error Launch memcpy ERROR 2, line 144. block 92, thread 20, value = 1e+06 ERROR! code: 2 ERROR 3, line 171, file /tmp/devblog/main.cu. block 25, thread 8 ERROR! code: 3 No error
錯誤是在的 GPU 執行期間生成的randomSpikeKernelFinal,但由于您沒有在調用之間同步主機和設備,因此主機線程能夠對內核和memcpy立即執行,而無需等待第一個 CUDA 內核完成。直到流同步之后, CPU 才檢測到并報告錯誤。
由于您有兩種不同類型的錯誤,因此可以分別捕獲和清除每一種錯誤。否則,您只報告您觀察到的每種類型的第一個錯誤。
收益
使用編譯時-Xptxas=-v,您可以看到此輸出(添加了突出顯示):
ptxas info : Compiling entry function '_Z17randomSpikeKernelPfi' for 'sm_70' ptxas info : Function properties for _Z17randomSpikeKernelPfi 0 bytes stack frame, 0 bytes spill stores, 0 bytes spill loads ptxas info : Used 14 個寄存器, 364 bytes cmem[0], 8 bytes cmem[2] ptxas info : Compiling entry function '_Z23randomSpikeKernelwErrorPfi' for 'sm_70' ptxas info : Function properties for _Z23randomSpikeKernelwErrorPfi 16 bytes stack frame, 0 bytes spill stores, 0 bytes spill loads ptxas info : Used 24 個寄存器, 364 bytes cmem[0], 8 bytes cmem[2] ptxas info : Compiling entry function '_Z22randomSpikeKernelFinalPfi' for 'sm_70' ptxas info : Function properties for _Z22randomSpikeKernelFinalPfi 0 bytes stack frame, 0 bytes spill stores, 0 bytes spill loads ptxas info : Used 18 個寄存器, 364 bytes cmem[0], 8 bytes cmem[2]
第一個內核沒有錯誤報告。第二個報告錯誤使用printf第三個也是最后一個內核使用了前面描述的新方法。下表顯示了早期輸出的寄存器計數。
| 內核 | 錯誤報告方法 | 寄存器 |
randomSpikeKernel |
沒有一個 | 14 |
randomSpikeKernelwError |
printf |
24 |
randomSpikeKernelFinal |
atomicCAS |
18 |
檢查錯誤并使用報告atomicCAS與使用時的 10 個新寄存器相比,增加了 4 個寄存器printf在這種小情況下,寄存器計數不太可能影響性能。對于寄存器使用是一個性能問題的內核,這種新的錯誤報告可以產生顯著的影響。
一個真實世界的例子
下面是一個例子,說明了這種新方法可以在實際代碼中產生的差異。
我們在 hpMusic 中對這個庫進行了野外測試, hpMusic 是一個高階計算流體動力學模擬代碼示例。在基線代碼中,一個內核printf用于報告罕見軟錯誤的語句使用了 248 個寄存器。通過評論printf(無錯誤報告),ncu報告了內核的 148 個寄存器。
最后,通過訪問我們的圖書館,ncu報告編譯的內核也使用了 150 個寄存器。由于這些內核受寄存器約束,因此通過避免printf在這個性能關鍵的內核中,它對運行時產生了重大影響。
| 內核變化 | 寄存器 | 占用率 | 內核運行時間(毫秒) |
| 輸出函數 | 248 | 11 . 97% | 293 . 5 |
| 無報告 | 148 | 17 . 83% | 243 . 6 |
| 打印備選方案 | 150 | 17 . 80% | 239 . 5 |
| printf 和 launch _ bounds | 168 | 17 . 25% | 299 |
雖然 hpMusic 開發人員是領域專家,他們也編寫 GPU 應用程序,但他們對使用printf在寄存器約束內核中。
結論
如果您正在報告軟錯誤或其他不常見的內核信息,下載 headers以及這篇文章中的例子,并自己嘗試一下。我們總是對反饋感興趣,所以請發送消息,讓我們知道它是如何工作的!
?