
DeepSeek-R1 等先進的 AI 模型證明,企業現在可以構建專用于自己的數據和專業知識的尖端 AI 模型。這些模型可以根據獨特的用例進行定制,以前所未有的方式應對各種挑戰。
基于早期 AI 采用者的成功,許多組織正在將重點轉移到全面生產的 AI 工廠 。然而,創建高效 AI 工廠的過程復雜且耗時,并且不同于構建特定于垂直行業的 AI 的目標。
它涉及到樓宇自動化,用于調配和管理復雜的基礎設施,在最新平臺上維護具有專業技能的站點可靠性工程師(SRE)團隊,以及大規模開發流程以實現超大規模的效率。此外,開發者需要一種方法來利用 AI 基礎設施的強大功能,同時具備超大規模數據中心的敏捷性、效率和規模,同時避免成本、復雜性和專業知識等方面的負擔。
本文將介紹 NVIDIA Mission Control (一個為使用 NVIDIA 參考架構構建的 AI 工廠提供支持的集成軟件堆棧) 如何通過編寫 NVIDIA 最佳實踐來應對這些挑戰,從而使組織能夠自信地專注于構建模型而不是管理基礎設施。
企業基礎架構和開發者生產力的新標準
NVIDIA Mission Control 為 IT 管理員提供強大的工具,以大規模優化 AI 工作負載利用率、性能和效率。借助自動工作負載恢復,開發者即使在硬件異常或維護期間也可以保持工作效率,從而確保出色的正常運行時間和更快的 AI 實驗。NVIDIA Mission Control 專為實現可擴展性而設計,可提供先進的全集群控制和可見性,無縫管理數千個 GPU,從而實現峰值運營效率。
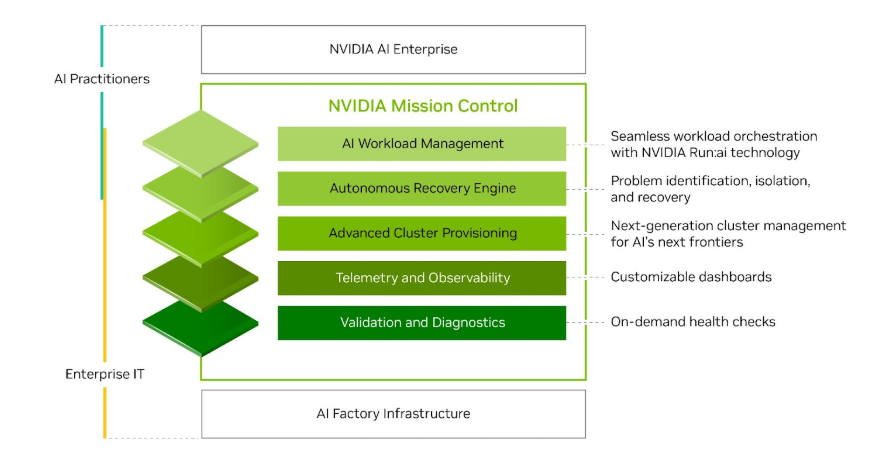
NVIDIA Mission Control 的主要功能
主要功能包括可擴展的控制平面、高級集群調配、遙測和可觀察性、AI 工作負載管理等。
用于快速部署的可擴展控制平面
加速 AI 工廠部署始于標準化、可擴展的控制平面,該控制平面可為訓練和推理工作負載提供集中式配置、管理和可觀察性。此控制平面專為實現靈活性而設計,可無縫支持異構架構,支持在同一 AI 工廠內使用 NVIDIA DGX SuperPOD 以及 NVIDIA DGX B200 系統 和 NVIDIA DGX GB200 系統 進行部署。
高級集群調配
NVIDIA Mission Control 中的高級集群配置由 NVIDIA Base Command Manager 提供支持 ,可簡化 AI 工廠運營,通過專為實現峰值效率而設計的自動化工作流大幅縮短部署時間。它專為 NVIDIA GB200 NVL72 等尖端架構 而構建,引入了機架管理功能、泄漏檢測策略、數千個 GPU 的配置以及大規模安全網絡。
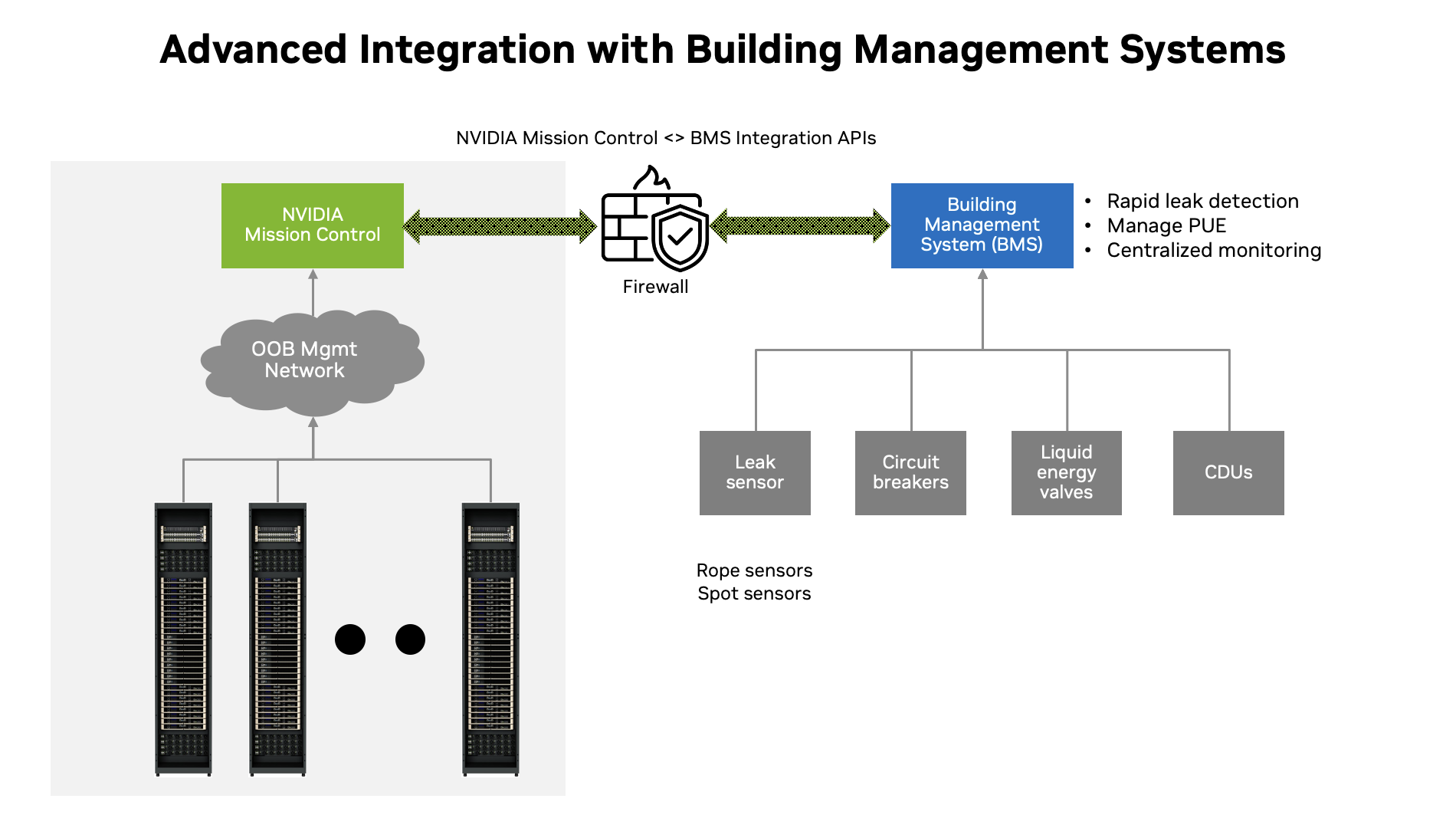
借助集成的庫存管理和直觀的可視化,IT 團隊可以獲得實時資產跟蹤和簡化的維護。智能功耗優化策略使管理員能夠在用戶和數據中心級別上微調性能,從而最大限度地提高效率。此外,通過標準化接口實現數據中心樓宇管理系統(BMS)與 NVIDIA Mission Control 的高級集成,確保打造面向未來的 AI 基礎設施。
遙測和可觀察性
遙測和可觀察性堆棧提供實時監控和高級分析,使 IT 管理員能夠深入了解 AI 基礎設施性能。該遙測采集系統專為實現可擴展性和彈性而構建,可在 AI 工廠中的數千個 GPU、 NVIDIA Spectrum-X 以太網 和 NVIDIA Quantum InfiniBand 網絡交換機以及 NVIDIA NVLink 交換機之間并行收集數據。該系統由 NVIDIA Unified Fabric Manager (UFM) 和 NVIDIA NMX Manager 提供支持。
集中式可觀察性中心將關鍵系統指標處理到時間序列數據庫中,用于監控、可視化和警報。借助集中式儀表板、主動警報和智能日志管理,NVIDIA Mission Control 使 IT 管理員能夠為其 AI 工廠保持出色的控制力和運營效率。
驗證和診斷
NVIDIA Mission Control 可確保全面的 AI 工廠驗證,嚴格驗證從基本功能到復雜交互的組件。該套件基于可擴展的測試框架構建,該框架為 NVIDIA AI 超級計算機—Selene、Eos 等實現了行業領先的 MLPerf 基準性能,可在安裝后提供實時運行狀況監控和早期問題檢測。IT 管理員還可以利用這些按需運行狀況檢查來評估其 AI 基礎設施的整個生命周期,確保大規模實現峰值性能和可靠性。
AI 工作負載管理
NVIDIA Run:ai 平臺提供企業級 AI 工作負載編排,將集中式控制平面與智能集群管理無縫結合,可實現多集群效率,將 GPU 利用率提升高達 5 倍。 它基于 Kubernetes 構建,現已與 NVIDIA Mission Control 集成,支持 NVLink 拓撲感知和內置運行狀況檢查,可充分發揮 NVIDIA DGX GB300 等新一代架構的潛力。 開發者還可以靈活地使用 Slurm 進行工作負載管理,確保從研究實驗室到企業范圍內的部署,都有一個適應性強、可擴展的 AI 基礎設施。
自動恢復引擎
NVIDIA Mission Control 利用自主恢復引擎在大規模訓練作業的后臺運行。這通過事件驅動的微服務來檢測、隔離和解決工作負載中斷,提高了 AI 訓練的可靠性,從而改善了 AI 工廠中的 GPU 使用情況。自主恢復引擎與 Slurm 集成,并利用 NVIDIA Run:ai 適用于 Kubernetes 來管理工作負載。
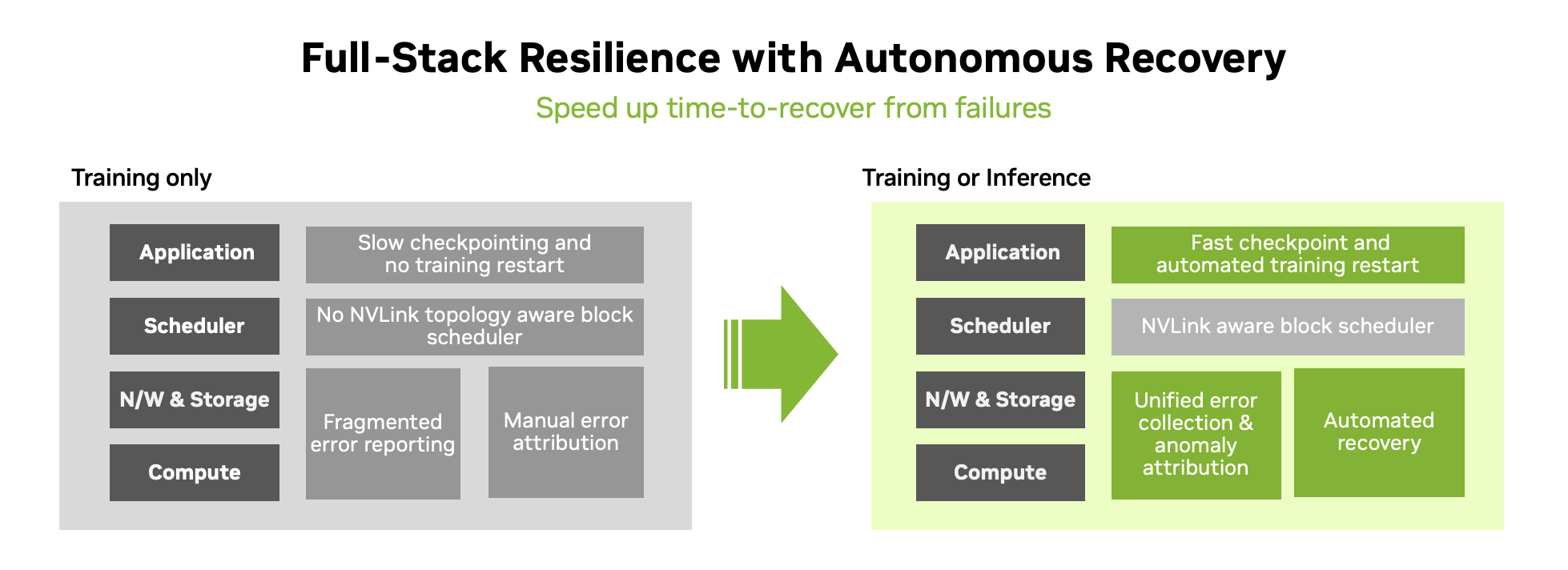
自動恢復引擎通過分析實時系統運行狀況來持續檢測異常情況,使用 AI 模型和預定義的規則來查明操作問題,并將其與特定硬件行為關聯起來。當出現異常時,NVIDIA Mission Control 會進行干預,從 NVIDIA Resiliency Extension (NVRx) 提供的上一個已知的良好檢查點重新啟動作業,從而消除開發者或 SRE 手動監控進度的需求。這最大限度地減少了機時間,并將恢復時間縮短 10 倍,從而加快訓練和推理運行速度。系統會自動排除有故障的硬件,確保順利執行。
與此同時,NVIDIA Mission Control 負責診斷工作,找出次要硬件的根本原因。這些診斷基于 NVIDIA 自己構建 AI 工廠的經驗而構建,為開發者節省了手動調試工作。其工作流引擎執行自動恢復 playbook,致力于修復和重新集成健康的組件回操作中。
如果某個組件仍然無法恢復,NVIDIA Mission Control 會標記該組件以用于退貨授權 (RMA) 。該軟件可以通過 NVIDIA Enterprise Support 發起支持票,簡化解決流程。這種智能編排可最大限度地延長 AI 工廠的正常運行時間,最大限度地提高效率,并確保開發者能夠以可預測的方式取得成果。
開始使用 NVIDIA Mission Control
AI 工廠不僅僅是一個傳統的數據中心,而是確保任務關鍵型工作負載保持正常運行的支柱,使組織能夠加速其在 AI 領域的投資。隨著企業組織擴展 AI,重點轉移到為模型構建器提供支持和加速 AI 實驗上,這對于縮短上市時間和保持競爭優勢至關重要。
借助 NVIDIA Mission Control,企業將受益于簡化的 AI 操作——從工作負載到基礎設施層——并通過新的軟件自動化提供成文的專業知識。 NVIDIA Mission Control 是為 NVIDIA Blackwell 數據中心提供支持的重要組件,可為推理和訓練帶來即時的敏捷性,同時提供全棧智能,提高基礎設施的恢復能力。
現在,每個企業都可以超大規模高效地運行 AI,從而簡化和加速 AI 實驗。如需了解更多信息,請查看 NVIDIA GTC 2025 會議“ 新一代數據中心:智能自動化和集成可觀察性,助力開發者實現生產力峰值 ”的點播回放。







