降低對新市場事件的響應時間是算法交易的一個驅動力。對延遲敏感的交易公司通過在其系統中部署諸如現場可編程門陣列( FPGA )和專用集成電路( ASIC )等低級別硬件設備來跟上金融電子市場不斷增長的步伐。
然而,隨著市場變得越來越高效,交易者需要依靠更強大的模型,如深度神經網絡( DNN )來提高盈利能力。由于在低級別硬件設備上實現此類復雜模型需要大量投資,通用 GPU 為 FPGA 和 ASIC 提供了一種可行、經濟高效的替代方案。
NVIDIA 在 STAC 審計的 STAC-ML 推理基準 中證明,1 NVIDIA A100 Tensor Core GPU 可以以低延遲一致地運行 LSTM 模型推斷。這表明, GPU 可以替代或補充現代交易環境中通用性較差的低級硬件設備。
STAC-ML 推理基準結果
具有長短期記憶的深度神經網絡( LSTM )是時間序列預測的成熟工具。它們也適用于現代金融。 STAC-ML 推理基準旨在測量 LSTM 模型推理的延遲。這被定義為從接收新輸入信息到計算模型輸出的時間。
基準測試定義了以下三種不同復雜度的 LSTM 模型: LSTM _ A 、 LSTM _ B 和 LSTM _ C 。每個模型都有一個獨特的特征、時間步長、層和每層單位的組合。 LSTM _ B 大約比 LSTM _ A 大 6 倍, LSTM _ C 大約大兩個數量級。
有兩個獨立的基準套房: Tacana 和 Sumaco 。 Tacana 用于在滑動窗口上執行的推斷,在滑動窗口中,為每個推斷操作添加新的時間步長,并刪除最早的時間步長。在 Sumaco ,每個推斷都是在一組全新的數據上進行的。
Tacana Suite 的低延遲優化結果
NVIDIA 在具有 FP32 精度( SUT ID NVDA221118b )的單個 NVIDIA A100 80 GB PCIe Tensor Core GPU 的 Supermicro 超級超級服務器 SYS-620U-TNR 上演示了以下延遲(第 99 百分位):
- LSTM _ A:35.2 微秒2
- LSTM _ B:68.5 微秒3
- LSTM _ C:640 微秒4
上面的數字用于在一個模型實例上運行推理。也可以在單個 GPU 上部署獨立模型實例的集合。對于 16 個獨立模型實例,相應的延遲為:
- LSTM _ A:54.1 微秒5
- LSTM _ B:140 微秒6
- LSTM _ C:748 微秒7
此外,延遲中沒有大的異常值。最大潛伏期不超過所有 LSTM 的中值潛伏期的 2.3 倍,8即使當并發模型實例的數量增加到 32 時。具有這樣的可預測性能對于金融業的低延遲環境至關重要,在這種環境中,極端的異常值可能會在市場快速移動期間導致重大損失。
NVIDIA 是第一家提交 Tacana 套件基準測試數據的供應商。與 Sumaco Suite 相比, Tacana 基準允許滑動窗口優化,這有助于利用時間序列數據的流式特性。 之前提交的 STAC ML 基準的 Sumaco 套件 聲稱延遲數字在相同數量級內。
Sumaco Suite 的高吞吐量優化結果
NVIDIA 還為 Sumaco Suite 提交了 FP16 精度( NVDA221118a )相同硬件上的吞吐量優化配置:
- LSTM _ A:1.629 至 1.707 米9功耗為 949 瓦時每秒的推斷
- LSTM _ B :超過 190 K10927 瓦功耗時每秒的推斷
- LSTM _ C:12.8 千11722 瓦功耗下的每秒推斷
這些數字證實了 NVIDIA GPU 在吞吐量和能效方面無與倫比,適用于后驗和模擬等工作負載。
對自動化交易的影響
為什么在自動化交易中,光只能行進 300 米的時間跨度——微秒也很重要?成熟的電子市場以高速傳播新信息。依賴 LSTM 等復雜神經網絡的交易應用程序存在模型推斷耗時過長的風險。
為了將我們的推斷延遲置于高頻交易環境中,我們分析了歐洲交易最活躍的金融合約之一的市場交易之間的時間間隔: EURO STOXX 50 指數期貨( FESX )。12
高精度時間戳( HPT )數據集 包括與 2022 年 10 月新價格水平交易相對應的納秒刻度數據。我們統計了兩次連續交易之間的時間差小于 上面報告的延遲 的頻率。推斷引擎中排隊的事件頻率的估計結果如下:
- LSTM _ A:0.14% 發生率
- LSTM _ B:0.58% 出現
- LSTM _ C:8.52% 出現
如圖所示, NVIDIA GPU 使電子交易應用程序能夠在服務于當今移動最快市場的大型 LSTM 模型上實時運行推斷。像 LSTM _ B 這樣復雜的模型的排隊頻率非常低,為 0.58% 。即使是最復雜的 LSTM _ C 模型,排隊頻率為 8.52% , NVIDIA 提交的推理延遲也低于 1 毫秒。
NVIDIA GPU 在電子交易方面的優勢
NVIDIA GPU 提供了許多好處,有助于降低電子交易堆棧的總體擁有成本,詳情如下。
培訓和部署平臺
無論您是否需要開發、回測或部署 AI 模型, NVIDIA GPU 都能提供世界級的性能,而無需迫使開發人員學習不同的編程語言和編程模型進行研究和交易。所有 NVIDIA GPU 都會說 CUDA ,因此無論您是在開發工作站還是數據中心使用各自的設備,都可以以相同的方式進行編程。
此外, NVIDIA Nsight 工具 由一組強大的開發人員資源組成,用于調試和配置應用程序,提高其性能。在許多情況下,甚至不需要學習 CUDA 。像 PyTorch 這樣的現代機器學習框架揭示了 CUDA 的性能相關特性,如 CUDA Graph 和 CUDA 流,并提供了復雜的評測功能。
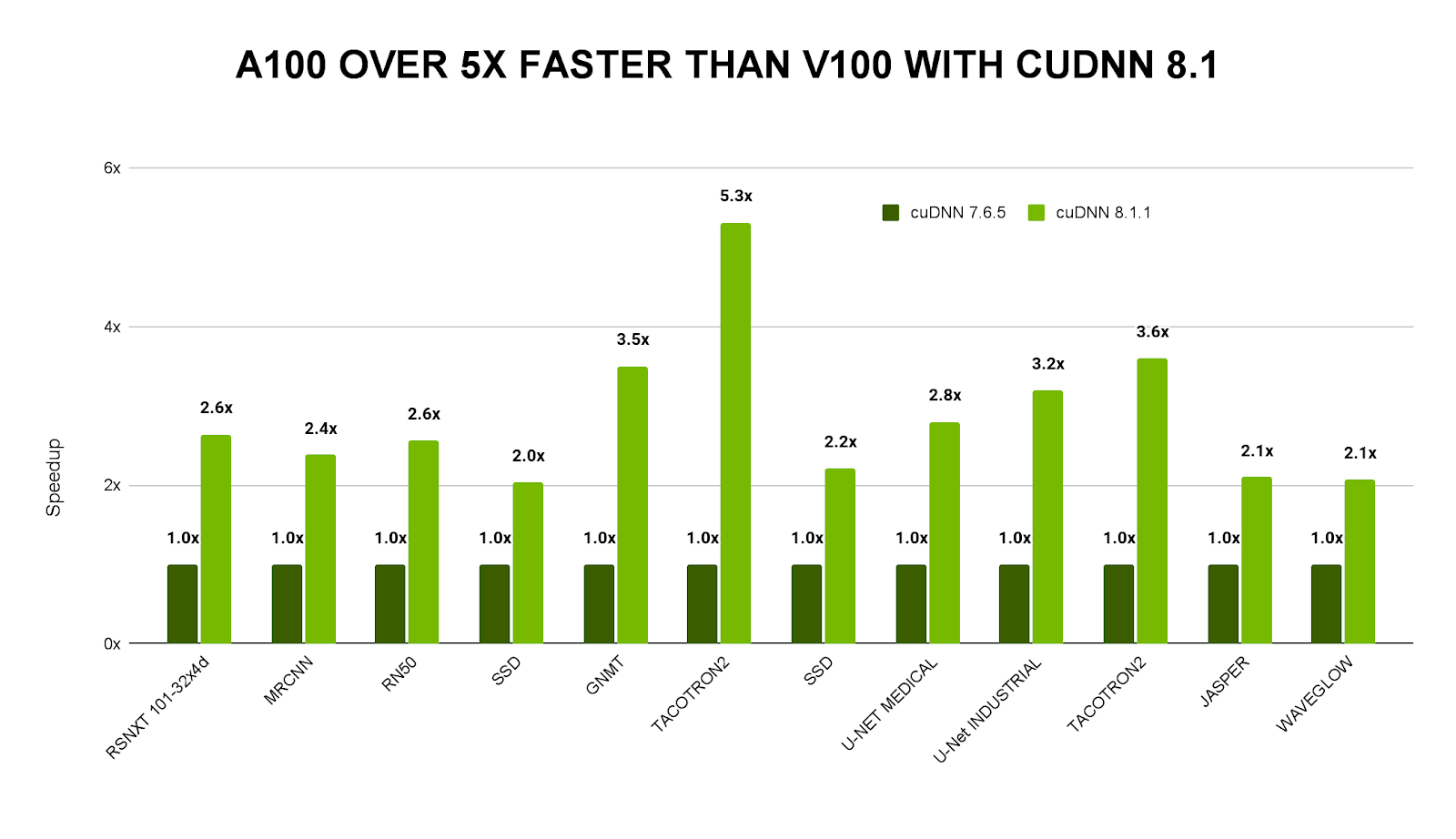
性能改進
NVIDIA 正在不斷提高其核心庫的性能,如用于加速基本線性代數子程序的 cuBLAS 、用于高性能矩陣乘法( GEMM )的 CUTLASS 或用于加速深度神經網絡原語的 cuDNN 。所有這些庫都有助于靈活的性能調整,甚至提供自動調整功能,以便為 GPU 和應用程序的給定組合選擇最佳原語。因此,基于 NVIDIA GPU 的 AI 應用程序堆棧在其整個生命周期內變得更快(圖 1 )。
高計算密度
有效利用數據中心的空間至關重要。即使在服務器中安裝一個 NVIDIA A100 Tensor Core GPU ,也可以實現以下空間效率數字:
- LSTM _ A:6666621 至 694874 推斷/秒/立方英尺13
- LSTM _ B:777714 至 77801 推斷/秒/立方英尺14
- LSTM _ C :每秒每立方英尺 5212 次推斷15
請注意,這些數字來自吞吐量優化配置報告( SUT ID NVDA221118a ),而不是延遲優化。 Supermicro 服務器通過 NVIDIA 認證 最多可用于四個 NVIDIA A100 GPU ,這將相應地增加計算密度。
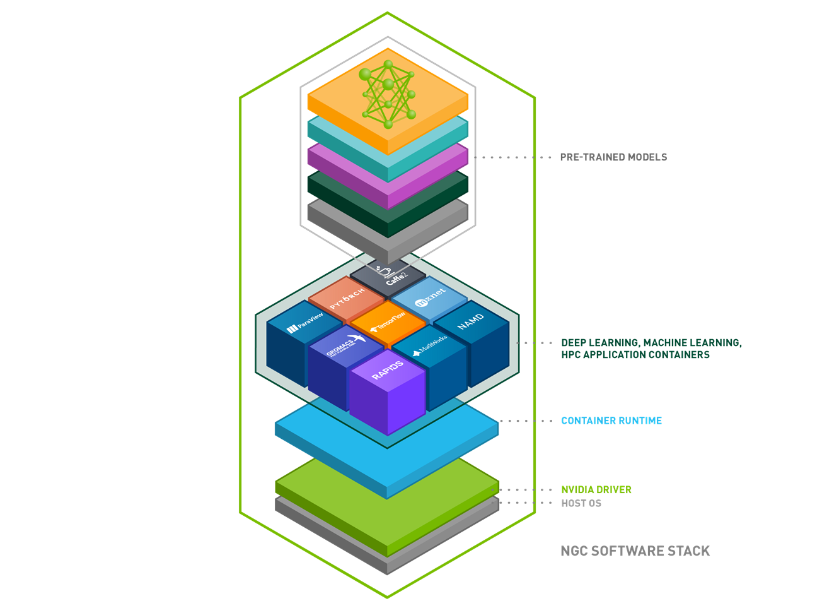
大型生態系統和開發者社區
NVIDIA GPU 支持許多深度學習框架,如 PyTorch 、 TensorFlow 或 mxNet ,這些框架被世界各地的數據科學家和定量研究人員使用。為了減輕依賴關系管理的痛苦,所有框架都以包含最新版本庫的容器映像的形式提供。這降低了設置開發環境的負擔,并確保了結果的再現性。這些容器圖像可以通過 NVIDIA NGC 輕松獲得,它提供完全管理的云服務以及 GPU 優化的 AI 軟件和預訓練模型的目錄(圖 2 )。
總結
STAC-ML 推理基準測試中獲得的結果證明了 GPU 在低延遲環境中的附加值,無論是獨立的還是互補的。在同一平臺上進行定量研究和交易開發,可以顯著縮短生產時間。單個硬件目標減輕了為不同平臺維護多個實現的負擔。 NVIDIA 加速計算平臺的一個獨特優勢是這種范式的轉變,即在研究和交易之間整合開發堆棧。
工具書類
- “ STAC ”和所有 STAC 名稱均為 Securities Technology Analysis Center , LLC 的商標或注冊商標
- STAC-ML.Markets.Inf.T.LSTM_A.1.LAT.v1
- STAC-ML.Markets.Inf.T.LSTM_B.1.LAT.v1
- STAC-ML.Markets.Inf.T.LSTM_C.1.LAT.v1
- STAC-ML.Markets.Inf.T.LSTM_A.16.LAT.v1
- STAC-ML.Markets.Inf.T.LSTM_B.16.LAT.v1
- STAC-ML.Markets.Inf.T.LSTM_C.16.LAT.v1
- STAC-ML.Markets.Inf.T.LSTM_A.2.LAT.v1
- STAC-ML.Markets.Inf.S.LSTM_A.[1,2,4].TPUT.v1
- STAC-ML.Markets.Inf.S.LSTM_B.[1,2,4].TPUT.v1
- STAC-ML.Markets.Inf.S.LSTM_C.[1,2,4].TPUT.v1
- 數據由 Deutsche B ? rse 提供
- STAC-ML.Markets.Inf.S.LSTM_A.[1,2,4].SPACE_EFF.v1
- STAC-ML.Markets.Inf.S.LSTM_B.[1,2,4].SPACE_EFF.v1
- STAC-ML.Markets.Inf.S.LSTM_C.[1,2,4].SPACE_EFF.v1
?