
政府、企業和學術界的量子算法研究人員有興趣在越來越大的量子系統上開發和測試新的量子算法。用例包括藥物發現、網絡安全、高能物理和風險建模。
然而,這些系統仍然很小,質量仍有待提高,容量有限。因此,在量子電路模擬器上開發應用程序和算法是很常見的。
NVIDIA cuQuantum 是一個軟件開發工具包( SDK ),使用戶能夠使用 GPU 輕松加速和縮放量子電路模擬。一種 計算狀態向量的自然工具 ,它使用戶能夠模擬比現在的量子計算機更深(更多的門)和更寬(更多的量子比特)的量子電路。
cuQuantum 包括最近發布的 NVIDIA cuQuantum Appliance ,這是一個具有多 GPU 、多節點狀態向量仿真支持的部署就緒軟件容器。 NVIDIA cuStateVec 中也提供了通用的多 GPU API ,可輕松集成到任何模擬器中。
對于張量網絡模擬, cuQuantum cuTensorNet library 提供的切片 API 支持分布在多個 GPU 或多個節點上的加速張量網絡收縮。現在還提供了一個更高級別的 API ,使多節點更容易實現,使用戶可以利用 NVIDIA A100 系統,實現近乎線性的強大擴展。
本文將深入探討 NVIDIA cuQuantum Appliance 的多節點狀態向量模擬。有關相關信息,請參見 Achieving Supercomputing-Scale Quantum Circuit Simulation with the NVIDIA cuQuantum Appliance 。
ABCI 2.0 超級計算機上 cuQuantum 設備的功能
去年, NVIDIA 參加了 AI Bridging Cloud Infrastructure (ABCI) 大型挑戰賽,以測試多節點 cuQuantum 設備的功能及其系統配置。 ABCI 是由日本國家先進工業科學技術研究所( AIST )主辦的超級計算機。
截至 2022 年 11 月, ABCI 2.0 在 TOP500 list 排名第 22 位,以每秒 22.21 PB 的速度執行高性能 Linpack ( HPL )基準測試。截至 2022 年 11 月,該超級計算機在 Green500 list 上排名 32 ,每瓦 21.89 千兆次。
ABCI system 由 1088 個計算節點組成,其中包括 4352 個 NVIDIA V100 GPU (稱為“計算節點( V )”),以及 120 個計算節點,其中包括 960 個 A100 GPU (稱為”計算節點( A )“)。 NVIDIA cuQuantum 團隊與 NVIDIA Ampere 架構節點合作,測試了一系列電路,以及一系列精度的解決方案精度。
ABCI 計算節點( A ) GPU 系統為 NVIDIA A100 40 GB ,每個節點 8 GPU ,第三代 NVLink 。它們的理論峰值為 19.3 PB ,理論峰值內存帶寬為 1555GB / s 。節點與 InfiniBand HDR 連接。
ABCI 計算節點上的量子計算性能基準( A )
運行了與應用研究和量子計算機基準測試相關的三種常用算法。
這三個基準利用了多節點 cuQuantum 設備:量子體積、量子近似優化算法( QAOA )和量子相位估計( QPE )。量子體積電路的深度為 10 ,深度為 30 。 QAOA 是一種常用的算法,用于解決組合優化問題,例如在相對較短的量子計算機上進行路由和資源優化。
NVIDIA 運行 QAOA , p = 1 。 QPE 是許多容錯量子算法的關鍵子例程,具有廣泛的應用,包括 Shor 的因子分解算法和一系列化學計算,如分子模擬。所有三種常見的量子算法都證明了弱縮放(圖 1 和圖 2 )。
此外,用量子體積檢驗了強縮放(圖 3 和圖 4 )。 cuQuantum 設備有效地將 ABCI 計算節點( A )變成了完美的 40-41 量子比特量子計算機。很明顯,擴展到像 ABCI 這樣的超級計算機對于加快解決時間和擴展研究人員可以利用狀態向量量子電路模擬技術探索的相空間都很有價值。
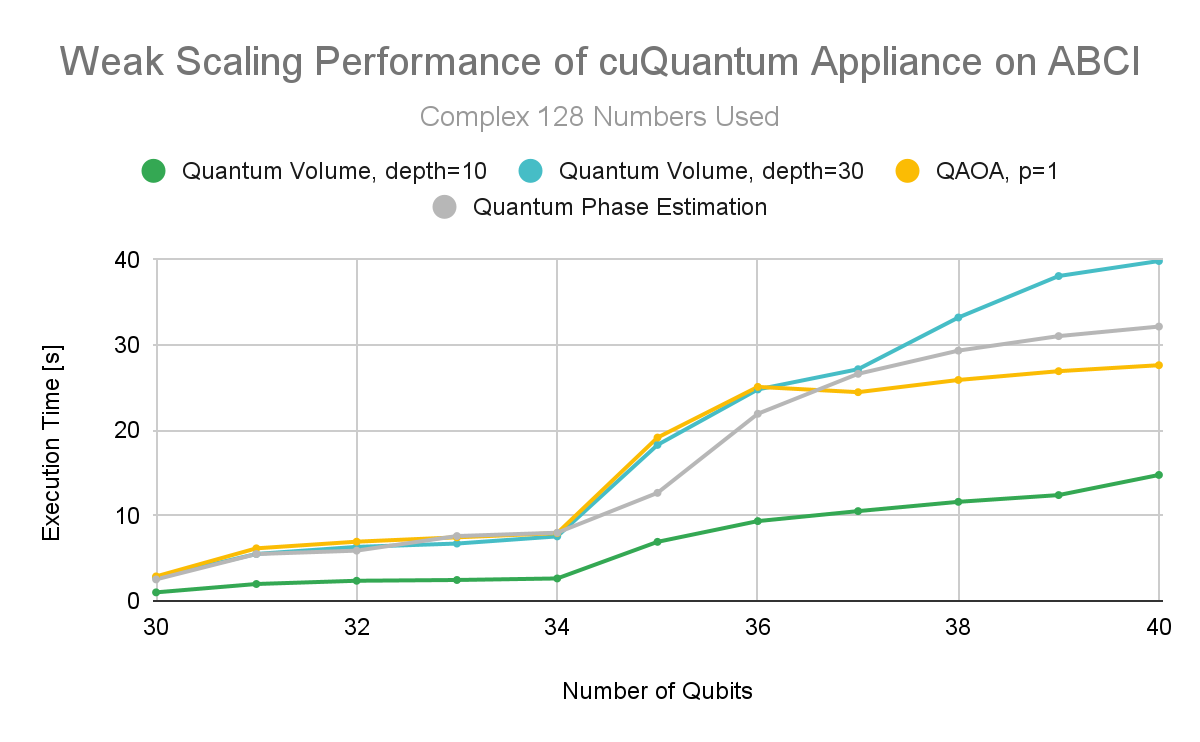
測試目標之一是比較復雜 128 ( c128 )和復雜 64 ( c64 )實現之間的差異。當降低精度時,結果表明可以為額外的量子位使用更多的內存。然而,重要的是要確認,降低的精度并不是以從模擬中產生有用結果為代價實現的。該實驗使用量子相位估計 calculate the number pi ,其測量到 16 位并匹配。
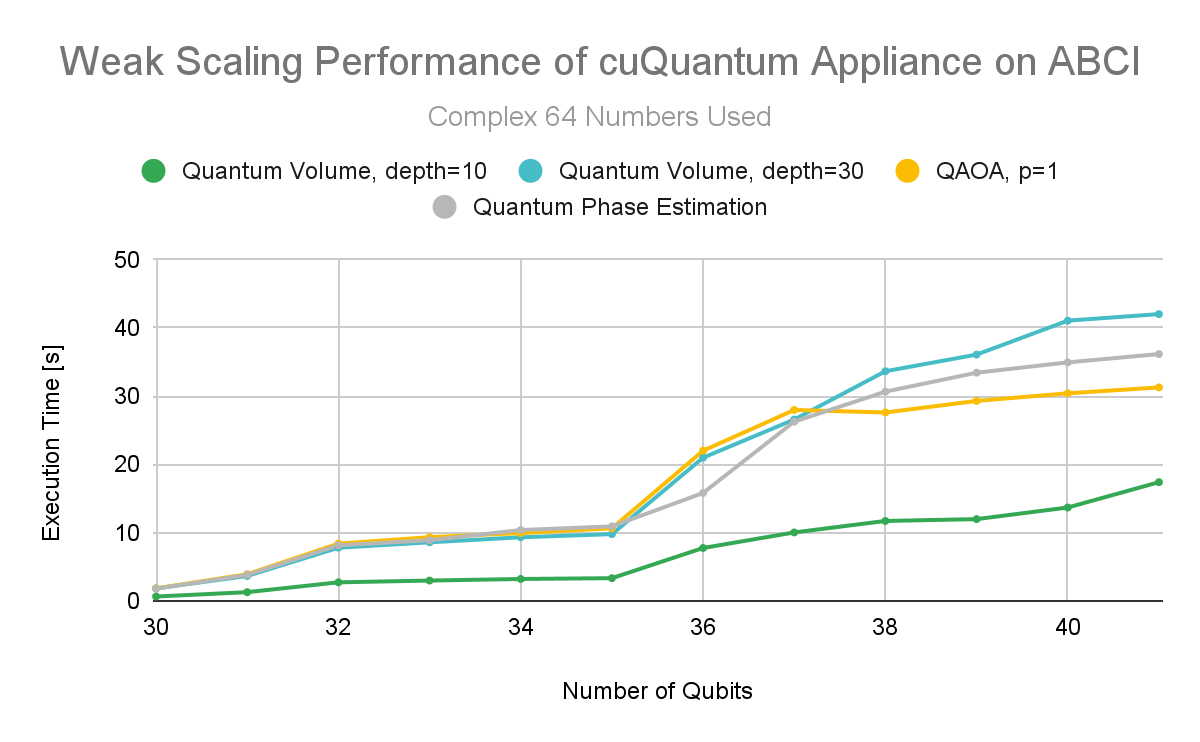
測試結果表明,由于精度較低,縮放性能較差。 cuQuantum Appliance 用戶可以期望利用較低的精度,并確信性能和精度受到的影響最小。
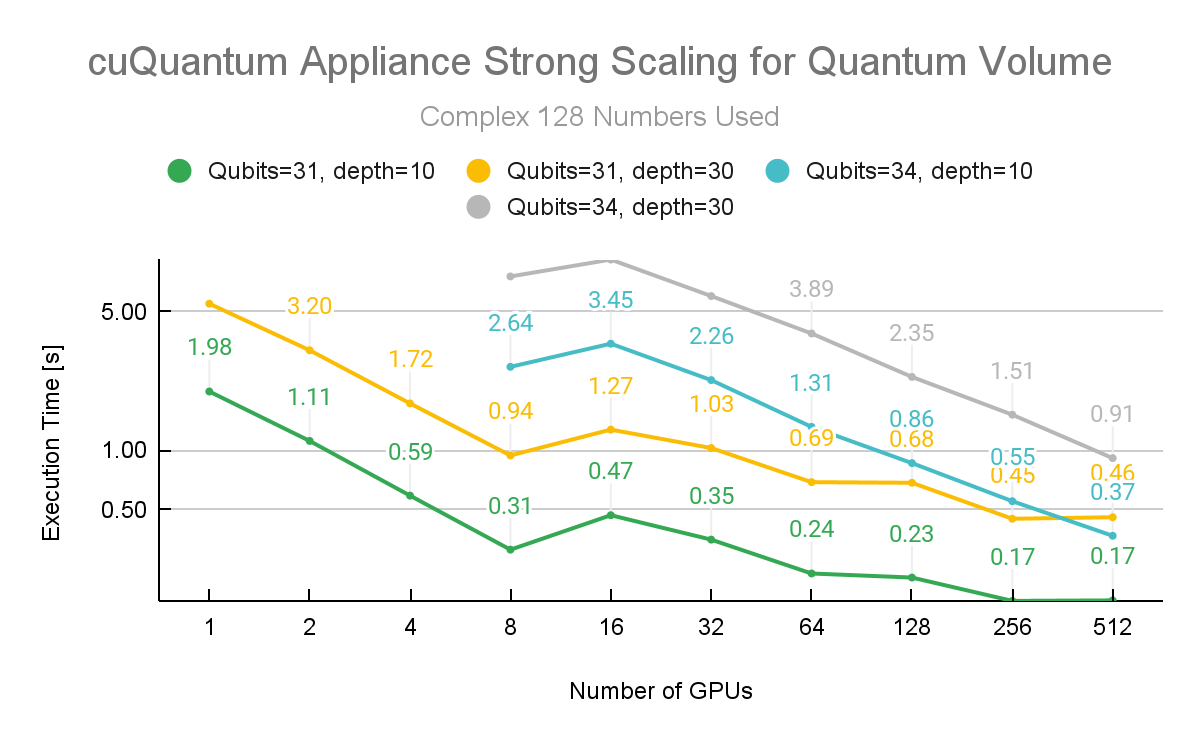
進行了其他測量,以測試 cuQuantum Appliance 多節點功能的強大擴展性。這些數字是用深度 10 和深度 30 的量子體積電路生成的。這兩個結果都是針對 31 和 34 量子位量子體積測量的。
圖 3 顯示了使用增量 GPU 和復雜 128 精度時的性能指標。很明顯,擴展到多個節點可以節省一系列問題大小的時間。
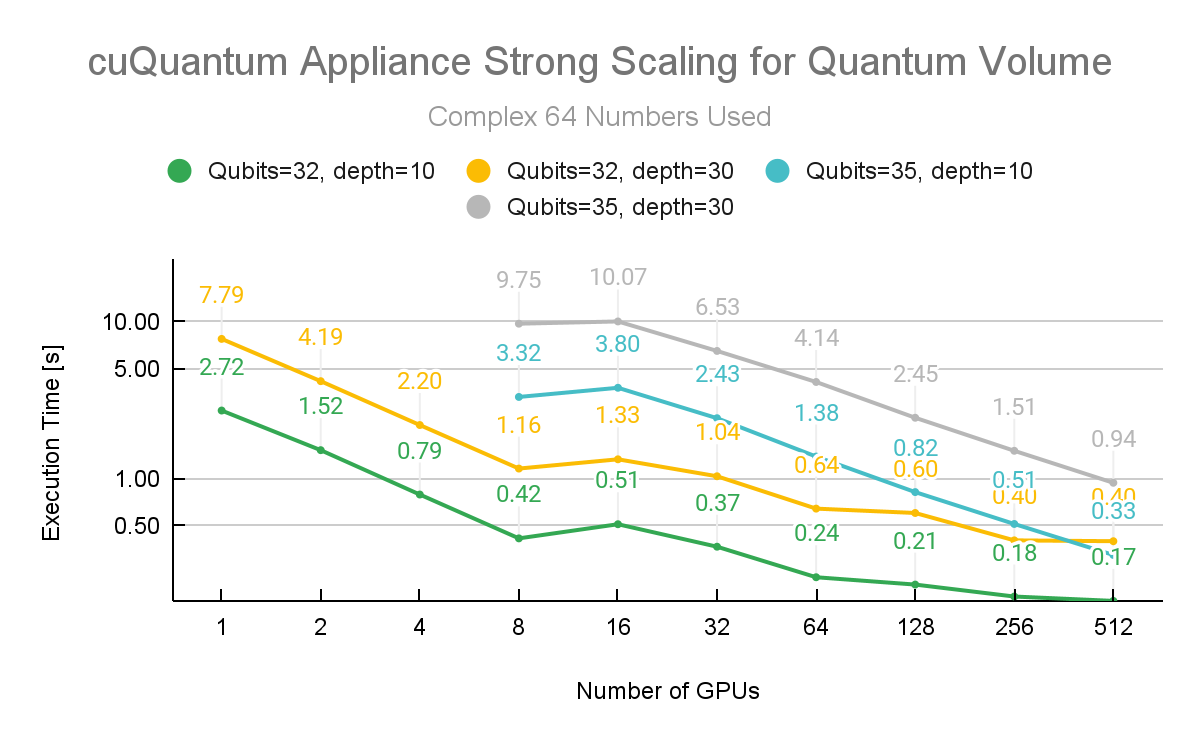
NVIDIA cuQuantum 團隊進行了額外的實驗,改變了圖 4 所示的精度。該圖顯示了量子體積在深度 10 和深度 30 處再次運行。在本例中,模擬保持在 32 和 35 個量子位,并分布在 ABCI 計算節點( A )上的 512 個 NVIDIA A100 40GB GPU 上。
執行時間從 8 跳到 16 GPU 與將工作負載分配到兩個節點而不是一個節點的額外初始化開銷有關。當將節點縮放到任意大的數量時,這一成本很快就會被分攤。
比較 cuQuantum 設備性能
用戶可以使用更新的 NVIDIA cuQuantum 設備實現規模化。 cuQuantum 基準測試總共運行了 40 個量子位, 64 個 A100 40 GB 節點。然而,用戶僅限于可訪問的數量 GPU 。現在可以輕松縮放模擬,無需更改現有 Qiskit 代碼,并且比沒有 cuQuantum Appliance 的先前實現快 81 倍。
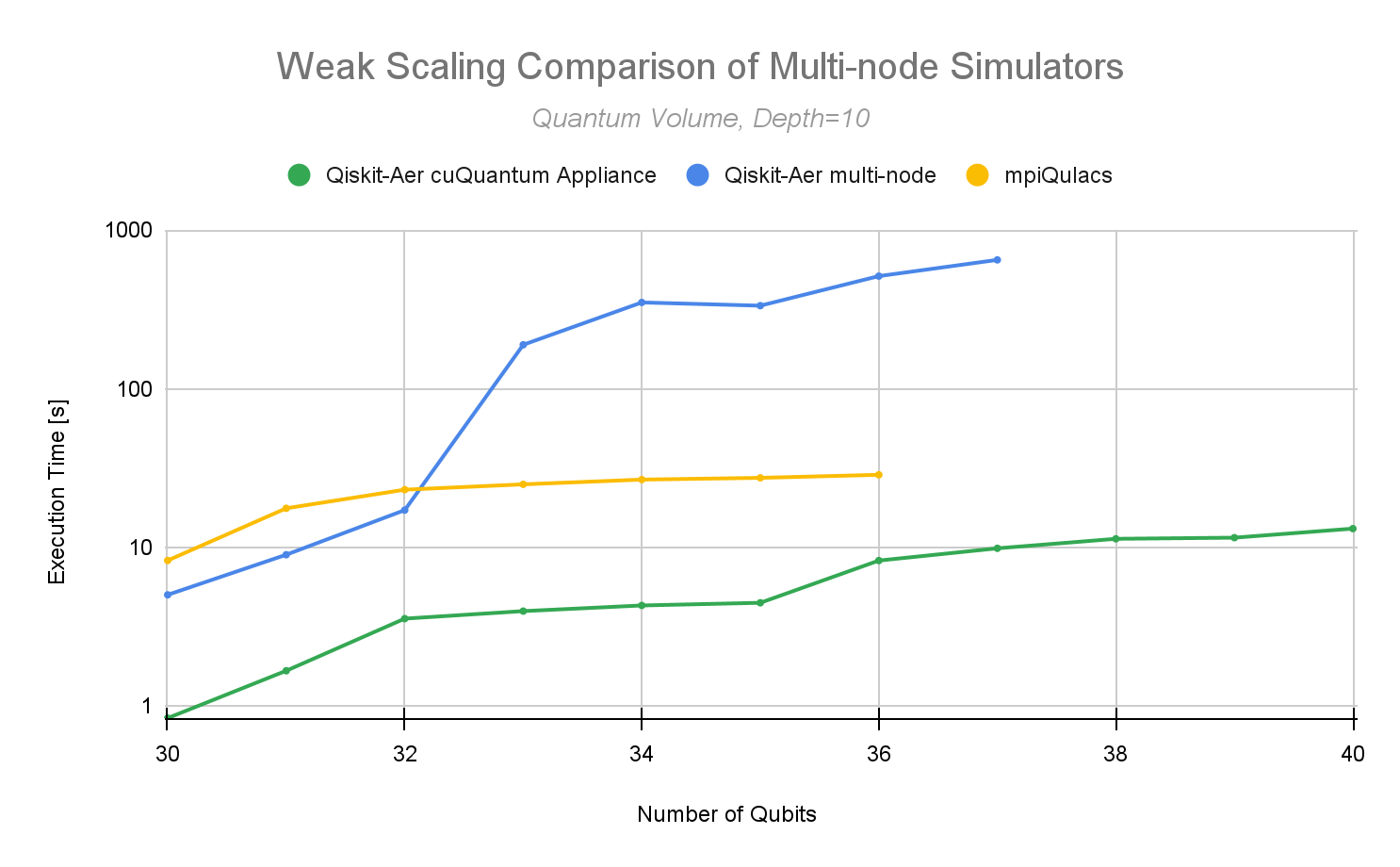
NVIDIA 還與名為 mpiQulacs 的非常快速的多節點全狀態矢量量子電路模擬器進行了對比。這是一個令人印象深刻的模擬器,它是為在富士通 A64FX CPU 架構上運行而開發的。 2022 年 3 月,他們宣布了多節點模擬器在量子體積深度為 10 、量子比特數為 36 的情況下的性能結果。 NVIDIA cuQuantum 設備現在使用戶可以在 ABCI 2.0 超級計算機上使用 c128 擴展到 40 個量子位,或使用 c64 擴展到 41 個量子位數,具有同類最佳性能。
對 NVIDIA Hopper GPU 進行的其他初步測試表明,使用新的 NVIDIA H100 GPU , cuQuantum Appliance 多節點性能數字將比此處顯示的結果提高約 2 倍。
NVIDIA 的 cuQuantum 團隊正在大規模加速狀態向量模擬。 cuQuantum 實現了規模化和同類最佳性能,顯示了節點間的弱伸縮性和強伸縮性。此外,先前宣布的結果已經在 AIST ABCI 2.0 超級計算機上進行了外部驗證,顯示了不同 HPC 基礎設施的通用性。
NVIDIA 還推出了第一個 cuQuantum 驅動的 IBM Qiskit 圖像。如今,用戶可以拉動這個容器,從而更容易、更快地使用這個流行的框架來擴展量子電路模擬。
cuQuantum 團隊已經開始將這些多節點 API 帶給更廣泛的開發者,并將在下一個 cuQuantum 版本中包含這些 API 。
開始使用 cuQuantum 設備
多節點 cuQuantum 設備現已上市。您可以直接從 NGC catalog for containers 訪問它。要請求功能或報告錯誤,請聯系 GitHub 上 NVIDIA/cuQuantum 的 cuQuantum 團隊。
其他資源
- cuQuantum Documentation
- Lightning Fast Simulations with Pennylane and the NVIDIA cuQuantum SDK
- Orquestra Integration with NVIDIA cuQuantum
- NVIDIA cuQuantum and QODA Adoption Accelerates
- A Deep Dive into the Latest HPC Software
- Defining the Quantum-Accelerated Supercomputer
- Scaling Quantum Circuit Simulations with cuQuantum for Quantum Algorithms
- Quantum Computing Simulation in Pharmaceuticals Research
- Accelerating Quantum Computing Research with GPUs
- AI for Science: Heralding Scientific Breakthroughs through AI
?





