

?
這篇文章根據我們迄今為止在游戲中使用 NVIDIA RTX 光線追蹤的經驗,收集了最佳實踐。我將這些技巧組織成簡短的、可操作的項目,為今天從事光線跟蹤工作的開發人員提供實用的技巧。他們的目標是提供一個在大多數情況下什么樣的解決方案可以帶來良好的性能。為了找到針對特定情況的最佳解決方案,我總是建議進行分析和試驗。
以下是簡短的縮寫:
- 作為 — 加速結構
- TLAS 公司 – 頂層加速結構
- 布拉斯 ——底層加速結構
- AABB 。 – 軸對齊邊框
- 實例 -TLAS 中 BLAS 的實例
- 幾何學 —一個幾何體和一個 BLAS
加速度結構
這是帖子中兩個主要部分的第一部分。它側重于光線跟蹤加速結構的構建和管理,這自然是將光線跟蹤用于任何目的的起點。
- 一般提示
- 構建時最大化 GPU 利用率
- 內存分配
- 將幾何圖形組織成 BLASE
- 生成首選項標志
- 動態布拉斯
- 非不透明幾何體
- 粒子
一般提示
考慮 AS building 的異步計算。 特別是在混合渲染中, G-buffer 或陰影貼圖被柵格化,在異步計算的基礎上執行是非常有益的。
考慮生成命令列表時使用的工作線程。 生成為建筑命令可能包括大量的 CPU 邊工作,比如對象的剔除。將其移動到一個或多個工作線程可能是有益的。
通常,包括 VZX54 在內的整個場景不是最佳的。相反,根據情況挑選實例。例如,考慮基于展開的攝影機視錐體進行剔除。在光柵化中,最大距離通常小于遠平面距離。也可以在剔除時考慮實例大小,以便在較短距離內剔除較小的實例。
對實例使用適當的 LOD 。 與光柵化一樣,使用最詳細的幾何體 LOD 通常是次優的。用于遠距離對象的 LOD 可以更簡單。在混合渲染中,可以考慮使用相同的 LOD 進行光柵化和光線跟蹤。這是避免自相交偽影(如曲面陰影本身)的有效方法。在光線追蹤中也可以考慮使用較低細節細節的細節細節細節,特別是為了降低動態 BLAS 的更新成本。如果光柵化和光線跟蹤之間的細節層次不匹配,在光線跟蹤中通常需要啟用背面消隱以防止自相交。有關光線跟蹤中 LOD 的更多討論,以及如何實現隨機 LOD 的解釋,請參見 使用 Microsoft DirectX 光線跟蹤實現隨機細節級別 。
盡可能將幾何圖形或實例標記為不透明。 將實例或幾何體標記為不透明,允許不間斷的硬件交叉點搜索,并防止調用任何命中著色器。盡可能這樣做。僅對需要的幾何體啟用任何命中著色器;例如,執行 alpha 測試。
盡可能使用三角形幾何圖形。 硬件在執行光線三角形相交方面表現出色。光線盒相交也會加速,但在跟蹤三角形幾何體時,可以最大限度地利用硬件。
構建時最大化 GPU 利用率
批處理頂點變形和 BLAS 生成。 連續執行生成三角形的所有頂點變形調用,這些三角形用作 BLAS building 的輸入,以及所有 BLAS build 調用。不要在連續呼叫之間設置資源屏障。這允許驅動程序在一定程度上并行化調用。所有的 BLAS 構建調用都需要唯一的暫存內存,以允許無障礙地執行。此外,不需要為每個資源持有 BLAS 設置單獨的 UAV 屏障。相反,您可以在 TLAS 構建之前擁有一個全球 UAV 屏障,以確保所有 BLAS 構建完成,而不管它們駐留在何處。
考慮合并小頂點變形調用。 通常,為一個幾何體或實例輸出變形頂點的調用是輕量級的,即使在連續調用之間沒有屏障的情況下也不會填充整個 GPU 。在一個調用中合并多個幾何體或實例的處理可以提高 GPU 的利用率并產生更好的性能。
內存分配
集中小額撥款。 blas 可以很小,有時只有幾 KB 。使用單獨的提交資源來存儲每個這樣小的 bla 不是最佳的。相反,將它們與更大的資源集中在一起。池可以節省內存,而且通常還可以提高性能。一種選擇是在大型資源堆中使用放置的資源。或者,只需從緩沖區手動分配部分,就可以將許多 blas 存儲在單個緩沖區中。這使得 BLASE 更緊密地備份到內存中,因為子分配只需要遵循 256 字節的對齊方式。不管采用何種池機制,都要避免內存碎片化,以保持池的好處。
釋放或不分配關鍵路徑上的資源。 資源分配 API 調用的成本可能變化很大,有時會非常高,導致明顯的結巴。避免結巴的可靠方法是將調用從關鍵路徑(即呈現線程)移到工作線程。這適用于分配和取消分配,即對創建的對象執行 CreateCommittedResource 和 CreateHeap 、 vkAllocateMemory 調用以及 Release 和 vkReleaseMemory 調用。呈現線程不應該等待線程進行分配調用。
考慮壓縮靜態 blas 。 壓縮 blas 可以節省內存并提高性能。內存消耗的減少取決于幾何結構,但最多可達 50% 。由于在 GPU 上完成 BLAS 構建后,需要將壓縮后的大小讀回 CPU ,因此對于只構建一次的 BLAS 來說,這是最實際的做法。記住,要集中小的分配并避免內存碎片,以便從壓縮中獲得最大的好處。
將幾何圖形組織成 BLASE
當實例的世界空間 AABB 中有很多空白空間時,請考慮拆分 BLAS 。 World space AABBs 用于測試光線是否可能命中實例并遍歷其關聯的 BLAS 。大量的空白空間會導致不必要的穿越 BLAS 。通常是他們自己的幾何體。將它們合并到一個單獨的 BLAS 中很容易導致 AABB 具有大量的空白空間,并且可能導致不必要的 BLAS 重建,而不是簡單地改變獨立實例的轉換。
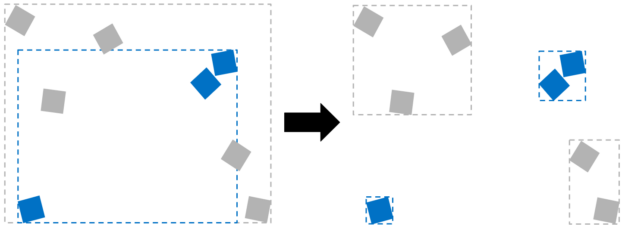
當實例世界空間 AABBs 明顯重疊時,考慮合并 blas 。 當實例的世界空間 AABBs 重疊時, TLAS 變得不最優。然后,光線可以在空間中的卷中命中多個實例。然后需要遍歷所有這些實例的 BLASes 以解決最近的命中。通過一個合并的 BLA 將更有效。針對 BLA 跟蹤性能不取決于其中的幾何圖形數。合并到單個 BLA 中的幾何圖形仍然可以擁有獨特的材質。
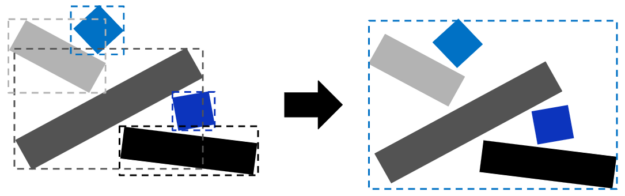
盡可能實例化 blase 。 實例化 BLASes 可以節省內存。它還可以提高光線跟蹤性能。實例可以具有獨特的材質和變換。在實例的 AABBs 重疊很多的情況下,盡管增加了內存消耗,但是作為多個幾何體復制并合并到單個 BLAS 中仍然是一個更好的選擇。
避免在幾何圖形中拉長三角形。 長 , 薄三角形具有非最優邊界體積,且有大量的空空間。它們很容易與許多其他邊界卷重疊。這導致在跟蹤光線時,與幾何體相對應的性能不最佳。驅動程序可以根據幾何圖形在一定程度上緩解問題。第一個這樣的三角形不可能引起問題,但是太多的三角形確實會導致問題,所以我建議盡可能避免它們,例如將它們分割成更小的三角形。
不要在 TLA 中包含天空幾何體。 一個 skybox 或 skysphere 將有一個與其他所有東西重疊的 AABB ,所有光線都必須根據它進行測試。對于表示天空的幾何體,在 miss 著色器中而不是在 hit 著色器中處理天空著色更為有效。
生成首選項標志
對于 TLA ,請考慮 PREFER_FAST_TRACE 標志并僅執行重建。 通常,這會產生最佳的整體性能。其基本原理是,使 TLA 盡可能高質量,而不考慮場景中發生的運動,這一點很重要,而且成本不會太高。
對于靜態 blas ,請使用 PREFER_FAST_TRACE 標志。 對于只構建一次的所有 blas ,優化最佳光線跟蹤性能是一個簡單的選擇。
對于動態 blas ,請選擇使用 PREFER_FAST_TRACE 或 PREFER_FAST_BUILD 標志,或兩者都不使用。 對于偶爾重建或更新的 blase ,最佳構建首選標志取決于許多因素。建造了多少?射線痕跡有多貴?是否可以通過在異步計算上執行構建來隱藏構建成本?為了找到特定情況下的最佳解決方案,我建議嘗試不同的選擇。
動態布拉斯
盡可能重復使用舊的 BLAS 。 每當您知道 BLAS 的頂點在上一次更新后沒有移動,請繼續使用舊的 BLAS 。
僅更新可見對象的 BLAS 。 當從 tla 中剔除實例時,也要將它們剔除的 BLAS 從 BLAS 更新過程中排除。
根據大小考慮跳轉。 有時不需要在每一幀上更新 BLAS ,這取決于它在屏幕上的大小。可以跳過一些更新而不引起明顯的視覺錯誤。
在大變形后重建 blas 。 BLAS 更新是有限變形后的一個不錯的選擇,因為它們比重建要便宜得多。但是,上一次重建后的大變形可能導致光線跟蹤性能不理想。拉長的三角形放大了這個問題。
考慮定期重建更新的 blas 。 當幾何體變形過大,需要重建以恢復最佳光線跟蹤性能時,可以很容易地進行檢測。簡單地周期性地重建所有 blas 是一種合理的方法,可以避免顯著的性能影響,而不考慮變形。
在框架上分布重建。 由于重建比更新慢得多,因此在單個幀上進行多次重建會導致結巴。為了避免這種情況,一個好的做法是在框架上分布重建。
考慮僅使用具有不可預測變形的重建。 在某些情況下,當幾何體變形足夠大且足夠快時,在構建 BLAS 時省略 ALLOW_UPDATE 標志并始終重建它是有益的。如果需要,可以考慮使用 PREFER_FAST_BUILD 標志來降低重建成本。在極端情況下,與使用 PREFER_FAST_TRACE 標志和更新相比,使用 PREFER_FAST_BUILD 標志可以獲得更好的總體光線跟蹤性能。
vz8 中的拓撲更新意味著三角形的更新。如果退化三角形的位置不代表恢復的三角形的位置,則可能導致非最佳光線跟蹤性能。“彎曲”變形中偶爾發生的拓撲變化通常不會有問題,但“破壞”變形中的較大拓撲變化可能會出現問題。如果可能的話,最好使用單獨的 BLAS 版本,或者對“破壞性”變形導致的不同拓撲使用非活動三角形。當三角形的位置為 NaN 時,該三角形處于非活動狀態。如果這些替代方案不可行,我建議重新構建 BLAS ,而不是在拓撲更改后進行更新。在更新中不允許通過索引緩沖區修改進行拓撲更改。
非不透明幾何體
盡可能減少非不透明區域。 對非不透明三角形調用任何命中著色器(通常用于執行 alpha 測試)會中斷硬件交集搜索。如果可能,最小化未標記為不透明的區域是提高性能的簡單方法。使用更多的三角形來更精確地定義非不透明區域可能是一個很好的折衷方案。
考慮拆分為不透明和非不透明幾何體。 當一個定義良好的幾何體三角形部分可以被視為完全不透明時,可以考慮將其拆分為單獨的幾何體并將其標記為不透明。不同的幾何圖形仍然可以駐留在同一個 BLA 中。
粒子
考慮將公告牌粒子表示為三角形幾何體。 在 BLASes 中表示廣告牌粒子的一個選項是將廣告牌輸出為三角形,將廣告牌的一部分沿垂直軸旋轉 90 度,使其朝向不同的方向。這允許使用三角形相交硬件,同時為粒子的視覺邊界提供合理的近似值。有關更多信息,請參閱 “它就是能操作”:光線跟蹤反射在“戰場五號” , 2019 年游戲開發者大會。
考慮阿爾法測試而不是混合。 根據粒子類型,在二次光線中對渲染主可見性時混合的粒子進行 alpha 測試可以提供合理的視覺質量。這種方法最適用于邊界清晰的粒子。對于代表煙或霧的粒子,這可能不適用。有關詳細信息,請參閱 “沃爾芬斯坦:揚布拉德”中的光線追蹤反射 。
避免對死粒子使用退化三角形。 更新 BLASes 中的退化三角形會使結構不適合光線跟蹤。對于具有動態數量活動粒子的粒子系統,我建議考慮其他解決方案,例如用正確的粒子數在每個幀上重建 BLAS 。
考慮將網格粒子表示為 TLA 中的實例。 對于渲染為三角形網格的粒子,為每個粒子創建一個唯一的實例可能是一個合理的解決方案。當粒子分布在場景周圍,因此單個光線通常不會命中多個實例時,這是正確的。實例應共享基礎網格 BLAS 。另外,考慮壓縮 BLAS 。
命中底紋
這篇文章的這一部分主要討論光線命中的陰影。即使是經驗豐富的圖形開發人員在開始開發光線跟蹤著色器時也可能從新的想法中受益,因為最佳解決方案可能與光柵化中的不同。
- 一般提示
- 最小化發散
- 任何命中著色器
- 著色器資源綁定
- 內聯光線跟蹤( DXR 1 . 1 )
- 管道狀態
一般提示
保持射線有效載荷小。 寄存器用于保存有效負載值,它們會減少命中著色器可用的寄存器數量。我建議避免粗心地使用有效負載,盡管向打包值添加復雜的代碼很少有益。
考慮向未使用的有效負載字段寫入一個安全的默認值。 當某些著色器不使用負載中的所有字段(其他著色器需要這些字段)時,仍然向未使用的字段寫入一個安全的默認值是有益的。這允許編譯器丟棄未使用的輸入值,并在寫入有效負載寄存器之前將其用于其他用途。
如果可能,在第一次命中時終止射線。 當不需要解析正確的最近命中時,例如對于陰影光線,使用 RAY_FLAG_ACCEPT_FIRST_HIT_AND_END_SEARCH 或 gl_RayFlagsTerminateOnFirstHitNV 標記光線是一種簡單而有效的優化。
只有在需要正確性時才使用面剔除。 與柵格化不同,啟用背面或正面剔除不會提高性能。相反,它會稍微減慢光線的遍歷速度。僅當需要獲得正確的渲染結果時才使用它們。
最小化光線跟蹤調用的活動狀態。 變量在 TraceRay 或 traceNV call 之前初始化并在其處于活動狀態之后使用,在調用命中著色器時需要在調用期間保持該狀態。司機有幾個不同的選擇,但他們都有成本。我建議盡量減少活動狀態的數量。識別這些變量并不總是小事。 NVIDIA 和微軟正在合作開發一種編譯器功能,用于自動檢測活動狀態。
避免深度遞歸。 深度的、非均勻的光線遞歸會很昂貴。
最小化發散
考慮統一的命中著色,但避免使用übershaders 。 當材質模型允許時,考慮統一各種幾何體的著色,以允許使用常見的命中著色器。通常,減少命中著色器中的代碼和數據分歧是有幫助的。尤其要避免手動在材質模型之間切換的übershaders 。當需要不同的材質模型時,我建議在單獨的 hit 著色器中實現每個模型。這給了系統最好的可能性來管理不同的命中陰影。
考慮簡化著色。 通常,不需要復制渲染主可見性中用于著色鏡面反射或間接漫反射照明的所有功能。忽略特征并不總是會導致顯著的視覺差異,或者視覺改進并不能證明渲染成本的合理性。光線越不相干,通常需要的主要可見性特征的復制就越不精確。此外,隨著命中距離的增加,陰影有時可以更簡化。
避免從頂點和像素著色器直接轉換。 在命中著色中獲得最佳性能的方法與光柵化的最佳方法不同。在光柵化中,即使是很小的代碼差異,也可以使用單獨的著色器置換。在命中著色中,減少單個命中著色器內的散度和單獨命中著色器的數量都很有幫助。通常,我不建議直接將頂點和像素著色器轉換為命中著色器。
考慮將通用代碼移到命中和未命中著色器之外。 當所有命中著色器都有一個公共部分時,我建議將該代碼從命中著色器移到光線生成著色器,例如。有時,在命中著色器和未命中著色器中也可能存在公用代碼,例如,命中著色器中下一次反彈的近似值與未命中著色器中第一次反彈的近似值相同。同樣,我建議將該通用代碼移到命中和未命中著色器之外。
任何命中著色器
喜歡統一和簡化任何命中著色器。 在光線遍歷過程中,任何命中著色器都可能執行大量操作,它會中斷硬件交叉點搜索。任何命中著色器的成本都會對整體性能產生顯著影響。我建議在光線跟蹤過程中使用統一和簡化的任何命中著色器。另外, GPU 的全部寄存器容量對于任何命中著色器都不可用,因為驅動程序會消耗部分寄存器容量來存儲光線狀態。
優化對材料數據的訪問。 在任何命中著色器中,對材質數據的最佳訪問通常至關重要。一系列依賴內存訪問是一種常見的模式。加載頂點索引、頂點數據和采樣紋理。如果可能,從該路徑中刪除間接尋址是有益的。
混合時,記住未定義的命中順序。 沿著光線的命中被發現,相應的任何命中著色器調用都以未定義的順序發生。這意味著混合技術必須與順序無關。這也意味著,要排除最近不透明命中之外的命中,必須適當限制光線距離。此外,您可能需要用 NO_DUPLICATE_ANYHIT_INVOCATION 標記混合幾何體,以確保結果正確。有關詳細信息,請參閱 光線追蹤寶石 中的第 9 章。
著色器資源綁定
如果可能,首選全局根表( DXR )或直接描述符訪問( Vulkan )。 通常,光線生成和未命中著色器使用的資源可以像計算著色器那樣方便地綁定,而不是通過著色器記錄進行綁定。此外,不管命中了什么,都可以像這樣綁定命中著色器資源。在所有命中記錄中使用相同的資源不是最佳的。
請考慮命中著色器的無綁定資源。 無限描述符表( DXR )或無大小描述符數組( Vulkan )中的資源,由特定于命中的系統值(如 InstanceIndex 或 gl_InstanceID 或直接存儲在命中記錄中的值( DXR 中的根常量)編制索引,可以有效地為命中著色器提供資源。
考慮索引和頂點緩沖區的根描述符。 ( DXR ) 作為無界描述符表的替代方法,直接將索引和頂點緩沖區地址作為根描述符存儲在命中記錄中是非常有效的。當通過根描述符訪問資源時,不會隱式執行越界檢查。根描述符地址必須遵循 4 字節對齊方式。預先計算到基地址的 16 位索引的偏移量可能會中斷對齊。
盡可能使用根簽名版本 1 . 1 和靜態描述符。 ( DXR ) 根簽名 1 . 1 允許驅動程序期望描述符是靜態的;也就是說,在命令列表被記錄之后,它們不會被應用程序修改。這將在驅動程序中啟用一些潛在的有益優化,特別是當根描述符不用于訪問緩沖區時。與根描述符一樣,不隱式地使用靜態描述符執行越界檢查。此外,靜態描述符和根描述符都不能為 null 。
不要使用無人機進行只讀訪問。 當著色器僅對給定資源執行讀取操作時,將其綁定為 UAV 不會提供最佳性能。
考慮在 GPU 上構造著色器。 當有許多幾何體和許多光線跟蹤過程時,命中表可能會變大,上載它們會消耗大量時間。不是上傳在 CPU 上構建的整個命中表,而是只在每個幀上上載所需的新信息,例如當前可見實例的材質索引,然后在 GPU 上執行命中表構造過程以提高效率。表構造所需的大部分信息可以永久地駐留在 GPU 內存中,例如命中組標識符、頂點緩沖區地址和幾何圖形的偏移量。
內聯光線跟蹤( DXR 1 . 1 )
使用統一的命中著色與內聯光線跟蹤。 由于命中著色器不是基于命中調用的,因此所有著色都在投射光線的著色器中內聯進行。這意味著應用經典著色器優化實踐。我強烈建議使用統一的 hit shading ,它允許使用一個公共代碼路徑處理不同的幾何圖形,并避免使用大量發散代碼的übershader 。當需要多個不同的著色模型時,我建議使用 DispatchRays 。
使用特定于命中的系統值來訪問具有內聯光線跟蹤的無綁定資源。 由于命中記錄中的綁定不可用,必須通過其他方式提供特定于幾何體的綁定。基于特定于命中的系統值(如 InstanceContributionToHitGroupIndex 和 GeometryIndex )訪問無界描述符表中的資源是一個很好的實踐。我建議盡可能避免間接訪問索引、頂點和材質數據。例如,根據系統值(如 InstanceID 從緩沖區讀取資源索引以選擇索引緩沖區可能會導致難以隱藏的延遲。
首選編譯時光線標志。 編譯時和運行時光線標志都可以與內聯光線跟蹤一起使用。我建議盡可能使用編譯時標志,因為它們可以實現有益的編譯時優化。
監視查詢對象的寄存器使用情況。 初始化后,當著色器執行可能繼續遍歷的代碼時,查詢對象必須保持光線遍歷的狀態。這會消耗寄存器,復雜的用戶代碼可能會比通常更快地限制占用。這種情況類似于在 DispatchRays 過程中執行任何命中著色器。在使用查詢對象之前初始化并在之后使用的變量可能會消耗額外的寄存器。
考慮重新排序線程組以提高一致性。 從計算著色器使用內聯光線跟蹤時,將調度線程組的默認行主分配給 GPU 執行通常不會產生最佳性能。通過手動重新排序線程組,可以提高線程組在 GPU 上同時執行的內存訪問的一致性。有關重新排序的詳細信息,請參見 使用線程組 ID 切換優化 L2 位置的計算著色器 。
管道狀態
考慮每個光線生成著色器一個狀態對象。 我建議為每個 DispatchRays 或 vkCmdTraceRaysNV 調用使用該過程中所需的著色器編譯一個單獨的 state 對象。它有助于優化寄存器消耗,并允許對本文后面描述的管道配置值進行優化設置。
將 MaxTraceRecursionDepth 、 MaxRecursionDepth 、 MaxPayloadSizeInBytes 和 MaxAttributeSizeInBytes 設置為盡可能小。 將這些值設置為高于所需的值可能會對性能產生不必要的負面影響。在 DispatchRays 或 vkCmdTraceRaysNV 調用中使用內聯光線跟蹤時,這些光線跟蹤調用不計入最大遞歸深度。
盡可能使用 SKIP_PROCEDURAL_PRIMITIVES 和 SKIP_TRIANGLES 。 ( DXR 1 . 1 )這些管道狀態標志允許在狀態編譯中進行簡單但可能有效的優化。
避免在關鍵路徑上創建狀態對象。 狀態對象編譯可能很慢。因此,請預先創建狀態對象;例如,在級別加載期間或在工作線程上異步創建狀態對象。
考慮使用著色器集合進行并行編譯和共享。 ( DXR ) 管理多個著色器時,著色器集合可能允許多線程編譯狀態對象并在狀態對象之間共享已編譯代碼。有關詳細信息,請參見 光線跟蹤管道狀態的并行著色器編譯 。
當需要自動指定綁定點時,請考慮編譯器選項。 ( DXR )默認情況下,編譯著色器庫時不使用著色器資源的自動綁定點分配。如果需要的話,有幾個有用的編譯器選項。首先, /auto-binding-space 在給定的寄存器空間中啟用自動綁定點分配。此外,默認情況下,所有沒有用關鍵字 static 標記的函數都被視為庫導出。使用 /auto-binding-space 選項時,所有導出都可以使用綁定點,而不管它們是否在最終狀態對象中使用。要將綁定點消耗限制為真正需要的函數,可以使用/ exports 選項來限制庫導出。
考慮使用 AddToStateObject 進行增量構建。 ( dxr1 . 1 ) dxr1 . 1 為狀態對象編譯引入了一個新選項。它允許基于現有對象增量構建狀態對象,這在使用許多著色器管理動態內容時非常有用。
手動管理堆棧(如果適用)。 使用 API 的查詢函數確定每個著色器所需的堆棧大小,并應用有關調用圖的應用程序端知識來減少內存消耗并提高性能。一個很好的例子是昂貴的反射著色器來拍攝次陰影光線,應用程序知道這些著色器只使用堆棧要求較低的普通命中著色器。驅動程序不能預先知道這個調用圖,所以默認的保守堆棧大小計算過度分配內存。
工具
考慮實施熱圖。 為了發現與特定的 BLASE 或特定幾何圖形的陰影相關的性能問題, NVIDIA 提供了一個方便的 API 來實現熱圖,以便可視化每個像素的處理成本。光線跟蹤在提高過程性能方面非常有用。有關詳細信息,請參見 使用計時器檢測分析 DXR 著色器 。
使用 NVIDIA Nsight 圖形進行分析和調試。 有關檢查加速結構、著色器表和分析光線跟蹤過程的詳細信息,請參閱 Nsight 圖形 詳細信息頁。
有關如何最有效地使用 Nsight 圖形的深刻建議,請參閱以下文章:
考慮更新到 Microsoft Shader 編譯器的最新版本。 ( DXR )偶爾會提供帶有新功能和優化的 Microsoft 著色器編譯器的更新版本。更新到 DirectXShaderCompiles GitHub repo 中的最新版本通常是值得的。







