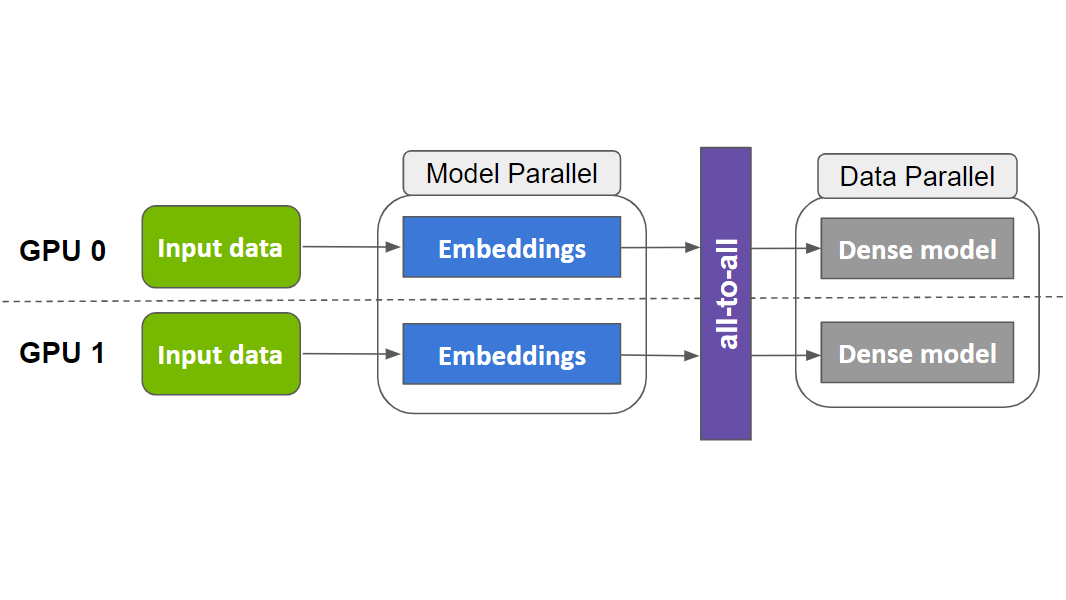
推薦系統是互聯網行業的核心,而高效地訓練這些系統對于各大公司來說是一個關鍵問題。大多數推薦系統是深度學習推薦模型(DLRMs),包含數十億甚至數百億個 ID 特征。圖 1 示出了一個典型的結構。

近年來, NVIDIA Merlin HugeCTR 和 TorchRec 等 GPU 解決方案通過在 GPU 上存儲大規模 ID 特征嵌入并對其進行并行處理,顯著加速了 DLRM 的訓練。與 CPU 解決方案相比,使用 GPU 內存帶寬可實現顯著改進。
與此同時,隨著訓練集群中使用的 GPU 數量增加(從 8 個 GPU 增加到 128 個 GPU),我們發現嵌入的通信開銷在總訓練開銷中占較大比例。在一些大規模訓練場景中(例如在 16 個節點上),它甚至超過了一半(51%)。
這主要有兩個原因:
1、隨著集群中 GPU 數量的增加,每個節點上的嵌入表數量逐漸減少,導致不同節點之間的負載不平衡,并降低訓練效率。
2. 與節點內帶寬相比,節點間帶寬要小得多,因此嵌入模型并行的通信時間更長。

為了幫助行業用戶更好地理解和解決這些問題,NVIDIA HugeCTR 團隊在 RecSys 2024 上展示了 EMBark。EMBark 支持 3D 靈活的分片策略,并結合通信壓縮策略來微調大規模集群深度推薦模型訓練中的負載不平衡問題,并減少嵌入所需的通信時間。 相關代碼 和 論文 均為開源。
EMBark 簡介?
EMBark 可提高不同集群配置下 DLRM 訓練中嵌入的性能,并加速訓練吞吐量。它使用 NVIDIA Merlin HugeCTR 開源推薦系統框架實施,但這些技術也可以應用于其他機器學習框架。
EMBark 包含三個關鍵組件:嵌入集群、靈活的 3D 分片方案和分片規劃器。圖 3 顯示了 EMBark 的整體架構。

嵌入集群?
嵌入集群可高效訓練嵌入,方法是將嵌入按類似功能分組,并為每個集群應用自定義壓縮策略。這些集群包括數據分布器、嵌入存儲和嵌入運算符,它們共同工作,將特征 ID 轉換為嵌入向量。
嵌入集群有三種類型:數據并行(DP)、基于歸約(RB)和基于唯一(UB)。每種方法在訓練期間都使用不同的通信方法,并且適用于不同的嵌入。
- DP 集群: DP 集群不會壓縮通信,使通信變得簡單高效,但它們會在每個 GPU 上復制嵌入表,因此僅適用于小型表。
- RB 集群 :使用歸約運算,對于使用池化運算壓縮多熱輸入表格具有顯著效果。
- UB 集群: 僅發送唯一向量,對于處理具有明顯訪問熱點的嵌入表是有益的。
靈活的 3D 分片方案?
靈活的 3D 分片方案可以解決 RB 集群中的工作負載不平衡問題。與固定分片策略(如逐行、逐表或逐列)不同,EMBark 使用 3D 元組 (i, j, k) 表示每個分片,其中 i 表示表格索引,j 表示行分片索引,k 表示列分片索引。這種方法允許每個嵌入跨任意數量的 GPU 進行分片,從而提供對工作負載平衡的靈活性和精確控制。
分片規劃器?
為了找到最佳的分片策略,EMBark 提供了一個分片規劃器,這是一種基于成本的貪婪搜索算法,可以根據硬件規格和嵌入配置確定最佳的分片策略。
評估?
利用嵌入集群、靈活的 3D 分片方案和高級分片規劃器,EMBark 可顯著提升訓練性能。為了評估其有效性,我們在一組 NVIDIA DGX H100 節點上進行了實驗,每個節點配備 8 個 NVIDIA H100 GPU (總計 640 GB HBM,每個節點的帶寬為 24TB/s)。
在每個節點內,所有 GPU 都通過 NVLink(900 GB/s 雙向)互聯,節點間通信使用 InfiniBand(8x400Gbps)。
| ? | DLRM-DCNv2 | T180 | T200 | T510 | T7 |
| # parameters | 48B | 70B | 100B | 110B | 470B |
| FLOPS per sample | 96M | 308M | 387M | 1,015M | 25M |
| # embedding tables | 26 | 180 | 200 | 510 | 7 |
| Table dimensions (d) | 128 | {32, 128} | 128 | 128 | {32, 128} |
| Average hotness (h) | ~10 | ~80 | ~20 | ~5 | ~20 |
| Achieved QPS | ~75M | ~11M | ~15M | ~8M | ~74M |
為了證明 EMBark 可以高效地訓練任何規模的 DLRM 模型,我們使用 MLPerf DLRM-DCNv2 模型進行了測試,并生成了多個具有更大嵌入表和不同屬性的合成模型(請參閱表 1)。我們的訓練數據集顯示冪律偏差為 a = 1.2。

基準使用串行內核執行順序、固定的表格行分片策略以及所有 RB 集群。實驗先后使用了三種優化:重疊、更靈活的分片策略和更好的集群配置。在四個典型的 DLRM 變體(DLRM-DCNv2、T180、T200 和 T510)中,EMBark 平均實現了 1.5 倍的端到端訓練吞吐量加速,比基準快達 1.77 倍。
您可以參閱 論文 ,了解更多詳細的實驗結果和相關分析。
使用 EMBark 加快 DLRM 訓練速度?
EMBark 解決了大規模推薦系統模型訓練中漫長嵌入過程的挑戰。通過支持 3D 靈活的分片策略,結合不同的通信壓縮策略,可以在大規模集群上微調深度推薦模型訓練中的負載不平衡問題,并減少嵌入所需的通信時間。
這提高了大規模推薦系統模型的訓練效率。在四個代表性的 DLRM 變體(DLRM-DCNv2、T180、T200 和 T510)中,EMBark 平均實現了 1.5 倍的端到端訓練吞吐量加速,比基準快 1.77 倍。
我們還在積極探索嵌入卸載相關技術和優化 torch 相關工作,并期待在未來分享我們的進展。如果您對此領域感興趣, 請聯系我們 獲取更多信息。
?