NVIDIA GPU 具有強大的計算能力,通常必須以高速傳輸數據才能部署這種能力。原則上這是可能的,因為 GPU 也有很高的內存帶寬,但有時他們需要你的幫助來飽和帶寬。
在本文中,我們將研究一種實現這一點的特定方法:預取。我們將解釋在什么情況下預取可以很好地工作,以及如何找出這些情況是否適用于您的工作負載。
上下文
NVIDIA GPU 從大規模并行中獲得力量。 32 個線程的許多扭曲可以放置在流式多處理器( SM )上,等待輪到它們執行。當一個 warp 因任何原因暫停時, warp 調度程序會以零開銷切換到另一個,確保 SM 始終有工作要做。
在高性能的 NVIDIA Ampere 架構 A100 GPU 上,多達 64 個活動翹板可以共享一個 SM ,每個都有自己的資源。除此之外, A100 還有 108 條短信,可以同時執行 warp 指令。
大多數指令都必須對數據進行操作,而這些數據幾乎總是源于連接到 GPU 的設備內存( DRAM )。 SM 上大量的翹曲都可能無法工作的一個主要原因是,它們正在等待來自內存的數據。
如果出現這種情況,并且內存帶寬沒有得到充分利用,則可以重新組織程序,以改善內存訪問并減少扭曲暫停,從而使程序更快地完成。這叫做延遲隱藏。
預取
CPU 上的硬件通常支持的一種技術稱為預取。 CPU 看到來自內存的請求流到達,找出模式,并在實際需要數據之前開始獲取數據。當數據傳輸到 CPU 的執行單元時,可以執行其他指令,有效地隱藏傳輸成本(內存延遲)。
預取是一種有用的技術,但就芯片上的硅面積而言很昂貴。相對而言, GPU 的這些成本甚至更高,因為 GPU 的執行單元比 CPU 多得多。相反, GPU 使用多余的扭曲來隱藏內存延遲。當這還不夠時,可以在軟件中使用預取。它遵循與硬件支持的預取相同的原理,但需要明確的指令來獲取數據。
要確定此技術是否能幫助您的程序更快地運行,請使用 GPU 評測工具(如 NVIDIA Nsight Compute )檢查以下內容:
- 確認沒有使用所有內存帶寬。
- 確認翹曲被阻止的主要原因是 攤位長記分牌 ,這意味著 SMs 正在等待來自 DRAM 的數據。
- 確認這些暫停集中在迭代互不依賴的大型循環中。
展開
考慮這種循環的最簡單可能的優化,稱為展開。如果循環足夠短,可以告訴編譯器完全展開循環,并顯式展開迭代。由于迭代是獨立的,編譯器可以提前發出所有數據請求(“加載”),前提是它為每個加載分配不同的寄存器。
這些請求可以相互重疊,因此整個負載集只經歷一個內存延遲,而不是所有單個延遲的總和。更妙的是,加載指令本身的連續性隱藏了單個延遲的一部分。這是一種接近最優的情況,但可能需要大量寄存器才能接收加載結果。
如果循環太長,可能會部分展開。在這種情況下,成批的迭代會被擴展,然后您會遵循與之前相同的一般策略。你的工作很少(但你可能沒那么幸運)。
如果循環包含許多其他指令,這些指令的操作數需要存儲在寄存器中,那么即使只是部分展開也可能不是一個選項。在這種情況下,在您確認滿足之前的條件后,您必須根據進一步的信息做出一些決定。
預取意味著使數據更接近 SMs 的執行單元。寄存器是最接近的。如果有足夠的可用空間(可以使用 Nsight Compute Occupation 視圖找到),可以直接預取到寄存器中。
考慮下面的循環,其中數組arr被存儲在全局存儲器( DRAM )中。它隱式地假設只使用了一個一維線程塊,而對于從中派生的激勵應用程序來說,情況并非如此。然而,它減少了代碼混亂,并且不會改變參數。
在本文的所有代碼示例中,大寫變量都是編譯時常量。BLOCKDIMX假定預定義變量blockDim.x的值。出于某些目的,它必須是編譯時已知的常數,而出于其他目的,它有助于避免在運行時進行計算。
for (i=threadIdx.x; i<imax; i+= BLOCKDIMX) { double locvar = arr[i]; <lots of instructions using locvar, for example, transcendentals>
}
假設您有八個寄存器用于預取。這是一個調整參數。下面的代碼在每四次迭代開始時獲取四個雙精度值,占據八個 4 字節寄存器,并逐個使用它們,直到批耗盡,此時您將獲取一個新批。
為了跟蹤批處理,引入一個計數器(ctr),該計數器隨著線程執行的每個后續迭代而遞增。為了方便起見,假設每個線程的迭代次數可以被 4 整除。
double v0, v1, v2, v3;
for (i=threadIdx.x, ctr=0; i<imax; i+= BLOCKDIMX, ctr++) { ctr_mod = ctr%4; if (ctr_mod==0) { // only fill the buffer each 4th iteration v0=arr[i+0* BLOCKDIMX]; v1=arr[i+1* BLOCKDIMX]; v2=arr[i+2* BLOCKDIMX]; v3=arr[i+3* BLOCKDIMX]; } switch (ctr_mod) { // pull one value out of the prefetched batch case 0: locvar = v0; break; case 1: locvar = v1; break; case 2: locvar = v2; break; case 3: locvar = v3; break; } <lots of instructions using locvar, for example, transcendentals>
}
通常,預取的值越多,該方法就越有效。雖然前面的例子并不復雜,但有點麻煩。如果預取值(PDIST或預取距離)的數量發生變化,則必須添加或刪除代碼行。
將預取值存儲在共享內存中更容易,因為您可以使用數組表示法,無需任何努力就可以改變預取距離。然而,共享內存并不像寄存器那樣接近執行單元。當數據準備好使用時,它需要一條額外的指令將數據從那里移動到寄存器中。為了方便起見,我們引入宏vsmem來簡化共享內存中數組的索引:
#define vsmem(index) v[index+PDIST*threadIdx.x]
__shared__ double v[PDIST* BLOCKDIMX];
for (i=threadIdx.x, ctr=0; i<imax; i+= BLOCKDIMX, ctr++) { ctr_mod = ctr%PDIST; if (ctr_mod==0) { for (k=0; k<PDIST; ++k) vsmem(k) = arr[i+k* BLOCKDIMX]; } locvar = vsmem(ctr_mod); <more instructions using locvar, for example, transcendentals>
}
除了批量預取,還可以進行“滾動”預取。在這種情況下,在進入主循環之前填充預取緩沖區,然后在每次循環迭代期間從內存中預取一個值,以便在以后的PDIST迭代中使用。下一個示例使用數組表示法和共享內存實現滾動預取。
__shared__ double v[PDIST* BLOCKDIMX];
for (k=0; k<PDIST; ++k) vsmem(k) = arr[threadIdx.x+k* BLOCKDIMX];
for (i=threadIdx.x, ctr=0; i<imax; i+= BLOCKDIMX, ctr++) { ctr_mod= ctr%PDIST; locvar = vsmem(ctr_mod); if ( i<imax-PDIST* BLOCKDIMX) vsmem(ctr_mod) = arr[i+PDIST* BLOCKDIMX]; <more instructions using locvar, for example, transcendentals>
}
與批處理方法相反,滾動預取在主循環執行期間不會再出現足夠大的預取距離的內存延遲。它還使用相同數量的共享內存或寄存器資源,因此它似乎是首選。然而,一個微妙的問題可能會限制其有效性。
循環中的同步(例如,syncthreads)構成了一個內存圍欄,并迫使arr的加載在同一迭代中的該點完成,而不是在以后的 PDIST 迭代中完成。解決方法是使用異步加載到共享內存中,最簡單的版本在 CUDA 程序員指南的 Pipeline interface 部分中解釋。這些異步加載不需要在同步點完成,只需要在顯式等待時完成。
以下是相應的代碼:
#include <cuda_pipeline_primitives.h>
__shared__ double v[PDIST* BLOCKDIMX];
for (k=0; k<PDIST; ++k) { // fill the prefetch buffer asynchronously __pipeline_memcpy_async(&vsmem(k), &arr[threadIdx.x+k* BLOCKDIMX], 8); __pipeline_commit();
}
for (i=threadIdx.x, ctr=0; i<imax; i+= BLOCKDIMX, ctr++) { __pipeline_wait_prior(PDIST-1); //wait on needed prefetch value ctr_mod= ctr%PDIST; locvar = vsmem(ctr_mod); if ( i<imax-PDIST* BLOCKDIMX) { // prefetch one new value __pipeline_memcpy_async(&vsmem(ctr_mod), &arr[i+PDIST* BLOCKDIMX], 8); __pipeline_commit(); } <more instructions using locvar, for example, transcendentals>
}
由于每一條__pipeline_wait_prior指令都必須與一條__pipeline_commit指令匹配,我們在進入主計算循環之前,將后者放入預取緩沖區的循環中,以簡化匹配指令對的簿記。
績效結果
圖 1 顯示,對于不同的預取距離,在前面描述的五種算法變化下,從金融應用程序中獲取的內核的性能改進。
- 分批預取到寄存器(標量分批)
- 分批預取到共享內存( smem 分批)
- 將預取滾動到寄存器(標量滾動)
- 將預取滾動到共享內存( smem 滾動)
- 使用異步內存拷貝將預取滾動到共享內存( smem 滾動異步)
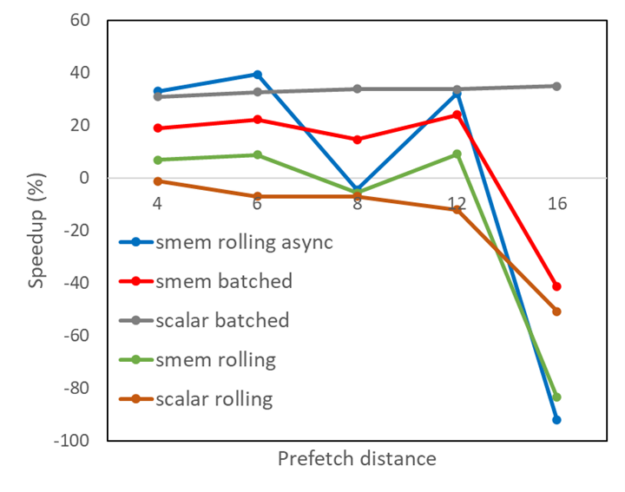
顯然,將預取滾動到具有異步內存拷貝的共享內存中會帶來很好的好處,但隨著預取緩沖區大小的增加,這是不均勻的。
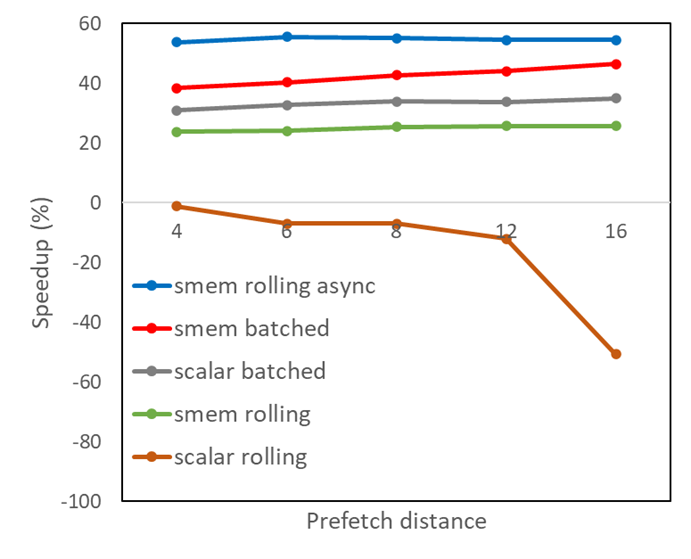
使用 Nsight Compute 對結果進行更仔細的檢查后發現,共享內存中會發生內存組沖突,這會導致異步負載的扭曲被拆分為比嚴格必要的更連續的內存請求。經典的優化方法是在共享內存中填充數組大小,以避免錯誤的跨步,這種方法在這種情況下有效。PADDING的值的選擇應確保PDIST和PADDING之和等于二加一的冪。將其應用于所有使用共享內存的變體:
#define vsmem(index) v[index+(PDIST+PADDING)*threadIdx.x]
這導致圖 2 所示的共享內存結果得到改善。預取距離僅為 6 ,再加上以滾動方式進行的異步內存拷貝,就足以以比原始版本代碼近 60% 的加速比獲得最佳性能。實際上,我們可以通過更改共享內存中數組的索引方案來實現這種性能改進,而無需使用填充,這是留給讀者的練習。
一個尚未討論的 預取的變化 將數據從全局內存移動到二級緩存,如果共享內存中的空間太小,無法容納所有符合預取條件的數據,這可能很有用。這種類型的預取在 CUDA 中無法直接訪問,需要在較低的 PTX 級別進行編程。
總結
在本文中,我們向您展示了源代碼的本地化更改示例,這些更改可能會加快內存訪問。這些不會改變從內存移動到 SMs 的數據量,只會改變時間。通過重新安排內存訪問,使數據在到達 SM 后被多次重用,您可以進行更多優化。