自 v1.0 以來已經過去了五個月,所以是時候進行新一輪 MLPerf 培訓基準了。在這個 v1.1 版本中,整個硬件和軟件堆棧的優化看到了基于 NVIDIA 平臺提交的基準測試套件的持續改進。這種改進在所有不同的尺度上都是一致的,從單個機器到工業超級計算機,例如由 560 個 NVIDIA DGX A100 系統組成的英偉達 SeleN 和由 768 個節點 A100 系統組成的微軟 Azure NDM A100 V4 集群。
越來越多的組織使用MLPerf基準來指導其AI基礎設施戰略。MLPerf(VZX19的一部分)是由學術界、研究實驗室和工業界的人工智能領導者組成的全球聯盟,其使命是 建立公平和有用的基準 ,為在規定條件下進行的硬件、軟件和服務的培訓和推理性能提供公正的評估。為了保持行業趨勢的領先地位,MLPerf不斷發展,定期舉行新的測試,并添加代表AI最先進水平的新工作負載。
與前幾輪的 MLPerf 基準測試一樣,本文從技術上深入探討了 NVIDIA 行業領先性能的優化工作。有關前幾輪的更多信息,請參閱以下帖子:
NVIDIA 繼續披露并詳細闡述這些技術細節,表明了其對公開和公平的社區驅動基準標準和實踐這一重要問題的堅定承諾,以促進人工智能的公益性發展。
整個堆棧的優化
由于構建模塊仍以目前成熟的 NVIDIA A100 GPU 、 英偉達 DGX A100 平臺和 NVIDIA SuperPod 參考體系結構為中心,整個堆棧的優化,特別是在系統軟件、庫和算法方面的優化,導致 MLPerf v1.1 中基于 NVIDIA 的平臺的性能不斷提高。
與 1 年前我們自己提交的 MLPerf v0.7 相比,我們觀察到芯片對芯片的改進高達 2.1 倍,最大規模培訓的改進高達 5.3 倍,如表 1 所示。
| Benchmark | v1.1 Max-Scale Records (min) (vs. v1.0) (vs. v0.7) | v1.1 Per-Accelerator Records* (min) (vs. v1.0) (vs. v0.7) |
| Recommendation (DLRM) | 0.63 (DGX SuperPOD) (1.6×) (5.3×) |
13.68 (A100) (1.1×) (1.9×) |
| NLP (BERT) | 0.23 (DGX SuperPOD) (1.4×) (4.1×) |
160.0 (A100) (1.1×) (2.1×) |
| Image Classification (ResNet-50 v1.5) | 0.35 (DGX SuperPOD) (1.2×) (2.2×) |
233.2 (A100) (1.0×) (1.4×) |
| Speech Recognition – Recurrent (RNN-T) | 2.38 (DGX SuperPOD) (1.2×) (NA**) |
273.92 (A100) (1.1×) (NA**) |
| Image Segmentation (3D U-Net) | 1.37 (DGX SuperPOD) (2.2×) (NA**) |
204.16 (A100) (1.1×) (NA**) |
| Object Detection – Lightweight (SSD) | 0.45 (DGX SuperPOD) (1.1×) (1.8×) |
66.08 (A100) (1.0×) (1.2×) |
| Object Detection – Heavyweight (Mask R-CNN) | 3.24 (DGX SuperPOD) (1.2×) (3.2×) |
369.36 (A100) (1.1×) (1.8×) |
| Reinforcement Learning (MiniGo) | 15.47 (DGX SuperPOD) (1.0×) (1.1×) |
2118.96 (A100) (1.0×) (1.1×) |
NVIDIA MLPERF v1.0 submission details :
根據加速器記錄: BERT : 1.0-1033 | DLRM:1.0-1037 | Mask R-CNN:1.0-1057 | Resnet50 v1.5:1.0-1038 | SSD:1.0-1038 | RNN-T:1.0-1060 | 3D Unet:1.0-1053 | MiniGo:1.0-1061
最大刻度記錄: BERT : 1.0-1077 | DLRM:1.0-1067 | Mask R-CNN:1.0-1070 | Resnet50 v1.5:1.0-1076 | SSD:1.0-1072 | RNN-T:1.0-1074 | 3D Unet:1.0-1071 | MiniGo:1.0-1075
NVIDIA MLPERF v1.1 submission details :
根據加速器記錄: BERT : 1.1-2066 | DLRM:1.1-2064 | Mask R-CNN:1.1-2066 | Resnet50 v1.5:1.1-2065 | SSD:1.1-2065 | RNN-T:1.1-2066 | 3D Unet:1.1-2065 | MiniGo:1.1-2067
最大刻度記錄: BERT : 1.1-2083 | DLRM:1.1-2073 | Mask R-CNN:1.1-2076 | Resnet50 v1.5:1.1-2082 | SSD:1.1-2070 | RNN-T:1.1-2080 | 3D Unet:1.1-2077 | MiniGo:1.1-2081 (*)
使用 NVIDIA 8xA100 服務器訓練時間并乘以 8 (**)計算 A100 的每加速器性能。 U-Net 和 RNN-T 不是 MLPerf v0.7 的一部分。 MLPerf 名稱和徽標是商標。有關更多信息,請訪問 www.mlperf.org 。
下一節將介紹一些亮點。
CUDA 圖
在 MLPerf v1.0 中,我們對大多數基準廣泛使用 CUDA 圖。 CUDA 圖將多個內核作為單個可執行單元啟動,通過最小化與 CPU 的通信來加快吞吐量。但每個圖的范圍只是一個完整迭代的一部分,該迭代處理單個小批量。因此,每次迭代分解為多個 CUDA 圖時,只捕獲了迭代的一部分。
在 MLPerf v1.1 中,我們使用 CUDA 圖將整個迭代捕獲到多個基準的單個圖中,從而進一步減少培訓期間與 CPU 的通信,并在規模上提高性能。這在 PyTorch 和 MXNet 基準測試中都得到了實現,從而使 ResNet-50 和 BERT 工作負載的性能提高了 6% 。
NCCL
NCCL 是 NVIDIA Magnum IO 技術公司 的一部分,它是優化服務器拓撲結構的 GPU 間通信的庫。 NCCL 今年早些時候增加的一個關鍵特性是 對 CUDA 圖形的支持 . 這使我們能夠將整個迭代捕獲為一個圖,如前一節所述。
之前, NCCL 復制了圖中的所有權重,并執行了一個 all REDUCT 函數,該函數將所有權重相加。然后將更新后的權重寫回圖形。這需要數據的多個副本。
我們現在引入了用戶緩沖區注冊, NCCL 集體使用指針,以避免在與可伸縮分層聚合和縮減協議( SHARP )一起使用時來回復制數據,該協議也是 NVIDIA Magnum IO 的一部分。在存在 CUDA 圖和 SHARP 的情況下,我們觀察到約 2% 的端到端額外加速。
NCCL 還實現了將縮放操作(乘以標量)融合到通信內核中以減少數據拷貝,從而在通信密集型網絡(如 BERT )中額外節省約 3% 的端到端成本。
細粒重疊
在這一輪中,我們充分利用了 GPU 硬件的功能,使獨立計算塊能夠在多個核之間進行細粒度的重疊,并增加了通信和計算的重疊。這提高了性能,尤其是最大規模的訓練,在 Mask R-CNN 上提高了 10% ,在 DLRM 上提高了 27% 。
特別是對于 recommender systems benchmark ( DLRM ),我們利用軟件和硬件的功能,通過重疊多個操作高效地使用 GPU 資源:
- 重疊嵌入索引計算和所有減少集體的前一次迭代
- 重疊數據梯度和權重梯度計算
- 增加了數學和其他多 GPU 集體的重疊,如全對全
對于 3D UNet ,空間并行性能通過更有效地調度數學和通信內核來提高,以增加兩者的重疊。
對于掩模 R-CNN ,我們實現了掩模頭、邊界盒頭和 RPN 頭的損耗計算重疊,以提高 GPU 在規模上的利用率。
通過更高效的內存拷貝(矢量化)和內核中更好的通信和數學重疊,我們顯著提高了多 GPU 組批處理規范( GBN )性能。這可以將工作負載擴展到 GPU 以上,從而為某些計算機視覺基準測試(如 ResNet50 和 SSD )節省 10% 以上的最大規模培訓,為 3D UNet 節省 5% 以上的培訓。
核融合與優化
最后,在這一輪 MLPerf 中,我們首次將偏差梯度縮減融合到矩陣乘法核中(兩個操作的融合)。這將導致高達 3% 的性能改進。
模型優化細節
在本節中,我們將深入討論每個工作負載上的優化工作。
BERT
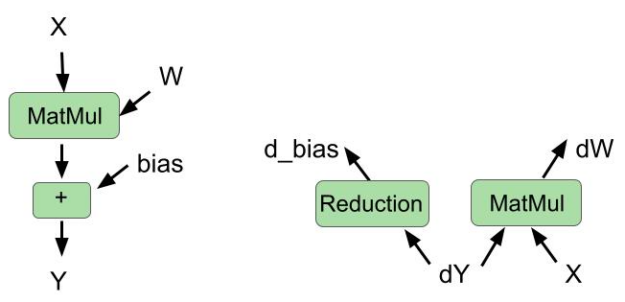
在后向傳遞中將偏置梯度減少融合到矩陣乘法中
cuBLAS 庫最近引入了一種新的融合類型:在同一內核中融合偏置梯度計算和權重梯度計算。
在這一輪中,我們使用 cuBLAS 功能在向后傳球中融合這兩個操作。我們還在正向傳遞中融合了偏置加法和矩陣乘法。圖 1 顯示了向前傳球和向后傳球的融合操作。
改進的融合多頭注意
在上一輪中,我們實現了多頭注意模塊的融合。此模塊跨num_sequences和num_heads變量使用并行性。這意味著在 GPU 上的不同流式多處理器( SMs )上同時調度的num_sequences*num_heads線程塊總數。num_heads在 MLPerf BERT 模型中為 16 ,并且當num_sequences小于 6 時,沒有足夠的線程塊填充 GPU ,從而限制了并行性。
在這一輪中,我們通過在注意力計算所需的批量矩陣乘法的序列維度上引入 slicing 來改進這些內核,這有助于按比例提高并行性。這種優化使最大規模的訓練場景的端到端加速約 8% ,其中每芯片批量較小。
使用 CUDA 圖捕獲完整迭代圖
正如前面關于 communications library 圖的部分所提到的,在這一輪中,我們將 BERT 的完整迭代捕獲到單個 CUDA 圖中。這是因為 CUDA NCCL 中支持 CUDA 圖形,以及 PyTorch 框架 . 由于 CPU 延遲和抖動在規模上有所減少,因此端到端節省了約 3% 。除此之外,在使用 CUDA 圖時,我們還利用了 NCCL 用戶緩沖區預注冊功能,從而使端到端性能提高了約 2% 。
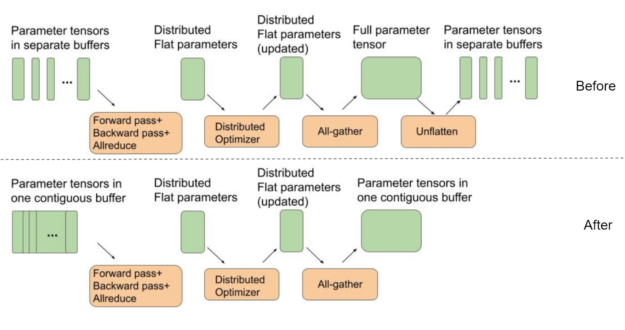
將模型參數緩沖區設置為指向連續平面緩沖區
BERT 使用分布式優化器加快優化步驟。為了獲得最佳的全聚集性能,分布式優化器中用于權重參數的中間緩沖區都應該是單個連續平面緩沖區的一部分。通過這種方式,我們可以更好地使用 GPU 互連,而不是在小的獨立張量上運行多個 all gather 函數,方法是為一條大消息運行 all gather 。
另一方面,默認情況下, PyTorch 為前向傳遞期間使用的每個模型參數張量分配單獨的緩沖區。這需要一個額外的“取消平臺”步驟,如圖 2 所示,在迭代結束和下一個迭代開始之間。
在這一輪 MLPerf 中,我們使用了一個單獨的連續緩沖區,其中每個參數張量作為一個大緩沖區的一部分彼此相鄰放置。這樣就不需要額外的取消緩沖步驟,如圖 2 所示。這種優化可在最大規模配置下為 BERT 節省約 4% 的端到端性能,其中優化器和參數拷貝的成本最為顯著。
DLRM
HugeCTR 是 NVIDIA Merlin 的一部分,是一個推薦系統專用培訓框架,它繼續支持 NVIDIA DLRM 提交。
混合嵌入索引預計算
在上一輪 MLPerf 中,我們實現了 hybrid embedding ,以減少 GPU 之間的通信。
盡管 HugeCTR 中實現的混合嵌入顯著減少了通信量,但它需要計算索引以確定在何處讀取和分發存儲在每個 GPU 上的嵌入向量。索引計算僅依賴于輸入數據,這些數據在前面的幾次迭代中被預取到 GPU 上。因此,在 Hugetr 中,索引預計算被用作優化,以隱藏在上一次迭代的通信內核下計算索引的成本。
與訓練迭代中的索引預計算相同,用于評估的混合嵌入索引可以在第一次執行評估時計算和緩存。它們可以在剩余的評估中重復使用,這完全消除了為后續評估計算指數的成本。
通信和計算之間的更好重疊
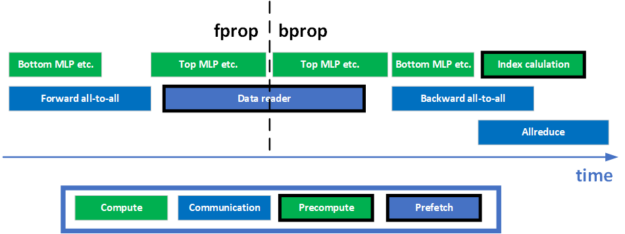
在 DLRM 中,為了促進模型并行訓練,在前進和后退階段分別需要兩個全對全集體。此外,在模型的數據并行部分的培訓結束時,還有一個 all REDUCT 集合。如何將計算與這些通信集體重疊是實現 GPU 的高利用率和高訓練吞吐量的關鍵。為了實現更好的重疊,進行了一些優化。圖 3 顯示了一次培訓迭代的簡化時間表。
在前向傳播階段,執行底部 MLP ,同時將所有內核轉發到所有內核,等待數據到達。在反向傳播階段, all REDUCT 和 all to all 重疊以提高網絡的利用率。索引預計算還計劃與這兩個通信集體重疊,以使用 GPU 上的空閑資源,最大限度地提高訓練吞吐量。
?
異步權重梯度計算
MLP 的數據梯度計算和權重梯度計算是共享相同輸入的兩個獨立計算分支。與數據梯度不同,在梯度全部減小之前,不需要權重梯度。由于 GPU 在調度內核方面的靈活性,這兩個計算在 HUGETR 中并行執行,最大限度地提高了 GPU 的利用率。
更好的融合
內核融合是一種有效的方法,可以減少對內存的訪問,提高 GPU 利用率。以前, DLRM 中利用了許多融合模式來實現更好的性能。例如,數據梯度計算、 ReLU 反向操作和偏置梯度計算可以通過 cuBLAS 在 HugeCTR 中融合在一起。這樣的跨層融合模式使得最后一次偏置梯度計算未被使用。
在這一輪中,利用 cuBLAS 中支持的 GEMM 和偏置梯度融合,將偏置梯度計算融合到 MLP 最后一層的權重梯度計算中。
另一個融合示例是權重轉換融合。為了支持混合精度訓練,訓練期間必須將 FP32 主砝碼轉換為 FP16 砝碼。作為優化,該精密鑄造與 Hugetr 中的 SGD optimizer 融合。每當更新 FP32 主權重時,它都會將更新權重的 FP16 版本寫入內存,從而無需單獨的內核進行轉換。
面具 R-CNN
在這一輪中,為所有卷積層切換到 NHWC 布局,使用專用評估節點,并改進損耗計算重疊,為掩碼 R-CNN 工作負載提供了最大的改進。
對所有卷積層使用 NHWC 布局
ResNet-50 主干網已經使用 NHWC 布局很長一段時間了,但該型號的其余部分直到現在都使用 NCHW 。
這一輪我們能夠將 FPN 模塊(緊跟在 ResNet-50 主干之后)切換到 NHWC 。在 NHWC 中運行 FPN 意味著我們可以轉置輸出而不是輸入,這更有效,因為輸入比輸出大得多。這一變化將最大規模配置的性能提高了 4-5% 。
使用專用節點專門評估多節點場景
雖然評估與培訓重疊,但 Mask R-CNN 評估是一個資源密集型過程。當評估同時進行時,培訓績效不可避免地會受到輕微影響。對于最大規模配置,評估所需時間幾乎與培訓所需時間相同。在后臺持續運行評估顯著影響培訓績效。
克服此問題的一種方法是使用一組單獨的節點進行評估,即一組節點進行培訓,一組較小的節點進行評估。對最大規模配置實施此更改將端到端性能提高了 12% 。
使用多線程 COCO 評估
COCO 求值函數消耗了大部分求值時間,并分別在邊界框和分割掩碼結果上運行。幾輪之前,我們通過在多個進程中運行這兩個評估調用來重疊這兩個評估調用。
這一輪,我們為 COCO 評估循環啟用了 openmp 多線程處理。這是 COVIAPI 軟件英偉達版中的一個可選特性。通過提供指定所需線程數的可選參數,可以并行化求值循環。此優化將評估速度提高了約 10% ,但僅顯示最后一次評估,因此對端到端時間的影響要小得多,約為 0.5% 。
小批量運行占用率四倍的兩階段 top-K 計算
我們在 Mask R-CNN 打了幾個 top-K 電話,由于占用率低,需要很長時間。 top-K 內核啟動的協作線程陣列或 CTA (線程塊)的數量與每 GPU 批大小成比例。最大規模配置使用的每 – GPU 批大小為 1 ,這導致僅啟動五個 CTA 。每個 CTA 分配一個 SMs ,而 A100 有 100 多個 SMs ,這表明 GPU 的利用率較低。
為了緩解這種情況,我們實施了兩階段方法:
- 在第一階段,我們將輸入分成四個相等的部分,然后通過一個調用對每個部分執行 top-K 。
- 在第二階段,我們將四個臨時結果連接起來,并取其中的 top-K 。
這將產生與以前相同的結果,但運行速度快 3 倍以上,因為我們現在在第一階段推出了 20 個 CTA ,而不是 5 個。進一步劃分輸入會使第一階段更快,但也會使第二階段更慢。
將輸入分成八種方式,而不是四種方式,這意味著在第一階段將啟動 40 個 CTA ,而不是 20 個。第一階段只需一半的時間就可以完成,但不幸的是,第二階段的速度太慢了,采用四向分割的方式,整體性能會更好。對最大規模配置實施四向拆分可使性能提升 3-4% 。
遮罩頭部、邊界盒頭部和 RPN 頭部的重疊損失計算
Mask R-CNN 推出的大多數 GPU 內核在批量較小時占用率較低。緩解這種情況的一種方法是盡可能多地重疊執行內核,以利用 GPU 資源,否則這些資源就會閑置。
一些損失計算可以同時進行。對于遮罩水頭損失、邊界框損失和 RPN 水頭損失,這是正確的,因此我們將這三個損失計算分別放在不同的 CUDA 流上,以便它們可以同時執行。這將最大規模配置的性能提高了約 5% 。
三維 UNet
矢量化連接和拆分操作
3D UNet 使用連接操作連接解碼器和編碼器激活。這將導致在向前和向后傳遞中為激活張量生成設備到設備的副本。我們通過使用矢量化加載和存儲優化了這些拷貝,執行了 4 倍寬的讀/寫操作。這使 concat 和 split 操作符的速度提高了 2.4 倍以上,在單節點配置下,端到端的加速比為 4.7% ,在最大規模配置下,端到端的加速比為 1.3% 。
高效空間并行卷積
在 MLPerf v1.0 中,我們引入了空間并行卷積,在這里我們將輸入激活拆分為多個 GPU (準確地說是 8 )。空間并行卷積的實現使我們能夠將暈交換隱藏在卷積后面的卷積后面。
在 MLPerf v1.1 中,我們優化了通信和卷積操作的調度,以便在啟動的通信和卷積內核之間獲得更好的重疊。雖然這確保了光暈交換不會暴露,但也有助于顯著降低抖動。此優化調度將最大規模配置的分數提高了 25% 以上。

空間并行損耗計算
3D Unet 使用骰子損失和 Softmax 交叉熵損失作為其損失函數。骰子損失定義為以下公式:
?
在此公式中,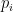
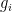
在最大比例配置中,由于單個 GPU 僅作用于圖像的一個切片,因此每個 GPU 僅包含
更好的配置
我們將全局批處理大小增加為數據集大小的一個因素。 DALI 數據加載器庫使我們能夠使用同一個碎片為不同的時代進行訓練。這使我們能夠顯著減少在 GPU 中緩存數據集所需的時間。
由于每個 GPU 加載的圖像要少得多,因此 DALI 中的邊界框緩存升溫速度也要快得多。此優化顯著縮短了啟動時間,并使 MLPerf v1.0 的加速比提高了 20% 。
數據并行異步計算
隨著培訓速度的加快,隱藏在培訓背后的規模評估變得具有挑戰性。在 MLPerf v1.1 中,單個圖像上的推斷在 GPU 上分片,以改進評估比例。然后收集所有推斷結果,形成最終輸出。這使得整個評估階段可以隱藏在培訓迭代之后。
更快的組實例規范
多 GPU InstanceRM 內核通過并行化多通道塊的 GPU 間通信和通過矢量化內存讀寫來減少內核的 DRAM 時間而得到了顯著改進。這使得最大規模配置的吞吐量提高了 5% 以上。
ResNet-50
端到端 CUDA 圖
對于 ResNet-50 ,當基準擴展到> 256 個節點時,每 GPU 批大小減小到一個非常小的值,其中迭代時間僅為~ 8-10ms 。在這些非常小的迭代時間內,確保 GPU 執行中沒有因 CPU 上運行的依賴項而產生的間隙是至關重要的。
對于 MLPerfV1.1 ,我們通過使用端到端技術減少了規模上的抖動 CUDA 圖 為了捕獲整個前向過程中的迭代,后向過程、優化器和 Horovord / NCCL 梯度都減少為單個圖形。 CUDA 圖的使用在最大規模的培訓中提供了 6% 的性能優勢。
GBN
隨著 ResNet50 規模的增加和本地批量的減少,為了實現盡可能快的收斂,我們使用 GBN 技術。對于每個 BatchNorm 層,在 GPU 組中,均數和方差均減少。
對于 MLPerf v1.1 ,通過并行化多個通道塊的 GPU 間通信,并通過矢量化內存讀寫來減少內核的 DRAM 時間,單個 DGX 節點內的 GBN 性能得到了顯著改善。這在規模上提供了 10% 的性能優勢。
固態硬盤
打開 – GPU 圖像緩存
圖像網絡大量使用圖像裁剪和調整大小來捕獲表示數據集更豐富統計信息的特征,并提高模型的泛化能力。
在以前的MLPRF回合中,SSD使用英偉達數據加載庫 (DALI) 圖像解碼特征來解碼JPG圖像的裁剪區域。此功能可避免在解碼整個圖像時浪費時間,尤其是在裁剪較小的情況下。
但是,這意味著該裁剪圖像只使用一次,因為該圖像未緩存在內存中。原始圖像的未來使用可能會有不同的裁剪區域,這意味著每次使用原始圖像時都會對其進行解碼。這種行為會導致 GPU 之間的抖動,因為解碼成本隨裁剪所需區域的大小變化很大。這在擴展場景中尤其明顯。
在這一輪中,我們利用了每個 NVIDIA A100 80-GB GPU 可用的 80-GB 內存容量,使用另一個 DALI 功能對整個圖像進行解碼并將其緩存在內存中。這使得將來可以使用相同的圖像來避免解碼成本,而是直接從內存中拾取裁剪區域。這樣做比每次解碼裁剪區域更便宜,并且運行時間和設備到設備的執行時間差異要小得多。
總體而言,該優化使單節點配置的端到端性能提高了 2% ,有效規模配置提高了約 5% ,規模介于單節點和最大規模之間。
用于 SSD 的 GBN ,
SSD 還利用了在 ResNet-50 中實現的 GBN 改進,在我們的最大規模配置中提供了約 4% 的 E2E 改進。
RNN-T
更優化的頂點傳感器
apex 中的傳感器模塊已進一步優化,以提高訓練吞吐量。傳感器接頭和傳感器損耗模塊分別增加了兩個優化。
傳感器接頭、 ReLU 和 dropout 是 RNN-T 中三個連續的內存綁定操作。作為優化, ReLU 和 dropout 已與 apex 中 apex.contrib.transducer.TransducerJoint 模塊中的傳感器接頭融合,有效地減少了到內存的跳閘。
傳感器損耗的反向傳播是一種內存密集型操作。 apex 中的 apex.contrib.transducer.TransducerLoss 中添加了一項優化,對反向操作中的加載和存儲進行矢量化,從而提高了內核的內存帶寬利用率。
GPU 上的更多數據預處理
當 GPU 忙于向前和向后傳遞時,在 CPU 上預處理下一批數據可能會隱藏數據預處理時間。這是理想的。但是,當數據預處理是計算密集型的時, CPU 上的預處理時間可能會暴露出來。
DALI 可以利用 GPU 的大規模并行處理特性,通過計算 GPU 上的部分預處理來幫助卸載 CPU 。在本文中,靜默修剪操作被移動到 GPU ,從而提高了訓練吞吐量。
結論
基于成熟且經驗證的 NVIDIA A100 GPU 和 NVIDIA DGX A100 平臺,在這一輪 MLPerf v1.1 培訓基準中,跨堆棧優化繼續為基于 NVIDIA 平臺的提交提供全面的性能改進。
值得重申的是,英偉達平臺是唯一的解決方案,提交所有工作負載在 MLPRF 基準套件,展示了業界領先的性能和通用性。
所有用于 NVIDIA 提交的軟件都可以從 MLPerf 存儲庫中獲得,以使您能夠重現我們的基準測試結果。我們不斷地將這些尖端的 MLPerf 改進添加到 NGC 上提供的深度學習框架容器中,這是我們針對 GPU 優化應用程序的軟件中心。
?