大語言模型(LLMs)在處理特定領域的問題時往往難以保證準確性,尤其是那些需要多跳推理或訪問專有數據的問題。雖然檢索增強生成(RAG)可以提供幫助,但傳統的向量搜索方法通常并不完善。
在本教程中,我們將向您展示如何將 GraphRAG 與經過微調的 GNN+LLM 模型結合使用,以實現比標準基準高 2 倍的準確性。
這種方法對于涉及以下情況的場景特別有價值:
- 特定領域的知識 (產品目錄、供應鏈)
- 高價值專有信息 (藥物研發、金融模型)
- 隱私敏感數據 (欺詐檢測、病歷)
GraphRAG 的工作原理
這種基于圖形驅動的檢索增強生成 (GraphRAG) 的特定方法建立在 G-Retriever 架構之上。G-Retriever 將接地數據表示為知識圖,將基于圖的檢索與神經處理相結合:
- 知識圖形構建:將領域知識表示為圖形結構。
- 智能檢索 :使用圖形查詢和 Prize-Collecting Steiner Tree (PCST) 算法查找相關子圖。
- 神經處理: 在 LLM 微調期間集成 GNN 層,以優化對檢索到的上下文的注意力。
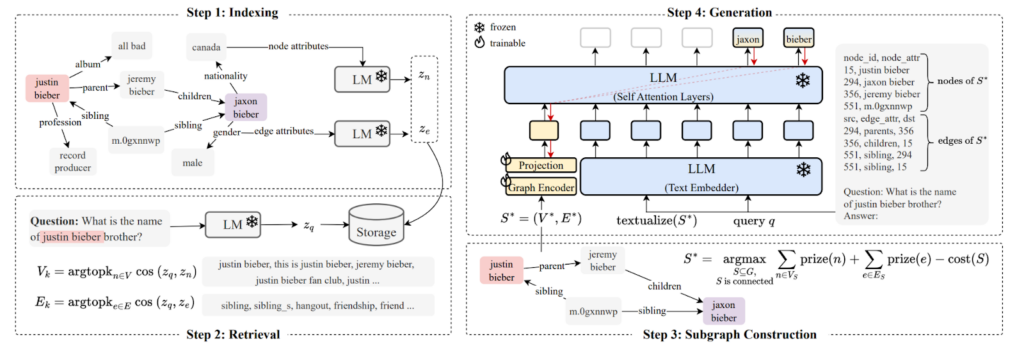
此過程適用于訓練數據三元組{(Qi, Ai, Gi)}:
- Qi: 多跳自然語言問題
- Ai: 答案節點集
- Gi = (Vi, Ei): 相關子圖 (已通過某種方法獲得)
管道遵循以下步驟:
- 找到語義相似的節點
和 edges
來詢問 Qi。
- 為這些匹配的節點和邊緣分配高額獎勵。
- 運行 PCST 算法的變體,找到可在最大化獎品的同時最小化大小的最佳子圖
。
- 在{(Qi, Gi*)}對上微調組合 GNN+LLM 模型,以預測{Ai}。
PyG 為 G-Retriever 提供模塊化設置。我們的代碼庫將其與用于持久化大型圖形的圖形數據庫和向量索引集成在一起,并提供檢索查詢模板。
真實示例:生物醫學 QA
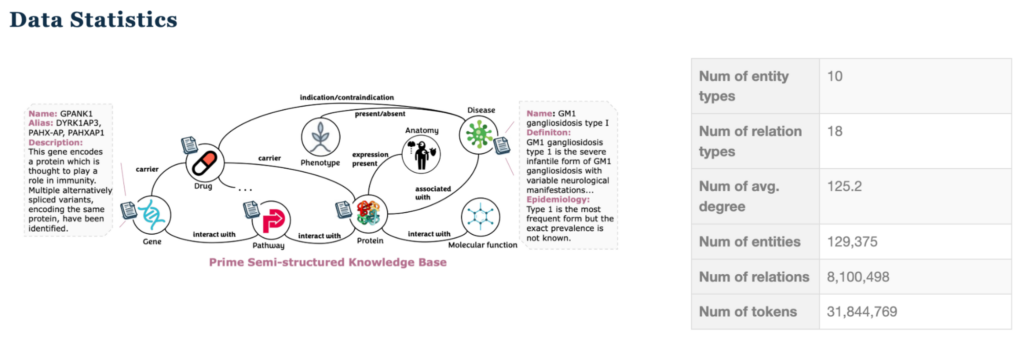
看看 STaRK-Prime 生物醫學數據集。思考以下問題:“哪些藥物針對 CYP3A4 酶并用于治療強淀粉病?”
正確答案 (Ivermectin) 需要了解以下內容:
- 直接關系 (藥物-酶、藥物-疾病連接)
- 節點屬性(藥物描述和分類)

由于以下因素,此數據集特別具有挑戰性:
- 異構節點和關系類型
- 可變長度文本屬性
- 平均節點度高,導致鄰域爆炸
- 復雜的多跳推理要求
實現詳情
為遵循本教程,我們建議您熟悉以下內容:
- 圖數據庫 : Neo4j 和 Cypher 查詢的工作知識
- 圖形神經網絡 (Graph Neural Networks, GNNs) : PyTorch Geometric (PyG) 的基本用法
- LLMs: 模型微調經驗
- 向量搜索:理解嵌入和相似性搜索
有關圖形數據庫和 GNN 的更多信息,請參閱 Neo4j 文檔 和 PyG 示例 。所有代碼均可在 /neo4j-product-examples GitHub repo 中獲取。
數據準備
基準測試數據集由序列化的 .pt 文件組成。對文件進行預處理,并將其加載到 Neo4j 數據庫中,如 GitHub 存儲庫中的 stark_prime_neo4j_loading.ipynb 所示。
添加數據庫約束以確保數據質量,并使用 CREATE CONSTRAINT 確保每個節點標簽的 nodeId 都是唯一的。
CREATE CONSTRAINT unique_geneorprotein_nodeid IF NOT EXISTS FOR (n:GeneOrProtein) REQUIRE n.nodeId IS UNIQUE |
您還可以在每個節點上加載文本嵌入屬性,該屬性是通過使用 OpenAI text-embedding-ada-002 嵌入文本描述生成的。
然后,使用 CREATE VECTOR INDEX 在具有余弦相似性的文本嵌入上創建向量索引,以在查找語義相似的節點時加快查詢時間。
有關 Neo4j 中索引和約束的更多信息,請參閱 Neo4j Cypher 手冊。
子圖檢索
初始檢索過程按以下步驟執行:
- 使用 Langchain OpenAI API 使用 text-embedding-ada-002 嵌入傳入問題。
- 使用向量搜索從數據庫 (
db.index.vector.queryNodes) 中查找前四個相似節點。 - 展開這四個節點中的一個躍點,這會為您提供一個較大的子圖 (由于密度原因) ,以創建基子圖 Gi。
- 使用向量相似度識別基底子圖 Gi 中排名前 100 的相關節點,并以 0.04 的恒定間隔分配獎品 (4.0 到 0.0)。
- 將圖形投影到 Neo4j GDS 中,并運行 PCST 算法的變體,以生成經過剪枝的子圖形 Gi*。
- 運行 PCST 算法以獲得剪枝子圖 Gi*。
對于每個剪枝子圖形,請按照以下步驟操作:
- 使用節點名稱和描述(
node_attr)來豐富它。 - 將問題編輯為
f"Question: {question}\nAnswer: "的提示模板。 - 將訓練和驗證數據集中的所有答案 nodeId 值轉換為相應的節點名稱。
- 使用分隔符
|將其連接起來。
按照 G-Retriever 的 recipe 編寫經過剪枝的子圖的文本說明。此外,將文本描述中的節點排序為微調模型的隱式信號。以下是一個示例提示:
node_id,node_attr14609,"name: Zopiclone, description: 'Zopiclone is...'"14982,"name: Zaleplon, description: 'Zaleplon is...'"...src,edge_attr,dst15570,SYNERGISTIC_INTERACTION,1544114609,SYNERGISTIC_INTERACTION,15441...Question: Could you suggest any medications effective for treating beriberi that are safe to use with Zopiclone?\nAnswer: |
此過程結束后,您將擁有一組訓練 PyTorch 數據對象,其中包含問題、以連接節點名稱表示的答案、edge_index (表示已剪枝子圖的拓撲) 以及文本化描述。這些節點已經可以用作答案,因此您可以評估 hits@1 和 recall 等指標,這些指標將在本文后面的結果中顯示。
為了進一步改進指標,您還可以微調 GNN+LLM。
GNN+ LLM 微調
使用 PyG 的 LLM 和 GNN 模塊共同微調 GNN 和 LLM,類似于 G-Retriever 示例 :
- GNN: GATv1 (Graph Attention Network)
- LLM: meta-llama/Llama-3.1-8B-Instruct
- 訓練: 在四個 A100 40GB GPUs 上進行 6K Q&As (約 2 小時)
- 上下文長度 :128k 個令牌,用于處理長節點描述
選擇 Llama 模型是因為其上下文長度為 128k,因此您可以在不限制子圖形大小的情況下處理長文本節點描述。
在四個 A100 40GB GPU 上微調 GNN+LLM 模型大約需要 2 小時來訓練 6K Q&As 和評估 4K Q&As。此過程會隨訓練示例的數量呈線性擴展。
結果
此方法實現了顯著改進 (表 1) :
| 方法 | 點擊數:1 | 點擊數:5 | 回顧 20 | MRR |
| 工作流 | 32.09 | 48.34 | 47.85 | 38.48 |
| G-Retriever | 32.27 0.3 | 37.92 0.2 | 27.16 0.1 | 34.73 0.3 |
| 子圖剪枝 | 12.60 | 31.60% | 35.93 | 20.96 |
| 基準 | 15.57 | 33.42 | 39.09 | 24.11 |
以下是我們的一些主要發現:
- 32% hits@1:比基準提升一倍以上。
- 工作流方法 :結合剪枝子圖和 G-Retriever 的優勢。
- 亞秒級推理 :適用于現實世界的查詢,例如使用 GPU、DPU 或 Jetson 等設備進行推理。
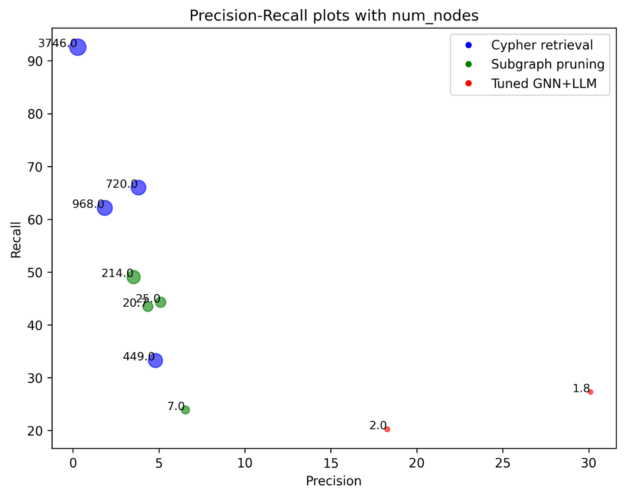
我們的結果獲得了 32% hits@1,是 STaRK-Prime 報告基準的兩倍多。中間步驟中生成的剪枝子圖也已達到接近最佳基準的分數,無需對 GNN+LLM 進行任何 fine-tuning。
但是,經過剪枝的子圖包含更多節點,而 G-Retriever 的輸出通常只有 1–2 個節點。這是因為,平均而言,真值答案有 1–2 個節點。
因此,Hits@5 和 Recall@20 對于 G-Retriever 來說是不公平的指標,因為它甚至不會產生 5 個答案。它經過微調,可以準確返回正確答案。另一方面,hits@1 對于已剪枝的子圖而言是不公平的指標,因為對已剪枝子圖中節點的順序沒有限制。
因此,向 G-Retriever 輸出追加經過剪枝的子圖(即 G-Retriever 的輸入)中任何唯一的節點,最多 20 個節點。我們將這個簡單的集成模型表示為管道。在所有指標中,此管道獲得的分數均顯著高于最佳基準。
在運行時,在給定問題的情況下,獲取基礎子圖形,為剪枝子圖形運行 PCST,GNN+LLM 的前向傳遞以及所有中間步驟可在幾秒鐘內完成。
| 時間/ 查詢 | 分鐘 | 中值 | 最大值 |
| 加密 | 0.056 | 0.069 | 1.179 |
| PCST | 0.044 | 0.166 | 3.573 |
| GNN+ LLM | 0.410 | 0.497 | 0.562 |
挑戰和未來工作
現有方法仍然存在一些挑戰和局限性,例如:
- 超參數復雜性
- 大型離散搜索空間 (例如,Cypher 擴展中的 hop 次數、節點和關系過濾、節點和邊緣獎勵分配等)
- 多個互連參數影響性能
- 難以找到最佳配置
- 數據集挑戰
- 處理多義詞/同義詞當前的
- 所有基準測試僅支持≤4 跳問題
- 假設答案是節點而非子圖
- 假設完整(無缺失邊)圖形
以下示例顯示了一個問題,其中正確答案節點 62592 為 hyaluronan metabolism,而我們的模型則為 47408 (hyaluronan metabolic process) 。很難分辨兩者的區別,以及為什么一個節點比另一個節點更受歡迎,才是真正的答案。
Q: Please find a metabolic process that either precedes or follows hyaluronan absorption and breakdown, and is involved in its metabolism or signaling cascades.Label (Synthesized): hyaluronan metabolism (id: 62592)Our answer ("Incorrect"): hyaluronan metabolic process (id: 47408)+ hyaluronan catabolic process, absorption of hyaluronan, hyal |
未來方向
我們向讀者指出幾個前景光明的未來方向,我們相信這些方向將進一步改進 GraphRAG:
- 先進的架構
- 探索圖形轉換器
- 支持全局注意力
- 擴展以處理更大的跳躍距離
- 支持復雜的子圖答案
- 魯棒性
- 處理不完整或噪聲圖
- 改進類似概念的消除歧義
- 擴展至企業級知識圖譜
有關更多信息,請參閱以下資源:
- /neo4j-product-examples/neo4j-gnn-llm-example GitHub 資源庫,其中包含要復制的所有代碼和設置說明
- graphrag.com 和 What is GraphRAG,了解有關 GraphRAG 和圖形構建模式的更多信息
- GNN+ LLM 斯坦福大學講座
?