訓練人工智能模型需要大量的數據。獲取大量訓練數據可能很困難、耗時且成本高昂。此外,所收集的數據可能無法涵蓋各種角落的情況,從而使人工智能模型無法準確預測各種場景。
Synthetic data提供了一種替代真實世界數據的方法,使人工智能研究人員和工程師能夠引導人工智能模型訓練。除了引導模型訓練外,研究人員還可以通過改變許多不同的參數(如位置、顏色、對象大小或照明條件)來快速生成新的數據集,以生成有助于創建通用模型的不同數據
這篇文章向你展示了如何使用一個模型,使用從NVIDIA Omniverse Replicator,一個以編程方式生成物理上精確的 3D 合成數據的 SDKpretrained model使用這些數據,而不是收集真實世界的數據。使用合成數據,可以創建所需的確切場景,甚至可以添加新元素或調整場景,從而進一步迭代對象檢測管道
構建數據集
要生成合成數據,首先要在數字世界中創建環境。對于這里給出的示例,環境是一個在所有生成的數據中都是一致的曲面
在本節中,您正在使用NVIDIA Omniverse Code以運行復制器腳本。以下屏幕截圖來自 NVIDIA Omniverse 代碼 GUI 。完成腳本后,您可以繼續在 NVIDIA Omniverse 代碼中運行,以查看生成的數據,也可以在本地終端中以無頭模式運行。將對這兩種方法進行描述。
為此,加載三個通用場景描述( USD )包括在NVIDIA Omniverse使用以下代碼創建基本場景:
with rep.new_layer():
CRATE = 'omniverse://localhost/NVIDIA/Samples/Marbles/assets/standalone/SM_room_crate_3/SM_room_crate_3.usd'
SURFACE = 'omniverse://localhost/NVIDIA/Assets/Scenes/Templates/Basic/display_riser.usd'
ENVS = 'omniverse://localhost/NVIDIA/Assets/Scenes/Templates/Interior/ZetCG_ExhibitionHall.usd'
加載這些資產后,使用 NVIDIA Omniverse Replicator API 將它們設置為場景中的靜態元素。從裝載的 USDs 中創建 NVIDIA Omniverse Replicator 元素,并將水果箱放在地面上的位置和重量。為了讓板條箱位于表面頂部,制作兩個物理對撞機,這樣一個對撞機就不會“穿過”另一個:
env = rep.create.from_usd(ENVS)
surface = rep.create.from_usd(SURFACE)
with surface:
rep.physics.collider()
crate = rep.create.from_usd(CRATE)
with crate:
rep.physics.collider()
rep.physics.mass(mass=10000)
rep.modify.pose(
position=(0, 20, 0),
rotation=(0, 0, 90)
)

接下來,加載水果 USD 資產,這一次將它們存儲在一個字典中,將它們的類名作為關鍵字,將資產位置作為值。使用這種方法,您可以稍后對它們進行迭代。
FRUIT_PROPS = {
'apple': 'omniverse://localhost/NVIDIA/Assets/ArchVis/Residential/Food/Fruit/Apple.usd',
'avocado': 'omniverse://localhost/NVIDIA/Assets/ArchVis/Residential/Food/Fruit/Avocado01.usd',
'kiwi': 'omniverse://localhost/NVIDIA/Assets/ArchVis/Residential/Food/Fruit/Kiwi01.usd',
'lime': 'omniverse://localhost/NVIDIA/Assets/ArchVis/Residential/Food/Fruit/Lime01.usd',
'lychee': 'omniverse://localhost/NVIDIA/Assets/ArchVis/Residential/Food/Fruit/Lychee01.usd',
'pomegranate': 'omniverse://localhost/NVIDIA/Assets/ArchVis/Residential/Food/Fruit/Pomegranate01.usd',
'onion': 'omniverse://localhost/NVIDIA/Assets/ArchVis/Residential/Food/Vegetables/RedOnion.usd',
'lemon': 'omniverse://localhost/NVIDIA/Assets/ArchVis/Residential/Decor/Tchotchkes/Lemon_01.usd',
'orange': 'omniverse://localhost/NVIDIA/Assets/ArchVis/Residential/Decor/Tchotchkes/Orange_01.usd' }
要生成每幀中不同的數據,請隨機化每幀中出現的水果、水果在板條箱中出現的位置以及水果總數。這為實際生產線中可能看到的每種水果配置提供了最大的覆蓋范圍。
def random_props(file_name, class_name, max_number=1, one_in_n_chance=3):
instances = rep.randomizer.instantiate(file_name, size=max_number, mode='scene_instance')
print(file_name)
with instances:
rep.modify.semantics([('class', class_name)])
rep.modify.pose(
position=rep.distribution.uniform((-8, 5, -25), (8, 30, 25)),
rotation=rep.distribution.uniform((-180,-180, -180), (180, 180, 180)),
scale = rep.distribution.uniform((0.8), (1.2)),
)
rep.modify.visibility(rep.distribution.choice([True],[False]*(one_in_n_chance)))
return instances.node

為了進一步使數據集多樣化,在每一幀中引入一些其他隨機化。首先,使用以下代碼隨機化每幀的光的數量、顏色和數量:
def sphere_lights(num):
lights = rep.create.light(
light_type="Sphere",
temperature=rep.distribution.normal(6500, 500),
intensity=rep.distribution.normal(30000, 5000),
position=rep.distribution.uniform((-300, -300, -300), (300, 300, 300)),
scale=rep.distribution.uniform(50, 100),
count=num )
return lights.node
rep.randomizer.register(sphere_lights)

攝像機角度是引入場景的另一種變化,以考慮板條箱的不同位置和攝像機高度。下面的代碼還確保相機始終面向機箱的位置,即使其位置已調整。
with camera:
rep.modify.pose(position=rep.distribution.uniform((-10, 105, -20), (5, 120, -5)), look_at=(0,20,0))

最后一步是運行數據生成腳本并記錄所需的信息。對于本例,為生成的每一幀中的水果寫出基線 RGB 數據、邊界框和標簽
with rep.trigger.on_frame(num_frames=10):
for n, f in FRUIT_PROPS.items():
random_props(f, n)
rep.randomizer.sphere_lights(5)
# Initialize and attach writer
writer = rep.WriterRegistry.get("BasicWriter")
writer.initialize(output_dir="fruit_data", rgb=True, bounding_box_2d_tight=True)
writer.attach([render_product])
創建 NVIDIA Omniverse Replicator 腳本后,有兩種方法可以生成完整的數據集。前面的圖像是來自 NVIDIA Omniverse 代碼 GUI 的劇照,它使您能夠調整場景并立即可視化更改。這個 GUI 使您有機會在每次代碼更改時可視化數據。一旦您對腳本感到滿意,就可以生成一個包含更多圖像的完整數據集
接下來的步驟詳細介紹了如何在 NVIDIA Omniverse 代碼 GUI 的腳本編輯器中繼續運行代碼,或者完全在自己的本地終端中運行代碼。
要運行無頭腳本,請在現有腳本的末尾添加以下行:
rep.orchestrator.run要在 NVIDIA Omniverse 容器內無頭運行此代碼,請首先找到omni.code.replicator.sh劇本打開 NVIDIA Omniverse 啟動器并導航到代碼應用程序。單擊啟動按鈕右側的菜單,查看 NVIDIA Omniverse 代碼安裝的位置。從該文件夾中,您可以運行以下命令,傳入您自己的無頭腳本的位置:
./omni.code.replicator.sh --no-window --/omni/replicator/script="FruitBasketOVEReplicatorDemo/data_generation/generate_data_headless.py"
瀏覽您的數據
使用 Replicator 腳本創建第一個幀后,可以調整參數以獲得所需的輸出。為此,您可能需要查看放置在生成圖像上的邊界框
NVIDIA Omniverse 中的函數用于可視化生成圖像上邊界框數據的顏色和標簽。這些函數獲取生成的背景圖像的路徑、邊界框數據、類標簽以及使用彩色邊界框存儲可視化的位置。
def colorize_bbox_2d(rgb_path, data, id_to_labels, file_path):
rgb_img = Image.open(rgb_path)
colors = [data_to_colour(bbox["semanticId"]) for bbox in data]
fig, ax = plt.subplots(figsize=(10, 10))
ax.imshow(rgb_img)
for bbox_2d, color, index in zip(data, colors, range(len(data))):
labels = id_to_labels[str(index)]
rect = patches.Rectangle(
xy=(bbox_2d["x_min"], bbox_2d["y_min"]),
width=bbox_2d["x_max"] - bbox_2d["x_min"],
height=bbox_2d["y_max"] - bbox_2d["y_min"],
edgecolor=color,
linewidth=2,
label=labels,
fill=False,
)
ax.add_patch(rect)
plt.legend(loc="upper left")
plt.savefig(file_path)
要使用上面顯示的函數,請使用生成的數據運行以下命令:
bbox2d_loose_file_name = "bounding_box_2d_tight_0.npy"
data = np.load(os.path.join(out_dir, bbox2d_tight_file_name))
bbox2d_tight_labels_file_name = "bounding_box_2d_tight_labels_0.json"
with open(os.path.join(out_dir, bbox2d_tight_labels_file_name), "r") as json_data:
bbox2d_loose_id_to_labels = json.load(json_data)
colorize_bbox_2d(rgb_path, data, bbox2d_loose_id_to_labels, os.path.join(vis_out_dir, "bbox2d_tight.png"))

訓練你的模特
生成數據后,可以啟動模型訓練工作流。此示例使用PyTorchtorchvision 軟件包,用于微調預訓練的 Faster R-CNN 模型。然而,合成數據也可以引入其他使用工具的管道,如NVIDIA TAO 工具包或 TensorFlow
訓練腳本中的第一步是定義數據集以構建 PyTorch DataLoader 。做一些初步工作,對三種文件類型進行排序,并將邊界框信息與正確的水果標簽關聯起來。這里的關鍵輸出是具有邊界框信息、水果標簽、框區域和圖像 ID 的目標
target = {}
target["boxes"] = torch.as_tensor(boxes, dtype=torch.float32)
target["labels"] = torch.as_tensor(labels_out, dtype=torch.int64)
target["image_id"] = torch.tensor([idx])
target["area"] = area
一旦您有了數據集,就可以將數據拆分為訓練管道的訓練、驗證和測試部分。然后使用以下代碼為訓練和驗證數據集創建數據加載器:
data_loader = torch.utils.data.DataLoader(
dataset, batch_size=16, shuffle=True, num_workers=4,
collate_fn= collate_fn)
validloader = torch.utils.data.DataLoader(
valid, batch_size=16, shuffle=True, num_workers=4,
collate_fn= collate_fn) 配置好數據集和數據加載器后,繼續訓練。跟蹤每個歷元的損失,并將數據配置為顯示在 TensorBoard 中以進行可視化
params = [p for p in model.parameters() if p.requires_grad]
optimizer = torch.optim.SGD(params, lr=0.001)
len_dataloader = len(data_loader)
model.train()
for epoch in range(num_epochs):
optimizer.zero_grad()
i = 0
for imgs, annotations in data_loader:
i += 1
imgs = list(img.to(device) for img in imgs)
annotations = [{k: v.to(device) for k, v in t.items()} for t in annotations]
loss_dict = model(imgs, annotations)
losses = sum(loss for loss in loss_dict.values())
writer.add_scalar("Loss/train", losses, epoch)
losses.backward()
optimizer.step()
print(f'Iteration: {i}/{len_dataloader}, Loss: {losses}')
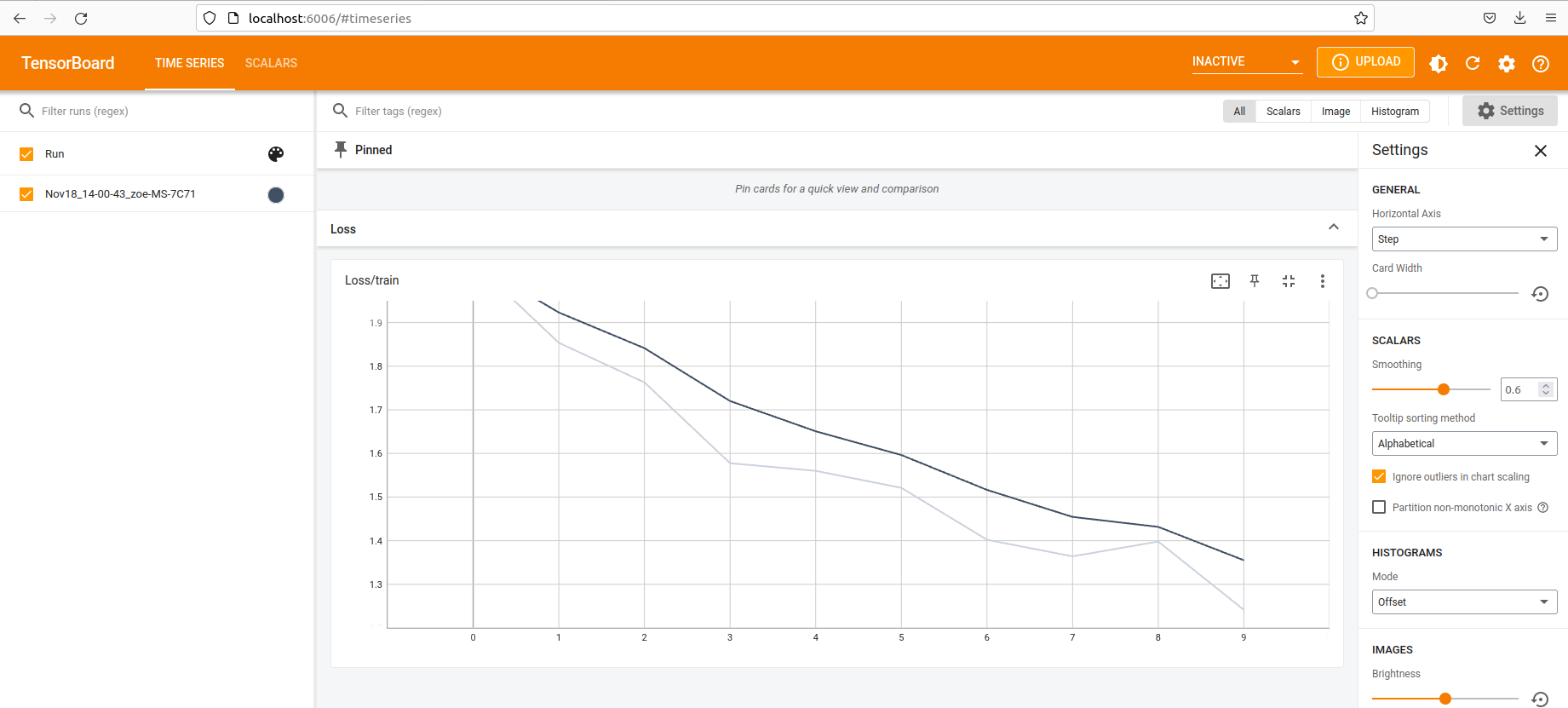
當損失充分減少,并且對模型的訓練方式感到滿意時,請保存模型。最后一步是將模型部署到生產環境中
將您的模型部署到生產中
首先,使用NVIDIA Triton 推理服務器使用以下腳本將模型導出為 ONNX 格式:
torch.onnx.export(model,
dummy_input,
os.path.join(OUTPUT_DIR, "model.onnx"),
opset_version=11,
input_names=["input"],
output_names=["boxes", "labels", "scores", "masks"]
)
接下來,從 NGC 運行 NVIDIA Triton 容器,然后使用以下命令啟動服務器:
tritonserver --model-repository=/model_repository --model-control-mode explicit --exit-on-error 0 --repository-poll-secs 3使用 NVIDIA Triton ,您可以“輪詢”模型存儲庫,以查看是否發生了更改。然后,將模型復制到 model _ repository 目錄中。
接下來,使用 bash 將模型復制到 NVIDIA Triton 目錄中,使用以下代碼:
mkdir model_repository/dmcount_onnx/ # create the folder with the model name
mkdir model_repository/dmcount_onnx/1/ # create the folder for the model version
cp model.onnx model_repository/dmcount_onnx/1/ # move the file to the directory
現在是推理的時候了。
完成循環
在部署模型之后,您可以選擇進一步迭代對象檢測管道的第一個完整實現。如果您選擇添加到原始數據集,則可以在相對較少的開銷下完成添加
例如,要將新水果(草莓)添加到原始選項集,請將新資源加載到原始字典并生成新數據:
'strawberry': 'omniverse://localhost/NVIDIA/Assets/ArchVis/Residential/Food/Berries/strawberry.usd',在訓練步驟中,調整標簽映射以使草莓添加到數據中:
static_labels = {
'apple' : 0,
'avocado' : 1,
'kiwi' : 2,
'lime' : 3,
'lychee' : 4,
'pomegranate' : 5,
'onion' : 6,
'strawberry' : 7,
'lemon' : 8,
'orange' : 9,
}
現在,您可以像以前一樣可視化邊界框數據,注意到在生成的一些幀中添加了草莓。管道的其他元素保持不變。在生產部署中,草莓顯示為注釋正確

在使用合成數據時,將新數據引入對象檢測管道是簡化的,這使得部署到生產中成為一個觸手可及的目標。合成數據釋放了迭代訓練工作流程的全部潛力
當您可以輕松地修改、調整和生成大量數據時,您就不再被培訓管道的第一步所束縛,可以專注于微調和將模型推向生產。
總結
本教程展示了如何將合成數據集成到現有模型中。第一步展示了 NVIDIA Omniverse 代碼如何為您提供一個用于編寫自己的 Replicator 腳本的交互式 GUI 。此腳本可以根據場景和模型所需的數據首選項進行自定義。然后,您可以根據您的確切規范創建預先標記的數據。從那里,您可以將合成數據帶到任何您想要的地方。本文中的示例將數據集成到 TorchVision 管道中進行微調
這個過程的最后一步是將經過訓練的模型部署到 NVIDIA Triton 中進行推理。當您將合成數據集成到現有工作流中時,此工作流代表了您所擁有的所有選項。 NVIDIA Omniverse Replicator 為您提供了一個工具,可以迭代生成合成數據,以適應您現有的工作流程。
為了開始使用 Omniverse Replicator ,下載 NVIDIA Omniverse并安裝NVIDIA Omniverse Code應用程序。要訪問代碼和其他 Omniverse Replicator 合成數據示例,請訪問NVIDIA-Omniverse/synthetic-data-examples在 GitHub 上。
額外資源
想了解更多信息嗎?看看這些專家引導的NVIDIA GTC 2023 關于生成合成數據和 Omniverse Replicator 的會話.
有關更多信息和最新消息,請參閱以下資源:
- 參觀開始在 Omniverse 上構建對于所有資源,您需要學習如何為平臺構建基于 USD 的自定義應用程序和擴展。
- 關注 Omniverse Instagram,Twitter,YouTube和Medium以獲得額外的資源和靈感。
- 查看Omniverse 論壇加入我們的Discord 服務器和Twitch與社區聊天。
- 訪問NVIDIA? OmniverseGitHub repo 用于探索社區構建的代碼示例和擴展。
?
?