適用于 Jetson 的 NVIDIA Metropolis 微服務提供了一套易于部署的服務,使您能夠使用最新的 AI 方法快速構建生產級視覺 AI 應用。
本文將介紹如何開發和部署生成式 AI 應用程序,這些應用程序在 NVIDIA Jetson 邊緣 AI 平臺上運行,并通過 Metropolis 微服務進行管理。您可以通過參考示例(這些示例可以作為構建任何模型的一般指南)來進行探索。
參考示例使用獨立的零射檢測 NanoOwl 應用,并將其與 適用于 Jetson 的 Metropolis 微服務 相結合,以便您可以在生產環境中快速構建原型并進行部署。
使用生成式 AI 實現應用轉型
生成式 AI 是一種機器學習技術,它使模型能夠以比之前方法更開放的方式理解世界。
大多數生成式 AI 的核心是基于 Transformer 的模型,該模型已在互聯網規模的數據上進行訓練。這些模型對各個領域有更廣泛的理解,使它們能夠用作各種任務的中堅力量。這種靈活性使 CLIP、Owl、Lama、GPT 和 Stable Diffusion 等模型能夠理解自然語言輸入。它們能夠零學習或幾次學習。

有關 Jetson 的生成式 AI 模型的更多信息,請訪問 NVIDIA Jetson 生成式 AI 實驗室 和 借助 NVIDIA Jetson 實現生成式 AI.
適用于 Jetson 的 Metropolis 微服務
Metropolis 微服務可用于在 Jetson 上快速構建生產就緒型 AI 應用。Metropolis 微服務是一組易于部署的模塊化 Docker 容器,用于攝像頭管理、系統監控、物聯網設備集成、網絡、存儲等。這些容器可以組合在一起,創建功能強大的應用。圖 2 顯示了可用的微服務。
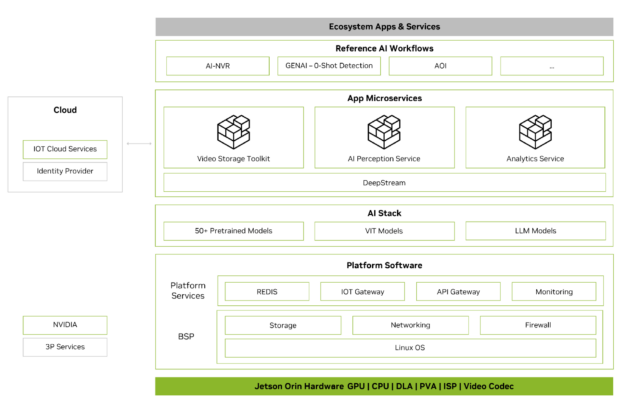
有關更多信息,請參閱適用于 Jetson 的 Metropolis 微服務白皮書。
將生成式 AI 應用與 Metropolis 微服務集成
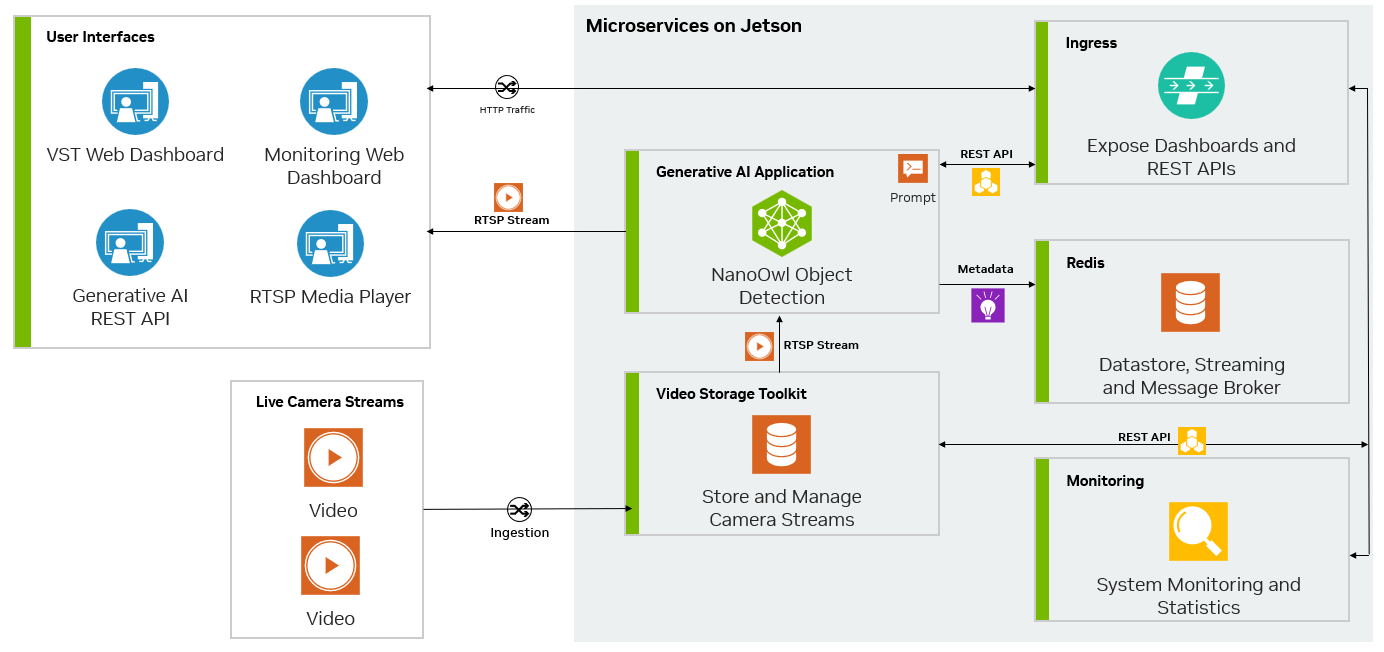
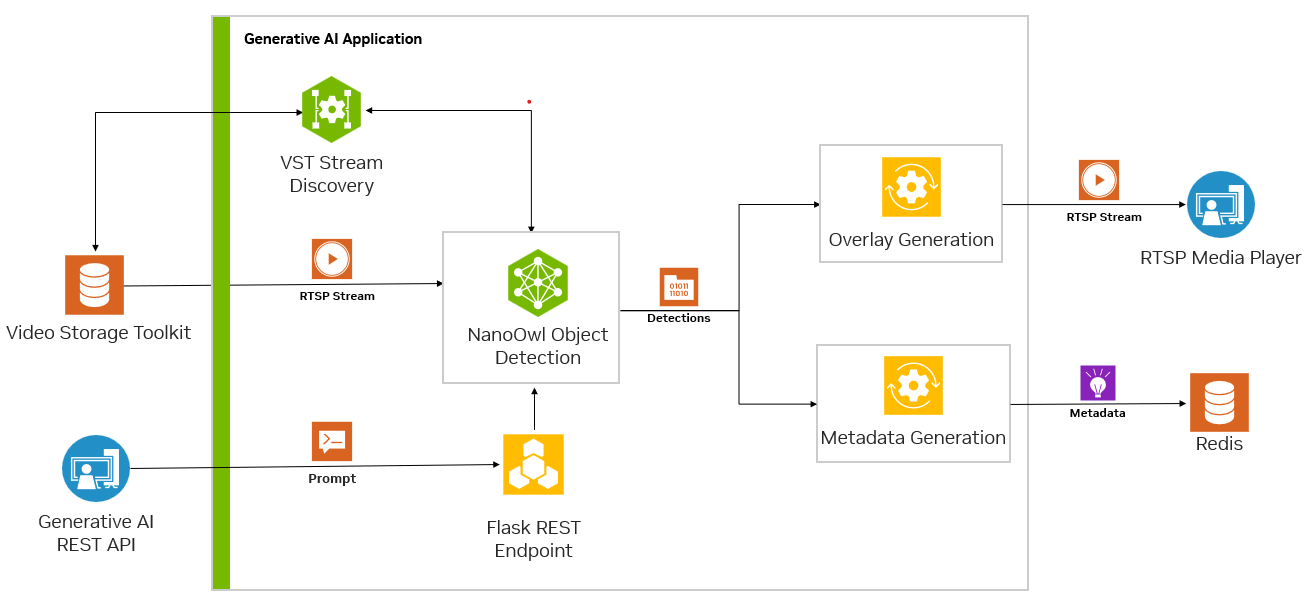
Metropolis 微服務和生成式 AI 可以結合使用,以利用幾乎不需要訓練或無需訓練的模型。圖 3 顯示了 NanoOwl 參考示例圖,該示例可用作在 Jetson 上使用 Metropolis 微服務構建生成式 AI 驅動的應用程序的一般方法。
使用 Metropolis 微服務定制應用程序
在 GitHub 上,您可以找到多種開源的生成式 AI 模型。其中一些模型經過優化,專為在 Jetson 平臺上運行而設計。您可以在Jetson 生成式 AI 實驗室上找到這些模型。
這些模型大多數都有許多共同點。作為輸入,它們通常可以接受文本和圖像。必須首先將這些模型加載到具有任何配置選項的內存中。然后,可以使用推理函數調用模型,在該函數中,圖像和文本被傳入以生成輸出。
在 Python 參考示例中,我們使用 NanoOwl 作為生成式 AI 模型。但是,參考示例的一般方法幾乎可以應用于任何生成式 AI 模型。
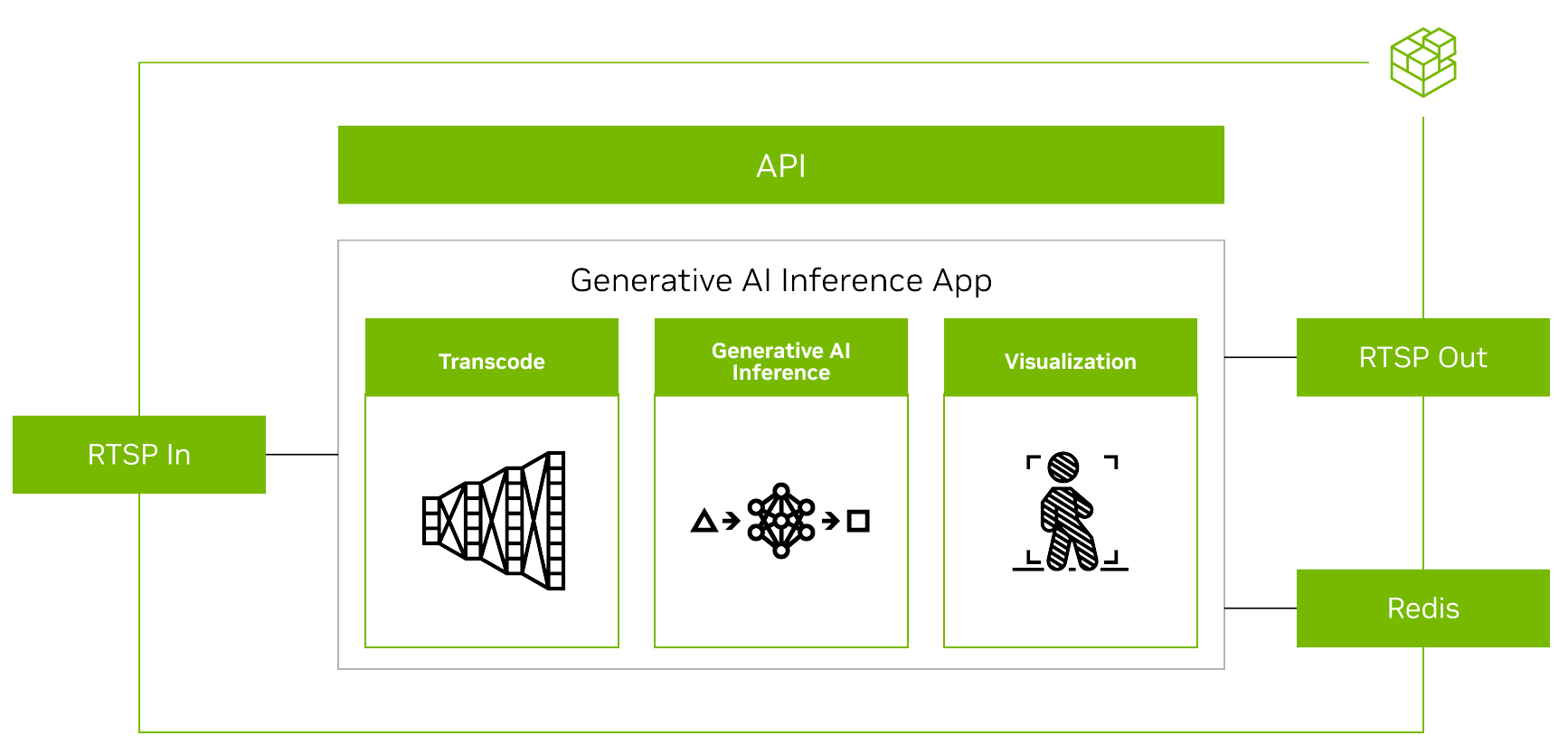
要使用 Metropolis 微服務運行任何生成式 AI 模型,您必須首先對齊其他微服務的輸入和輸出(圖 4)。
在流式傳輸視頻時,輸入和輸出均使用RTSP協議。RTSP從視頻提取和管理微服務Video Storage Toolkit(VST)進行流式傳輸。輸出通過覆蓋的推理輸出通過RTSP進行流式傳輸。輸出元數據將發送到Redis流,其他應用程序可以在其中讀取數據。欲了解更多信息,請觀看使用Metropolis微服務的視頻存儲工具包演示視頻。
其次,由于生成式 AI 應用程序需要一些外部接口(例如提示),因此您需要該應用程序接受 REST API 請求。
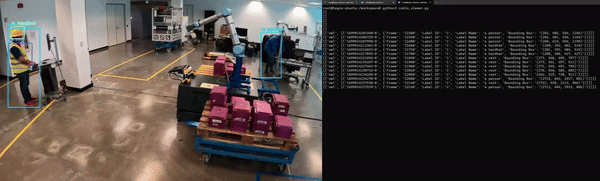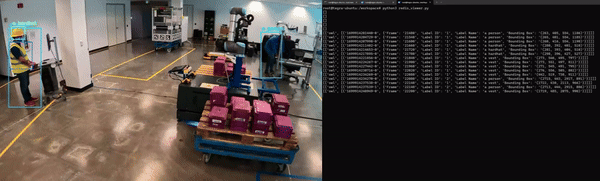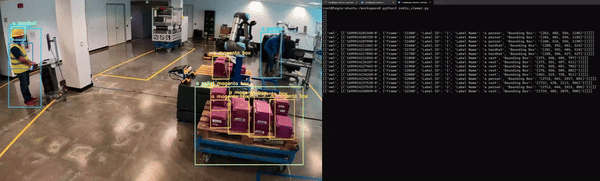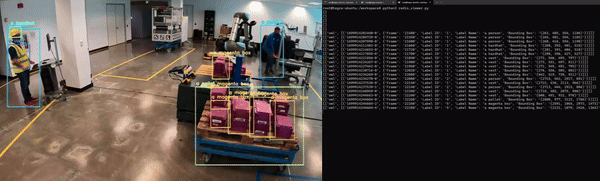
最后,應用程序必須經過容器化才能與其他微服務無縫集成。圖 5 展示了 Redis 上 NanoOwl 物體檢測和元數據輸出的示例。
準備生成式 AI 應用程序
此參考示例使用 NanoOwl.但是,對于具有可從 Python 調用的加載和推理函數的任何模型,您都可以按照這些步驟進行操作。本文中展示了幾個 Python 代碼示例,以重點介紹如何將生成式 AI 與 Metropolis 微服務相結合的主要理念,但省略了一些代碼以專注于常規 recipe.有關完整實現的更多信息,請參閱 /NVIDIA-AI-IOT/mmj_genai GitHub 項目。
要準備與 Metropolis 微服務集成的生成式 AI 模型,請執行以下步驟:
- 調用
predict模型推理的函數 - 使用
jetson-utils庫。 - 使用 Flask 添加 REST 端點以提示更新。
- 使用
mmj_utils生成疊加。 - 使用
mmj_utils與 VST 交互以獲取流。 - 使用
mmj_utils向 Redis 輸出元數據。
調用模型推理的 predict 函數
NanoOwl 將生成式 AI 模型包裝成OwlPredictor類。當此類實例化時,它會將模型加載到內存中。要對圖像和文本輸入進行推理,請調用predict函數來獲取輸出。
在這種情況下,輸出是已檢測對象的邊界框和標簽列表。
import PIL.Imageimport timeimport torchfrom nanoowl.owl_predictor import OwlPredictorimage = PIL.Image.open("my_image.png")prompt = ["an owl", "a person"]#Load model predictor = OwlPredictor( "google/owlvit-base-patch32", image_encoder_engine="../data/owlvit_image_encoder_patch32.engine" )#Embed Texttext_encodings = predictor.encode_text(text)#Inferenceoutput = predictor.predict(image=image, text=prompt, text_encodings=text_encodings, threshold=0.1, pad_square=False) |
大多數生成式 AI 模型都有類似的 Python 接口。有圖像和文本輸入,必須加載模型,然后模型可以從提示和圖像中推理以獲得一些輸出。要引入自己的生成式 AI 模型,您可以將其包裝在類中,并實現類似于OwlPredictor類。
使用 Jetson-utils 庫添加 RTSP I/O
您可以使用 jetson-utils 庫。該庫提供了 videoSource 和 videoOutput,它們可以用來從 RTSP 流中捕獲幀,并在新的 RTSP 流上輸出幀的類別。
from jetson_utils import videoSource, videoOutputstream_input = "rtsp://0.0.0.0:8554/input"stream_output = "rtsp://0.0.0.0:8555/output"#Create stream I/Ov_input = videoSource(stream_input)v_output = videoOutput(stream_output)while(True): image = v_input.Capture() #get image from stream output = predictor.predict(image=image, text=prompt, ...) new_image = postprocess(output) v_output.Render(new_image) #write image to stream |
此代碼示例從 RTSP 流中捕獲幀,然后將其傳遞給模型推理函數。根據模型輸出創建新圖像,并將其渲染到輸出 RTSP 流。
添加 REST 端點,以便使用 Flask 進行提示更新
許多生成式 AI 模型接受某種提示或文本輸入。要使用戶或其他服務能夠動態更新提示,請添加 REST 端點以促使 Flask 接受提示更新并將其傳遞給模型。
為了更輕松地將 Flask 服務器與您的模型集成,請創建一個可調用的包裝器類,使其能夠在自己的線程中啟動 Flask 服務器。有關更多信息,請參閱NVIDIA-AI-IOT/mmj_genai GitHub 項目。
from flask_server import FlaskServer#Launch flask server and connect queue to receive prompt updates flask_queue = Queue() #hold prompts from flask input flask = FlaskServer(flask_queue)flask.start_flask()while(True): ... if not flask_queue.empty(): #get prompt update prompt = flask_queue.get() output = predictor.predict(image=image, text=prompt, ...) ... |
通過包含任何傳入提示更新的隊列連接您的主腳本和 Flask 端點。當 GET 請求發送到 REST 端點時,Flask 服務器會將更新的提示放在隊列中。然后,您的主循環可以檢查隊列中是否有新的提示,并將其傳遞給模型,以便對更新的類進行推理。
使用 mmj_utils 生成疊加層
對于計算機視覺任務,可以看到模型輸出的可視化疊加效果(圖 6)。對于物體檢測模型,您可以在輸入圖像上疊加模型生成的邊界框和標簽,以查看模型檢測到每個物體的位置。

要執行此操作,請使用名為 DetectionGenerationCUDA 的函數,該函數來自 mmj_utils 庫。此庫依賴于 jetson_utils,它提供了用于生成疊加的 CUDA 加速函數。
from mmj_utils.overlay_gen import DetectionOverlayCUDAoverlay_gen = DetectionOverlayCUDA(draw_bbox=True, draw_text=True, text_size=45) #make overlay objectwhile(True): ... output = predictor.predict(image=image, text=prompt, ...) #Generate overlay and output text_labels = [objects[x] for x in output.labels] bboxes = output.boxes.tolist() image = overlay_gen(image, text_labels, bboxes)#generate overlay v_output.Render(image) |
您可以使用DetectionGenerationCUDA類,通過指定關鍵字參數來調整文本大小、邊界框大小和顏色,以滿足您的需求。有關如何使用mmj_utils,請參考/NVIDIA-AI-IOT/mmj_utilsGitHub 庫。
要生成疊加層,請調用對象并傳遞模型生成的輸入圖像、標簽列表和邊界框。然后,它會在輸入圖像上繪制標簽和邊界框,并返回帶有疊加層的修改后的圖像。然后,可以在 RTSP 流上渲染修改后的圖像。
使用 mmj_utils 與 VST 交互以獲取流
VST 可以幫助管理 RTSP 流,并提供一個良好的 Web UI 來查看輸入和輸出流。要與 VST 集成,可以直接使用 VST REST API,或者使用 mmj_utils 中的 VST 類,該類包含了 VST REST API 的接口。
從 VST 獲取 RTSP 流鏈接,而不是在 Python 腳本中對 RTSP 輸入流進行硬編碼。此鏈接可能來自 IP 攝像頭或通過 VST 管理的其他視頻流源。
from mmj_utils.vst import VSTvst_rtsp_streams = vst.get_rtsp_streams()stream_input = vst_rtsp_streams[0]v_input = videoSource(stream_input)... |
這將連接到 VST 并獲取第一個有效的 RTSP 鏈路。可以在此處添加更復雜的邏輯,以連接到特定源或動態更改輸入。
使用 mmj_utils 將元數據輸出到 Redis
生成式 AI 模型生成 元數據,可供其他服務用于生成分析和見解。
在這種情況下,NanoOwl 會輸出檢測到的物體的邊界框。您可以在 Metropolis 架構 中,通過分析 Redis 流中的數據來捕獲這些信息。在 mmj_utils 庫中,有一個輔助類可以幫助在 Redis 上生成檢測元數據。
from mmj_utils.schema_gen import SchemaGeneratorschema_gen = SchemaGenerator(sensor_id=1, sensor_type="camera", sensor_loc=[10,20,30])schema_gen.connect_redis(aredis_host=0.0.0.0, redis_port=6379, redis_stream="owl")while True: ... output = predictor.predict(image=image, text=prompt, ...) #Output metadata text_labels = [objects[x] for x in output.labels]schema_gen(text_labels, bboxes) |
您可以將SchemaGenerator包含輸入攝像頭流相關信息的對象并連接到 Redis.然后,可以通過傳入模型生成的文本標簽和邊界框來調用該對象。檢測信息將轉換為 Metropolis Schema,并輸出到 Redis 以供其他微服務使用。
應用程序部署
要部署應用程序,您可以設置 Ingress 和 Redis 等平臺服務。然后,通過將自定義生成式 AI 容器與 VST 等應用程序服務相結合,docker compose.
主應用程序已準備好所有必要的 I/O 和微服務集成(圖 7),您可以部署該應用程序并連接 Metropolis 微服務。
- 將生成式 AI 應用程序容器化。
- 設置必要的平臺服務。
- 使用
docker compose. - 實時查看輸出。
將生成式 AI 應用容器化
部署的第一步是使用 Docker 容器化生成式 AI 應用程序。
為了實現這一目標,一個簡單的方法是利用jetson-containers項目。該項目提供了一個構建適用于Jetson平臺的Docker容器的簡易方案,這些容器能夠支持機器學習應用,包括生成式AI模型。通過使用Jetson容器來創建包含必要依賴項的容器,隨后可以進一步定制這些容器,以添加應用程序代碼以及運行生成式AI模型所需的任何其他軟件包。
有關如何為 NanoOwl 示例構建容器的更多信息,請參閱 src/readme GitHub 項目中的文件。
設置必要的平臺服務
接下來,設置 Metropolis 微服務提供的必要平臺服務。這些平臺服務提供使用 Metropolis 微服務部署應用程序所需的許多功能。
此參考生成式 AI 應用僅需要 Ingress、Redis 和 Monitoring 平臺服務。可以通過 APT 快速安裝平臺服務,并使用systemctl.
有關如何安裝和啟動必要平臺服務的更多信息,請參閱適用于 Jetson 的 Metropolis 微服務快速入門指南。
使用 docker compose 啟動應用程序
應用容器化和必要的平臺服務設置完成后,您可以使用docker compose.
為此,創建一個docker-compose.yaml文件,該文件定義了要啟動的容器以及任何必要的啟動選項。在您定義docker compose文件,您可以使用docker compose up和 docker compose down命令。
有關 Docker 部署的更多信息,請查閱 GitHub 項目中的 /deploy/readme 文件。
實時查看輸出
部署應用程序后,您可以通過 VST 添加 RTSP 流,并通過 REST API 與生成式 AI 模型交互,以發送提示更新,并通過查看 RTSP 輸出實時查看檢測變化。您還可以在 Redis 上看到元數據輸出。
結束語
本文介紹了如何采用生成式 AI 模型并將其與適用于 Jetson 的 Metropolis 微服務集成。借助生成式 AI 和 Metropolis 微服務,您可以快速構建靈活準確的智能視頻分析應用。
欲了解有關所提供服務的更多信息,請訪問 適用于 Jetson 的 Metropolis 微服務產品頁面。如需查看完整的參考應用以及有關如何自行構建和部署應用的更多詳細步驟,請查閱 /NVIDIA-AI-IOT/mmj_genai GitHub 項目。
?