推薦系統在跨各種平臺實現個性化用戶體驗方面發揮著至關重要的作用。這些系統旨在根據用戶過去的行為和偏好預測和推薦用戶可能與之交互的商品。構建有效的推薦系統需要理解和利用龐大、復雜的數據集,這些數據集可捕獲用戶和商品之間的交互。
本文將向您展示如何基于共訪問矩陣構建簡單而強大的推薦系統。構建共訪問矩陣的主要挑戰之一是處理大型數據集時涉及的計算復雜性。使用像 pandas 等庫的傳統方法效率低下且速度緩慢,尤其是在處理數百萬甚至數十億次交互時。這正是 RAPIDS cuDF 的用武之地。RAPIDS cuDF 是一個 GPU DataFrame 庫,提供了類似 pandas 的 API,用于加載、過濾和操作數據。
推薦系統和聯合訪問矩陣
推薦系統是一種機器學習算法,旨在為用戶提供個性化建議或推薦。這些系統用于各種應用,包括電子商務(Amazon、OTTO)、內容流式傳輸(Netflix、Spotify)、社交媒體(Instagram、X、TikTok)等。這些系統的作用是幫助用戶發現符合其興趣和偏好的產品、服務或其他內容。
用于構建推薦系統的數據集通常包含以下內容:
要推薦的項目。
- 用戶與物品之間的交互。對于給定用戶的這種交互序列稱為會話。然后目標是推斷用戶將與下一個交互的物品。
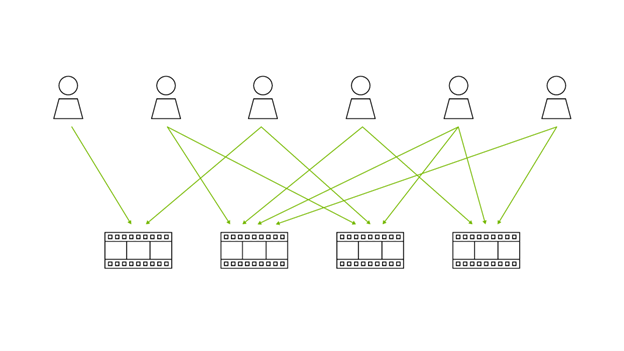
圖 1 顯示了用戶與項目 6543、242、5381 和 5391 進行交互的示例會話。推薦系統的目標是預測用戶將與下一個交互的項目。評估性能的一種常見方法是使用模型對

在會話期間,用戶通常會與多個商品進行交互。協同訪問矩陣會對一起出現的商品進行計數,大小為
構建共同訪問矩陣所面臨的挑戰
計算共訪問矩陣需要查看所有會話并計算所有并發次數。這很快就會產生高昂的成本:對于大小為 ?

pandas 使計算易于實現,但以犧牲效率為代價。為避免顯存爆炸,一方面需要將會話拆分成多個部分。另一方面,大數據集會導致嚴重的減速。
需要更快速的計算框架,同時還能讓pandas的代碼更加清晰。這正是RAPIDS cuDF的用武之地。你可以使用RAPIDS cuDF將計算加速40倍,無需更改代碼。
本文演示了如何使用 RAPIDS cuDF pandas 加速器模式構建共訪問矩陣并加速工作流程。在閱讀時運行代碼將讓您更好地了解加速器的益處。開始之前,請務必打開 GPU 加速器。有關更多詳細信息,請參閱演示筆記本。
RAPIDS cuDF pandas 加速器模式
RAPIDS cuDF 是一個 Python GPU DataFrame 庫,旨在加速在 CPU 上對大型數據集執行緩慢的操作(例如加載、連接、聚合和過濾)。
其 API 風格與 pandas 類似,借助新的 cuDF pandas 加速器模式,您可以在不更改任何代碼的情況下將加速計算引入 pandas 工作流程。cuDF 庫為表格數據處理提供 50 倍到 150 倍的性能提升。
RAPIDS cuDF pandas 加速器模式擴展了 cuDF 庫的功能,可將表格數據處理的性能提高 50 倍到 150 倍。它使您能夠將加速計算引入 pandas 工作流程,而無需更改任何代碼。
數據
本教程中使用的數據取自 OTTO – 多目標推薦系統 Kaggle 比賽的訓練集,該比賽包含一個月的課程。前三周用于構建矩陣,最后一周用于評估。驗證課程被截斷以構建模型的目標。回想一下 20 將用于查看共訪問矩陣檢索截斷項目的效果。
請注意,使用時間分割以避免信息泄露非常重要。測試數據包含數據集的第五周。數據集包含 186 萬個項目,以及大約 5 億用戶與這些項目的交互。這些交互存儲在 chunked parquet 文件中,以便于處理。
已知的數據相關信息如下:
session:會話ID;在本例中,會話相當于一個用戶aid:商品 IDts:交互發生的時間type:交互的類型;可以是點擊、購物車或訂單

實施共同訪問矩陣
由于數據集中的項目數量眾多,內存存在問題。因此,請將數據分為兩部分,以防止共訪問矩陣過大。然后,遍歷訓練數據中的所有拼接文件,以進行循環處理。
covisitation_matrix = []for part in range(PARTS): print(f"- Part {part + 1}/{PARTS}") matrix = None for file_idx, file in enumerate(tqdm(train_files)): |
第一步是加載數據。然后應用一些轉換以節省內存:將列的類型更改為int32,并限制會話時間超過30次交互。
for part in range(PARTS): for file_idx, file in enumerate(tqdm(train_files)): [...] # Load sessions & convert columns to save memory df = pd.read_parquet(file, columns=["session", "aid", "ts"]) df["ts"] = (df["ts"] / 1000).astype("int32") df[["session", "aid"]] = df[["session", "aid"]].astype("int32") # Restrict to first 30 interactions df = df.sort_values( ["session", "ts"], ascending=[True, False], ignore_index=True ) df["n"] = df.groupby("session").cumcount() df = df.loc[df.n < 30].drop("n", axis=1) |
接下來,您可以通過在會話列上將數據聚合到自身來獲取所有并發數據。這已經非常耗時,生成的數據幀非常大。
# Compute pairs df = df.merge(df, on="session") |
為降低矩陣計算成本,請將項目限制為當前考慮的部分中的項目。此外,僅考慮在 1 小時內對不同項目進行的交互,不允許在會話中進行重復的交互。
# Split in parts to reduce memory usage df = df.loc[ (df["aid_x"] >= part * SIZE) & (df["aid_x"] < (part + 1) * SIZE) ] # Restrict to same day and remove self-matches df = df.loc[ ((df["ts_x"] - df["ts_y"]).abs() < 60 * 60) & (df.aid_x != df.aid_y) ]# No duplicated interactions within sessionsdf = df.drop_duplicates( subset=["session", "aid_x", "aid_y"], keep="first", ).reset_index(drop=True) |
在下一步中,計算矩陣權重。通過對數據對進行求和聚合來計算所有的并發次數。
# Compute weights of pairsdf["wgt"] = 1df["wgt"] = df["wgt"].astype("float32")df.drop(["session", "ts_x", "ts_y"], axis=1, inplace=True)df = df.groupby(["aid_x", "aid_y"]).sum() |
在第二個循環(循環遍歷parquet文件)結束時,通過將新計算的權重添加到先前的權重來更新系數。由于共訪問矩陣很大,因此此過程很慢,并且會消耗內存。要釋放一些內存,請刪除未使用的變量。
# Update covisitation matrix with new weightsif matrix is None: matrix = dfelse: # this is the bottleneck operation matrix = matrix.add(df, fill_value=0) # Clear memorydel dfgc.collect() |
查看所有數據后,通過僅保留每個項目的 N 個最佳候選項(即具有最高權重的候選項)來減小矩陣大小。這是有趣信息所在的地方。
for part in range(PARTS): [...] # Final matrix : Sort values matrix = matrix.reset_index().rename( columns={"aid_x": "aid", "aid_y": "candidate"} ) matrix = matrix.sort_values( ["aid", "wgt"], ascending=[True, False], ignore_index=True ) # Restrict to n candids matrix["rank"] = matrix.groupby("aid").candidate.cumcount() matrix = matrix[matrix["rank"] < N_CANDIDS].reset_index(drop=True) covisitation_matrix.append(matrix) |
最后一步是連接矩陣中單獨計算的不同部分。然后,如果需要,您可以選擇將矩陣保存到磁盤。
covisitation_matrix = pd.concat(covisitation_matrix, ignore_index=True) |
就這樣,這段代碼使用 pandas 計算簡單的共訪問矩陣。它確實有一個主要缺陷:速度很慢,計算矩陣大約需要 10 分鐘!為了在合理的運行時間內,它還需要大幅限制數據。
cuDF pandas 加速器模式
這就是 cuDF pandas 加速器模式的用武之地。重啟內核,只需一行代碼即可釋放您 GPU 的強大功能:
%load_ext cudf.pandas |
表 1 顯示了支持和不支持 cuDF 加速的運行時。一行代碼實現了 40 倍的加速。
| ? | pandas | cuDF pandas |
| 10%的數據 | 8 分鐘 41 秒 | 13 秒 |
| 完整數據集 | 1 小時 30 分鐘* | 5 分鐘 30 秒 |
生成候選項
使用共訪問矩陣生成候選項以推薦是其中一種應用。這是通過聚合會話中所有項目的共訪問矩陣的權重來完成的。然后,將推薦權重最大的項目。在 pandas 中,實現非常簡單,并且再次受益于 GPU 加速器。
首先加載數據,然后只考慮最后的N_CANDIDS看到的項目。在會議中已經看到的項目是很好的推薦。我們將首先推薦它們。請記住,自匹配是從共訪問矩陣中刪除的,以節省內存,因此只需在此處恢復它們即可。
candidates_df_list = []last_seen_items_list = []for file_idx in tqdm(range(len(val_files))): # Load sessions & convert columns to save memory df = pd.read_parquet( val_files[file_idx], columns=["session", "aid", "ts"] ) df["ts"] = (df["ts"] / 1000).astype("int32") df[["session", "aid"]] = df[["session", "aid"]].astype("int32") # Last seen items df = df.sort_values( ["session", "ts"], ascending=[True, False], ignore_index=True ) df["n"] = df.groupby("session").cumcount() # Restrict to n items last_seen_items_list.append( df.loc[df.n < N_CANDIDS].drop(["ts", "n"], axis=1) ) df.drop(["ts", "n"], axis=1, inplace=True) |
接下來,將會話中項目的共訪問矩陣合并。然后,每個項目都會與 (候選項、權重)對相關聯。要獲得候選項的會話級別權重,請計算候選項在會話項目上的權重總和。通過獲取權重最大的
N_CANDIDS 候選項,您可以獲得推薦系統的候選項。
for file_idx in tqdm(range(len(val_files))): [...] # Merge covisitation matrix df = df.merge( covisitation_matrix.drop("rank", axis=1), how="left", on="aid" ) df = df.drop("aid", axis=1).groupby( ["session", "candidate"] ).sum().reset_index() # Sort candidates df = df.sort_values(["session", "wgt"], ascending=[True, False]) # Restrict to n items df["rank"] = df.groupby("session").candidate.cumcount() df = df[df["rank"] < N_CANDIDS].reset_index(drop=True) candidates_df_list.append(df) |
績效評估
要評估候選對象的強度,請使用召回指標。召回指標衡量檢索者在真值中成功找到的物品所占的比例。
在本例中,允許 20 個候選項。你希望查看用戶購買的商品中成功檢索矩陣的比例。實現的召回是 0.5868,這已經是強基準。在推薦系統返回的 20 個商品中,平均有 11 個是用戶購買的。這已經是強基準:在比賽期間,排名靠前的團隊的得分接近 0.7。請參閱演示筆記本,了解有關實現的詳細信息,這超出了本文的討論范圍。
更進一步
通過加速共訪問矩陣計算和聚合,您可以非常快速地進行迭代,從而改善候選者的回憶。第一個改進是為矩陣提供更多的歷史記錄。借助快速實現,無需等待數小時的計算結束。
然后優化矩陣。雖然您可以嘗試各種方法,但目前,共訪問矩陣會針對每個同時出現的商品給出一個權重,該演示為時間更近的商品提供了更多權重,因為此類交互似乎更相關。另一種想法是考慮交互的類型,一起購買的商品或一起添加到購物車的商品似乎比簡單查看的商品更適合推薦。
到目前為止,在聚合矩陣權重時,會話中的所有項目都被視為同等重要。然而,在會話后期出現的項目的預測系數高于最早出現的項目。因此,可以通過在會話結束時增加項目候選項的權重來優化聚合,以提高預測準確性。
通過這三次更改,recall@20 將提升至 0.5992。實現遵循與本文中介紹的代碼相同的方案,并添加了幾行以實現改進。有關詳細信息,請參閱演示 Notebook。
最后一步是將多個共訪問矩陣合并,以捕獲不同類型的候選對象。
總結
本文提供了構建和優化共訪問矩陣的全面的指南。盡管共訪問矩陣是一個簡單的工具——它們會計算用戶會話中項目的共出現次數——但構建它們涉及處理大量數據。高效運行對于快速迭代和改進推薦系統是必要的。
通過利用 RAPIDS cuDF 及其新發布的 pandas 加速器模式,共訪矩陣計算速度最高可提升至原來的 50 倍。得益于 GPU 加速,快速構建多樣化的共訪矩陣是 NVIDIA 的 Kaggle Grandmasters 贏得多項推薦系統競賽(包括 KDDCup 2023 和 OTTO)的關鍵要素。
雖然演示notebook僅計算兩種類型的矩陣,但可能性是無限的。嘗試實驗代碼并嘗試改進矩陣的構建,以捕獲不同的候選項。
?