此更新文章最初發布于 2025 年 3 月 18 日 。
企業組織正在采用 AI 智能體 來提高生產力并簡化運營。為了更大限度地發揮影響,這些智能體需要強大的推理能力來解決復雜問題、發現隱藏的聯系,并在動態環境中自主做出邏輯決策。
推理模型能夠解決復雜問題,因此已成為代理式 AI 生態系統的關鍵組成部分。通過使用長思考、Best-of-N 或自我驗證等技術,這些模型能夠更好地處理代理式流程不可或缺的推理密集型任務。
從自動化客戶支持到優化供應鏈和執行財務戰略,推理模型正在為各種應用提供支持。在物流領域,它們通過模擬假設場景 (例如在貨物中斷期間改變路線) 來提高效率。在科學研究中,它們有助于假設生成和多步驟解決問題。在醫療保健領域,它們可增強診斷和治療規劃。通過實現精確的邏輯推理,這些模型正在推動各行各業提供更可靠、更可擴展的 AI 解決方案。
本文將介紹 NVIDIA Llama Nemotron 推理模型系列。我們將介紹構建這一先進模型系列的過程。我們還將探索如何在 AI 智能體和協作式多智能體系統中使用這些模型,以推動推理之外的工作,并將其用于開放式的通用領域任務。
NVIDIA Llama Nemotron 推理模型系列
2025 年 3 月,NVIDIA 宣布推出 NVIDIA Llama Nemotron ,這是一個開放的領先 AI 模型系列,提供出色的推理能力、計算效率和供企業使用的開放許可證。
該系列有三種尺寸 ( Nano 、 Super 和 Ultra ) ,可根據開發者的用例、計算可用性和準確性要求,為其提供合適的模型大小。
Nano
Nano 經過 Llama 3.1 8B 的微調,可在 PC 和 edge 上實現更高的精度。

Super
Super 是從 Llama 3.3 70B 中提煉而成的 49B,可在數據中心 GPU 上實現更高的準確性和吞吐量。此模型是本文的重點。

Ultra
Ultra 從 Llama 3.1 405B 中提取出 253B,可在多 GPU 數據中心服務器上實現更高的代理精度。

帶有推理模型的 Llama Nemotron 在行業標準推理和代理式基準測試中提供領先的準確性:GPQA Diamond、AIME 2024、AIME 2025、MATH 500 和 BFCL,以及 Arena Hard。此外,這些模型具有商業可行性,因為它們基于開放式 Llama 模型構建,并基于 NVIDIA 審查的數據集以及使用開放式模型合成生成的數據進行訓練。
除了本文中概述的方法,以及模型已獲得許可,我們還將分享 Hugging Face 上的后訓練流程中使用的大部分數據。這些數據包括訓練后數據,包含近 3000 萬個高質量數據樣本,側重于數學、代碼、指令遵循、安全、聊天和推理功能。
您可以在 Hugging Face 上詳細了解數據集。我們的團隊致力于持續發布數據。我們還公開了 HelpSteer 3 ,這是我們之前在 HelpSteer 和 HelpSteer2 方面工作的延續。
測試時擴展概述
在深入探討 NVIDIA 如何創建這些令人驚嘆的模型之前,我們需要簡要解釋測試時擴展和推理,以及它們對使用 AI 構建的組織的重要性。
測試時擴展 是一種在推理期間應用更多計算的技術,用于通過各種選項進行思考和推理,從而改善模型或系統的響應。這有助于在關鍵的下游任務上擴展模型或系統的性能。
“通過問題進行推理是一項復雜的任務,而測試時 compute 是使這些模型達到對前面提到的用例有用所需的推理水平的重要組成部分。讓模型在推理過程中花費更多資源,為探索更多可能性開辟了道路。這增加了模型建立所需連接的可能性,或者在沒有額外時間的情況下達到它可能無法達到的解決方案的可能性。”
雖然推理和測試時擴展對代理式工作流中的許多重要任務大有益,但在當前的先進推理模型中存在一個常見問題。具體來說,開發者無法選擇模型的推理時間,因為他們無法在“推理”和“推理”操作之間進行選擇。Llama Nemotron 系列模型通過系統提示打開或關閉推理,使模型在非推理問題領域也保持有用性。
使用推理構建 Llama Nemotron
Llama 3.3 Nemotron 49B Instruct 基于 Llama 3.3 70B Instruct 。它經歷了廣泛的后訓練階段,以減小模型的大小,同時保留然后增強模型的原始功能。
使用了三個廣泛的 post-training 階段:
- 蒸餾到神經架構搜索和知識蒸餾。如需了解更多信息,請參閱 Puzzle:Distillation-Based NAS for Inference-Optimized LLMs 。
- 借助 NVIDIA 創建的 60B 個合成數據令牌 (代表 4M 個生成樣本中的 30M 個) 進行監督式微調,以確保在推理 off 和推理 on 領域中提供高質量的內容。在此階段,該團隊利用 NVIDIA NeMo 框架 高效擴展訓練后工作流。
- 通過 NVIDIA NeMo 完成強化學習 (RL) 階段,以增強聊天功能和指令遵循性能。這可確保對各種任務作出高質量的響應。
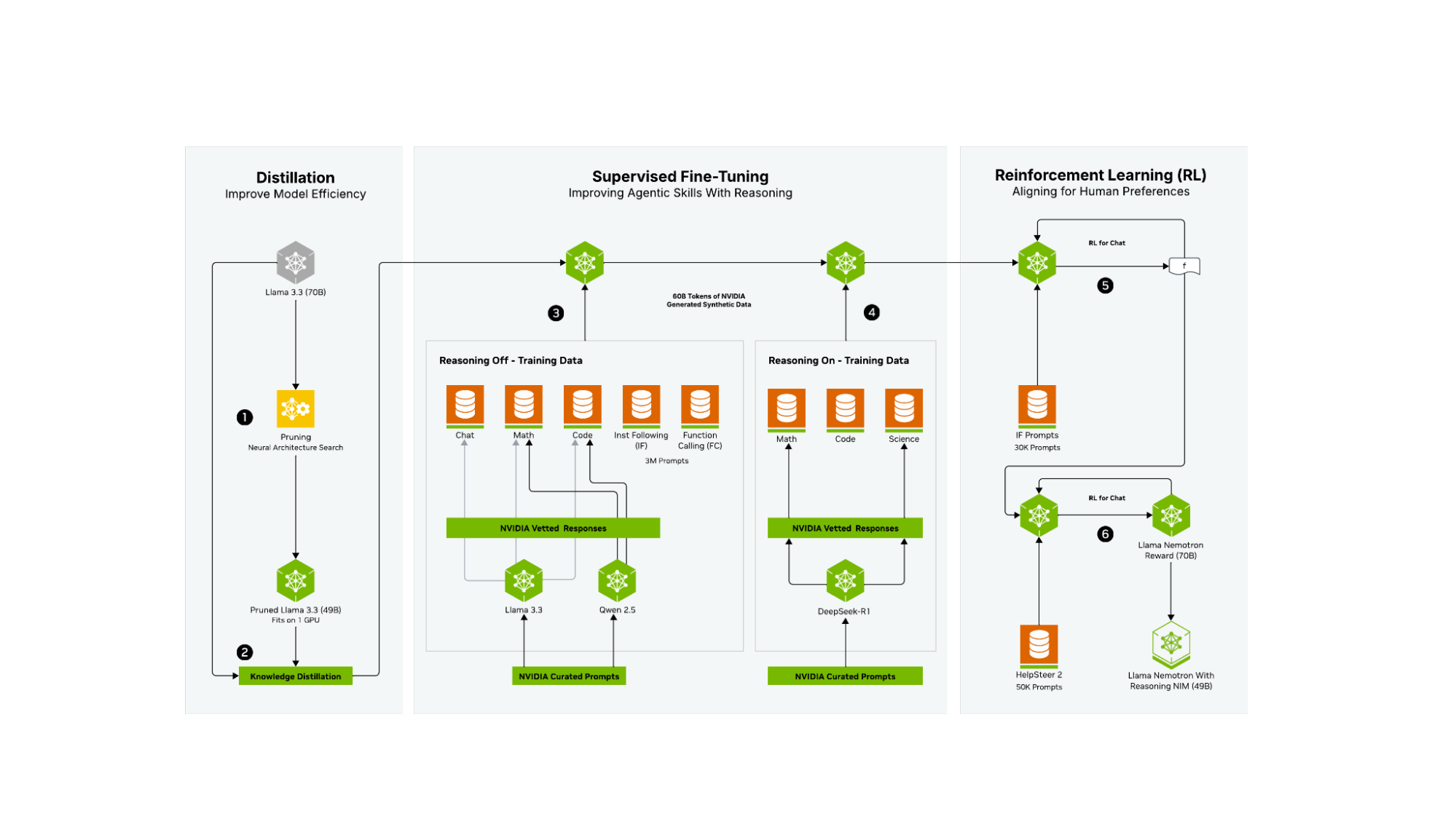
神經架構搜索 (Neural Architecture Search, NAS) 技術報告 詳細說明了第一階段 (步驟 1 和 2) 。在簡化的形式中,可以將其視為通過多種蒸餾和 NAS 方法,根據特定的旗艦硬件,將每個模型的參數數量“調整”為預先選定的最佳數量。模型后訓練的第二階段 (步驟 3 和 4) 涉及合成數據驅動的監督式微調,旨在實現一些重要目標。第一個目標是提高多項任務的非推理性能。訓練后工作流的這一部分 (第 3 步) 利用 NVIDIA 精心策劃的提示,通過基準模型 (Llama 3.3 70B Instruct) 以及 Qwen2.5 7B Math 和 Coder 模型創建合成數據。然后,這些數據由 NVIDIA 進行篩選和審查,用于增強聊天、數學和代碼任務的推理性能。此外,我們還付出了巨大努力,確保指令遵循和函數調用的推理性能在此階段達到一流水平。
第二個目標 (第 4 步) 是通過使用精選的 DeepSeek-R1 數據 (僅適用于 Math、Code 和 Science) 進行訓練,創建出色的推理模型。每個提示和響應都經過精心策劃,以確保在推理增強過程中只使用高質量數據,并借助 NVIDIA NeMo 框架 。這種方法可確保我們有選擇地將 DeepSeek-R1 的強大推理能力運用到其擅長的領域。
推理 ON/OFF (步驟 3 和 4) 是同時訓練的,并且僅因其系統提示而有所不同,這意味著生成的模型可以作為推理模型,也可以作為帶有開關 (系統提示) 的傳統 LLM,在每種模式之間進行切換。這樣做的目的是讓組織可以使用一個大小合適的模型來執行推理和非推理任務。
最后階段使用 RL 來更好地與用戶意圖和期望保持一致 (步驟 5 和 6) 。在執行這兩項任務時,模型利用 REINFORCE 算法和基于啟發式驗證器進行 RL,以實現指令遵循和函數調用增強 (第 5 步) 。之后,使用基于人類反饋的強化學習 (RLHF) ,使用 HelpSteer2 數據集和 NVIDIA Llama 3.1 Nemotron Reward 模型 (第 6 步) 針對聊天用例調整最終模型。
這些細致的后訓練步驟可生成一流的推理模型,并且在這兩種范式之間進行切換,本質上不會影響函數調用和指令遵循性能。此后訓練流程可創建在代理式 AI 工作流和流程的每個步驟都有效的模型,同時為 NVIDIA 旗艦硬件保持最佳參數數量。
借助 Llama Nemotron Super 在基準測試中實現領先的準確性
NVIDIA Llama Nemotron 模型將 DeepSeek-R1 等模型的強大推理能力與出色的世界知識相結合,并專注于 Meta 的 Llama 3.3 70B Instruct 的可靠工具調用和指令遵循,從而生成能夠領導關鍵代理式任務的模型。

借助 Llama Nemotron Ultra 253B 實現出色的推理準確性
Llama Nemotron Ultra 僅具有 253B 個總參數,其推理性能可媲美甚至超越 DeepSeek-R1 等頂級開放推理模型,同時由于其優化的大小和出色的工具調用功能,可提供更高的吞吐量。這種出色推理能力的結合,在不影響工具調用的情況下,可打造出適用于代理式工作流的出色模型。
除了 Llama Nemotron Super 的完整后訓練流程外,Llama Nemotron Ultra 還經歷了一個重點 RL 階段,以增強推理能力。

使用 Llama Nemotron Super 為系統提供動力支持,以執行復雜任務
本節將介紹一種新的測試時擴展方法,該方法使用由 NVIDIA Llama 3.3 Nemotron 49B Instruct 提供支持的多智能體協作系統。它以 92.7 的分數在 Arena Hard 基準測試(Chatbot Arena 性能的關鍵預測指標)中實現了最先進的性能。有關更多詳細信息,請參閱 Dedicated Feedback 和 Edit Models Empower Inference-Time Scaling for Open-Ended General-Domain Tasks。
許多測試時擴展方法主要用于解決具有可驗證解決方案的問題,包括數學問題、邏輯推理和競爭性編程。然而,許多重要任務都沒有可驗證的解決方案,包括提出研究想法、撰寫研究論文或開發交付復雜軟件產品的有效方法。
Llama Nemotron 測試時擴展系統解決了這一限制。該方法采用更人性化的方法來解決這些問題,并涉及以下步驟:
- 集思廣益,討論一個或多個問題的初始解決方案
- 從朋友、同事或其他專家處獲取有關解決方案的反饋
- 根據提供的反饋編輯初始解決方案
- 在合并編輯后選擇前景最佳的解決方案
此方法支持在廣泛的通用領域任務中利用 test-time scaling。
在概念化這種多智能體協作系統時,一個很好的類比是團隊合作,為沒有預定義解決方案的問題提出最佳解決方案。相比之下,長期思考可以被概念化為一個經過訓練的人長期思考一個問題,得出一個可以根據答案進行檢查的答案。
開始使用 NVIDIA Llama Nemotron 模型
“蒸餾、神經架構搜索、強化學習和傳統對齊策略的復雜組合被用于創建出色的 NVIDIA Llama Nemotron 推理模型。借助這些模型,您可以選擇大小合適的模型,這些模型不會影響功能,其構建旨在保留指令遵循和函數調用的優勢,確保它們在代理式 AI 系統中成為力倍增器。您可以利用這些模型為多智能體協作系統提供支持,以處理艱巨的開放式通用領域任務。”
除了作為此版本的一部分開源的模型之外,用于訓練過程中每個步驟的 大部分數據 也將發布以供寬松使用,用于訓練每個模型的方法 (通過技術報告) ,以及測試時擴展系統。您可以使用 NVIDIA NeMo 框架使用 SFT 和 RL 構建自己的自定義模型。
探索此模型系列,并在 build.nvidia.com 上開始原型設計。對于生產,在由 NVIDIA AI Enterprise 支持的任何 GPU 加速系統上部署專用 API 端點,以實現高性能和可靠性。或者,通過 NVIDIA 生態系統合作伙伴 (包括 Baseten、Fireworks AI 和 Together AI) ,只需單擊幾下即可獲得專用的托管 NVIDIA NIM 端點。您還可以在 Hugging Face 上找到該系列模型。
如需詳細了解自定義推理模型和推理用例,請查看 NVIDIA GTC 2025 會議“ 構建推理模型以實現高級代理式 AI 自主性 ”。
?





