隨著 生成式 AI 和視覺基礎模型的最新進展,VLM 呈現了新一波視覺計算浪潮,其中模型能夠實現高度復雜的感知和深度上下文理解。這些智能解決方案為增強 XR 設置中的語義理解提供了一種很有前景的方法。通過集成 VLM,開發者可以顯著改進 XR 應用解釋用戶操作以及與用戶操作交互的方式,使其響應速度更快、更直觀。
本文將向您介紹如何利用 NVIDIA AI Blueprint 進行視頻搜索和摘要 ,以及如何增強 Blueprint 以支持 XR 環境中的音頻。我們介紹了實時語音識別和沉浸式交互的分步過程——從設置環境到無縫集成。
使用多模態 AI 智能體推進 XR 應用
借助對話式 AI 功能增強 XR 應用,為用戶帶來更加身臨其境的體驗。通過創建在 XR 環境中提供 Q&A 功能的生成式 AI 智能體,用戶可以更自然地進行交互并獲得即時幫助。多模態 AI 智能體處理并合成多種輸入模式,例如視覺數據 (例如 XR 頭顯設備輸入) 、語音、文本或傳感器流,以做出上下文感知型決策并生成自然的交互式響應。
這種集成可以產生重大影響的用例包括:
- 熟練勞動力培訓:在模擬訓練比使用真實設備更安全、更實用的行業中,XR 應用可以提供沉浸式受控環境。通過 VLMs 增強語義理解可實現更逼真、更有效的訓練體驗,從而促進更好的技能轉移和安全協議。
- 設計和原型設計:工程師和設計師可以利用 XR 環境來可視化和操作 3D 模型。VLM 使系統能夠理解手勢和上下文命令,從而簡化設計流程并促進創新。
- 教育和學習:XR 應用可以跨各種學科打造沉浸式教育體驗。通過語義理解,該系統可以適應學習者的互動,提供個性化內容和互動元素,加深理解。
通過集成 VLM 并整合增強的語義理解和對話式 AI 功能等功能,開發者可以擴展 XR 應用的潛在用例。
適用于視頻搜索和摘要的 NVIDIA AI Blueprint
將 VLM 用于 XR 應用的關鍵挑戰之一在于處理長視頻或實時流,同時有效捕獲時間上下文。用于視頻搜索和摘要的 NVIDIA AI Blueprint 通過使 VLM 能夠處理更長的視頻時長和實時視頻源,解決了這一挑戰。
用于視頻搜索和摘要的 AI Blueprint 有助于簡化視頻分析 AI 智能體的開發。這些智能體通過利用 VLM 和 LLM 來促進全面的視頻分析。VLM 會為視頻片段生成詳細說明,然后將其存儲在向量數據庫中。LLM 會對這些描述進行總結,以生成對用戶查詢的最終回復。有關此智能體及其功能的更多詳細信息,請參閱使用 NVIDIA AI Blueprint 構建視頻搜索和摘要智能體。
此 AI Blueprint 的靈活設計使用戶能夠定制工作流程并適應不同的環境。為了根據虛擬現實 (VR) 智能體的特定用例調整藍圖,第一步是確保將 VR 數據連續流式傳輸到工作流中。例如,您可以使用 FFmpeg 直接從 VR 頭盔屏幕捕獲 VR 環境。為了使智能體具有交互性,我們的團隊優先啟用語音通信。還有什么比與 VR 智能體交互更好的方式呢?
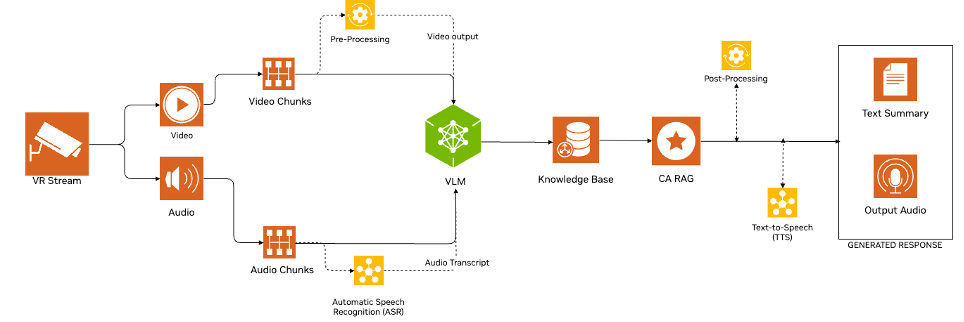
有多種方法可以將音頻和視覺理解融入 XR 環境。在本教程中,我們修改了 AI 藍圖,通過以一致的間隔分割音頻和視頻,并將其另存為.mpg 和.wav 文件,從而加入音頻處理。視頻文件(.mpg)由 VLM 處理,而音頻文件(.wav)則通過 API 調用發送到 NVIDIA Riva NIM ASR 進行轉錄。 Riva ASR NIM API 提供了輕松訪問多種語言的先進自動語音識別(ASR)模型的途徑。然后,轉錄的文本與相應的視頻一起發送到 VLM。
用于視頻搜索和摘要的 AI Blueprint 可以理解長視頻或直播。但是,對于此智能體,當用戶提出問題時,只需要理解視頻的部分內容。工作流檢查是否存在音頻轉錄。如果轉錄可用,則調用 VLM。否則,管道會等待音頻輸入,而不是持續處理所有視頻幀。
檢測到轉錄內容后,工作流將繼續進行 VLM 和大語言模型 (LLM) 調用,然后使用 Riva NIM 文本轉語音 (TTS) 模型將生成的響應轉換回音頻,然后將其語音傳回用戶。圖 1 顯示了此過程的詳細步驟。
第 1 步:創建 VR 環境
首先,通過 Oculus Link 桌面應用連接 Meta Quest 3。連接頭顯設備后,在 VR 中模擬環境。 NVIDIA Omniverse 是一個用于開發 OpenUSD 應用的平臺,專注于工業數字化和物理 AI 模擬。 NVIDIA Isaac Sim 是一款基于 Omniverse 構建的參考應用,用于在物理精準的虛擬環境中設計、仿真、測試和訓練基于 AI 的機器人和自主機器。 本教程使用預構建的 Isaac Sim 模擬中的 Cortex UR10 Bin Stacking 模擬。
模擬運行后,下一個任務是將 Isaac Sim 連接到 Quest。這是通過在 Isaac Sim 中啟用 NVIDIA 提供的一組 Create XR 插件來實現的。已激活的插件如下所示:
- Omniverse XR 遙測
- OpenXR 輸入/ 輸出
- 適用于 XR 的播放擴展程序
- XR 模擬器
- UI Scene View 實用程序
- VR 體驗
- XR 核心基礎架構
- 通用 XR 配置文件
- 用于構建配置文件 UI 的 XR UI 代碼
- 視口的 XR UI 代碼
- XR UI 通用
激活這些插件后,使用 OpenXR 單擊“Start VR Mode”按鈕以進入 VR 環境。
接下來,在 Windows 系統上設置 RTSP 流,按照以下步驟捕捉 VR 環境:
- 下載適用于
mediamtx-v1.8.4的 Windows 版本。 - 解壓下載的文件夾,并導航至包含
cd mediamtx_v1.8.4_windows_amd64的目錄。 - 創建
mediamtx.yml配置文件,并將其放置在同一目錄中。 - 運行
.\mediamtx.exe以啟動 RTSP 服務器。 - 在 Windows 上安裝 FFmpeg 。
- 根據您的設置執行以下命令之一。請注意,您可能需要調整一些參數,以實現兼容性和最佳串流性能。
運行以下命令以設置 FFmpeg 以同時截取屏幕和麥克風。
ffmpeg -f gdigrab -framerate 10 -i desktop -f dshow -i audio="Microphone (Realtek(R) Audio)" -vf scale=640:480 -c:v h264_nvenc -preset fast -b:v 1M-maxrate 1M -bufsize 2M -rtbufsize 100M -c:a aac -ac 1 -b:a 16k -map 0:v -map1:a -f rtsp -rtsp_transport tcp rtsp://localhost:8554/stream |
運行以下命令以設置 FFmpeg,以便在播放預先錄制的音頻文件時進行屏幕截取。該命令會無限循環音頻。如要僅播放一次音頻,請刪除 -loop 0 參數。
ffmpeg -f gdigrab -framerate 10 -i desktop -stream_loop -1 -i fourth_audio.wav -vf scale=640:480 -c:v h264_nvenc -qp 0 -c:a aac -b:a 16k -f rtsp -rtsp_transport tcp rtsp://localhost:8554/stream |
第 2 步:將音頻添加到 pipeline
為支持輸入和輸出音頻處理,我們的團隊修改了用于視頻搜索和摘要工作流的 AI Blueprint,使其能夠在視頻輸入之外加入音頻。在未來的版本中,VSS 將原生支持此功能。
在本教程中,我們使用 GStreamer 的 splitmuxsink 功能修改了提取工作流。該團隊建立了一個音頻處理工作流,對傳入的音頻流進行解碼,并將其轉換為標準格式。然后,使用 splitmuxsink 元素將音頻數據寫入分段的 .wav 文件,以便于管理和播放。這種集成可確保在 AI 藍圖的提取工作流中同時處理音頻和視頻流,從而實現全面的媒體處理。
以下代碼展示了增強音頻工作流程的示例方法:
caps = srcbin_src_pad.query_caps()if "audio" in caps.to_string(): decodebin = Gst.ElementFactory.make("decodebin", "decoder") audioconvert = Gst.ElementFactory.make("audioconvert", "audioconvert") decodebin.connect("pad-added", on_pad_added_audio, audioconvert) wavenc = Gst.ElementFactory.make("wavenc", "wav_encoder") splitmuxsink = Gst.ElementFactory.make("splitmuxsink", "splitmuxsink") splitmuxsink.set_property("location", self._output_file_prefix + "_%05d.wav") splitmuxsink.set_property("muxer", wavenc) splitmuxsink.set_property("max-size-time", 10000000000) splitmuxsink.connect("format-location-full", cb_format_location_audio, self) pipeline.add(decodebin) pipeline.add(audioconvert) pipeline.add(splitmuxsink) srcbin.link(decodebin) audioconvert.link(splitmuxsink) pipeline.set_state(Gst.State.PLAYING) |
第 3 步:集成
藍圖工作流使用隊列來處理實時 RTSP 流生成的視頻塊。這些視頻塊會與預定義的文本提示一起傳遞給 VLM。此外,該隊列還可用于處理音頻塊,并將其發送至 Riva NIM ASR API 進行轉錄。然后,生成的轉錄用作 VLM 的輸入文本提示。
AI 藍圖提取工作流目前在所有視頻塊中使用相同的輸入提示,詳情請參閱 使用 NVIDIA AI Blueprint 構建視頻搜索和摘要代理 。對管道進行了修改,以便在轉錄生成的問題中使用提示。當有人提出問題時,這會將流程從摘要任務轉移到特定視頻片段的 VQA 任務。我們還提高了管道的效率,因為如果沒有相應的音頻轉錄,它會跳過視頻塊的 VLM 推理。
然后,VLM 推理輸出會附加來自知識庫的信息,其中包含機械臂名稱等相關信息。然后,系統會將其發送至 LLM,以生成最終答案。完成 VLM 和 LLM 推理后,系統會將文本發送到 Riva TTS API 以創建音頻 .mp3 文件,而不是在 Web UI 上顯示生成的響應。然后,此文件將發送到本地 Windows 系統,在 VR 設置中為用戶播放。
視頻 1。觀看用戶與 Isaac Sim 的 Cortex UR10 Bin 堆疊模擬的交互演示
開始使用 NVIDIA AI Blueprint 進行視頻搜索和摘要
準備好使用 NVIDIA AI Blueprint 創建自己的 AI 智能體進行視頻搜索和摘要了嗎? 申請參與 Early Access Program 。
查看以下資源以了解詳情: