
計算機視覺模型的進步提供了更深入的見解,使我們的生活更加富有成效,我們的社區更加安全,我們的地球更加清潔。
例如,目標檢測可以告訴我們患者是在走路還是坐在地板上,但如果患者暈倒了,它卻不能提醒我們,我們離目標檢測還有很長的一段路要走。新的計算機視覺模型通過處理時間信息和預測動作來克服這些類型的挑戰。
從頭開始構建這些模型需要人工智能專業知識、大量訓練數據和大量計算能力。幸運的是,轉移學習使您能夠使用這些資源的一小部分構建自定義模型。
在本文中,我們將介紹使用 NGC 目錄中的 NVIDIA AI 軟件構建和部署計算機視覺應用程序的每個步驟,并在 Google Cloud Vertex AI Workbench 上運行該應用程序。
軟件和基礎架構
NGC catalog 提供 GPU 優化的 AI 框架、訓練和推理 SDK 以及預訓練模型,可通過現成的 Jupyter 筆記本輕松部署。
Google Cloud Vertex AI 工作臺 是整個 AI 工作流的單一開發環境。它通過與在生產中快速構建和部署模型所需的所有服務深度集成,加速了數據工程。
通過管理管道加快應用程序開發
NVIDIA 和 Google Cloud 已經合作,可以輕松地將軟件和模型從 NGC 目錄部署到 Vertex AI 工作臺。只需單擊一下即可使用 Jupyter 筆記本,而無需十幾個復雜的步驟,就可以輕松完成。
此快速部署功能以最佳配置在 Vertex AI 上啟動 JupyterLab 實例,預加載軟件依賴項,并一次性下載 NGC 筆記本。這使您能夠立即開始執行代碼,而不需要任何專業知識來配置開發環境。
擁有免費積分的谷歌云賬戶足以構建和運行此應用程序。
Live webinar
您也可以在 6 月 22 日參加我們的 live webinar ,我們將逐步指導您如何使用 NGC 目錄和 Vertex AI Workbench 中的軟件構建識別人類行為的計算機視覺應用程序。
開始
要跟進,您需要以下資源:
- 登記或簽名 進入 NGC 目錄
- 登錄 Google 云或注冊以接收 free credits
軟件
- NVIDIA TAO 工具包 :一個 AI 模型適應框架,用于使用自定義數據微調預訓練模型,并生成高度精確的計算機視覺、語音和語言理解模型。
- 動作識別模型 :一個五類行動識別網絡,用于識別人們在圖像中的行為。
- Action Recognition Jupyter Notebook :使用 TAO 工具包的 Action \ u Recognition \ u Net 的一個示例用例。
當您登錄到 NGC 目錄時,您將看到策劃的內容。
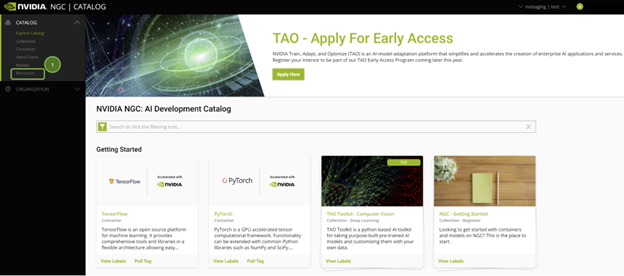
NGC 上的所有 Jupyter 筆記本電腦都托管在左窗格的 Resources 下。查找 TAO 動作識別 notebook.
有幾種方法可以開始使用此資源中的 Jupyter 筆記本示例:
- 下載資源,設置 GPU 實例(云或本地),并運行 setup 命令啟動 Jupyter notebook 。
- 在 筆記本產品頁 上或通過 Vertex AI 集合實體 選擇 部署到頂點 AI (圖 2 )。
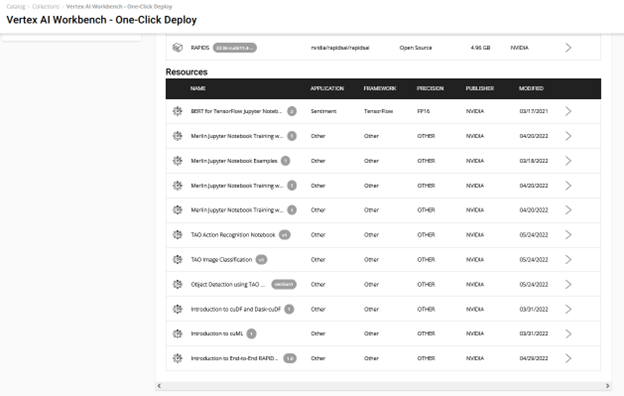
采用快速部署的簡單路線。它負責端到端的設置需求,如獲取 Jupyter 筆記本、配置 GPU 實例、安裝依賴項以及運行 JupyterLab 接口以快速開始開發!通過選擇 在 Vertex AI 上部署 進行嘗試。
您將看到一個窗口,其中包含有關資源和 AI 平臺的詳細信息。 Deploy 選項將通向 Google Cloud Vertex AI 平臺工作臺。
以下信息是預配置的,但可以根據資源的要求進行自定義:
- 筆記本的名稱
- 區域
- Docker 容器環境
- 機器類型,GPU 類型,GPU 數量
- 磁盤類型和數據大小
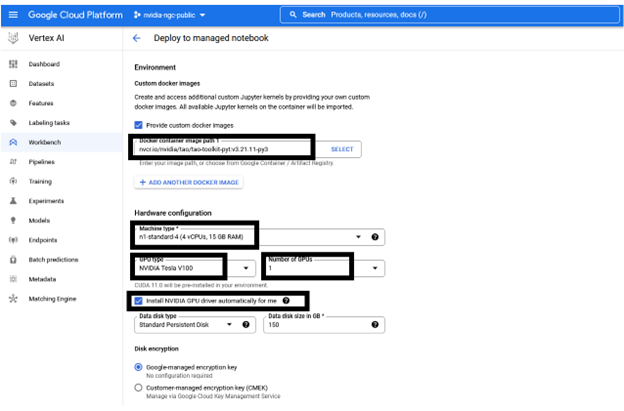
在選擇 Create 之前,您可以保持推薦的配置不變或根據需要進行更改。創建 GPU 計算實例和設置 JupyterLab 環境大約需要幾分鐘的時間。
要啟動界面,請選擇 Open 、 Open JupyterLab 。該實例加載了拉取的資源( Jupyter 筆記本),并將環境設置為 JupyterLab 中的內核。
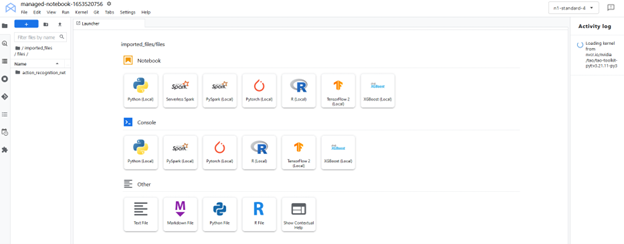
JupyterLab 接口從 NGC 提取資源(自定義容器和 Jupyter 筆記本)。在 JupyterLab 界面中選擇定制內核tao-toolkit-pyt。
運行筆記本
這個動作識別 Jupyter 筆記本展示了如何微調識別五種人類動作的動作識別模型。此數據集中有兩個操作使用它:fall-floor和ride-bike。
筆記本電腦利用 HMDB51 數據集微調從 NGC 目錄加載的預訓練模型。該筆記本還展示了如何在經過訓練的模型上運行推理,并將其部署到實時視頻分析框架 NVIDIA DeepStream 中。
設置環境變量
設置HOST_DATA_DIR、HOST_SPECS_DIR、HOST_RESULTS_D IR 和env-key 變量,然后執行單元格。數據、規格、結果文件夾和 Jupyter 筆記本位于\ action recognition net 文件夾中。
%env HOST_DATA_DIR=/absolute/path/to/your/host/data # note: You could set the HOST_SPECS_DIR to folder of the experiments specs downloaded with the notebook %env HOST_SPECS_DIR=/absolute/path/to/your/host/specs %env HOST_RESULTS_DIR=/absolute/path/to/your/host/results # Set your encryption key, and use the same key for all commands %env KEY = nvidia_tao
運行后續單元格下載 HMDB51 數據集并將其解壓縮到$HOST_DATA_DIR。預處理腳本剪輯視頻并從中生成光流,光流存儲在$HOST_DATA_DIR/processed_data 目錄中。
!wget -P $HOST_DATA_DIR "https://github.com/shokoufeh-monjezi/TAOData/releases/download/v1.0/hmdb51_org.zip" !mkdir -p $HOST_DATA_DIR/videos && unzip $HOST_DATA_DIR/hmdb51_org.zip -d $HOST_DATA_DIR/videos !mkdir -p $HOST_DATA_DIR/raw_data !unzip $HOST_DATA_DIR/videos/hmdb51_org/fall_floor.zip -d $HOST_DATA_DIR/raw_data !unzip $HOST_DATA_DIR/videos/hmdb51_org/ride_bike.zip -d $HOST_DATA_DIR/raw_data
最后,將數據集拆分為 train ,并通過運行以下代碼單元示例來測試和驗證內容,如 Jupyter 筆記本中所示:
# download the split files and unrar !wget -P $HOST_DATA_DIR https://github.com/shokoufeh-monjezi/TAOData/releases/download/v1.0/test_train_splits.zip !mkdir -p $HOST_DATA_DIR/splits && unzip $HOST_DATA_DIR/test_train_splits.zip -d $HOST_DATA_DIR/splits # run split_HMDB to generate training split !cd tao_toolkit_recipes/tao_action_recognition/data_generation/ && python3 ./split_dataset.py $HOST_DATA_DIR/processed_data $HOST_DATA_DIR/splits/test_train_splits/testTrainMulti_7030_splits $HOST_DATA_DIR/train $HOST_DATA_DIR/test
驗證最終測試和列車數據集:
!ls -l $HOST_DATA_DIR/train !ls -l $HOST_DATA_DIR/train/ride_bike !ls -l $HOST_DATA_DIR/test !ls -l $HOST_DATA_DIR/test/ride_bike

下載預訓練模型
您可以使用 NGC CLI 獲取經過預訓練的模型。有關更多信息,請轉至 NGC ,并在導航欄上選擇 SETUP 。
!ngc registry model download-version "nvidia/tao/actionrecognitionnet:trainable_v1.0" --dest $HOST_RESULTS_DIR/pretrained
檢查下載的模型。您應該看到resnet18_3d_rgb_hmdb5_32.tlt和resnet18_2d_rgb_hmdb5_32.tlt。
print("Check that model is downloaded into dir.")
!ls -l $HOST_RESULTS_DIR/pretrained/actionrecognitionnet_vtrainable_v1.0
培訓規范
在“等級庫”文件夾中,可以找到與訓練、評估、推斷和導出功能相關的不同等級庫文件。選擇train_rgb_3d_finetune.yaml文件,您可以更改此規范文件中的超參數,例如歷元數。
確保根據系統中數據和結果文件夾的路徑編輯規格文件中的路徑。
培訓模型
我們提供了一個在 HMDB5 數據集上訓練的預訓練 RGB-only 模型。使用預訓練模型,您甚至可以用更少的時間獲得更好的準確性。
print("Train RGB only model with PTM")
!action_recognition train \ -e $HOST_SPECS_DIR/train_rgb_3d_finetune.yaml \ -r $HOST_RESULTS_DIR/rgb_3d_ptm \ -k $KEY \ model_config.rgb_pretrained_model_path=$HOST_RESULTS_DIR/pretrained/actionrecognitionnet_vtrainable_v1.0/resnet18_3d_rgb_hmdb5_32.tlt \ model_config.rgb_pretrained_num_classes=5
評估模型
我們提供了兩種不同的樣本策略來評估視頻剪輯上的預訓練模型。
- 中心模式: 選取序列的中間幀進行推斷。例如,如果模型需要 32 幀作為輸入,而視頻剪輯有 128 幀,則從索引 48 到索引 79 中選擇幀進行推斷。
- conv mode: 從單個視頻中抽取 10 個序列并進行推斷。最終結果取平均值。
接下來,評估使用 PTM 培訓的 RGB 模型:
!action_recognition evaluate \ -e $HOST_SPECS_DIR/evaluate_rgb.yaml \ -k $KEY \ model=$HOST_RESULTS_DIR/rgb_3d_ptm/rgb_only_model.tlt \ batch_size=1 \ test_dataset_dir=$HOST_DATA_DIR/test \ video_eval_mode=center
video_eval_mode=center
Inferences
在本節中,您將運行動作識別推理工具,以使用經過訓練的 RGB 模型生成推理并打印結果。
與評估一樣,推理也有兩種模式:中心模式和轉換模式。最終輸出顯示視頻中的每個輸入序列標簽:[video_sample_path] [labels list for sequences in the video sample]
!action_recognition inference \ -e $HOST_SPECS_DIR/infer_rgb.yaml \ -k $KEY \ model=$HOST_RESULTS_DIR/rgb_3d_ptm/rgb_only_model.tlt \ inference_dataset_dir=$HOST_DATA_DIR/test/ride_bike \ video_inf_mode=center
您可以在此數據集上看到推理函數結果的示例。

結論
NVIDIA TAO 和預訓練模型通過消除從頭構建模型的需要,幫助您加快定制模型的開發。
借助 NGC catalog 的快速部署功能,您可以在幾分鐘內訪問環境以構建和運行計算機視覺應用程序。這使您能夠專注于開發,避免在基礎架構設置上花費時間。
?






