
語音識別技術在語音助手和機器人、通過輔助醫療或教育解決現實世界問題等方面越來越受歡迎。這有助于實現全球 speech AI 接入的民主化。隨著為獨特的新興語言標記的數據集變得越來越廣泛,開發人員可以輕松、準確、經濟地構建 AI 應用程序,以增強本地區的技術開發和體驗。
Kinyarwanda 是盧旺達、烏干達、剛果民主共和國和坦桑尼亞 980 萬人的母語,全球共有 2000 多萬人使用。
2022 年 4 月, Mozilla Common Voice (MCV) ,一個眾包項目,旨在使語音識別向所有人開放和可訪問,對構建基尼亞盧旺達數據集做出了重大貢獻,詳見文章 Lessons from Building for Kinyarwanda on Common Voice 。這是一個 57 GB 的數據集,有 2000 多小時的音頻,是 MCV 平臺上最大的數據集。
為了給開發人員帶來工作和數據集的價值,在此數據集上訓練了一個自動語音識別 ( ASR )模型,該模型在發布的檢查點上實現了最先進的性能。
本文概述了使用 NeMo ASR 工具包的培訓過程。它簡要介紹了數據集面臨的挑戰,使用 byte-pair encoding 將字符轉換為更長的單位,以及改進模型性能的訓練過程。開發者可以參考 GitHub 上的 step-by-step tutorial 了解參考代碼和詳細信息。
獲取數據集
MCV 擁有最大的公開多語言數據集。您可以從 Mozilla Common Voice Hub 下載特定語言的數據集。
在用于模型的 Kinyarwanda 數據集中,有 1404853 個句子被預先分解為 train/dev/test 數據。數據集中的每個條目都包含一個唯一的 MP3 文件和相應的信息,如文件名、轉錄和 TSV 格式的元信息。
NeMo ASR 要求數據包括單個音頻文件中的一組發音,以及描述數據集的清單,以及每行一個發音的信息。
一旦下載了數據集,在培訓分割中, TSV 文件將轉換為 JSON 清單, MP3 文件將轉換成 WAV 文件,這是 NeMo 工具包的推薦格式。然后分別對測試和開發數據重復相同的步驟。
清單格式如下所示:
{"audio_filepath": "/path/to/audio.wav", "text": "the transcription of the utterance", "duration": 23.147}數據預處理
在訓練模型之前,數據需要預處理,以減少模糊性和不一致性,并使數據易于解釋。此模型的預處理步驟為:
- 用空格替換所有標點符號(撇號除外)
- 將不同類型的撇號[””替換為 1
- 使所有文本小寫? 確保一致性
- 用變音符號替換罕見字符? ( [éè?ēê] → e 、 例如)?
- 刪除所有剩余的詞匯表字符
(例如,組合拉丁字母、空格和撇號)
由于 99% 的數據集的音頻持續時間為 11 秒或更短,建議在預處理期間將最大音頻持續時間限制為 11 秒,以加快訓練速度。
最后的基尼亞盧旺達語抄本由預處理后的拉丁字母、空格和撇號組成。
子字標記化
可以訓練基于字符的 ASR 模型,但它們會將每個字母視為一個單獨的令牌,生成輸出需要更多的時間。使用更長的單位可以提高質量和速度。
這個過程包括一個名為 byte-pair encoding 的標記化算法,它將單詞拆分為子標記,并用一個特殊符號標記單詞的開頭,這樣很容易恢復原始單詞。
為了簡化這個過程, NeMo 工具包通過將標記化器傳遞到模型配置來支持動態子字標記化,因此無需修改轉錄本。這不會影響模型性能,并且可能有助于在不重新訓練令牌化器的情況下適應其他域。
請訪問 GitHub 上的 NVIDIA/NeMo ,了解 NeMo ASR 子字標記化的詳細說明和教程。
培訓模式
兩種方法導致訓練模型。第一種方法涉及使用兩種模型架構從頭開始訓練模型: Conformer CTC 和 Conformer Transducer 。第二種方法包括
從不同的預訓練檢查點微調 Kinyarwanda Conformer 傳感器模型。
要訓練 Conformer CTC 模型,請使用 speech_to_text_ctc_bpe.py 和默認配置 conformer_ctc_bpe.yaml 。要訓練 Conformer 傳感器模型,請使用 speech_to_text_rnnt_bpe.py 和默認配置 automatic speech recognition 。
對于微調,請將預訓練的 STT_EN_Conformer_Transducer model 用于非自監督的檢查點。使用 SSL_EN_Conformer_Large 作為 NVIDIA GPU Cloud 的自我監督檢查點。您可以在 GitHub 上的分步教程中找到有關培訓過程的更多詳細信息。
下面提供了自監督檢查點初始化( SSL _ EN _ Conformer _ Large )的參考代碼。
import nemo.collections.asr as nemo_asr
ssl_model = nemo_asr.models.ssl_models.SpeechEncDecSelfSupervisedModel.from_pretrained(model_name='ssl_en_conformer_large')
# define fine-tune model
asr_model = nemo_asr.models.EncDecCTCModelBPE(cfg=cfg.model, trainer=trainer)
# load ssl checkpoint
asr_model.load_state_dict(ssl_model.state_dict(), strict=False)
del ssl_model
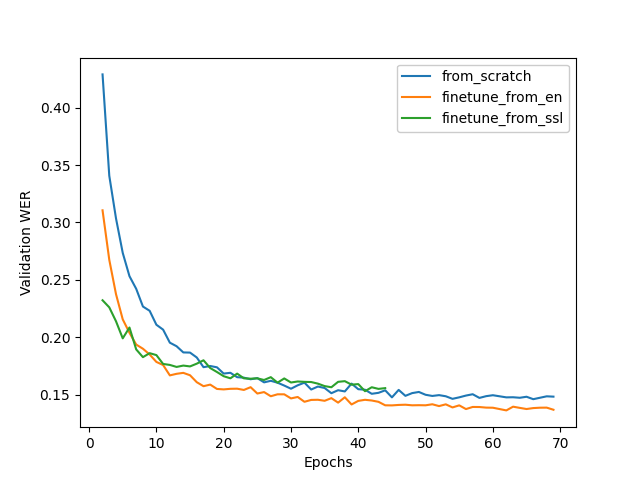
圖 1 顯示了訓練動態的比較。微調方法對于訓練來說既快速又容易,同時還可以加快收斂速度和提高質量。
測試結果
在構建模型時,目標是在轉錄語音輸入的同時最小化字錯誤率( WER )。簡單地說,單詞錯誤率是錯誤數除以單詞總數。? 它通常用于測試模型的性能,但不應成為唯一的標準,因為噪聲、回聲和口音等超出范圍的變量會對語音識別產生重大影響。
還考慮了字符錯誤率( CER )。 CER 給出了錯誤預測的字符百分比。我們的模型在基尼亞盧旺達 ASR 模型中 WER 和 CER 的百分比最低(表 1 )。
| Model | WER % | CER % |
| Conformer-CTC-Large | 18.73? | 5.75 |
| Conformer-Transducer-Large | 16.19 | 5.7? |
關鍵要點
我們使用 NeMo 工具包從頭開始構建了兩個高質量的基尼亞盧旺達檢查站。 Conformer-Transducer checkpoint 具有更好的質量,但 Conformer-CTC 的推理速度是 4x ,因此根據需要,它們都可能有用。?
預訓練模型的高性能是語音人工智能社區新發展的又一步。最先進的模型可以通過使用更多的數據對其進行微調來進一步改進,這些數據包含更多的方言、口音和稀有詞匯,是人們如何使用母語的真實表示。 NVIDIA NeMo 預訓練模型是開源的,滿足全球民主化和包容性的目標。
額外資源
探索 MVC 計劃,為您的語言訪問或提供語音數據。有關模型的更多信息,請參閱以下資源:
- 瀏覽 NeMo ASR Collection on NVIDIA GPU Cloud 并下載模型
- 下載 NeMo pretrained models
- 在 GitHub 上瀏覽 NeMo toolkit 以獲取示例代碼、示例和教程
與來自谷歌、 Meta 、 NVIDIA 等的專家一起參加第一屆年度 NVIDIA -Speech AI 峰會。 Register now.
?






