在 3GPP 第五代 (5G) 蜂窩標準中,第 1 層 (L1) 或物理層 (PHY) 是無線接入網 (RAN) 工作負載中計算密集程度最高的部分。它涉及一些非常復雜的數學運算,其中包含復雜的算法,例如信道估計和均衡、調制/解調和前向糾錯 (FEC).這些功能需要高計算密度,才能在不同的無線電條件下保持 5G 的低延遲要求和信號完整性。
傳統上,此層是使用專用硬件實現的,例如帶有數字信號處理 (DSP) 核心的專用集成電路 (ASIC).但是,這種方法有一些缺點,即無法擴展性能、硬件和軟件緊密合以及封閉的單一供應商解決方案。所有這些都導致部署和運行 RAN 的成本高昂。
為應對這些挑戰,該行業一直在向虛擬化 RAN (vRAN) 和開放 RAN (O-RAN) 架構轉變,使用基于 x86 CPU 的商用現成 (COTS) 服務器。人們期望這將降低成本,而由此產生的硬件和軟件分解將加快創新周期,引領云原生架構之路。
然而,由于 L1 的信號處理需求十分復雜,因此難以在基于 x86 CPU 的 COTS 服務器上實現理想的 vRAN 性能。為了解決這一 L1 性能差距,一些行業參與者正在構建固定功能加速器。示例包括獨立 ASIC、現場可編程門陣列 (FPGA) 或集成系統級芯片 (SoC).
固定功能加速器補充了 CPU 性能,并加速了從 vRAN L1 管道卸載的一組選定功能的處理,同時保留了 CPU 內的大部分 L1 處理。這是一種加速方法,在業內被稱為后備加速。
在許多方面,基于加速器的固定功能后備 vRAN 平臺與設備類的宏基站架構模型類似,后者缺乏可擴展性和敏捷性。我們的行業需要一個完全軟件定義的 vRAN,它可以提供可編程性、性能和軟件可擴展性,同時支持互操作性和多供應商解決方案(O-RAN 的關鍵原則)。
隨著人工智能和機器學習 (AI/ML) 成為塑造 5G 以外格局的關鍵驅動力之一,業界采用面向未來的 vRAN 平臺同樣重要。該平臺應準備好在現有 RAN 基礎設施上啟用 AI/ML 等新功能作為增強功能。
NVIDIA Aerial 平臺
NVIDIA Aerial 平臺將適用于 5G 的 NVIDIA Aerial vRAN 堆棧、AI 框架和加速計算基礎設施相結合。它通過使用 GPU 的高度可編程性和并行處理能力來實現主要優點。該平臺與傳統的固定功能后備加速方法的區別有兩個方面:
- 它不使用任何固定功能加速器
- NVIDIA Aerial 不是選擇性地將 L1 函數子集卸載到加速器,而是在 GPU 中實現整個 L1 處理管線,這種方法稱為在線加速。
NVIDIA Aerial vRAN 堆棧是完全可編程、軟件定義、支持 AI 的云原生 5G vRAN。有關 NVIDIA Aerial 入門指南的更多信息,請參閱 NVIDIA cuBB GPU Accelerated 5G vRAN,這是 2019 年世界移動通信大會的主題演講。
本文的目標是展示基于 GPU 的內聯架構 NVIDIA Aerial 的優點。我們解釋為什么可編程的內聯加速是提供高性能、高能效、可擴展的云原生 vRAN 的關鍵基礎。
了解后備和內聯加速模型
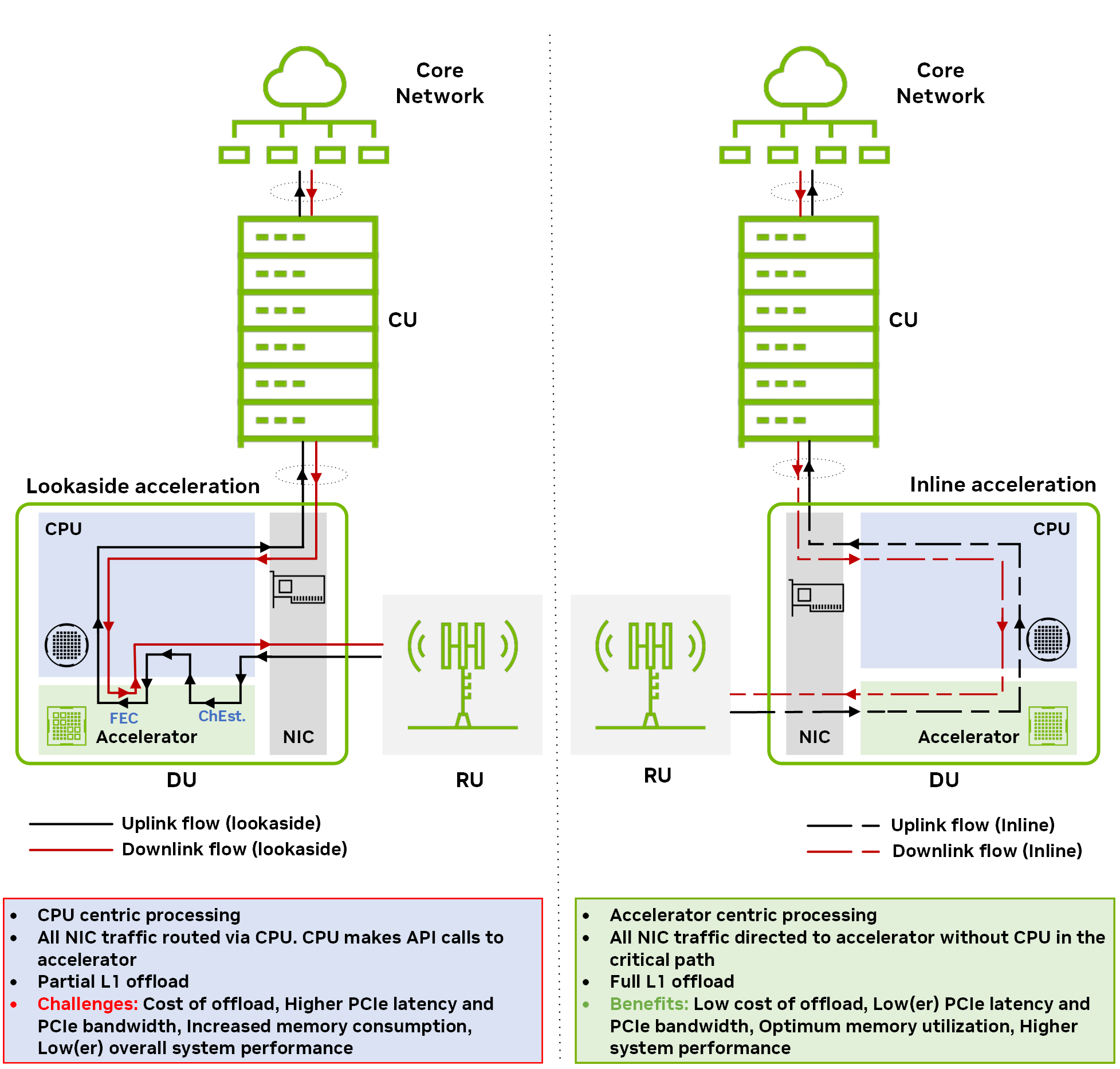
首先,研究 lookaside 和 Inline 加速模型的通用工作原理。
圖 1 展示了兩種不同加速模型的下行鏈路和上行鏈路方向的數據流:后備 和 內聯。想了解更多相關信息,請參閱 Hardware Acceleration for Open Radio Access Networks: A Contemporary Overview。
在后備加速模型中,主機 CPU 向加速器調用數據處理卸載,并在處理完成后接收返回的結果。后備方法需要在 CPU 和加速器之間來回傳輸數據。如果有多個非連續的功能塊卸載(例如 FEC 解碼和通道估計),則主機到設備數據傳輸的開銷和由此產生的內存帶寬消耗會大幅增加。
在內聯加速模型中,加速器直接與網絡接口卡 (NIC) 交換數據,而無需在關鍵路徑中涉及 CPU.對于內聯模型中的完整 L1 加速,整個 L1 處理將卸載到加速器中。
與后備加速不同,內聯加速不需要在主機和設備之間來回傳輸冗余數據。其最終效果是更高效地使用內存和 PCIe 帶寬。
可編程的內聯加速更適合 vRAN
詳細了解基于兩種加速方法的 vRAN 解決方案:
- 固定功能加速器
- 使用可編程加速器內聯
在本節中,我們重點介紹每種加速器的優點和局限性,并解釋為什么與固定功能加速器相比,可編程加速器的內聯方法更適合 vRAN.
- 卸載成本會影響延遲和性能
- 服務質量保證會增加復雜性
- 后備加速器集成為 PCIe 設備,不等同于內聯加速器
- 固定功能加速本質上不是云原生的
- 固定功能加速器缺乏可擴展性
- 固定功能加速器不靈活
卸載成本會影響延遲和性能
由于 CPU 和加速器之間 PCIe 接口中的請求/響應事務,后備加速會導致卸載成本。在多次來回事務(由于卸載一組非連續函數)的情況下,后備加速會增加 CPU 周期消耗和延遲,從而影響 perf/Watt 和 perf/$$.
為降低卸載成本,加速器驅動可能會將多個請求合并或批處理在一起。但是,這會導致不必要的緩沖和排隊,從而顯著提高各種用戶數據流的延遲。
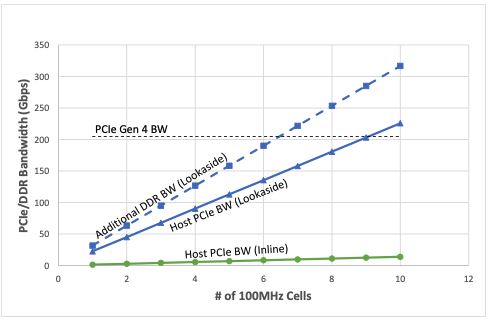
圖 2 顯示了隨著受支持的 4-transmit-4 -receive (4T4R) 100MHz 單元數量的增加,預期的主機 PCIe 和雙數據速率帶寬 (DDR BW) 消耗 (Gbps).該圖顯示,使用后備加速器部署時,支持四個下行鏈路 (DL) 層和兩個上行鏈路 (UL) 層(每個 100MHz 單元)所需的聚合事務帶寬要糟糕得多。與內聯加速器相比,所消耗的帶寬大約增加了 40 倍。
還值得一提的是,隨著單元數量的增加,PCIe 4.0 技術無法維持所需的帶寬,需要 PCIe 5.0 技術來支持后備加速器。
服務質量保證會增加復雜性
細粒度 QoS 支持各種用戶數據流是后備加速器面臨的另一個挑戰。PCIe 接口為滿足 QoS 需求所需的復雜隊列架構可能會導致性能下降,并影響加速器收到的排隊請求的尾部延遲。
以 DU 系統為例,該系統支持互聯網協議語音 (VoIP)、物聯網 (IoT)、增強型移動寬帶 (eMBB) 和超可靠的低延遲通信 (URLLC) 應用的混合用戶數據流。在后備模型中,如果 VoIP 或 URLLC 數據包被卡在加速器排隊的大量 eMBB 數據塊后面,就會產生顯著的延遲和抖動,并降低 QoS.隨著每次交易都需要通過后備加速器,這可能會隨著時間的推移而累積,從而導致嚴重的性能下降。
有一些方法可以通過 QoS 保證和跨 PCIe 界面的分層調度來解決這些問題。但是,這增加了硬件和軟件的復雜性,導致成本和能耗增加,以及基站容量降低。
為了進一步證明部署內聯加速器相比于觀察加速器在容量和能效方面的優勢,我們針對以下系統配置的兩個指標評估了兩種加速模式的性能:100 MHz、4T4R、4 個 DL/2 UL 層:
- 支持的 100MHz 單元數量
- MHz=每瓦層數
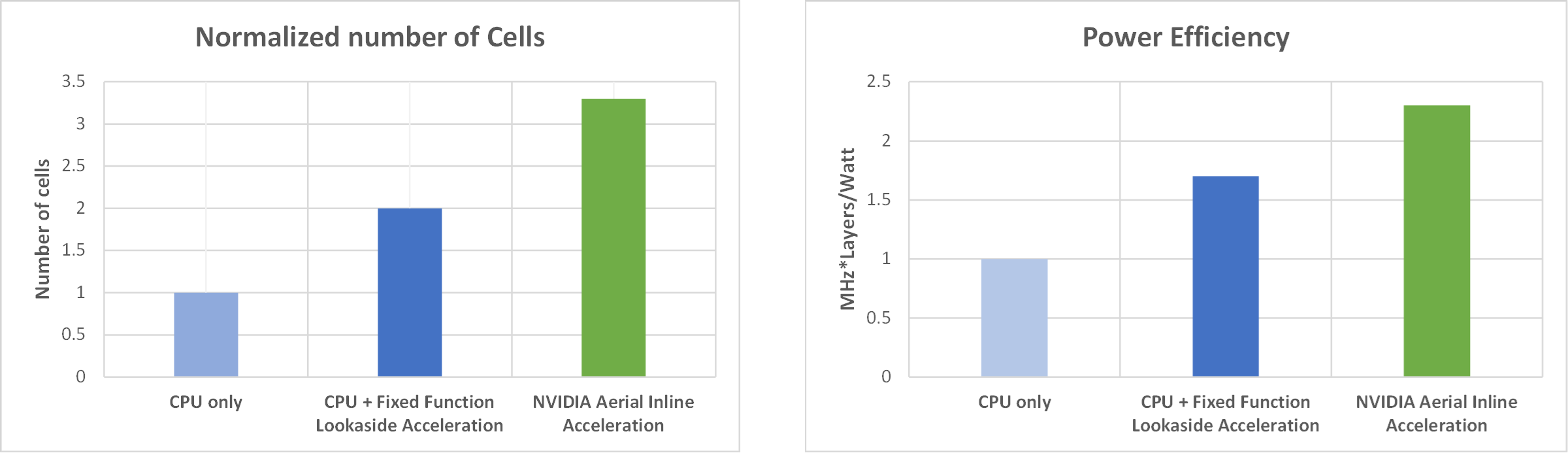
圖 3 顯示了性能比較,左側顯示支持的單元數量指標(標準化),右側顯示 MHz*層/瓦指標。對于每個指標,與固定功能后備加速器或無加速器(即僅使用 CPU)相比,在部署內聯加速器時,單元容量和能效優勢都很明顯。
后備加速器集成為 PCIe 設備,不等同于內聯加速器
有人認為,在 CPU 中集成后備加速器使其成為一種內聯架構。沒有什么能與事實相距甚遠。
雖然集成可能會限制功率優化并降低組件價格,但 CPU 中集成的任何固定功能后備加速器(例如 FEC)仍然顯示為 PCIe 設備,并通過 DPDK BBDEV 進行訪問。最終結果是,固定功能后備加速器(無論它們是獨立組件還是集成在 CPU 中)的效率都相同。
事實上,集成后備加速器會帶來一系列新問題:管理特定的 CPU 庫存單元 (SKU)、處理功能優先級、增加 CPU 成本等。
固定功能加速本質上不是云原生的
云計算的關鍵原則是,基礎設施資源可以跨應用共享,從而提高利用率,并提供更好的規模經濟效益。
固定功能加速器(例如基于 FPGA 的低密度奇偶校驗 (LDPC)、基于 SoC 的 L1 high-PHY 等)是單用途加速器。如果 5G vRAN 未使用固定功能加速器,則會浪費資源,不會被任何其他應用程序使用。
典型的 5G 網絡平均利用率低于 50%.這意味著固定功能的后備加速器只能位于云端,使用時間不會超過 50%.另一方面,GPU 等通用型可編程加速器可重復用于其他應用,例如大型語言模型 (LLM) 訓練和推理、計算機視覺和分析。
數據平面開發套件基帶設備 (DPDK BBDEV) 是一個常用于后備加速的應用程序編程接口 (API),但它不適合云原生部署。DPDK 包含許多專為高性能網絡設備設計的結構,包括:
- 大型分頁表
- 預分配緩沖區
- 固定顯存
- 單根輸入/輸出虛擬化 (SR-IOV)
- 以隊列為中心的 enqueue-dequeue 運算
但是,這些功能對底層硬件產生了強烈的親和力,無法以真正的云原生方式實現無縫的可移植性和工作負載移動。
固定功能加速器缺乏可擴展性
固定功能加速器(如 FEC LDPC、離散里葉變換 (DFT)、逆 DFT (iDFT) 和其他選定的基帶第 1 層函數)的一個主要缺點是,雖然它的大小可能適合一種配置或用例,但對于另一種配置來說則次優。
以 FEC LDPC 為例。在具有 4T4R 天線和 DDDSUUDDD 信道配置(D:下行鏈路、U:上行鏈路、S:特殊)和 4 個 DL/2 UL 層的典型 5G 頻率范圍 1 (FR1) sub-6 GHz 系統中,LDPC 解碼器可能占 UL 插槽中物理上行鏈路共享信道 (PUSCH) 工作負載的 25%左右。
在保持其他配置不變的情況下,如果系統維度從 4T4R 擴展到 64T64R 天線配置(大規模 MIMO),LDPC 解碼器在 PUSCH 管道上的計算負載不會相應增加。事實上,在這個更高維度的系統中,LDPC 約占總上行鏈路工作負載的 10%.
為什么會出現這種情況?這是因為 LDPC 解碼器的復雜性僅隨著層數呈線性擴展,而其他算法(例如信道估計或檢測)則以超線性方式擴展。如果在固定函數加速邏輯中實現這些函數,這很容易從資源利用率和功耗的角度導致次優設計。
固定功能加速器不靈活
固定功能加速器很難隨著 3GPP 版本(例如,具有新功能)的發展而發展,因為它們專為特定版本的規范而設計。在固定功能加速器上運行的這些復雜算法的升級很困難(尤其是在硬件中實施時),因此隨著時間的推移會限制改進。此外,硬件問題修復存在問題,通常會導致昂貴的替換,因為這是唯一可行的解決方案。
總結一下,固定功能后備加速有幾個缺點:影響性能和延遲、降低能效以及缺乏可編程性和可擴展性。這些問題直接導致電信運營商的資本支出 (CapEx) 和運營支出 (OpEx) 增加。
接下來,我們將討論 NVIDIA 采用的替代方法,該方法通過利用可編程性和內聯加速原則來解決之前強調的許多問題。該解決方案為行業領先的 vRAN 鋪平道路。
NVIDIA Aerial:適用于 vRAN 的基于 GPU 的可編程內聯加速
NVIDIA 采用了周全的架構方法,使用內聯架構將 L1 級負載全部卸載到可編程 GPU。該架構使用 Bluefield DPUs 將所有前傳增強型通用公共無線電接口 (eCPRI) 數據流量引入 GPU,而數據路徑中無需使用 CPU。
自然要問的一個問題是,為什么要使用 GPU?5G PHY 的信號處理要求在計算方面具有挑戰性,并因密集的矩陣運算而變得更加復雜。GPU 架構的大規模并行性為支持此類工作負載提供了合適的硬件資源。
從開發者的角度來看,GPU 的編程使用 CUDA 和 NVIDIA DLSS,這是一款在商業上非常成功的并行編程框架。這讓您的工作變得更加簡單,因為您可以使用成熟的工具和擴展庫進行軟件生命周期管理,包括規劃、設計、開發、優化、測試和維護。GPU 在計算復雜的 AI 和機器學習領域的廣泛應用證明了這一點。
第二個問題是,為什么選擇內聯架構?內聯架構將 vRAN L1 的全部處理負載轉移到 GPU,無需進行任何 CPU 交互。卸載的接口是功能應用程序平臺接口 (FAPI),這是在 Small Cell Forum (小基站論壇) 中制定的行業標準 SCF。完全卸載避免了 CPU 和加速器之間在主機 PCIe 接口上產生的復雜且低效的乒乓球效應,從而提高了性能并降低了之前介紹的延遲。
NVIDIA Aerial 實現完全可編程、云原生、支持 AI 的高性能端到端 L1 高 PHY (7.2 倍拆分) 內聯加速基于兩個基本原則:
- 加速計算
- 快速 I/O
通過組件 CUDA baseband (cuBB),加速計算提供了 GPU 加速的 5G L1 信號處理管線的軟件堆棧。cuBB 將所有 PHY 層處理保留在高性能 GPU 顯存內,從而提供前所未有的吞吐量和效率。cuBB 包含了針對 NVIDIA GPU 高度優化的 5G L1 高 PHY 加速庫 cuPHY,該庫通過使用 GPU 的強大計算能力和高度并行性,提供了無與倫比的可擴展性。
通過 NVIDIA DOCA,快速 I/O 實現了 GPUNetIO 模組。該模組通過在 GPU 顯存和內存之間直接交換數據包,提供了優化的 I/O 和數據包處理。 GPUDirect 支持 NVIDIA 的 ConnectX 智能網卡。實現快速 I/O 處理和直接內存訪問 (DMA) 技術對于充分發揮在線加速的潛力至關重要。
為實現這一目標,NVIDIA Aerial 平臺采用了以 GPU 為中心的方法,并使用 NVIDIA DOCA GPUetIO 庫實施。在這種方法中,NVIDIA GPU 使用 GPUDirect Async Kernel-initiated Network (GDAKIN) 通信,用于配置和更新網卡寄存器,以編排網絡收發操作,而無需 CPU 干預。有關更多信息,請參閱 Inline GPU Packet Processing with NVIDIA DOCA GPUNetIO。
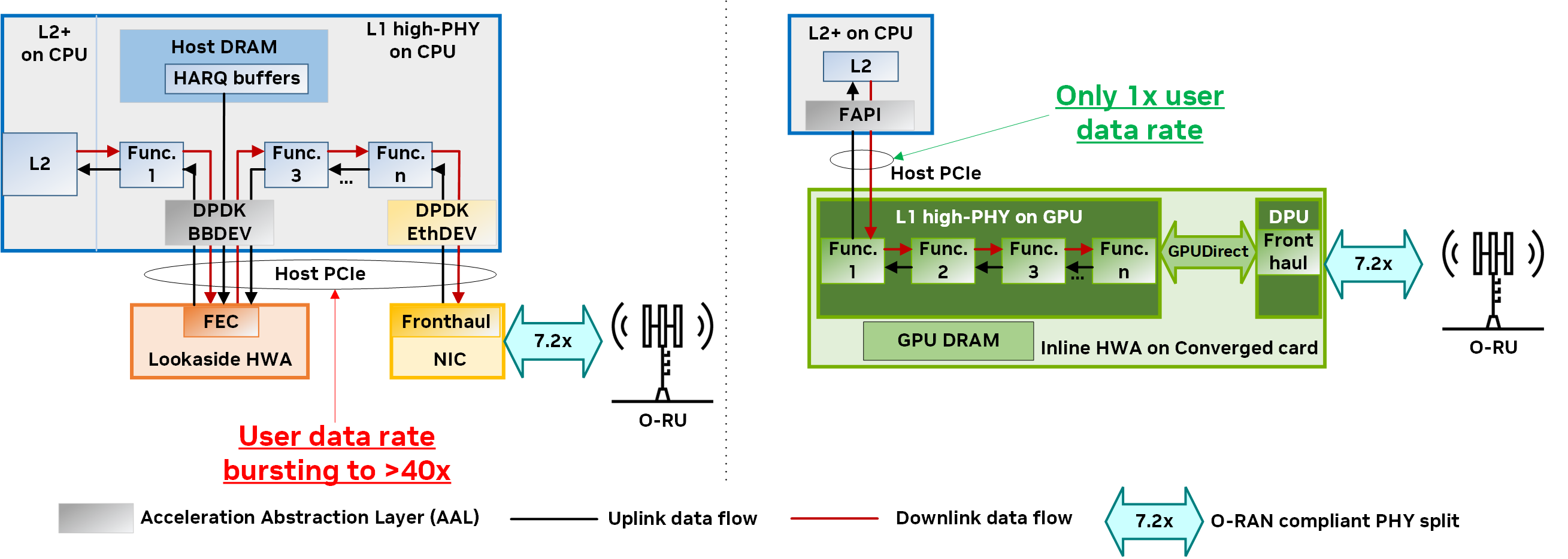
圖 4 顯示了使用 NVIDIA Aerial 的基于 GPU 的內聯加速實現與基于固定功能硬件加速器 (HWA) 的典型后備加速之間 PHY 層的架構比較。在右側, NVIDIA Aerial 平臺提供快速、高效和精簡的數據流,從 L2 到 L1 再到前回傳,無需 CPU 暫存副本或限制主機 PCIe 帶寬。
- L2 和 L1 (即 FAPI)之間的更高級別的加速抽象層 (AAL)
- 采用 GPU 和 DPU 的融合架構
- 由 NVIDIA DOCA GPUNetIO 和 GPUDirect 技術提供支持的互連技術
由于整個 L1 處理流程和相應的數據都包含在同一融合卡上的 GPU 內核和動態隨機存取內存 (DRAM) 中,因此 NVIDIA Aerial 不會使用 L2+ 級的關鍵共享資源(例如,主機 DRAM 或主機 PCIe),這與傳統的后備架構(左)有所不同。
在處理整個 L1 工作負載時, NVIDIA Aerial 平臺的 CPU 核心消耗更少,且具有高度的 GPU 并行性,可提供更低的資本性支出和運營性支出解決方案,并具有出色的性能、可擴展性、敏捷性、可編程性和能效。
NVIDIA Aerial 滿足了關鍵要求
表 1 簡要介紹了 5G vRAN 的關鍵要求、固定功能加速器的后備架構在滿足這些要求方面的局限性,以及 GPU 可編程加速器的內聯架構在解決這些缺點方面的優勢。
| 要求 | 固定功能后備架構 | GPU 可編程內聯架構 |
| 高性能和低延遲 | 跨 PCIe 的多個請求和響應會導致 CPU 消耗增加,并導致 perf/Watt 和 perf/$$更加糟糕。由于后備請求的批處理和排隊,L1 處理延遲更高。 | L2+L1+FH 簡化處理流程,不會通過 PCIe 進行來回交易,從而實現更好的 perf/Watt 和 perf/$$.L1 運行時期間無緩沖/排隊,從而優化 L1 處理延遲。 |
| 云經濟 | 不得重復使用:僅具有“固定”功能,且不可與云基礎設施中的其他應用共享。 | 完全可編程且通用,從而提高資源利用率。 |
| 應用程序可移植性 | DPDK BBDEV:由于與硬件的親和力強,因此不容易移植。 | FAPI:在 L2 和 L1 之間使用更高級別的抽象實現更好的可移植性。 |
| 可擴展性 | 針對特定系統配置進行設計和優化。 | 完全可編程和可擴展,適用于各種系統配置。 |
| 敏捷性 | 無法編程,設計周期長,并且難以根據不斷發展的標準和算法進行更新。 | 完全可編程和軟件定義,易于更新,以適應不斷發展的標準和新算法。 |
結束語
在本文中,我們重點介紹了固定功能加速器和后備處理模型的低效性。我們向您展示了后備模型如何影響性能和能效,以及許多可擴展性挑戰。
具有可編程加速器的內聯處理模型解決了固定功能后備加速模型的技術瓶頸,并在各種 RAN 配置中提供高性能、高能效和可擴展性。
NVIDIA Aerial 是唯一能夠實現新興 vRAN 關鍵原則的商用平臺:高性能、軟件定義、基于 COTS、云原生和 AI 就緒。它實現 GPU 可編程的內聯處理模型和完整的 L1 卸載,通過完全符合 O-RAN 標準的軟件架構為各種 RAN 配置和用例提供高效性能。
我們邀請您與我們合作,實現 RAN 基礎設施的現代化,并實現高效、高性能、可擴展、敏捷、云原生、完全軟件定義和 AI 就緒的 vRAN.
?