
光學字符檢測(OCD)和光學字符識別(OCR)是用于從圖像中提取文本的計算機視覺技術。不同行業的使用情況各不相同,包括從掃描的文檔或帶有手寫文本的表格中提取數據、自動識別車牌、根據序列號對履行中心中的箱子或物體進行分類、根據零件號識別組裝線上要檢查的部件等。
OCR 應用于許多行業,包括金融服務、醫療保健、物流、工業檢測和智能城市。OCR 通過自動化手動任務,提高了企業的生產效率和運營效率。
為了有效,OCR 必須達到或超過人類水平的準確性。由于它所涉及的獨特用例,它本身就很復雜。例如,當 OCR 分析文本時,文本可以在字體、大小、顏色、形狀和方向上變化,可以是手寫的,也可以具有其他噪聲,如部分遮擋。在測試環境中微調模型對于保持高精度和降低錯誤率變得極其重要。
NVIDIA TAO 工具包 是一個低代碼人工智能工具包,可以幫助開發人員為許多視覺人工智能應用程序定制和優化模型。NVIDIA 在 TAO 5.0 中引入了用于自動字符檢測和識別的新模型和功能。這些模型和功能將加速創建自定義 OCR 解決方案。有關更多詳細信息,請參閱 Access the Latest in Vision AI Model Development Workflows with NVIDIA TAO Toolkit 5.0。
本文是關于使用 NVIDIA TAO 和預訓練模型創建和部署自定義 AI 模型以準確檢測和識別手寫文本的系列文章的一部分。這一部分解釋了使用 TAO 對字符檢測和識別模型的訓練和微調。第二部分將引導您完成使用 NVIDIA Triton 部署模型的步驟。所提供的步驟可用于任何其他 OCR 任務。
NVIDIA TAO OCD/OCR 工作流程
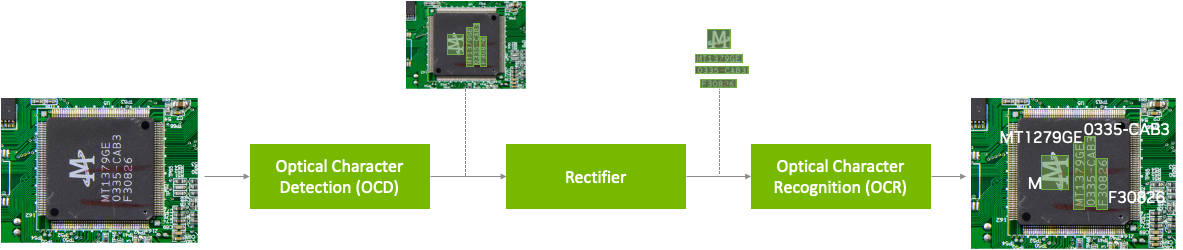
預訓練的模型已經在大型數據集上進行了訓練,并且可以使用額外的數據進行進一步的微調,以完成特定的任務。光學字符檢測網絡(OCDNet)是一個 TAO 預訓練模型,用于檢測具有復雜背景的圖像中的文本。它使用一種稱為可微分二值化的過程來幫助準確定位各種形狀、大小和字體的文本。結果是具有檢測到的文本的邊界框。
文本整流器是一種中間件,在推理階段充當字符檢測和字符識別之間的橋梁。它的主要功能是提高識別極端角度文本中字符的準確性。為了實現這一點,文本整流器將覆蓋文本區域的多邊形頂點和原始圖像作為輸入。
光學字符識別網絡(OCRNet)是另一個 TAO 預訓練模型,可用于識別位于檢測到的邊界框區域中的文本字符。該模型將圖像作為網絡輸入,并生成一系列字符作為輸出。
先決條件
要繼續學習本教程,您需要以下內容:
- 一個NGC account
- 這是一個樣品 Jupyter notebook,用于訓練 OCD 和 OCR 模型。
- NVIDIA TAO Toolkit 5.0(包含在 Jupyter 筆記本電腦中的安裝說明)。有關一組完整的依賴項和先決條件,請參閱 TAO Toolkit 快速啟動指南。
下載數據集
本教程對 OCD 和 OCR 模型進行了微調,以檢測和識別手寫字母。它使用了IAM Handwriting Database,這是一個包含各種手寫英文文本文檔的大型數據集。這些文本樣本將用于訓練和測試 OCD 和 OCR 模型的手寫文本識別器。
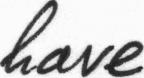
若要訪問此數據集,請在IAM 注冊頁面進行注冊。
注冊后,從下載頁面開始:
- 數據/asci.tgz
- 數據/表格 A-D.tgz
- 數據/表格-H.tgz
- 數據/表格-Z.tgz
以下部分探討了 Jupyter 筆記本的各個方面,以深入研究 OCDNet 和 OCRNet 的微調過程,從而檢測和識別手寫字符。
請注意,此數據集可能僅用于非商業性研究目的。想要了解更多信息,請訪問IAM 手寫數據庫。
運行筆記本
OCDR Jupyter 筆記本展示了如何將 OCD 和 OCR 模型微調為 IAM 手寫數據集。它還展示了如何在經過訓練的模型上運行推理并執行部署。
設置環境變量
在 Jupyter 筆記本中設置以下環境變量以匹配當前目錄,然后執行:
%env LOCAL_PROJECT_DIR=home/<username>/ocdr_notebook
%env NOTEBOOK_DIR=home/<username>/ocdr_notebook
# Set this path if you don't run the notebook from the samples directory.
%env NOTEBOOK_ROOT=home/<username>/ocdr_notebook將生成以下文件夾:
- 主機數據 包含了用于模型訓練的訓練/測試分割數據。
- 主機規范目錄 包含了規范文件,這些文件中包含了 TAO 用于執行訓練、推理、評估和模型部署的超參數。
- 主機結果目錄 包含經過微調的 OCD 和 OCR 模型的結果。
- 預數據 是指下載的手寫數據集文件的位置。這個路徑將被用來預處理 OCD/OCR 模型訓練的數據。
TAO 啟動器在運行任務時使用 Docker 容器。要使數據和結果對 Docker 可見,請使用~/.tao_mounts.json文件運行 Jupyter 筆記本中的單元格以生成~/.tao_mounts.json文件
該環境現在可以與 TAO Launcher 一起使用了。接下來的步驟將為 TAO OCD 模型訓練準備正確格式的手寫數據集。
為 OCD 和 OCR 準備數據集
按照以下步驟預處理 IAM 手寫數據集以匹配 TAO 圖像格式。注意,在 TAO 中用于 OCD 和 OCR 模型訓練的文件夾結構中, /img容納手寫圖像數據,以及/gt包含在每個圖像中發現的字符的基本真相標簽。
|── train
| ├──img
| ├──gt
|── test
| ├──img
| ├──gt首先將下載的四個.tgz 文件移動到$PRE_DATA_DIR目錄如果您遵循與上面相同的步驟,.tgz 文件將被放置在/data/iamdata.
從這些文件中提取圖像和地面實況標簽。隨后的單元格將提取圖像文件,并在運行時將其移動到正確的文件夾格式。
!tar -xf $PRE_DATA_DIR/ascii.tgz --directory $PRE_DATA_DIR/ words.txt
# Create directories to hold the image data and ground truth files.
!mkdir -p $PRE_DATA_DIR/train/img
!mkdir -p $PRE_DATA_DIR/test/img
!mkdir -p $PRE_DATA_DIR/train/gt
!mkdir -p $PRE_DATA_DIR/test/gt
# Unpack the images, let's use the first two groups of images for training, and the last for validation.
!tar -xzf $PRE_DATA_DIR/formsA-D.tgz --directory $PRE_DATA_DIR/train/img
!tar -xzf $PRE_DATA_DIR/formsE-H.tgz --directory $PRE_DATA_DIR/train/img
!tar -xzf $PRE_DATA_DIR/formsI-Z.tgz --directory $PRE_DATA_DIR/test/img數據現在已正確組織。然而,IAM 數據集使用的基本事實標簽目前采用以下格式:
a01-000u-00-00 ok 154 1 408 768 27 51 AT A
# a01-000u-00-00 -> word id for line 00 in form a01-000u
# ok -> result of word segmentation
# ok: word was correctly
# er: segmentation of word can be bad
#
# 154 -> graylevel to binarize the line containing this word
# 1 -> number of components for this word
# 408 768 27 51 -> bounding box around this word in x,y,w,h format
# AT -> the grammatical tag for this word, see the
# file tagset.txt for an explanation
# A -> the transcription for this word
這個words.txt文件如下所示:
0 1
0 a01-000u-00-00 ok 154 408 768 27 51 AT A
1 a01-000u-00-01 ok 154 507 766 213 48 NN MOVE
2 a01-000u-00-02 ok 154 796 764 70 50 TO to
...
目前,words.txt使用四點坐標系在圖像中的單詞周圍繪制邊界框。 TAO 要求使用八點坐標系在檢測到的文本周圍繪制邊界框。
要將數據轉換為八點坐標系,請使用extract_columns和process_text_file筆記本第 2.1 節中提供的功能。words.txt將被轉換為以下 DataFrame,并準備在 OCDNet 模型上進行微調。
filename x y x2 y2 x3 y3 x4 y4 word
0 gt_a01-000u.txt 408 768 435 768 435 819 408 819 A
1 gt_a01-000u.txt 507 766 720 766 720 814 507 814 MOVE
2 gt_a01-000u.txt 796 764 866 764 866 814 796 814 to
...為了為 OCRNet 準備數據集,必須將原始圖像數據和標簽轉換為 LMDB 格式,LMDB 格式將圖像和標簽轉換成鍵值內存數據庫。
# Convert the raw train and test dataset to lmdb
print("Converting the training set to LMDB.")
!tao model ocrnet dataset_convert -e $SPECS_DIR/ocr/experiment.yaml \
dataset_convert.input_img_dir=$DATA_DIR/train/processed \
dataset_convert.gt_file=$DATA_DIR/train/gt.txt \
dataset_convert.results_dir=$DATA_DIR/train/lmdb
# Convert the raw test dataset to lmdb
print("Converting the testing set to LMDB.")
!tao model ocrnet dataset_convert -e $SPECS_DIR/ocr/experiment.yaml \
dataset_convert.input_img_dir=$DATA_DIR/test/processed \
dataset_convert.gt_file=$DATA_DIR/test/gt.txt \
dataset_convert.results_dir=$DATA_DIR/test/lmdb
數據現在已經處理完畢,可以在 OCDNet 和 OCRNet 預訓練模型上進行微調。
創建自定義字符檢測(OCD)模型
NGC CLI 將用于下載經過預訓練的 OCDNet 模型。想要了解更多信息,請訪問 NGC,然后點擊導航欄中的“設置”。
下載 OCDNet 預訓練模型
!mkdir -p $HOST_RESULTS_DIR/pretrained_ocdnet/
# Pulls pretrained models from NGC
!ngc registry model download-version nvidia/tao/ocdnet:trainable_resnet18_v1.0 --dest $HOST_RESULTS_DIR/pretrained_ocdnet/您可以使用以下調用檢查模型是否已下載到/pretained_ocdnet/:
print("Check that model is downloaded into dir.")
!ls -l $HOST_RESULTS_DIR/pretrained_ocdnet/ocdnet_vtrainable_resnet18_v1.0
OCD 訓練規范
在 specs 文件夾中,可以找到與兩個模型的訓練、評估、推斷和導出數據的方式相關的不同文件。對于訓練 OCDNet,您將使用 specs/ocd 文件夾中的 train.yaml 文件。您可以在這個規范文件中嘗試更改不同的超參數,例如紀元的數量。
下面是一些可以進行實驗的配置的代碼示例:
num_gpus: 1
model:
load_pruned_graph: False
pruned_graph_path: '/results/prune/pruned_0.1.pth'
pretrained_model_path: '/data/ocdnet/ocdnet_deformable_resnet18.pth'
backbone: deformable_resnet18
train:
results_dir: /results/train
num_epochs: 300
checkpoint_interval: 1
validation_interval: 1
...
訓練角色檢測模型
既然已經配置了規范文件,請提供規范文件、預訓練模型和結果的路徑:
#Train using TAO Launcher
#print("Run training with ngc pretrained model.")
!tao model ocdnet train \
-e $SPECS_DIR/train.yaml \
-r $RESULTS_DIR/train \
model.pretrained_model_path=$DATA_DIR/ocdnet_deformable_resnet18.pth培訓輸出如下所示。請注意,此步驟可能需要一些時間,具體取決于train.yaml.
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
| Name | Type | Params
--------------------------------
0 | model | Model | 12.8 M
--------------------------------
12.8 M Trainable params
0 Non-trainable params
12.8 M Total params
51.106 Total estimated model params size (MB)
Training: 0it [00:00, ?it/s]Starting Training Loop.
Epoch 0: 100%|█████████| 751/751 [19:57<00:00, 1.59s/it, loss=1.61, v_num=0]評估模型
接下來,評估在 IAM 數據集上訓練的 OCDNet 模型。
# Evaluate on model
!tao model ocdnet evaluate \
-e $SPECS_DIR/evaluate.yaml \
evaluate.checkpoint=$RESULTS_DIR/train/model_best.pth評估輸出如下所示:
test model: 100%|██████████████████████████████| 488/488 [06:44<00:00, 1.21it/s]
Precision: 0.9412259824693795
Recall: 0.8738614928590677
Hmean: 0.9062936622138628
Evaluation finished successfully.
OCD 推斷
推理工具生成帶注釋的圖像輸出和包含預測信息的.txt 文件。運行下面的推理工具,在 OCDNet 模型上生成推理,并可視化檢測到的文本的結果。
# Run inference using TAO
!tao model ocdnet inference \
-e $SPECS_DIR/ocd/inference.yaml \
inference.checkpoint=$RESULTS_DIR/ocd/train/model_best.pth \
inference.input_folder=$DATA_DIR/test/img \
inference.results_dir=$RESULTS_DIR/ocd/inference圖 3 顯示了 OCDNet 對測試樣本圖像的推斷。

導出 OCD 模型以進行部署
最后一步是將 OCD 模型導出為 ONNX 格式以進行部署。
!tao model ocdnet export \
-e $SPECS_DIR/export.yaml \
export.checkpoint=$RESULTS_DIR/train/model_best.pth \
export.onnx_file=$RESULTS_DIR/export/model_best.onnx創建自定義字符識別(OCR)模型
現在您已經有了經過訓練的 OCDNet 模型來檢測并將邊界框應用于手寫文本區域,請使用 TAO 微調 OCRNet 模型以識別和分類檢測到的字母。
下載 OCRNet 預訓練模型
在 Jupyter 筆記本中繼續,OCRNet 預訓練模型將從 NGC CLI 中提取。
!mkdir -p $HOST_RESULTS_DIR/pretrained_ocrnet/
# Pull pretrained model from NGC
!ngc registry model download-version nvidia/tao/ocrnet:trainable_v1.0 --dest $HOST_RESULTS_DIR/pretrained_ocrnetOCR 培訓規范
OCRNet 將使用 experiment.yaml 規范文件進行訓練。您可以更改訓練超參數,如批量大小、時期數量和學習率,如下所示:
dataset:
train_dataset_dir: []
val_dataset_dir: /data/test/lmdb
character_list_file: /data/character_list
max_label_length: 25
batch_size: 32
workers: 4
train:
seed: 1111
gpu_ids: [0]
optim:
name: "adadelta"
lr: 0.1
clip_grad_norm: 5.0
num_epochs: 10
checkpoint_interval: 2
validation_interval: 1
訓練字符識別模型
在數據集上訓練 OCRNet 模型。您還可以在 train 命令中配置 spec 參數,如歷元數或學習率,如下所示。
!tao model ocrnet train -e $SPECS_DIR/ocr/experiment.yaml \
train.results_dir=$RESULTS_DIR/ocr/train \
train.pretrained_model_path=$RESULTS_DIR/pretrained_ocrnet/ocrnet_vtrainable_v1.0/ocrnet_resnet50.pth \
train.num_epochs=20 \
train.optim.lr=1.0 \
dataset.train_dataset_dir=[$DATA_DIR/train/lmdb] \
dataset.val_dataset_dir=$DATA_DIR/test/lmdb \
dataset.character_list_file=$DATA_DIR/train/character_list.txt
輸出將類似于以下內容:
...
Epoch 19: 100%|█| 3605/3605 [08:04<00:00, 7.44it/s, loss=0.0368, v_num=1, val_lCurrent_accuracy : 0.778
Best_accuracy : 0.727
+----------------+--------------+---------------------+
| Ground Truth | Prediction | Confidence && T/F |
|----------------+--------------+---------------------|
| at | al | 0.2867 False |
| home | home | 0.7792 True |
| . | . | 0.9828 True |
| there | there | 0.5470 True |
| had | had | 0.6234 True |
+----------------+--------------+---------------------+
評估模
您可以根據 OCRNet 模型的字符識別準確性來評估該模型。識別準確率只是指文本區域中正確識別的所有字符的百分比。
!tao model ocrnet evaluate -e $SPECS_DIR/ocr/experiment.yaml \
evaluate.results_dir=$RESULTS_DIR/ocr/evaluate \
evaluate.checkpoint=$RESULTS_DIR/ocr/train/best_accuracy.pth \
evaluate.test_dataset_dir=$DATA_DIR/test/lmdb \
dataset.character_list_file=$DATA_DIR/train/character_list.txt評價
輸出應類似于以下內容:
data directory: /data/iamdata/test/lmdb num samples: 37109
Accuracy: 77.8%
OCR 推斷
OCR 推斷將從邊界框中生成已識別字符的序列輸出,如下所示。
!tao model ocrnet inference -e $SPECS_DIR/ocr/experiment.yaml \
inference.results_dir=$RESULTS_DIR/ocr/inference \
inference.checkpoint=$RESULTS_DIR/ocr/train/best_accuracy.pth \
inference.inference_dataset_dir=$DATA_DIR/test/processed \
dataset.character_list_file=$DATA_DIR/train/character_list.txt
+--------------------------------------+--------------------+--------------------+
| image_path | predicted_labels | confidence score |
|--------------------------------------+--------------------+--------------------|
| /data/test/processed/l04-012_28.jpg | lelly | 0.3799 |
| /data/test/processed/k04-068_26.jpg | not | 0.9644 |
| /data/test/processed/l04-062_58.jpg | set | 0.9542 |
| /data/test/processed/l07-176_39.jpg | boat | 0.4693 |
| /data/test/processed/k04-039_39.jpg | . | 0.9286 |
+--------------------------------------+--------------------+--------------------+
導出 OCR 模型以進行部署
最后,將 OCD 模型導出為 ONNX 格式以進行部署。
!tao model ocrnet export -e $SPECS_DIR/ocr/experiment.yaml \
export.results_dir=$RESULTS_DIR/ocr/export \
export.checkpoint=$RESULTS_DIR/ocr/train/best_accuracy.pth \
export.onnx_file=$RESULTS_DIR/ocr/export/ocrnet.onnx \
dataset.character_list_file=$DATA_DIR/train/character_list.txt
結果
表 1 詳細介紹了本文中提到的兩個模型的準確性和性能。字符檢測模型在 ICDAR 預訓練的 OCDNet 模型上進行了微調,字符識別模型則在 Uber-text OCRNet 預訓練模型上進行了微調。ICDAR 和 Uber 文本是公開可用的數據集,我們分別用于預訓練 OCDNet 和 OCRNet 模型。這兩種模型都可以在 NGC 上找到。
| ? | OCDNet | OCRNet |
| 數據集 | IAM Handwritten Dataset | |
| 神經網絡架構 | 可變形 Conv ResNet18 | ResNet50 |
| 精確 | 90% | 78% |
| 推理分辨率 | 1024×1024 | 1x32x100 |
| NVIDIA L4 上的推理性能(FPS) GPU | 125 幀/秒(BS=1) | 8030(BS=128) |
總結
這篇文章解釋了在 NVIDIA TAO 中創建自定義字符檢測和識別模型的端到端工作流程。您可以從 NGC 的字符檢測(OCDNet)和字符識別(OCRNet)的預訓練模型開始。然后使用 TAO 在自定義數據集上對其進行微調,并導出模型進行推理。
請繼續閱讀第二部分,了解如何使用 NVIDIA Triton 將此模型部署到生產中的分步演練。
?




