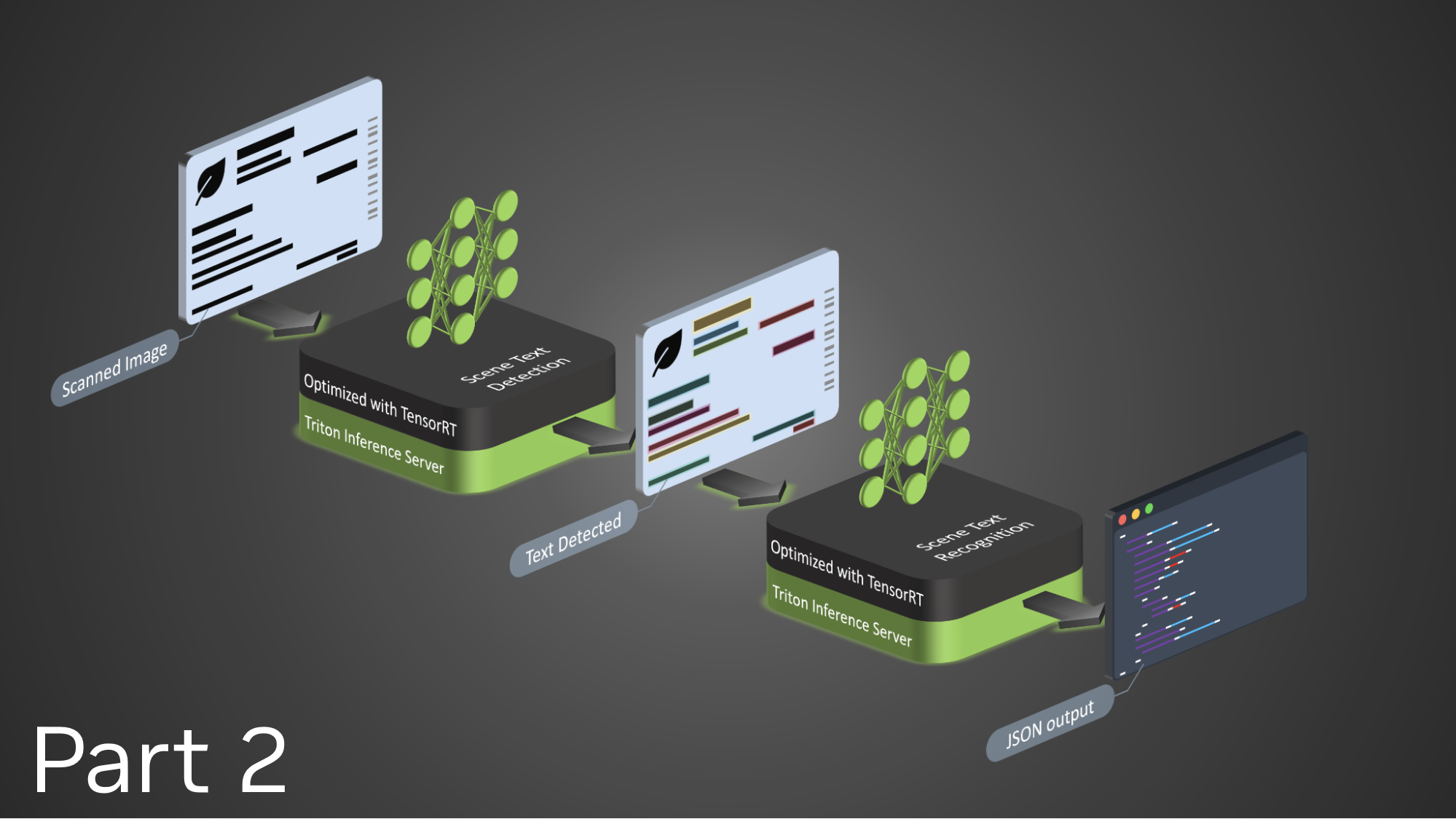
NVIDIA Triton Inference Server 通過使團隊能夠在任何基于 GPU 或 CPU 的基礎設施上部署、運行和擴展經過訓練的 ML 或 DL 模型,簡化和標準化 AI 推理。它幫助開發人員在云端、本地、邊緣和嵌入式設備上提供高性能推理。
nvOCDR 庫已集成到 Triton 中進行推理。nvOCDR 庫封裝了用于光學字符檢測和識別(OCD/OCR)的整個推理管道。該庫使用在 TAO Toolkit 上訓練的 OCDNet 和 OCRNet 模型。想要了解更多詳細信息,請參閱 nvOCDR 文檔。
本文是關于使用 NVIDIA TAO 和預訓練模型創建和部署自定義 AI 模型以準確檢測和識別手寫文本的系列文章的一部分。第一部分 解釋了如何使用 TAO 對字符檢測和識別模型進行訓練和微調。本部分將引導您完成使用 NVIDIA Triton 部署模型的步驟。所提供的步驟可用于任何其他 OCR 任務。
使用 OCD/OCR 模型構建 Triton 樣本
以下步驟顯示了在 Triton 推理服務器中使用 Docker 圖像構建和使用 OCD/OCR 模型的簡單推薦方法。
步驟 1:準備 ONNX 模型
一旦你按照ocdnet.ipynb和ocrnet.ipynb要完成模型訓練和導出,可以獲得兩個 ONNX 模型,例如ocdnet.onnx和ocrnet.onnx.(在ocdnet.ipynb?里,導出的 ONNX 命名為model_best.onnx在里面ocrnet.ipynb,導出的 ONNX 命名為best_accuracy.onnx)
# bash commands
$ mkdir onnx_models
$ cd onnx_models
$ cp <ocd results dir>/export/model_best.onnx ./ocdnet.onnx
$ cp <ocr results dir>/export/best_accuracy.onnx ./ocrnet.onnx
字符列表文件,生成于ocrnet.ipynb,也是必需的:
$ cp <ocr DATA_DIR>/character_list ./步驟 2:獲取 nvOCDR 存儲庫
要獲取 nvOCDR 存儲庫,請使用以下腳本:
$ git clone https://github.com/NVIDIA-AI-IOT/NVIDIA-Optical-Character-Detection-and-Recognition-Solution.git步驟 3:構建 Triton 服務器 Docker 映像
Triton 服務器和客戶端 Docker 鏡像的構建過程可以通過運行相關腳本自動啟動:
$ cd NVIDIA-Optical-Character-Detection-and-Recognition-Solution/triton
# bash setup_triton_server.sh [input image height] [input image width] [OCD input max batchsize] [DEVICE] [ocd onnx path] [ocr onnx path] [ocr character list path]
$ bash setup_triton_server.sh 1024 1024 4 0 ~/onnx_models/ocd.onnx ~/onnx_models/ocr.onnx ~/onnx_models/ocr_character_list步驟 4:構建 Triton 客戶端 Docker 鏡像
使用以下腳本構建 Triton 客戶端 Docker 映像:
$ cd NVIDIA-Optical-Character-Detection-and-Recognition-Solution/triton
$ bash setup_triton_client.sh
步驟 5:運行 nvOCDR Triton 服務器
在構建 Triton 服務器和 Triton client Docker 鏡像后,創建一個容器并啟動 Triton’服務器:
$ docker run -it --net=host --gpus all --shm-size 8g nvcr.io/nvidian/tao/nvocdr_triton_server:v1.0 bash接下來,修改 nvOCDR-lib 的配置文件。nvOCDR-lib 可以支持高分辨率輸入圖像(4000 x 4000 或更大)。如果您的輸入圖像很大,您可以在 Triton 服務器容器中將配置文件更改為/opt/nvocdr/ocdr/triton/models/nvOCDR/spec.json,以支持高分辨率圖像推斷。
# to support high resolution images
$ vim /opt/nvocdr/ocdr/triton/models/nvOCDR/spec.json
"is_high_resolution_input": true,
"resize_keep_aspect_ratio": true,
這個resize_keep_aspect_ratio將自動設置為 Trueis_high_resolution_input為 True。如果您要推斷分辨率較小的圖像(例如 640 x 640 或 960 x 1280),您可以設置 is_high_resolution_input為 False。
在容器中,運行以下命令以啟動 Triton 服務器:
$ CUDA_VISIBLE_DEVICES=<gpu idx> tritonserver --model-repository /opt/nvocdr/ocdr/triton/models/
步驟 6:發送推理請求
在一個單獨的控制臺中,從 Triton 客戶端容器啟動 nvOCDR 示例:
$ docker run -it --rm -v <path to images dir>:<path to images dir> --net=host nvcr.io/nvidian/tao/nvocdr_triton_client:v1.0 bash
啟動推理:
$ python3 client.py -d <path to images dir> -bs 1

結論
NVIDIA TAO 5.0 介紹了光學字符檢測(OCD)和光學字符識別(OCR)的幾個功能和模型。本文介紹了自定義和微調預訓練模型的步驟,以準確識別 IAM 數據集上的手寫文本。該模型實現了 90%的字符檢測準確率和 80%的字符識別準確率。文章中提到的所有步驟都可以從提供的 Jupyter 筆記本上運行,從而可以輕松地用最少的代碼創建自定義的人工智能模型。
有關詳細信息,請參閱:
?