
數據標記和模型訓練一直被認為是團隊在構建 AI / ML 基礎設施時面臨的最大挑戰。這兩個步驟都是 ML 應用程序開發過程中的關鍵步驟,如果做得不當,可能會導致結果不準確和性能下降。要了解更多信息,請參閱人工智能基礎設施聯盟的2022 年 AI 基礎設施生態系統報告。
數據標記對于所有形式的監督學習都至關重要,在監督學習中,整個數據集都被完全標記。它也是半監督學習的一個關鍵組成部分,半監督學習將一組較小的標記數據與設計用于以編程方式自動標記數據集其余部分的算法相結合。標記對計算機視覺至關重要,計算機視覺是機器學習中最先進和最發達的領域之一。盡管它很重要,但貼標簽的速度很慢,因為它需要擴大分布式人力團隊的規模。
除了標注之外,模型訓練是機器學習的另一個主要瓶頸。訓練很慢,因為它需要等待機器完成復雜的計算。它要求團隊了解網絡、分布式系統、存儲、專用處理器( GPU 或 TPU )和云管理系統( Kubernetes 和 Docker )。
超級 AI 套件與 NVIDIA 〔 TAO 〕工具包
Superb AI 為計算機視覺團隊引入了一種新的方法,以大幅減少提供高質量訓練數據集所需的時間。團隊現在可以通過 Superb AI Suite 來實現這一目標。
NVIDIA TAO Toolkit 是建立在 TensorFlow 和 PyTorch 之上的 TAO 框架的低代碼版本,它可以抽象掉框架的復雜性,從而加快模型開發過程。TAO 工具包可以讓您使用transfer learning,使用自己的數據對 NVIDIA 預訓練模型進行微調,并進行推理優化。
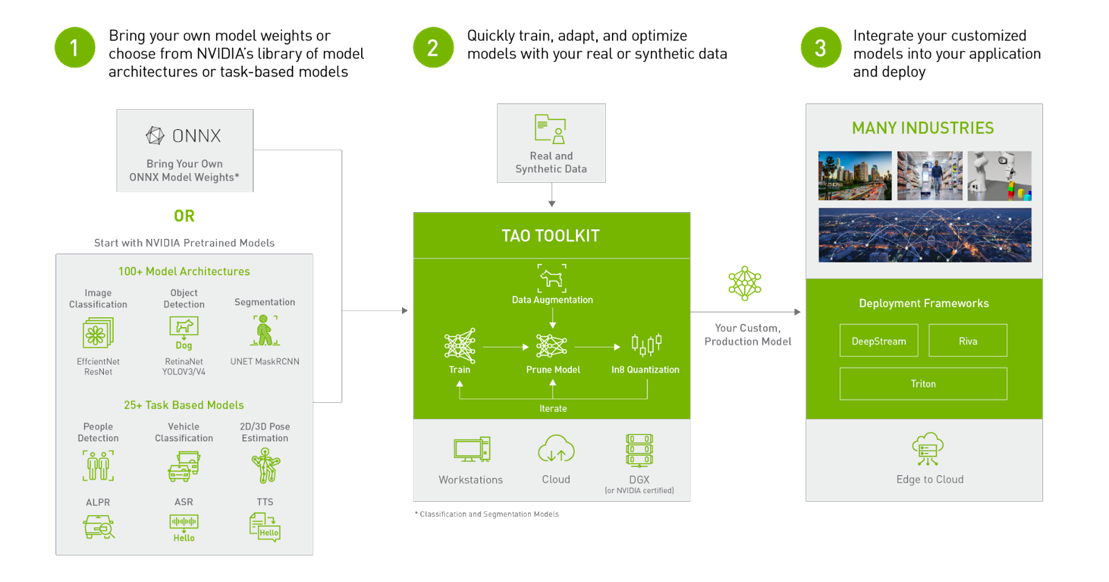
計算機視覺工程師可以將 Superb AI 套件和 TAO 工具包結合使用,以應對數據標記和模型訓練的挑戰。更具體地說,您可以在 Suite 中快速生成標記數據,并使用 TAO 訓練模型,以執行特定的計算機視覺任務,無論是分類、檢測還是分割。
準備計算機視覺數據集
本文演示了如何使用 Superb AI Suite 準備一個與 TAO Toolkit 兼容的高質量計算機視覺數據集。它完成了下載數據集、在 Suite 上創建新項目、通過Suite SDK 使用Superb AI 的自動標記功能 快速標記數據集,導出標記的數據集,并設置 TAO Toolkit 配置以使用數據。
步驟 1 :開始使用 Suite SDK
首先,前往superb-ai.com創建帳戶。然后按照快速入門指南安裝并認證 Suite CLI。您應該能夠安裝最新版本的 spb-cli,并檢索 Suite 帳戶名/訪問密鑰以進行身份驗證。
步驟 2 :下載數據集
本教程適用于COCO 數據集,一個在計算機視覺研究領域非常受歡迎的大規模目標檢測、分割和字幕數據集。
您可以使用此代碼片段來下載數據集。將其保存在名為 download-coco.sh 的文件中,然后從終端運行 bash download-coco.sh 。這將創建一個存儲 COCO 數據集的 data/ 目錄。
下一步是將 COCO 轉換為 Suite SDK 格式,以對 COCO 驗證 2017 數據集中最常見的五個類進行采樣。本教程僅處理邊界框注釋,但 Suite 也可以處理多邊形和關鍵點。
您可以使用 此代碼片段來執行轉換。將其保存在名為 convert.py 的文件中,然后從終端運行 Python convert.py 。這將創建一個 upload-info.json 文件,該文件存儲有關圖像名稱和注釋的信息。
步驟 3 :在 Suite SDK 中創建項目
正在使用 Suite SDK 創建項目。本教程使用 Superb AI 創建項目指南。請按照以下配置進行操作。
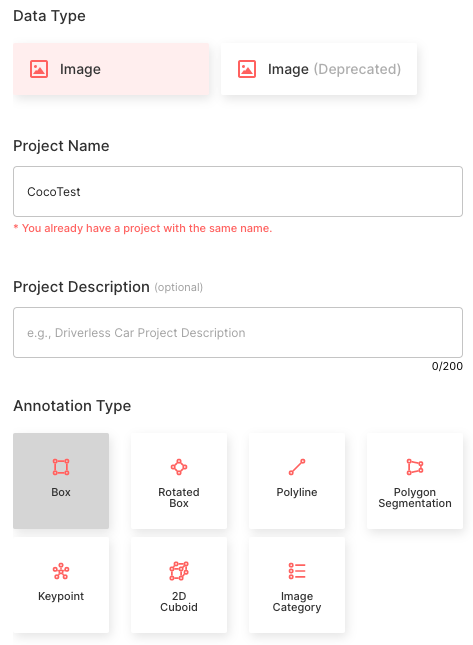
- 選擇形象數據類
- 將項目名稱設置為椰子測試
- 選擇注釋類型作為邊界框
- 創建五個與 COCO 類名的類名匹配的對象類: “人”、“車”、“椅子”、“書”、“瓶子”
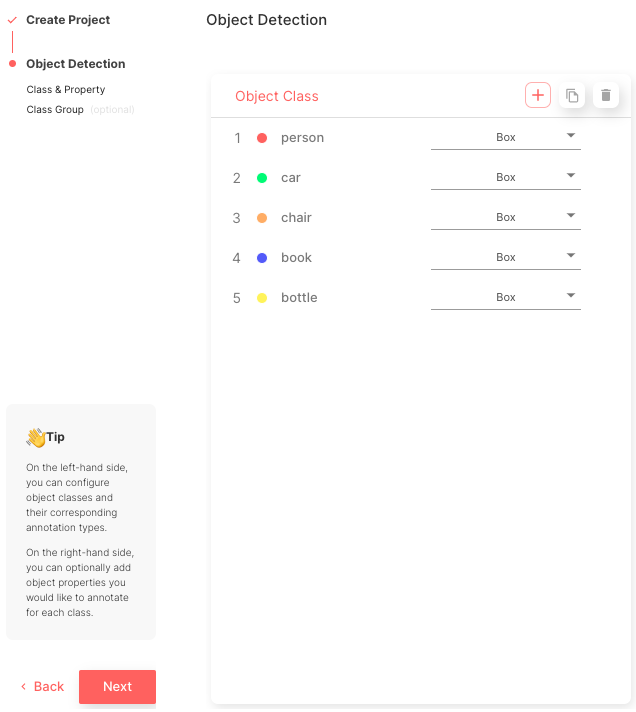
這個過程完成后,您可以查看項目主頁面,如圖 5 所示。
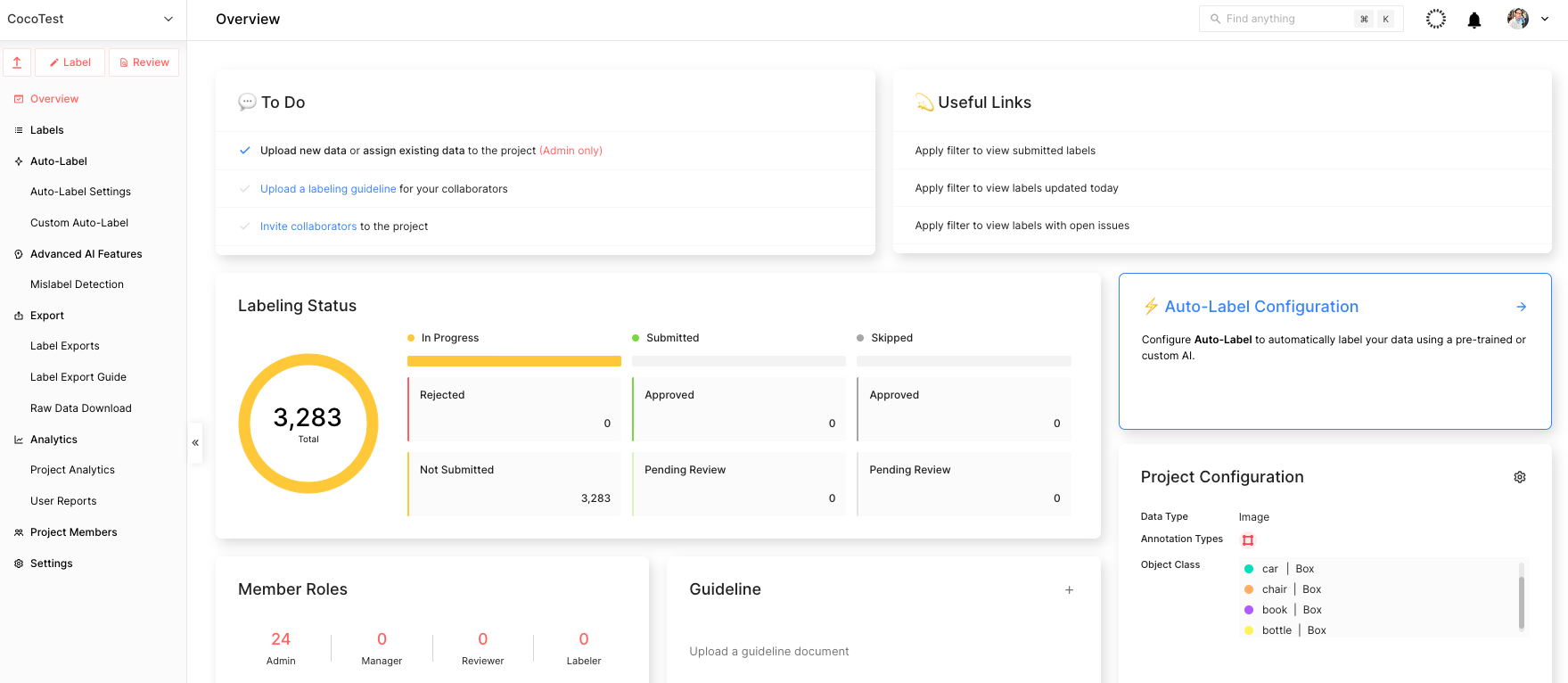
步驟 4 :使用 Suite SDK 上傳數據
創建完項目后,開始上傳數據。您可以使用此代碼片段上傳數據。將其保存為upload.py,然后在終端中運行python upload.py --project CocoTest --dataset coco-dataset。
這意味著CocoTest是項目名稱,并且coco-dataset是數據集名稱。這將啟動上傳過程,根據設備的處理能力,上傳過程可能需要幾個小時才能完成。
您可以通過 Suite 網頁實時查看上傳的數據集,如圖 6 所示。
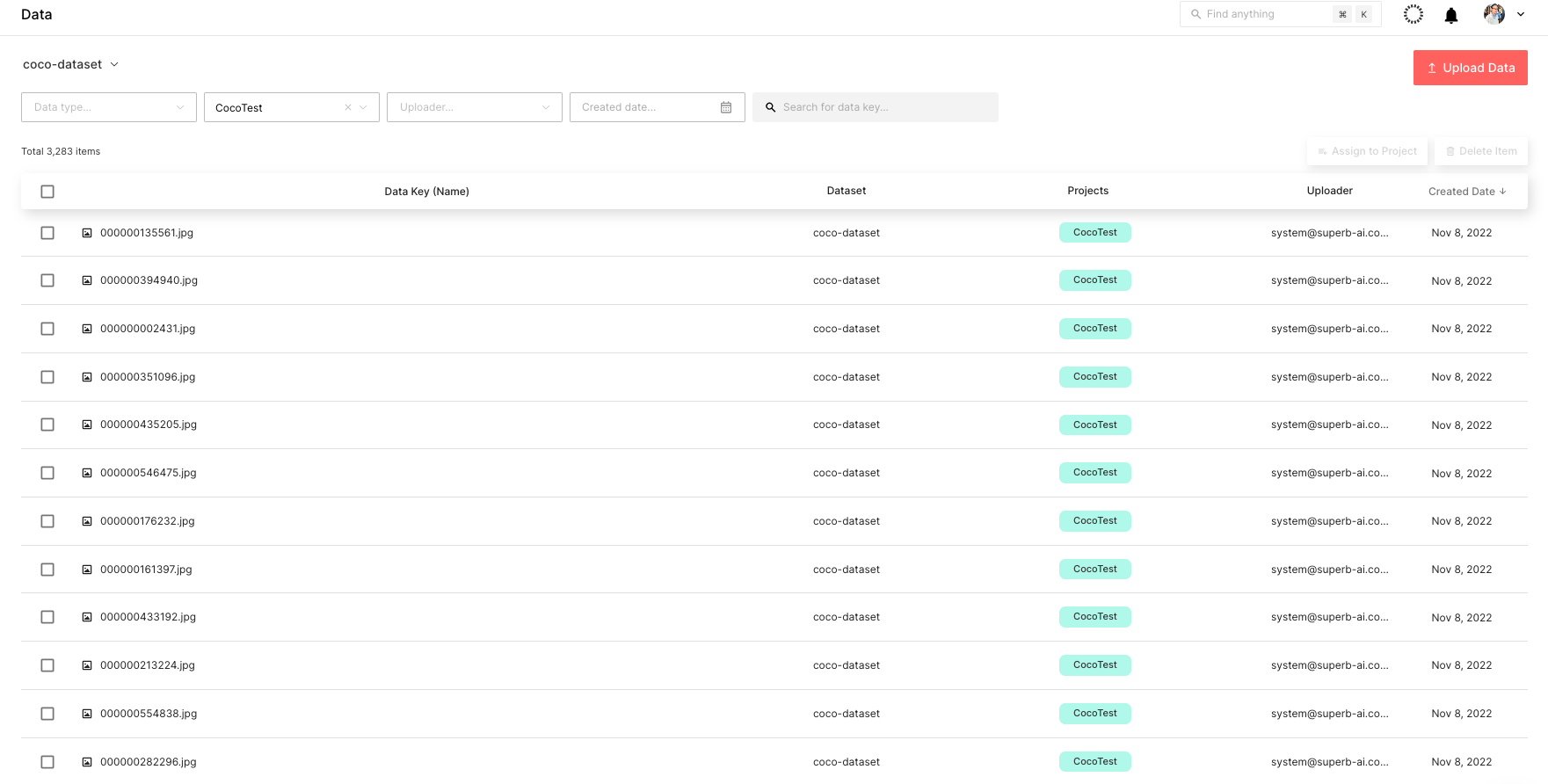
步驟 5 :標記數據集
下一步是標記 COCO 數據集。要快速完成此操作,請使用 Suite 強大的自動標記功能。更具體地說,自動添加標簽和自定義自動標簽都是功能強大的工具,可以通過自動檢測對象并對其進行標記來提高標記效率。
自動標簽是 Superb AI 開發的一個預訓練模型,用于檢測和標記 100 多個常見對象,而自定義自動標簽是使用您自己的數據訓練的模型,用于探測和標記利基對象。
本教程中的 COCO 數據由 Auto Label 能夠標記的五種常見對象組成。請按照配置 Auto-Label 的指南進行操作。需要牢記的重要一點是,您需要選擇MSCOCO 盒 CAL作為自動標記 AI,并將對象名稱與相應應用的對象進行映射。處理 COCO 數據集中的所有 3283 個標簽可能需要大約一個小時。
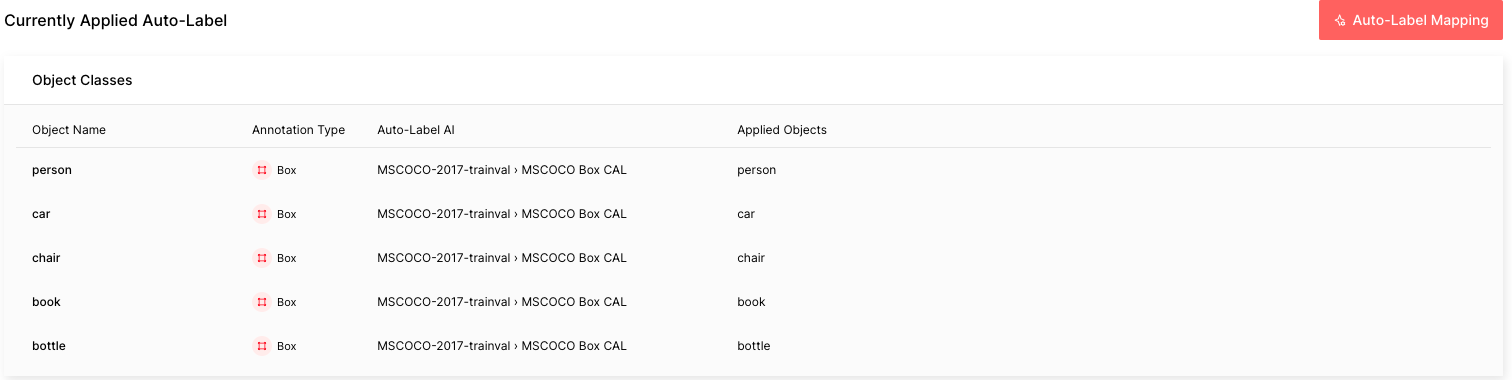
自動標簽運行完成后,您將看到每個自動標簽任務的難度:紅色是困難的,黃色是中等的,綠色是容易的。難度越高,“自動標簽”錯誤標記該圖像的可能性就越大。
這種難度或估計的不確定性是根據物體尺寸小、照明條件差、場景復雜等因素計算的。在現實世界中,您可以輕松地按難度對標簽進行排序和過濾,以便優先處理出錯幾率較高的標簽。
步驟 6 :從 Suite 導出標記的數據集
獲取標記的數據集后,導出并下載標簽。標簽不僅僅是注釋信息,為了充分利用標簽來訓練 ML 模型,您還需要了解其他信息,例如項目配置和有關原始數據的元信息。要將所有這些信息與注釋文件一起下載,請首先請求導出,以便 Suite 系統可以創建一個 zip 文件進行下載。請參閱Suite 中導出和下載標簽的指南。
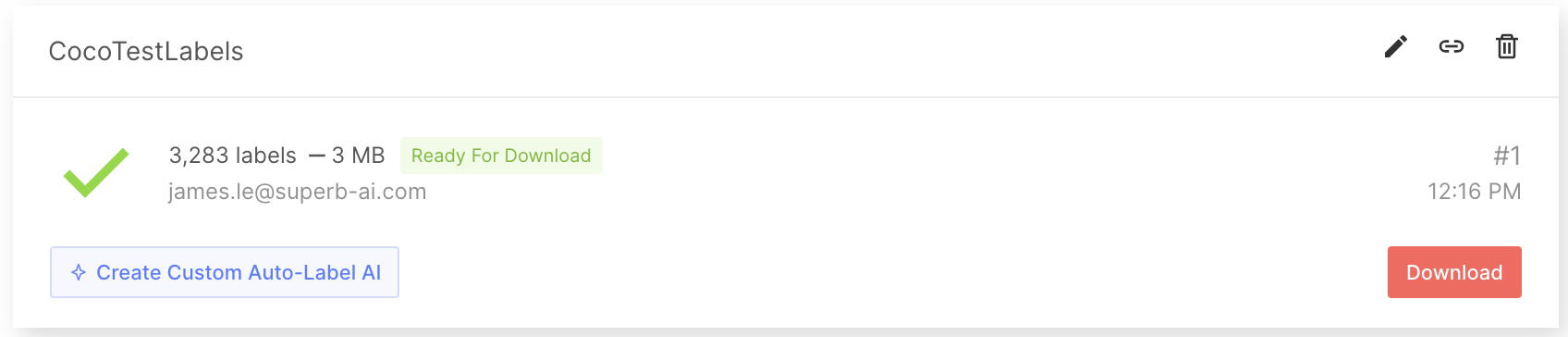
導出標簽時,將創建一個壓縮的 zip 文件供您下載。導出結果文件夾將包含有關整個項目的常規信息、每個標簽的注釋信息以及每個數據資產的元數據。想要了解更多詳情,請訪問 導出結果格式 文檔。
步驟 7 :將輸出轉換為 COCO 格式
接下來,創建一個腳本,將標記的數據轉換為可以被 TAO Toolkit 識別的格式,例如COCO 格式。請注意,由于本教程使用了 COCO 數據集,因此數據已經采用了 COCO 格式。例如,您可以在下面找到一個隨機導出標簽的 JSON 文件:
{
"objects": [
{
"id": "7e9fe8ee-50c7-4d4f-9e2c-145d894a8a26",
"class_id": "7b8205ef-b251-450c-b628-e6b9cac1a457",
"class_name": "person",
"annotation_type": "box",
"annotation": {
"multiple": false,
"coord": {
"x": 275.47,
"y": 49.27,
"width": 86.39999999999998,
"height": 102.25
},
"meta": {},
"difficulty": 0,
"uncertainty": 0.0045
},
"properties": []
},
{
"id": "70257635-801f-4cad-856a-ef0fdbfdf613",
"class_id": "7b8205ef-b251-450c-b628-e6b9cac1a457",
"class_name": "person",
"annotation_type": "box",
"annotation": {
"multiple": false,
"coord": {
"x": 155.64,
"y": 40.61,
"width": 98.34,
"height": 113.05
},
"meta": {},
"difficulty": 0,
"uncertainty": 0.0127
},
"properties": []
}
],
"categories": {
"properties": []
},
"difficulty": 1
}步驟 8 :準備用于模型訓練的標記數據
接下來,使用 SuiteDataset 將 COCO 數據從 Suite 中提取到模型開發中。 SuiteDataset 使 Suite 中導出的數據集可以通過 PyTorch 數據管道訪問。下面顯示的代碼片段實例化了訓練集的 SuiteData 對象類。
class SuiteDataset(Dataset):
"""
Instantiate the SuiteDataset object class for training set
"""
def __init__(
self,
team_name: str,
access_key: str,
project_name: str,
export_name: str,
train: bool,
caching_image: bool = True,
transforms: Optional[List[Callable]] = None,
category_names: Optional[List[str]] = None,
):
"""Function to initialize the object class"""
super().__init__()
# Get project setting and export information through the SDK
# Initialize the Python Client
client = spb.sdk.Client(team_name=team_name, access_key=access_key, project_name=project_name)
# Use get_export
export_info = call_with_retry(client.get_export, name=export_name)
# Download the export compressed file through download_url in Export
export_data = call_with_retry(urlopen, export_info.download_url).read()
# Load the export compressed file into memory
with ZipFile(BytesIO(export_data), 'r') as export:
label_files = [f for f in export.namelist() if f.startswith('labels/')]
label_interface = json.loads(export.open('project.json', 'r').read())
category_infos = label_interface.get('object_detection', {}).get('object_classes', [])
cache_dir = None
if caching_image:
cache_dir = f'/tmp/{team_name}/{project_name}'
os.makedirs(cache_dir, exist_ok=True)
self.client = client
self.export_data = export_data
self.categories = [
{'id': i + 1, 'name': cat['name'], 'type': cat['annotation_type']}
for i, cat in enumerate(category_infos)
]
self.category_id_map = {cat['id']: i + 1 for i, cat in enumerate(category_infos)}
self.transforms = build_transforms(train, self.categories, transforms, category_names)
self.cache_dir = cache_dir
# Convert label_files to numpy array and use
self.label_files = np.array(label_files).astype(np.string_)
def __len__(self):
"""Function to return the number of label files"""
return len(self.label_files)
def __getitem__(self, idx):
"""Function to get an item"""
idx = idx if idx >= 0 else len(self) + idx
if idx < 0 or idx >= len(self):
raise IndexError(f'index out of range')
image_id = idx + 1
label_file = self.label_files[idx].decode('ascii')
# Load label information corresponding to idx from the export compressed file into memory
with ZipFile(BytesIO(self.export_data), 'r') as export:
label = load_label(export, label_file, self.category_id_map, image_id)
# Download the image through the Suite sdk based on label_id
try:
image = load_image(self.client, label['label_id'], self.cache_dir)
# Download data in real time using get_data from Suite sdk
except Exception as e:
print(f'Failed to load the {idx}-th image due to {repr(e)}, getting {idx + 1}-th data instead')
return self.__getitem__(idx + 1)
target = {
'image_id': image_id,
'label_id': label['label_id'],
'annotations': label['annotations'],
}
if self.transforms is not None:
image, target = self.transforms(image, target)
return image, target以類似的方式處理測試集。下面的代碼片段通過包裝 SuiteDataset,使其與 Torchvision COCOEvaluator 配合使用。
class SuiteCocoDataset(C.CocoDetection):
"""
Instantiate the SuiteCocoDataset object class for test set
(by wrapping SuiteDataset to make compatible with torchvision's official COCOEvaluator)
"""
def __init__(
self,
team_name: str,
access_key: str,
project_name: str,
export_name: str,
train: bool,
caching_image: bool = True,
transforms: Optional[List[Callable]] = None,
category_names: Optional[List[str]] = None,
num_init_workers: int = 20,
):
"""Function to initialize the object class"""
super().__init__(img_folder='', ann_file=None, transforms=None)
# Call the SuiteDataset class
dataset = SuiteDataset(
team_name, access_key, project_name, export_name,
train=False, transforms=[],
caching_image=caching_image, category_names=category_names,
)
self.client = dataset.client
self.cache_dir = dataset.cache_dir
self.coco = build_coco_dataset(dataset, num_init_workers)
self.ids = list(sorted(self.coco.imgs.keys()))
self._transforms = build_transforms(train, dataset.categories, transforms, category_names)
def _load_image(self, id: int):
"""Function to load an image"""
label_id = self.coco.loadImgs(id)[0]['label_id']
image = load_image(self.client, label_id, self.cache_dir)
return image
def __getitem__(self, idx):
"""Function to get an item"""
try:
return super().__getitem__(idx)
except Exception as e:
print(f'Failed to load the {idx}-th image due to {repr(e)}, getting {idx + 1}-th data instead')
return self.__getitem__(idx + 1)然后可以將 SuiteDataset 和 SuiteCoDataset 用于您的培訓代碼。下面的代碼片段說明了如何使用它們。在模型開發過程中,與train_loader并使用進行評估test_loader.
train_dataset = SuiteDataset(
team_name=args.team_name,
access_key=args.access_key,
project_name=args.project_name,
export_name=args.train_export_name,
caching_image=args.caching_image,
train=True,
)
test_dataset = SuiteCocoDataset(
team_name=args.team_name,
access_key=args.access_key,
project_name=args.project_name,
export_name=args.test_export_name,
caching_image=args.caching_image,
train=False,
num_init_workers=args.workers,
)
train_loader = DataLoader(
train_dataset, num_workers=args.workers,
batch_sampler=G.GroupedBatchSampler(
RandomSampler(train_dataset),
G.create_aspect_ratio_groups(train_dataset, k=3),
args.batch_size,
),
collate_fn=collate_fn,
)
test_loader = DataLoader(
test_dataset, num_workers=args.workers,
sampler=SequentialSampler(test_dataset), batch_size=1,
collate_fn=collate_fn,
)步驟 9 :使用 NVIDIA TAO 工具包訓練您的模
現在可以使用 Suite 注釋的數據來訓練對象檢測模型。通過使用 TAO 工具包,您可以訓練、微調、修剪和導出高度優化和準確的計算機視覺模型,以便將其部署到流行的網絡架構和主干網中。在本教程中,您可以選擇YOLO v4,它包括在 TAO 中的對象檢測模型。
首先,從 TAO 工具包快速入門 下載筆記本示例。
pip3 install nvidia-tao
wget --content-disposition https://api.ngc.nvidia.com/v2/resources/nvidia/tao/tao-getting-started/versions/4.0.1/zip -O getting_started_v4.0.1.zip
$ unzip -u getting_started_v4.0.1.zip -d ./getting_started_v4.0.1 && rm -rf getting_started_v4.0.1.zip && cd ./getting_started_v4.0.1接下來,使用以下代碼啟動筆記本:
$ jupyter notebook --ip 0.0.0.0 --port 8888 --allow-root在本地主機上打開 Internet 瀏覽器,然后導航到 URL :
http://0.0.0.0:8888要創建 YOLOv4 模型,請打開notebooks/tao_launcher_starter_kit/yolo_v4/yolo_v4.ipynb并按照筆記本上的說明訓練模型。
根據結果,不斷調整模型,直到達到您的度量目標。如果需要,您可以創建自己的主動學習循環。在真實世界的場景中,查詢失敗預測的樣本,指定人工標注器來注釋這批新的樣本數據,并用新標注的訓練數據補充模型。Superb AI Suite 可以進一步幫助您在后續幾輪模型開發中進行數據收集和注釋,以不斷提高模型性能。
最近發布的 TAO Toolkit 4.0,可以讓沒有任何人工智能專業知識的用戶更容易上手,創建高精度模型。使用 AutoML 自動微調您的超參數,將 TAO Toolkit 交鑰匙部署到各種云服務中,將 TAO Toolkit 與第三方 MLOP 服務集成,探索新的基于 transformer 的視覺模型(如 CitySemSegformer 和 Peoplenet Transformer)。
結論
計算機視覺中的數據標注可能會帶來許多獨特的挑戰。由于需要標記的數據量很大,因此該過程可能很困難且成本高昂。此外,該過程可能是主觀的,這使得在大型數據集中實現一致的高質量標記輸出具有挑戰性。
模型訓練也可能具有挑戰性,因為許多算法和超參數需要調整和優化。這個過程需要對數據和模型有深入的了解,并進行大量實驗以獲得最佳結果。此外,計算機視覺模型往往需要大量的計算能力來訓練,這使得在有限的預算和時間內很難做到這一點。
Superb AI Suite 使您能夠收集和標記高質量的計算機視覺數據集。使用 NVIDIA TAO 工具包,您可以優化預先訓練的計算機視覺模型。在不犧牲質量的情況下,將兩者結合使用可顯著加快計算機視覺應用程序的開發時間。
想要更多信息嗎?退房時間:
關于 Superb AI
Superb AI 提供了一個訓練數據平臺,使構建、管理和管理計算機視覺數據集比以往任何時候都更快、更容易。我們的解決方案專注于標簽和質量保證的適應性自動化模型,幫助公司大幅減少為計算機視覺模型構建數據管道所需的時間和成本。2018 年,由擁有數十年經驗的研究人員和工程師(包括 25 多項出版物、7300 多項引用和 100 多項專利)發起,我們的愿景是讓處于各個階段的公司能夠比以往更快地開發計算機視覺應用程序。
Superb AI 也是通過 NVIDIA Inception Program for Startups 由 NVIDIA 提供的計劃,有助于培育世界尖端初創公司的發展,為他們提供 NVIDIA 技術和專家,與風險投資家建立聯系的機會,以及提高知名度的市場營銷支持。
?





