CUDA 5 為 CUDA 工具箱添加了一個強大的新工具: nvprof 。 nvprof 是一個可用于 Linux 、 Windows 和 OS X 的命令行探查器。乍一看, nvprof 似乎只是 NVIDIA Visual Profiler 和 NSight 日蝕版 中圖形分析功能的無 GUI 版本。但是 nvprof 遠不止這些;對我來說, nvprof 是一個輕量級的分析器,它達到了其他工具所不能達到的水平。
使用 nvprof 進行快速檢查
我經常想知道我的 CUDA 應用程序是否按預期運行。有時這只是一個正常的檢查:應用程序是否在 GPU 上運行內核?它是否執行過多的內存復制?通過使用 nvprof ./myApp 運行我的應用程序,我可以快速看到它所使用的所有內核和內存副本的摘要,如下面的示例輸出所示。
==9261== Profiling application: ./tHogbomCleanHemi
==9261== Profiling result:
Time(%) Time Calls Avg Min Max Name
58.73% 737.97ms 1000 737.97us 424.77us 1.1405ms subtractPSFLoop_kernel(float const *, int, float*, int, int, int, int, int, int, int, float, float)
38.39% 482.31ms 1001 481.83us 475.74us 492.16us findPeakLoop_kernel(MaxCandidate*, float const *, int)
1.87% 23.450ms 2 11.725ms 11.721ms 11.728ms [CUDA memcpy HtoD]
1.01% 12.715ms 1002 12.689us 2.1760us 10.502ms [CUDA memcpy DtoH]
在默認的 摘要模式 中, nvprof 提供了應用程序中 GPU 內核和內存副本的概述。摘要將對同一內核的所有調用組合在一起,顯示每個內核的總時間和總應用程序時間的百分比。除了摘要模式之外, nvprof 還支持 GPU – 跟蹤和 API 跟蹤模式 ,它可以讓您看到所有內核啟動和內存副本的完整列表,在 API 跟蹤模式下,還可以看到所有 CUDA API 調用的完整列表。
下面是一個使用 nvprof --print-gpu-trace 評測在我的電腦上的兩個 GPUs 上運行的 nbody 示例應用程序的示例。我們可以看到每個內核在哪個 GPU 上運行,以及每次啟動使用的網格維度。當您想驗證 multi- GPU 應用程序是否按預期運行時,這非常有用。
nvprof --print-gpu-trace ./nbody --benchmark -numdevices=2 -i=1 ... ==4125== Profiling application: ./nbody --benchmark -numdevices=2 -i=1 ==4125== Profiling result: Start Duration Grid Size Block Size Regs* SSMem* DSMem* Size Throughput Device Context Stream Name 260.78ms 864ns - - - - - 4B 4.6296MB/s Tesla K20c (0) 2 2 [CUDA memcpy HtoD] 260.79ms 960ns - - - - - 4B 4.1667MB/s GeForce GTX 680 1 2 [CUDA memcpy HtoD] 260.93ms 896ns - - - - - 4B 4.4643MB/s Tesla K20c (0) 2 2 [CUDA memcpy HtoD] 260.94ms 672ns - - - - - 4B 5.9524MB/s GeForce GTX 680 1 2 [CUDA memcpy HtoD] 268.03ms 1.3120us - - - - - 8B 6.0976MB/s Tesla K20c (0) 2 2 [CUDA memcpy HtoD] 268.04ms 928ns - - - - - 8B 8.6207MB/s GeForce GTX 680 1 2 [CUDA memcpy HtoD] 268.19ms 864ns - - - - - 8B 9.2593MB/s Tesla K20c (0) 2 2 [CUDA memcpy HtoD] 268.19ms 800ns - - - - - 8B 10.000MB/s GeForce GTX 680 1 2 [CUDA memcpy HtoD] 274.59ms 2.2887ms (52 1 1) (256 1 1) 36 0B 4.0960KB - - Tesla K20c (0) 2 2 void integrateBodies(vec4::Type*, vec4::Type*, vec4::Type*, unsigned int, unsigned int, float, float, int) [242] 274.67ms 981.47us (32 1 1) (256 1 1) 36 0B 4.0960KB - - GeForce GTX 680 1 2 void integrateBodies(vec4::Type*, vec4::Type*, vec4::Type*, unsigned int, unsigned int, float, float, int) [257] 276.94ms 2.3146ms (52 1 1) (256 1 1) 36 0B 4.0960KB - - Tesla K20c (0) 2 2 void integrateBodies(vec4::Type*, vec4::Type*, vec4::Type*, unsigned int, unsigned int, float, float, int) [275] 276.99ms 979.36us (32 1 1) (256 1 1) 36 0B 4.0960KB - - GeForce GTX 680 1 2 void integrateBodies(vec4::Type*, vec4::Type*, vec4::Type*, unsigned int, unsigned int, float, float, int) [290] Regs: Number of registers used per CUDA thread. SSMem: Static shared memory allocated per CUDA block. DSMem: Dynamic shared memory allocated per CUDA block.
[使用] nvprof to Profile] Anything
nvprof 知道如何評測運行在 GPUs NVIDIA 上的 CUDA 內核,不管它們是用什么語言編寫的(只要它們是使用 CUDA 運行時 API 或驅動程序 API 啟動的)。這意味著我可以使用 nvprof 來評測 OpenACC 程序(沒有顯式內核),甚至可以在內部生成 PTX 匯編內核的程序。 Mark Ebersole 在他最近關于 CUDA Python 的 CUDA Cast ( 第十集 )中展示了一個很好的例子,其中他使用 NumbaPro 編譯器(來自 Continuum Analytics )及時編譯了一個 Python 函數,并在 GPU 上并行運行。
在 OpenACC 或 CUDA Python 程序的初始實現過程中,函數是否在 nvprof 或 GPU 上運行可能并不明顯(尤其是如果您沒有計時)。在 Mark 的例子中,他在 GPU 內部運行 Python 解釋器,捕捉應用程序的 CUDA 函數調用和內核啟動的跟蹤,顯示內核確實在 GPU 上運行,以及用于將數據從 CPU 傳輸到 GPU 的 cudaMemcpy 調用。這是一個很好的例子,說明了像 nvprof 這樣的輕量級命令行 GPU 探查器的“健全性檢查”功能。
使用 nvprof 進行遠程分析
有時,您正在部署的系統不是您的桌面系統。例如,如果您使用的是 GPU 集群或云系統,如 Amazon EC2 ,并且您只能通過終端訪問機器。這是 nvprof 的另一個重要用途。只需連接到遠程計算機(例如使用 ssh ,并在 nvprof 下運行應用程序。
通過使用 --output-profile 命令行選項,您可以輸出一個數據文件,以便以后導入到 nvprof 或 NVIDIA 可視化探查器中。這意味著您可以在遠程計算機上捕獲一個概要文件,然后在可視化分析器中可視化并分析桌面上的結果(有關詳細信息,請參見“ 遠程分析 ”)。
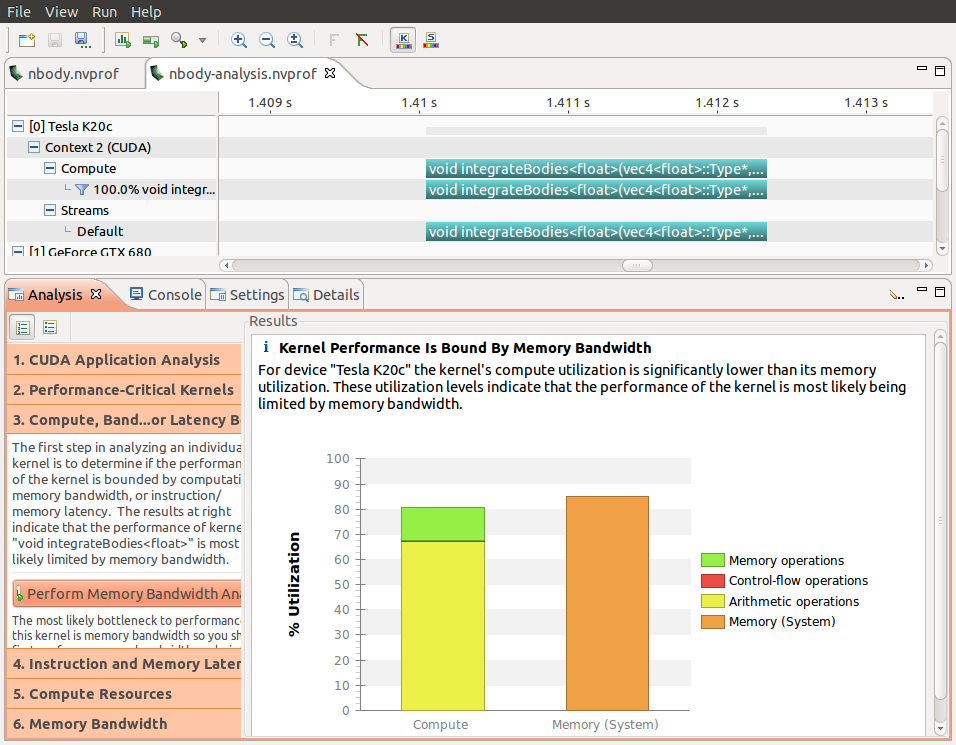
nvprof 提供了一個方便的選項( --analysis-metrics ),用于捕獲 visualprofiler 在其“引導分析”模式下所需的所有 GPU 指標。下面的屏幕截圖顯示了用于確定內核瓶頸的可視化分析器。此分析的數據是使用下面的命令行捕獲的。
nvprof --analysis-metrics -o nbody-analysis.nvprof ./nbody --benchmark -numdevices=2 -i=1
非常方便的工具
如果您是命令行工具的粉絲,我想您會喜歡使用 nvprof 。 nvprof 可以做的還有很多,我在這里還沒有提到,比如在 NVIDIA 可視化分析器中收集分析指標。
我希望讀完這篇文章后,你會發現自己每天都在使用它,就像隨身攜帶的一把隨身攜帶的小刀。
?






