NVIDIA 宣布最新的 CUDA 工具包軟件版本 12.0 。該版本是多年來的第一個主要版本,它專注于通過新的硬件功能實現新的編程模型和 CUDA 應用程序加速。
現在,您可以使用 CUDA 自定義代碼、增強的庫和開發人員工具,針對 NVIDIA Hopper 和 NVIDIA Ada Lovelace 架構中特定于架構的功能和指令。
CUDA 12.0 包括許多主要和次要的變化。這里并沒有列出所有更改,但本文概述了關鍵功能。
概述
- 支持新的 NVIDIA Hopper 和 NVIDIA Ada Lovelace 架構功能,并為所有 GPU 提供了額外的編程模型增強,包括新的 PTX 指令和通過更高級別的 C 和 C ++ API 進行的曝光
- 支持改進后的 CUDA 動態并行 API ,與傳統 API 相比,性能有了顯著提高
- CUDA 圖形 API 的增強功能:
- 現在,您可以通過調用內置函數來調度 GPU 設備端內核的圖形啟動。有了這種能力,內核中的用戶代碼可以動態調度圖形啟動,大大提高了 CUDA 圖形的靈活性。
cudaGraphInstantiateAPI 已被重構以刪除未使用的參數。
- 支持 GCC 12 主機編譯器
- 支持 C ++ 20
- JIT LTO CUDA 工具包中的新
nvJitLink庫 - 庫優化和性能改進
- Nsight Compute 和 Nsight Systems 開發人員工具更新
- 更新了對最新 Linux 版本的支持
有關詳細信息,請參見 CUDA Toolkit 12.0 Release Notes 。 CUDA Toolkit 12.0 可供下載。
NVIDIA Hopper 和 NVIDIA Ada Lovelace 架構支持
CUDA 應用程序可以立即受益于新 GPU 系列中增加的流式多處理器( SM )計數、更高的內存帶寬和更高的時鐘速率。 CUDA 和 CUDA 庫基于 GPU 硬件架構增強提供了新的性能優化。
CUDA 12.0 為 NVIDIA Hopper 和 NVIDIA Ada Lovelace 架構的許多功能提供了可編程功能:
- 許多張量運算現在可以通過公共 PTX 獲得:
- TMA 操作
- TMA 批量操作
- 32x Ultra xMMA (包括 FP8 和 FP16 )
- NVIDIA Hopper GPU 中的啟動參數控制
membar域 - 支持 C ++和 PTX 中的 Hopper 異步事務屏障
- 支持協同網格陣列( CGA )放松障礙的 C intrinsic
- 支持編程二級緩存到 SM 多播(僅限 NVIDIA Hopper GPU )
- 支持 SIMT 集體的公共 PTX :
elect_one - 基因組學和 DPX 指令現在可用于 NVIDIA Hopper GPU ,以提供更快的組合數學運算(三向最大值、融合加法+最大值等)。
延遲加載
延遲加載是一種延遲內核和 CPU 側模塊加載的技術,直到應用程序需要加載。默認值是在庫首次初始化時搶先加載所有模塊。這不僅可以節省設備和主機內存,還可以節省算法的端到端執行時間。
自 11.7 發布以來,延遲加載一直是 CUDA 的一部分。后續的 CUDA 版本繼續對其進行擴充和擴展。從應用程序開發的角度來看,選擇延遲加載不需要任何特定的東西。您的現有應用程序按原樣使用延遲加載。
如果您的操作對延遲特別敏感,您可能需要評測應用程序。與延遲加載的權衡是在應用程序中首次加載函數時的最小延遲量。這總體上低于沒有延遲加載的總延遲。?
| Metric | Baseline | CUDA 11.7 | CUDA 11.8+ | Improvement |
| End-to-end runtime [s] | 2.9 | 1.7 | 0.7 | 4x |
| Binary load time [s] | 1.6 | 0.8 | 0.01 | 118x |
| Device memory footprint [MB] | 1245 | 435 | 435 | 3x |
| Host memory footprint [MB] | 1866 | 1229 | 60 | 31x |
所有用于延遲加載的庫都必須使用 11.7 +才能符合條件。
在此版本中,默認情況下, CUDA 堆棧中未啟用延遲加載。要為應用程序評估它,請使用設置的環境變量CUDA_MODULE_LOADING=LAZY運行。
兼容性
CUDA 次要版本兼容性是 11.x 中引入的一項功能,它使您能夠靈活地將應用程序與同一主要版本中的 CUDA Toolkit 的任何次要版本動態鏈接。編譯一次代碼,您就可以動態鏈接到 CUDA Toolkit 同一主要版本中任何次要版本的庫、 CUDA runtime 和用戶模式驅動程序。
例如, 11.6 個應用程序可以鏈接到 11.8 運行時,反之亦然。這是通過庫文件中的 API 或 ABI 一致性實現的。有關詳細信息,請參見 CUDA Compatibility 。
次要版本兼容性持續到 CUDA 12.x 。但是,由于 12.0 是一個新的主要版本,兼容性保證被重置。在 11.x 中使用次要版本兼容性的應用程序在鏈接到 12.0 時可能會出現問題。要么根據 12.0 重新編譯應用程序,要么靜態鏈接到 11.x 中所需的庫,以確保開發的連續性。
同樣,在 12.0 中重新編譯或構建的應用程序將鏈接到未來版本的 12.x ,但不會鏈接到 CUDA Toolkit11.x 的組件。
JIT LTO 支持
CUDA 12.0Toolkit 為 JIT LTO 支持引入了新的nvJitLink庫。 NVIDIA 不支持此功能的驅動程序版本。有關詳細信息,請參見 Deprecated Features 。
C ++ 20 編譯器支持
CUDA Toolkit12.0 增加了對 C ++ 20 標準的支持。以下主機編譯器及其最低版本啟用了 C ++ 20 :
- 通用計算機 10
- 宗族 11
- MSVC 2022 年
- NVC ++ 22.x 版本
- 臂 C / C ++ 22.x
有關功能的更多信息,請參閱相應的主機編譯器文檔。
雖然大多數 C ++ 20 功能在主機和設備代碼中都可用,但有些功能受到限制。
模塊支持
C ++ 20 中引入了模塊,作為跨翻譯單元導入和導出實體的新方法。
由于 CUDA 設備編譯器和主機編譯器之間需要復雜的交互,因此 CUDA C ++在主機或設備代碼中都不支持模塊。模塊的使用以及導出和導入關鍵字被診斷為錯誤。
配套支架
子程序是可恢復的函數。可以暫停執行,在這種情況下,控制權返回給調用者。協程的后續調用在其被掛起時恢復。
主機代碼支持子程序,但設備代碼不支持。設備功能范圍內co_await、co_yield和co_return關鍵字的使用在設備編譯期間被診斷為錯誤。
三向比較運算符
三元比較運算符<=>是一種新的關系運算符,使編譯器能夠綜合其他關系運算符。
因為它與標準模板庫中的實用程序函數緊密耦合,所以每當隱式調用宿主函數時,它的使用在設備代碼中受到限制。
在直接調用運算符且不需要啟用隱式調用的情況下使用。
Nsight 開發人員工具
Nsight 開發人員工具正在接收與 CUDA 工具包 12.0 一致的更新。
NVIDIA Nsight Systems 2022.5 介紹了 InfiniBand 交換機度量采樣的預覽。 NVIDIA Quantum InfiniBand 交換機提供高帶寬、低延遲通信。在 Nsight Systems 時間線上查看交換機指標,使您能夠更好地了解應用程序的網絡使用情況。您可以使用此信息優化應用程序的性能。

Nsight 工具旨在協作使用。 Nsight 系統中的性能分析通常為深入了解 Nsight Compute 中的內核活動提供信息。
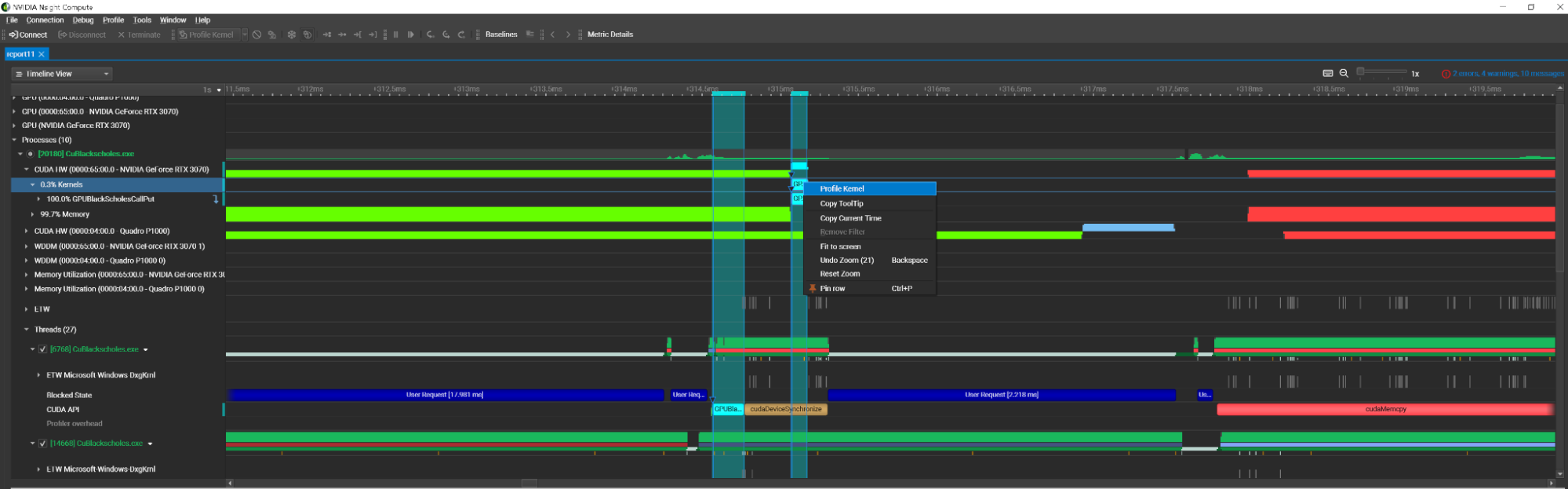
為了簡化這一過程, Nsight Compute 2022.4 引入了 Nsight Systems 集成。此功能使您能夠啟動系統跟蹤活動并在 Nsight Compute 界面中查看報告。然后,您可以檢查報告并從上下文菜單中啟動內核評測。
使用此工作流,您不必運行兩個不同的應用程序:所有這些都可以在一個應用程序中完成。
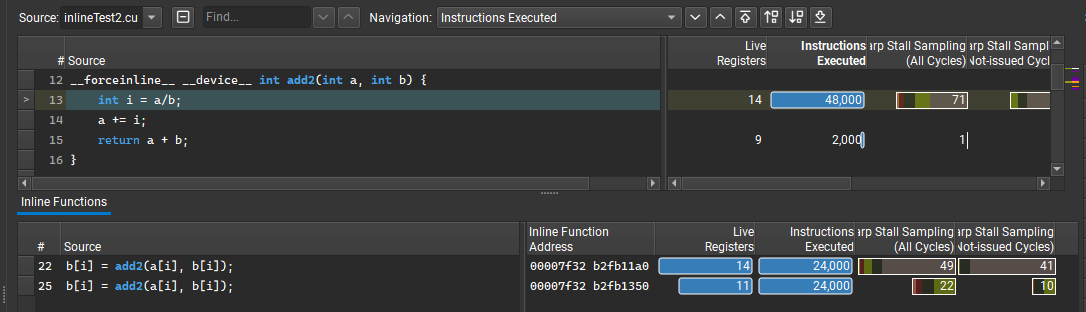
Nsight Compute 2022.4 還引入了一個新的內聯函數表,它為函數的多個內聯實例提供了性能度量。這個被大量請求的特性使您能夠了解函數是在一般情況下還是僅在特定的內聯情況下遇到性能問題。
它還使您能夠了解內聯發生的位置,當這種級別的詳細信息不可用時,這通常會導致混亂。主源代碼視圖繼續顯示每行級別的度量匯總,而表中列出了函數內聯的多個位置以及每個位置的性能度量。
Acceleration Structure 查看器還獲得了各種優化和改進,包括對 NVIDIA OptiX 曲線分析的支持。
有關詳細信息,請參見 NVIDIA Nsight Compute 、 NVIDIA Nsight Systems 和 Nsight Visual Studio Code Edition 。
數學庫更新
添加到庫中的所有優化和功能都是有代價的,通常以二進制大小的形式出現。每個庫的二進制大小在其生命周期中緩慢增加。 NVIDIA 已在不犧牲性能的情況下,努力縮小這些二進制文件。 cuFFT 的尺寸減小最大, CUDA 工具包 11.8 和 12.0 之間的尺寸減小超過 50% 。
還有一些特定于庫的特性值得一提。
庫布拉斯
cuBLASLt 使用新的 FP8 data types 公開了混合精度乘法運算。這些操作還支持 BF16 和 FP16 偏置融合,以及 FP8 輸入和輸出數據類型的 GEMs 的 FP16 偏置與 GELU 激活融合。
在性能方面,與 A100 上的 BF16 相比, H100 PCIe 和 SXM 上的 FP8 GEMM 分別快 3 倍和 4.5 倍。 CUDA Math API 提供 FP8 轉換,以便于使用新的 FP8 矩陣乘法運算。
cuBLAS 12.0 擴展了 API 以支持 64 位整數問題大小、前導維數和向量增量。這些新函數與 32 位整數對應函數具有相同的 API ,不同之處在于它們的名稱中帶有_64后綴,并將相應的參數聲明為int64_t。
cublasStatus_t cublasIsamax(cublasHandle_t handle, int n, const float *x, int incx, int *result);
64 位整數對應項如下:
cublasStatus_t cublasIsamax_64(cublasHandle_t handle, int64_t n, const float *x, int64_t incx, int64_t *result);
性能是 cuBLAS 的重點。當傳遞給 64 位整數 API 的參數符合 32 位范圍時,庫將使用與調用 32 位整數 API 相同的內核。要嘗試新的 API ,遷移應該像在 cuBLAS 函數中添加_64后綴一樣簡單,這要歸功于 C / C ++將int32_t值自動轉換為int64_t。
快速傅里葉變換
在計劃初始化期間, cuFFT 執行一系列步驟,包括試探法,以確定使用了哪些內核以及內核模塊加載。
從 CUDA 12.0 開始, cuFFT 使用 CUDA 并行線程執行( PTX )匯編形式(而不是二進制形式)提供了更多的內核。
當 cuFFT 計劃初始化時, CUDA 設備驅動程序在運行時加載 cuFFT 內核的 PTX 代碼并進一步編譯為二進制代碼。由于新的實現,第一個可用的改進將為 NVIDIA Maxwell 、 NVIDIA Pascal 、 NVIDIA Volta 和 NVIDIA Turing 架構啟用許多新的加速內核。
cuSPARSE 公司
為了減少稀疏稀疏矩陣乘法( SpGEMM )所需的工作空間, NVIDIA 發布了兩種內存使用率更低的新算法。第一種算法計算中間產品數量的嚴格界限,而第二種算法允許將計算劃分為塊。這些新算法對內存存儲量較小的設備上的客戶非常有用。
INT8 支持已添加到cusparseGather、cusparseScatter和cusparseCsr2cscEx2中。
最后,對于 SpSV 和 SpSM ,預處理時間平均提高了 2.5 倍。對于執行階段, SpSV 平均提高了 1.1 倍,而 SpSM 平均提高了 3.0 倍。
數學 API
新的 NVIDIA Hopper 架構配備了新的 Genomics 和 DPX 指令,用于更快地計算組合算術運算,如三向最大值、融合加法+最大值等。
新的 DPX 指令使動態編程算法比 A100 GPU 的速度提高了 7 倍。動態編程是一種通過將復雜遞歸問題分解為更簡單的子問題來解決復雜遞歸問題的算法技術。為了獲得更好的用戶體驗,現在通過 MathAPI 公開了這些說明。
例如,三路 max + ReLU 操作max(max(max(a, b), c), 0)。
int __vimax3_s32_relu ( const int a, const int b, const int c )
有關詳細信息,請參見 Boosting Dynamic Programming Performance Using NVIDIA Hopper GPU DPX Instructions 。
圖像處理更新: nvJPEG
nvJPEG 現在有一個改進的實現,顯著減少了 GPU 內存占用。這是通過使用零拷貝內存操作、融合內核和就地顏色空間轉換來實現的。
總結
我們繼續致力于幫助研究人員、科學家和開發人員通過簡化的編程模型解決世界上最復雜的 AI / ML 和數據科學挑戰。
該 CUDA 12.0 版本是多年來的第一個主要版本,是通過使用下一代 NVIDIA GPU 幫助加速應用程序的基礎。 NVIDIA Hopper 和 NVIDIA Ada Lovelace 體系結構中特定于體系結構的新功能和指令現在可通過 CUDA 自定義代碼、增強的庫和開發人員工具進行定位。
使用 CUDA 工具包,您可以在 GPU 加速的嵌入式系統、桌面工作站、企業數據中心、基于云的平臺和 HPC 超級計算機上開發、優化和部署應用程序。該工具包包括 GPU 加速庫、調試和優化工具、 C / C ++編譯器、運行庫以及對許多高級 C / C ++和 Python 庫的訪問。
有關更多信息,請參閱以下資源:
- NVIDIA CUDA Toolkit
- NVIDIA Hopper architecture and NVIDIA Ada Lovelace architecture
- CUDA Compatibility
- NVIDIA Releases Open-Source GPU Kernel Modules
- GPU-Accelerated Libraries
- NVIDIA Nsight Compute and NVIDIA Nsight Systems
?