
這個大型語言模型 (LLM) 縮放規律的最新發展已經表明,當模型參數的數量進行縮放時,用于訓練的令牌的數量也應該以相同的速率進行縮放。這個Chinchilla和LLaMA模型已經驗證了這些經驗推導的定律,并表明先前最先進的模型在預訓練期間使用的令牌總數方面訓練不足。
考慮到最近的發展, LLM 顯然比以往任何時候都更需要更大的數據集。
然而,盡管有這種需求,大多數為創建用于訓練 LLM 的大規模數據集而開發的軟件和工具都沒有公開發布或可擴展。這需要 LLM 開發人員構建自己的工具來策劃大型語言數據集。
為了滿足對大型數據集日益增長的需求,我們開發并發布了 NeMo 數據策展器:一種可擴展的數據策展工具,使您能夠策展萬億個代幣多語言數據集,用于 LLM 的預訓練。
Data Curator 是一組 Python 模塊,它使用 Message-Passing Interface (MPI),Dask 和 Redis Cluster 將以下任務擴展到數千個計算核心:
- 數據下載
- 文本提取
- 文本重新格式化和清理
- 質量過濾
- 精確或模糊重復數據消除
將這些模塊應用于數據集有助于減輕梳理非結構化數據源的負擔。通過文檔級重復數據消除,您可以確保對模型進行針對唯一文檔的培訓,從而大大降低預培訓成本。
在這篇文章中,我們概述了 Data Curator 中的每個模塊,并證明它們能夠提供超過 1000 個 CPU 內核的線性擴展。為了驗證所策劃的數據,我們還展示了使用Common Crawl 處理的文檔進行預訓練,相比于使用原始下載文檔,能夠顯著改善下游任務的效果。
數據管理管道
此工具使您能夠下載數據并進行大規模的提取、清理、消除重復數據和篩選文檔。圖 1 顯示了典型的 LLM 數據策劃流程,這是可以實現的。在以下各節中,我們將簡要介紹每一個可用模塊的實現。
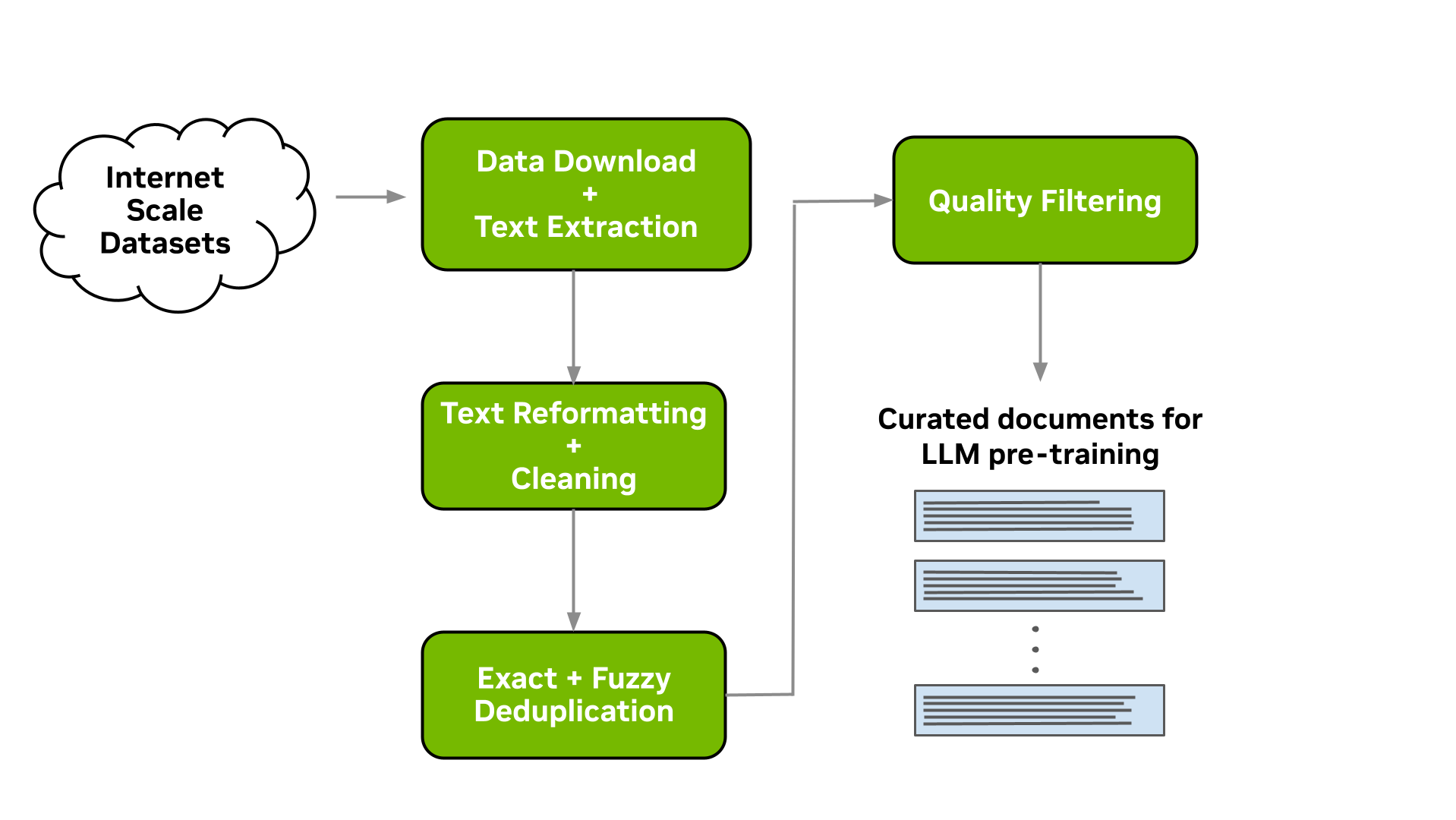
下載和文本提取
為許多 LLM 從業者準備自定義預訓練數據集的起點是指向包含 LLM 預訓練感興趣內容的數據文件或網站的 URL 列表。
Data Curator 讓您能夠從數據存儲庫下載預先爬取的網頁,例如Common Crawl,Wikidumps和ArXiv,并將相關文本提取到JSONL文件中。Data Curator 還提供了靈活性,允許您提供自己的下載和提取功能來處理來自各種來源的數據集。通過使用 MPI 和 Python 多處理器,您可以在運行時跨多個計算節點啟動數千個異步下載和提取工作程序。
文本重新格式化和清理
在下載并從文檔中提取文本時,一個常見的步驟是修復在提取過程中可能出現的所有與 Unicode 相關的錯誤,這些錯誤是由于文本數據未正確解碼而產生的。Data Curator 使用 Fixes Text For You library (ftfy) 來修復所有與 Unicode 相關的錯誤。清理過程還有助于規范文本,從而在執行文檔重復數據消除時提高召回率。
文檔級重復數據消除
當從大規模網絡爬網源,如公共爬網下載數據時,通常會遇到完全重復的文檔和高度相似的文檔(即近乎重復的文檔)。使用這些重復文檔對 LLM 進行預訓練可能會導致泛化能力差和文本生成過程中缺乏多樣性。
我們提供精確和模糊的重復數據消除實用程序,可從文本數據中刪除重復數據。精確重復數據消除實用程序計算每個文檔的 128 位散列,按散列將文檔分組到桶中,每個桶選擇一個文檔,并刪除桶中剩余的精確重復項。
模糊重復數據消除實用程序采用了基于 MinHashLSH 的方法,在此方法中,為每個文檔計算 MinHashes,然后利用 min-wise 哈希的位置敏感屬性對文檔進行分組。將文檔分組到存儲桶后,將計算每個存儲桶中文檔之間的相似性,以檢查在MinHashLSH中的應用。
對于這兩種重復數據消除實用程序, Data Curator 使用分布在計算節點上的 Redis Cluster 來實現分布式字典,用于將文檔聚類到存儲桶中。 Redis Cluster 實現的可擴展設計和八卦協議能夠有效地將重復數據消除工作負載擴展到許多計算節點。
文檔級質量篩選
除了包含相當一部分重復文檔外,來自 web 爬網源(如 Common crawl )的數據往往還包括許多帶有非正式散文的文檔。例如,這包括許多 URL 、符號、樣板內容、省略號或重復子字符串。從語言建模的角度來看,它們可以被認為是低質量的內容。
雖然已經表明,不同的 LLM 預訓練數據集會導致 改善下游性能,但大量的低質量文檔可能會 阻礙性能。Data Curator 為您提供了一個高度可配置的文檔過濾實用程序,使您能夠將自定義啟發式過濾器大規模應用于語料庫。該工具還包括語言數據過濾器的實現(基于分類器和啟發式),以 提高整體數據質量和下游任務性能,特別是在應用于 web 爬網數據時。
擴展到多個計算核心
為了展示 Data Curator 中可用的不同模塊的擴展能力,我們使用它們來準備一個由大約 40B 令牌組成的小型數據集。這涉及到在 5 TB 的 Common Crawl WARC 文件上運行前面描述的數據管理管道。
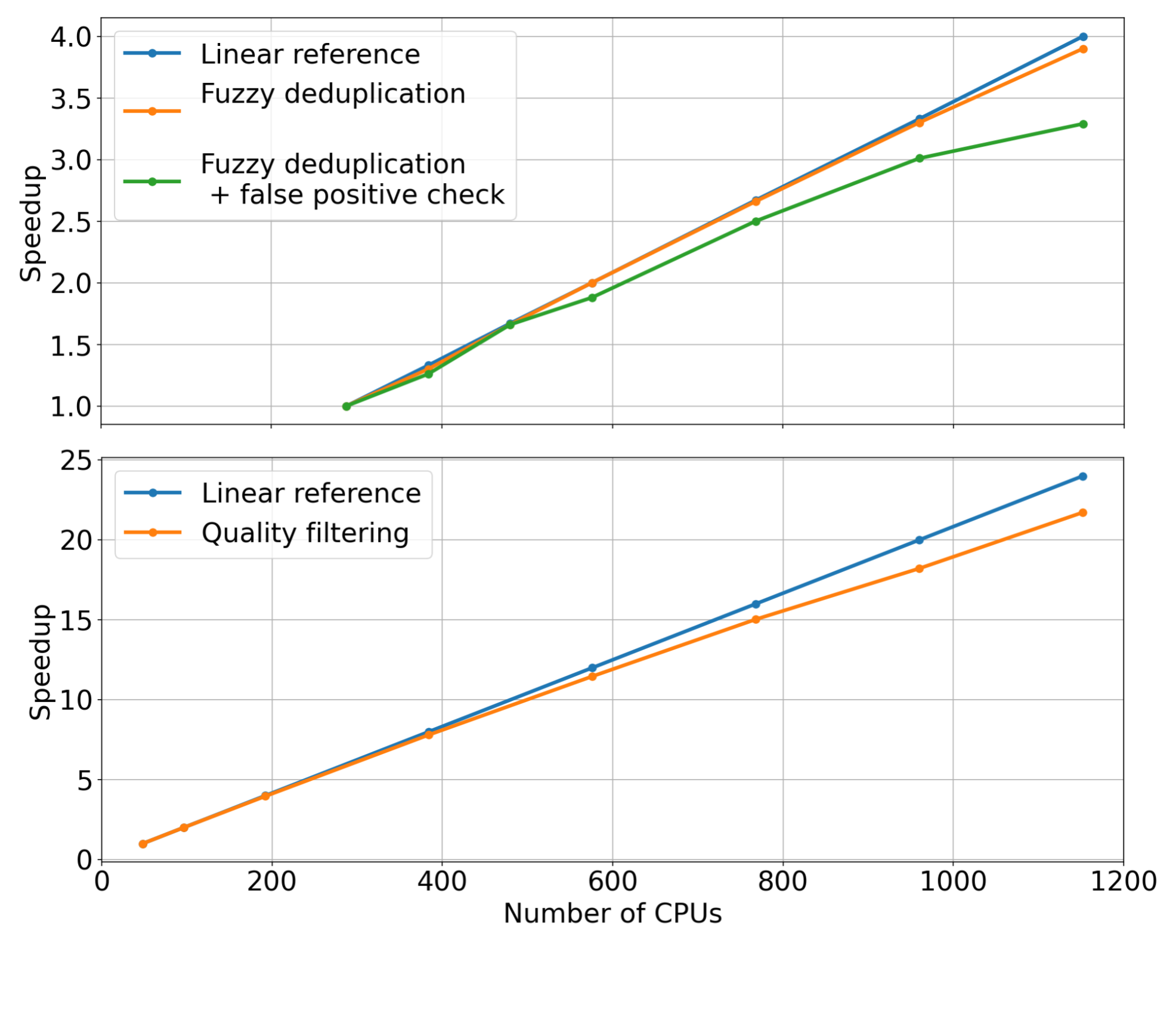
對于每個管道階段,我們固定了輸入數據集的大小,同時線性增加了用于擴展數據管理模塊的 CPU 核心的數量(即強擴展)。然后,我們測量了每個模塊的加速。測量的質量過濾和模糊重復數據消除模塊的加速如圖 2 所示。
通過檢查測量的趨勢,很明顯,當增加用于分配數據管理工作負載的 CPU 核心數量時,這些模塊可以達到顯著的加速。與線性參考(橙色曲線)相比,我們觀察到,當使用 1000 CPU 或更多時,兩個模塊都能夠實現相當大的加速。
固化的預訓練數據提高了模型的下游性能
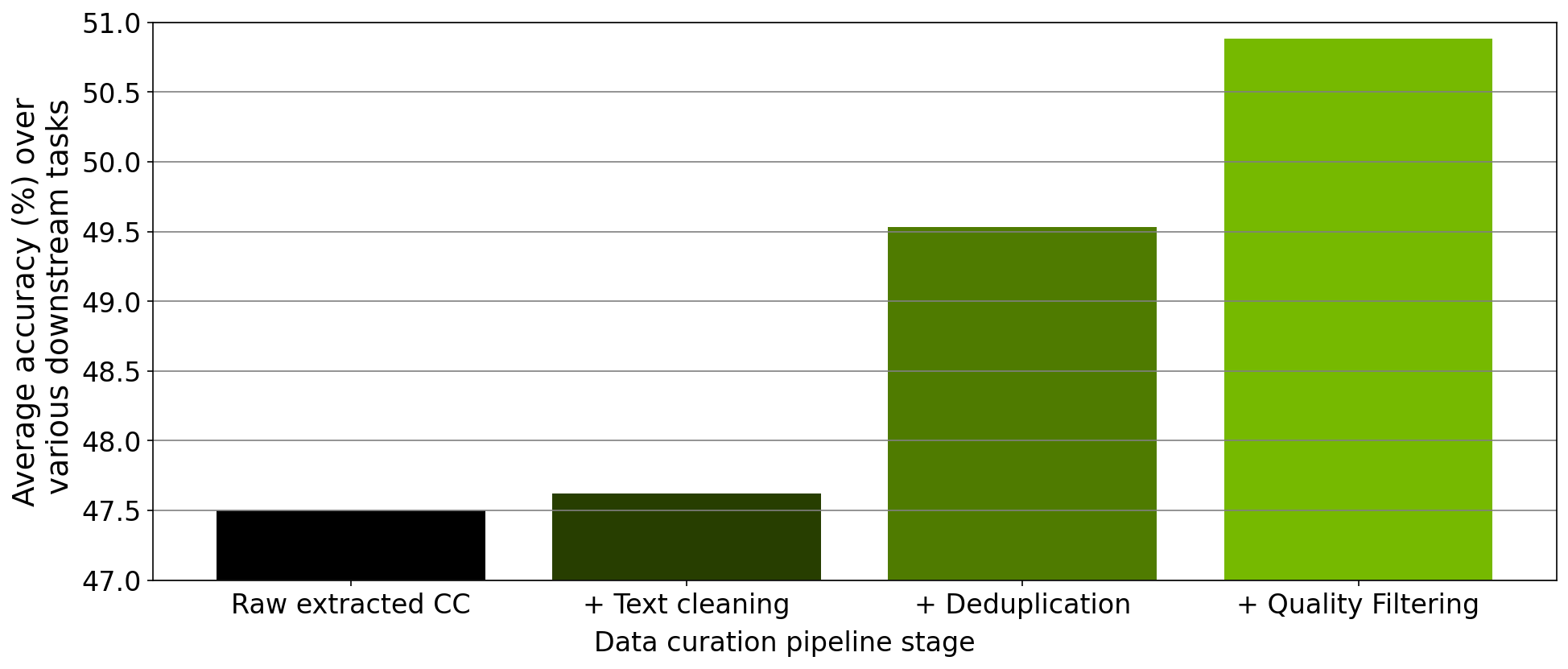
除了驗證每個模塊的縮放比例外,我們還對工具內實施的數據管理管道的每個步驟中收集的數據進行了消融研究。從下載的 Common Crawl 快照開始,我們在提取、清理、重復數據消除和篩選后,在此快照中策劃的 78M 個令牌上訓練了一個 357M 參數的 GPT 模型。
在每次預訓練實驗之后,我們在零樣本設置中評估 RACE-High 、 PiQA 、 Winogrande 和 Hellaswag 任務中的模型。圖 3 顯示了我們的消融實驗結果在所有四項任務中的平均值。隨著數據在管道的不同階段進行,所有四個任務的平均值都顯著增加,這表明數據質量有所提高。
使用 NeMo 數據策展人策展 2T 代幣數據集
最近,NVIDIA NeMo service 開始為早期訪問用戶提供定制 NVIDIA 訓練的 43B 參數多語言大型基礎模型的機會。為了預訓練這個基礎模型,我們準備了一個由 2T 令牌組成的數據集,其中包括來自各種不同領域的 53 種自然語言以及 37 種不同的編程語言。
策劃這個大型數據集需要將我們在 data Curator 中實現的數據策劃管道應用于 6K 以上的 CPU 集群上總共 8 . 7 TB 的文本數據。在這些代幣的 1 . 1T 上預訓練 43B 基礎模型,產生了最先進的 LLM , NVIDIA 客戶目前正在使用該 LLM 來滿足其 LLM 需求。
結論
為了滿足 LLM 預訓練數據集管理的日益增長需求,我們推出了 Data Curator,這是 NeMo framework 的一部分。我們已經證明,這個工具能夠收集高質量的數據,從而提高 LLM 的下游性能。此外,我們已經展示了 Data Curator 中的每個數據管理模塊都可以擴展到使用數千個 CPU 核心。我們預計,這個工具將大大有利于 LLM 開發人員嘗試構建預訓練數據集。
?





