
調試代碼是軟件開發的關鍵方面,但可能具有挑戰性且耗時。并行編程可以為已經很復雜的調試過程引入新的維度,其中可以同時處理數千個線程。
開發人員可以使用各種工具和技術來幫助使調試變得更簡單、更高效。本文介紹了一種調試工具:NVIDIA Compute Sanitizer。我們將探索這些功能,并通過示例向您展示它的用途,以便您可以在調試過程中節省時間和精力,同時提高 CUDA 應用程序的可靠性和性能。
Compute Sanitizer 隨CUDA Toolkit一起捆綁。
什么是 Compute Sanitizer ?
Compute Sanitizer 是一套工具,可以對代碼的功能正確性執行不同類型的檢查。調試的一個關鍵挑戰是找到錯誤的根本原因,解決它通常比追蹤它更容易,尤其是在并行執行環境中,因為在這種環境中,錯誤的來源可能是瞬態的。
Compute Sanitizer 通過檢查代碼是否存在內存訪問違規、競爭條件、對未初始化變量的訪問以及同步錯誤,擅長于根本原因調試。所有這些都可能表現為 bug ,但其行為不一定會直接導致源代碼中的根本原因。
您可能已經熟悉一種用于調試的工具:cuda-memcheck。但是,該工具已在 CUDA 11.6 中被棄用,并在 ZCk 12.0 及更高版本中被刪除。Compute Sanitizer 已取代它的位置,提供了額外的功能,如改進的性能和對 Microsoft hardware-accelerated GPU scheduling 的支持,以及對內存檢查之外的功能的更廣泛支持。
Compute Sanitizer 中有四個主要工具:
memcheck:用于內存訪問錯誤和泄漏檢測racecheck:共享內存數據訪問危險檢測工具initcheck:未初始化的設備全局內存訪問檢測工具synccheck:用于線程同步危險檢測
除了這些工具, Compute Sanitizer 還有一些額外的功能:
- 用于創建針對 CUDA 應用程序的清理和跟蹤工具的 API 。
- 與 NVIDIA 工具擴展(NVTX)集成
- Coredump 支持可用于 cuda-gdb
開始使用 Compute Sanitizer
Compute Sanitizer 是 CUDA Toolkit 的一部分。要了解更多信息和獲取工具包的鏈接,請訪問 NVIDIA Compute Sanitizer。
安裝工具包后,使用以下格式從命令行啟動 Compute Sanitizer :
$ compute-sanitizer [options] app_name [app_options]
表 1 顯示了計算消毒器的選項。想要了解更多信息,請參閱 命令行選項,在 Compute Sanitizer 用戶手冊 中。
| 選項 | 描述 |
--kernel-regex kns=myKernel 子字符串 |
控制計算消毒器工具檢查哪些內核。對于管理測試和工具輸出的大型復雜代碼非常有用。 |
–-launch-skip N |
跳過N內核在開始檢查之前啟動。 |
–-log-file 文件名 |
設置 Compute Sanitizer 寫入的文件。通常, Compute Sanitizer 直接寫入stdout. |
--generate-coredump yes |
當檢測到錯誤時創建一個 CUDA 核心轉儲,稍后可以加載到 CUDA debugger 中cuda-gdb以便進一步分析。 |
為 Compute Sanitizer 編譯
Compute Sanitizer 可以在沒有任何特殊編譯標志的情況下成功分析和檢查 GPU 應用程序。但是,通過在代碼的編譯階段包含一些額外的標志,可以使工具的輸出更加有用,例如-lineinfo生成行號信息,而不會在優化級別上影響代碼。然后 Compute Sanitizer 可以將錯誤歸因于源代碼行。
計算消毒器內存檢查
也許 Compute Sanitizer 中最常用的工具是內存檢查器。下面的代碼示例顯示了一個簡單的 CUDA 程序,用于將數組的每個元素乘以標量。這個代碼執行到完全沒有抱怨,但你能看到它有什么問題嗎?
#include <assert.h>#include <stdio.h>#define N 1023__global__ void scaleArray(float* array, float value) { int threadGlobalID = threadIdx.x + blockIdx.x * blockDim.x; array[threadGlobalID] = array[threadGlobalID]*value; return;}int main() { float* array; cudaMallocManaged(&array, N*sizeof(float)); // Allocate, visible to both CPU and GPU for (int i=0; i<N; i++) array[i] = 1.0f; // Initialize array printf("Before: Array 0, 1 .. N-1: %f %f %f\n", array[0], array[1], array[N-1]); scaleArray<<<4, 256>>>(array, 3.0); cudaDeviceSynchronize(); printf("After : Array 0, 1 .. N-1: %f %f %f\n", array[0], array[1], array[N-1]); assert(array[N/2] == 3.0); // Check it's worked exit(0);} |
如果您發現越界數組訪問,則得 10 分:
- 執行配置
<<<4, 256>>>啟動 4 個塊,每個塊中有 256 個線程,因此總共有 1024 個線程。 - 數組有長度N= 1023 ,索引為 0 , 1 …,N-2 = 1021 ,N-1 = 1022 。
- 在某個點上, 1024 線程,它有一個
threadGlobalID的值1023 = threadIdx.x + blockIdx.x * blockDim.x = 255+3*256,嘗試執行代碼。 - 嘗試將越界數組訪問作為
array[1023].
這導致了一個令人討厭的錯誤:“未定義的行為”。它很可能會悄無聲息地失敗。在較大的程序中,它可能會導致嚴重的正確性問題,影響其他內存分配,甚至可能導致分段錯誤。
嘗試編譯并運行以下代碼:
$ nvcc -lineinfo example1.cu -o example1.exe$ ./example1.exeBefore: Array 0, 1 .. N-1: 1.000000 1.000000 1.000000After : Array 0, 1 .. N-1: 3.000000 3.000000 3.000000 |
請來 Compute Sanitizer 提供幫助。嘗試運行以下命令,您應該會看到類似的輸出:
$ compute-sanitizer --tool memcheck ./example1.exe========= COMPUTE-SANITIZERBefore: Array 0, 1 .. N-1: 1.000000 1.000000 1.000000========= Invalid __global__ read of size 4 bytes========= at 0x70 in /home/pgraham/devblog/NCS/example1.cu:8:scaleArray(float *, float)========= by thread (255,0,0) in block (3,0,0)========= Address 0x7f3aae000ffc is out of bounds========= and is 1 bytes after the nearest allocation at 0x7f3aae000000 of size 4092 bytes... |
想要了解更多關于如何解釋此輸出的信息,請參閱 理解 Memcheck 錯誤,但我們可以討論一些關鍵特性。首先,您會得到錯誤 info Invalid __global__ read,因為 GPU 正試圖讀取某個不是合法地址的全局存儲器。然后,您可以獲得文件和行號,以及導致此問題的實際線程和塊。在這種情況下,example1.cu:8 映射到源中的直線 array[threadGlobalID] = array[threadGlobalID]*value;。
現在您可以修復代碼了。有多種選擇,但添加if threadGlobalID<N之前的錯誤線路可能是最容易的。重新編譯并運行memcheck 工具再次確認。
現在,你發現其他問題了嗎?
如果你發現缺少,得 20 分cudaFree 對于MallocManaged 數組。同樣,代碼運行到完成。您似乎得到了正確的答案,但由于沒有釋放分配的內存,您引入了泄漏!這可能會減少后續應用程序可用的內存量,甚至導致系統不穩定。
香草味的memcheck 錯過了這個。如何檢查這些錯誤?的附加選項之一memcheck 該工具可以在以下方面為您提供幫助:--leak-check=full.
$ compute-sanitizer --tool memcheck --leak-check=full ./example1.exe========= COMPUTE-SANITIZERBefore: Array 0, 1 .. N-1: 1.000000 1.000000 1.000000After : Array 0, 1 .. N-1: 3.000000 3.000000 3.000000========= Leaked 4092 bytes at 0x7ff652000000========= Saved host backtrace up to driver entry point at allocation time========= Host Frame: [0x2b7e93]========= in /usr/lib/x86_64-linux-gnu/libcuda.so.1========= Host Frame:__cudart585 [0x439a0]========= in /home/pgraham/devblog/NCS/./example1.exe========= Host Frame:__cudart836 [0x10c76]========= in /home/pgraham/devblog/NCS/./example1.exe========= Host Frame:cudaMallocManaged [0x51483]========= in /home/pgraham/devblog/NCS/./example1.exe========= Host Frame:cudaError cudaMallocManaged<float>(float**, unsigned long, unsigned int) [0xb066]========= in /home/pgraham/devblog/NCS/./example1.exe========= Host Frame:main [0xac2e]========= in /home/pgraham/devblog/NCS/./example1.exe========= Host Frame:__libc_start_main [0x24083]========= in /usr/lib/x86_64-linux-gnu/libc.so.6========= Host Frame:_start [0xab0e]========= in /home/pgraham/devblog/NCS/./example1.exe================== LEAK SUMMARY: 4092 bytes leaked in 1 allocations========= ERROR SUMMARY: 1 error |
您應該看到類似于代碼示例中所示的輸出。cudaError 突出顯示,這表明您對cudaMallocManaged 創建了泄漏的內存。在代碼退出之前,未釋放分配的內存。正在添加cudaFree(array);就在最后exit(0);修復了這個問題。這樣做,重新編譯、執行并檢查您(以及memcheck 工具)現在對您的代碼感到滿意。
這是一個簡單的程序,用于在 GPU 上縮放陣列,以顯示 Compute Sanitizer 和 memcheck 如何工作。使用網格步長循環,可以為任意大小的數組編寫代碼,以訪問 CUDA 中的數組。要了解有關圍繞 CUDA API 調用的錯誤檢查代碼的更多信息,請參閱 如何在 CUDA C/C++ 中查詢設備屬性和處理錯誤。
什么是數據競賽?
數據競賽是并行編程方法特有的問題。當多個線程同時訪問共享數據,并且至少有一個訪問是寫操作時,就會發生這種情況。圖 1 顯示了一個簡單的示例。
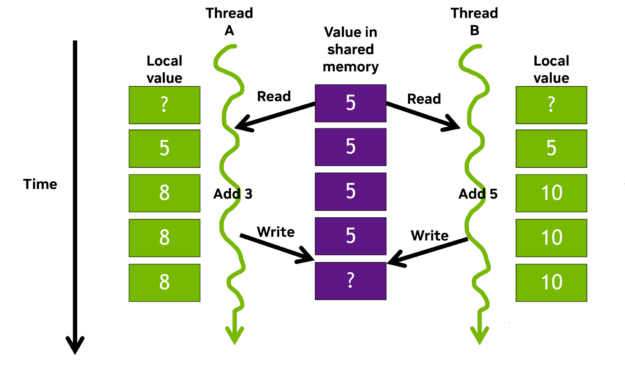
使用聲明的存儲__shared__限定符被放置在片上共享存儲器中。同一線程塊內的所有線程都可以訪問這種按塊共享內存,與全局內存訪問相比速度要快得多。共享內存經常用于線程間通信,并用作保存正在處理的數據的臨時緩沖區。
考慮線程 A 和線程 B 并行工作,并將它們的本地計數貢獻給共享計數器。線程將它們自己的本地值添加到共享值,并同時將它們的和寫回共享內存。由于 A 和 B 現在正在向同一地址寫入不同的值,因此發生了數據競爭,結果突然不正確,甚至可能是未定義的。
有一些機制可以避免這種情況。例如,鎖和原子操作通過保護對共享值的更新來幫助確保正確的行為。然而,我們都容易犯錯。在具有數千個線程的復雜代碼中,是否存在問題可能是不明確的。共享值很可能仍然會增加,只是不是按照數據值所建議的方式增加,從而產生一個看似成功的、帶有錯誤值的運行。
這就是 Compute Sanitizerracecheck功能是如此寶貴。此工具是一個競爭條件檢測功能,可幫助您識別和解決 CUDA 代碼中的數據競爭。
下面的代碼示例顯示了用于演示的 GPU 內核racecheck:
#include <assert.h>#include <stdio.h>#define N 1024__global__ void blockReduceArray(int* array, int* sum) { int threadGlobalID = threadIdx.x + blockIdx.x * blockDim.x; __shared__ int blockSum; if (threadIdx.x == 0 ) { sum[blockIdx.x] = 0; // Initialise the return value blockSum = 0; // Initialise our block level counter } __syncthreads(); // Add each thread's value to our block level total blockSum += array[threadGlobalID]; __syncthreads(); // Set the return value if (threadIdx.x == 0 ) sum[blockIdx.x] = blockSum; return;}int main() { int globalSum; int* sum; int* array; int numBlocks = 4; cudaMallocManaged(&array, N*sizeof(int)); cudaMallocManaged(&sum, numBlocks*sizeof(int)); for (int i=0; i<N; i++) array[i] = 1; // Initialize array blockReduceArray<<<numBlocks, N/numBlocks>>>(array, sum); cudaDeviceSynchronize(); // Do a reduction on the host of the block values globalSum = 0; for (int i=0; i<numBlocks; i++) globalSum += sum[i]; printf("After kernel - global sum = %d\n", globalSum); cudaFree(sum); cudaFree(array); exit(0);} |
該示例將數組中的所有值相加以生成單個值,也稱為減少活動它在 GPU 上的塊級別進行匯總。然后,每個塊的總和返回到主機,并再次求和,以返回將數組中的每個值相加的總值。此示例使用快速共享內存作為緩沖區,以保存數組元素添加的運行總數。
這種方法避免了對全局內存進行不必要的寫入,直到內核結束時進行最終更新。在引入此類優化時,最好使用分析驅動的方法。對代碼進行分析,檢查是否存在任何瓶頸、未充分利用的硬件或要優化的算法;應用您的更改;然后重復。
在您熟悉了代碼之后,編譯并運行它,看看它是否有效。您正在將數組中的每個元素初始化為一,并且有 1024 個元素,因此最終的總和應該是 1024 。以下是輸出:
$ nvcc -lineinfo example2.cu -o example2.exe$ ./example2.exe$After kernel - global sum = 4 |
另一個錯誤: 4 絕對不是 1024 ,正如你所期望的那樣!
計算消毒器racecheck 幫助您確定失敗的原因并避免出現這種情況。跑道檢查 命令的執行方式與memcheck下面的示例顯示了該命令的輸出。第 17 行出現問題,如錯誤消息所示。
$ compute-sanitizer --tool racecheck ./example2.exe========= COMPUTE-SANITIZER========= Error: Race reported between Read access at 0xe0 in /home/pgraham/devblog/NCS/example2.cu:17:blockReduceArray(int *, int *)========= and Write access at 0x100 in /home/pgraham/devblog/NCS/example2.cu:17:blockReduceArray(int *, int *) [16 hazards]=========After kernel - global sum = 4========= RACECHECK SUMMARY: 1 hazard displayed (1 error, 0 warnings) |
如果您查看突出顯示的代碼行,您可以看到問題:
... // Add each thread's value to the block level totalblockSum += array[threadGlobalID];... |
塊中的所有線程同時嘗試讀取存儲為blockSum,將它們的數組值添加到其中,并將其寫回共享內存地址。這創建了一個競賽條件,如圖 1 中的示例所示。因此,每個線程讀取共享值( 0 ),將其遞增( 1 ),然后寫回 1 。最終,共享值最終是 1 ,而不是 256 ,當將四個塊中的每一個加在一起時,您會看到錯誤的答案 4 。
您可以通過將第 17 行更改為 atomicAdd 來實現:
atomicAdd(&blockSum, array[threadGlobalID]); |
此操作保護對共享值的訪問blockSum 通過確保它是由訪問線程以串行方式讀取、遞增和寫入的。代碼現在可以正常運行。
順便提一句,atomicAdd 在修復過程中可能會降低代碼性能。例如,它可能會序列化每個塊中的 256 個線程。NVIDIA CUB 是一個可重復使用的軟件組件庫,它提供塊級和設備級原語,用于執行高度優化的縮減操作。
在可能的情況下,我們建議在開發和性能調優通用代碼模式時使用庫或組件(如 CUB ),因為它們通常會超過您在合理時間內可以實現的性能。而且它們通常是免費的!
如果不是這樣簡單的代碼知道了預期的答案,那么像這樣的比賽條件很容易被發現。所以racecheck 幫助避免了以后難以破解的問題。
結論
使用NVIDIA Compute Sanitizer,立即下載CUDA Toolkit。
希望我們已經向您介紹了如何開始使用 Compute Sanitizer。當然,這些工具的功能非常豐富,我們只是略知一二。想要了解更多關于 Compute Sanitizer 的信息和示例,請訪問 NVIDIA/compute-sanitizer-samples GitHub 樣本回購和 Compute Sanitizer 用戶手冊。
最近的 GTC 課程涵蓋了 Compute Sanitizer 中引入的一些新功能:
為了獲得支持,開發者論壇以及專門針對 sanitizer 工具的 子論壇都是不錯的起點。
如果你想更深入地了解本文中沒有討論的任何功能,請告訴我們。祝你好運!
?






