語音是與 AI 驅動的應用程序通信的主要手段之一。從虛擬助理到數字化身,基于語音的界面正在改變我們通常與智能設備的交互方式。
深度學習?用于語音識別和語音合成的技術有助于改善用戶體驗,如人類般的響應和自然的音調。
如果您計劃構建和部署支持語音 AI 的應用程序,本文將概述 自動語音識別?( ASR )和文本到語音( TTS )技術如何因深度學習而發展。我還提到了當今現代應用中使用的一些流行的、最先進的 ASR 和 TTS 架構。
解密語音 AI
無論你是在元宇宙中與數字人交談,還是在聯絡中心與真人交談,每天都會產生數千億分鐘的音頻。語音 AI 可以幫助自動化所有這些音頻分鐘。
Speech AI 包括 ASR 、 TTS 和相關任務等技術。有趣的是,這些技術并不新鮮,而且已經存在了 50 年。
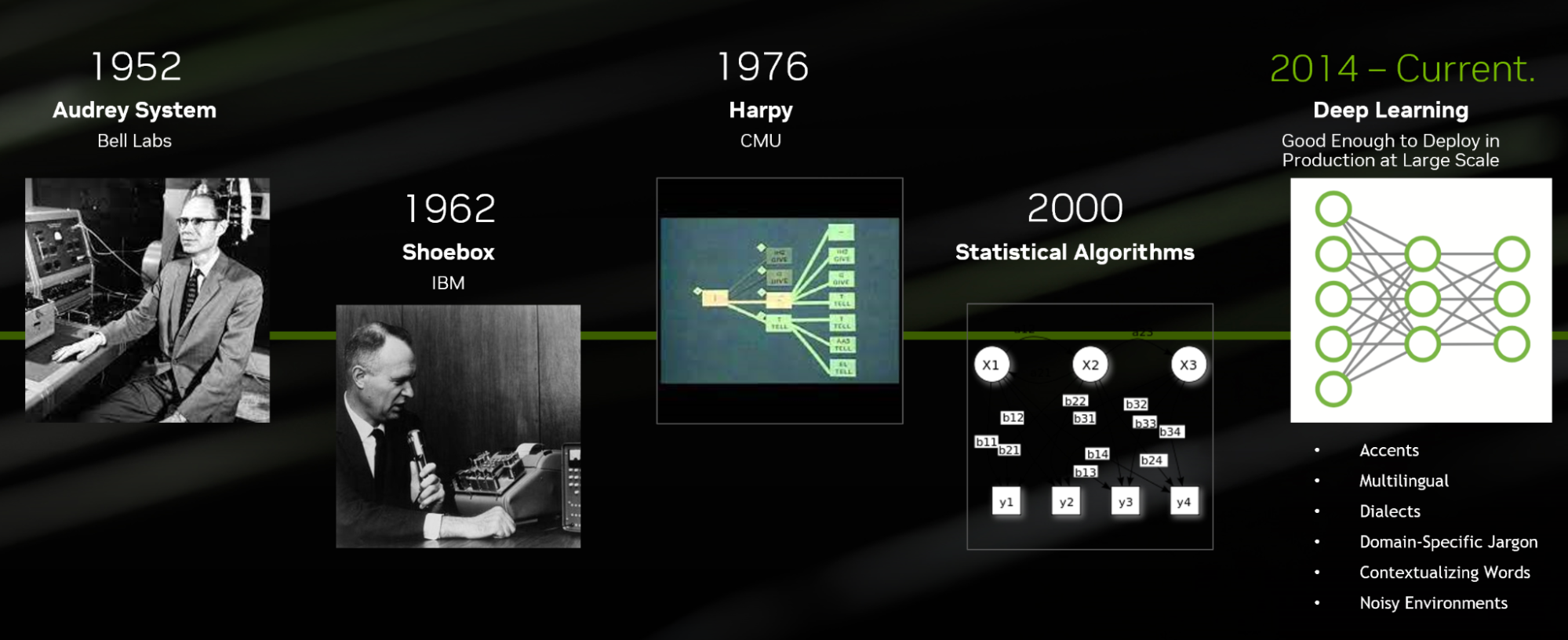
語音識別進化
今天,使用深度學習技術開發的 ASR 算法可以針對特定領域的行話、語言、口音和方言進行定制,也可以在嘈雜的環境中進行轉錄。
這種技術水平與貝爾實驗室于 1952 年發明的第一個 ASR 系統 Audrey 有很大不同。當時, Audrey 只能轉錄數字,并沒有使用深度學習技術開發。
ASR 管道
標準 ASR deep learning pipeline 由特征提取器、聲學模型、解碼器和語言模型以及 BERT 標點符號和大寫模型組成。
文本到語音的演變
使用深度學習技術開發的 TTS 或語音合成系統聽起來像真人,可以實時運行,進行自然而有意義的討論。另一方面,傳統系統如 Voder 、 DECtalk 商用和串聯 TTS 聲音機器人,很難實時運行。
深度學習 TTS 算法足夠靈活,因此您可以在推斷時調整速度、音調和持續時間,以生成更具表現力的 TTS 語音。
TTS 管道
基本 TTS pipeline 包括以下組件:文本規范化、文本編碼、音調/持續時間預測器、譜圖生成器和聲碼器模型。
您可以在點播視頻 Speech AI Demystified 中進一步了解 ASR 和 TTS 在過去幾年中的變化,以及 ASR 和 TTS 管道中的每個模型和模塊。
當前使用的流行 ASR 和 TTS 架構
已經創建了幾種最先進的神經網絡架構。當今 ASR 中最流行的一些是 CTC 和基于傳感器的架構模型。例如,您可以將這些架構技術應用于 CitriNet 和 Conformer 等模型。
對于 TTS ,存在不同類型的架構:
- 自回歸或非自回歸
- 確定性或生成性
- 顯式控件或非顯式控件
這些 TTS 架構中的每一個都提供不同的功能。例如,確定性模型可以準確預測結果,而不包括隨機性。生成模型包括數據分布本身,可以捕捉合成語音的不同變化。要構建端到端的文本到語音管道,必須將每個類別中的一個架構組合起來。
您可以在點播視頻 Speech AI Demystified 中獲得最新的架構最佳實踐,為支持語音的應用程序構建 ASR 和 TTS 管道。
NVIDIA 語音 AI SDK
通過利用 GPU 加速語音 AI SDK ,您可以開發基于深度學習的 ASR 和 TTS 算法。 NVIDIA Riva 幫助您構建和部署可定制的 AI 管道,在所有云、內部、邊緣和嵌入式設備上提供世界級的準確性。
Riva 擁有最先進的 NGC 預訓練模型 ,可在多個開放和專有數據集上進行訓練。您可以使用低編碼工具定制這些模型,以適應您的行業和使用情況,并優化語音 AI 技能,這些技能可以實時運行,而不犧牲準確性。
構建您的第一個語音 AI 應用程序
您是否希望為應用程序添加交互式語音體驗?以下免費電子書將指導您的旅程:
- 使用 語音人工智能介紹?全面了解不斷增長的語音 AI 環境。
- 使用 End-to-End Speech AI Pipelines 了解如何通過將 TTS 技能添加到應用程序中來實現自然發音的語音。
- 了解您的組織如何使用 開發語音人工智能應用?部署語音 AI 。
如果您喜歡循序漸進的指導,請查看 開始使用用于語音 AI 的高度準確的自定義 ASR?的自定進度在線課程。
?