
在一個新的汽車應用程序中,我們使用了 卷積神經網絡 ( CNNs )來映射從前置攝像頭到自動駕駛汽車的轉向命令的原始像素。這種強大的端到端方法意味著,只要從人類那里獲得最少的訓練數據,系統就可以學會在當地道路和高速公路上使用或不使用車道標線進行轉向。該系統還可以在視覺引導不清晰的區域運行,如停車場或未鋪路面的道路。[編者按:一定要查看新文章“[Editor ’ s Note : be sure to check out the new post “ 解釋端到端深度學習如何駕駛自動駕駛汽車 ”]。

我們設計了一個端到端的學習系統,使用 NVIDIA 開發箱 運行的 Torch 7 進行培訓。安NVIDIA DRIVETMPX自動駕駛汽車電腦,也與 Torch 7,是用來確定在哪里駕駛時,以 30 幀每秒( FPS )。該系統訓練成僅以人的轉向角為訓練信號,自動學習必要處理步驟的內部表示,例如檢測有用的道路特征。我們從來沒有明確地訓練它去探測,例如,道路的輪廓。與使用顯式分解問題的方法(如車道標記檢測、路徑規劃和控制)相比,我們的端到端系統同時優化所有處理步驟。
我們相信端到端的學習可以帶來更好的性能和更小的系統。更好的性能結果是因為內部組件自我優化來實現最大化系統性能,而不是優化人為選擇的中間標準,例如車道檢測。可以理解的是,選擇這樣的標準是為了便于人理解,而這并不能自動保證最大的系統性能。更小的網絡是可能的,因為系統學會用最少的處理步驟來解決問題。
這篇博文基于 NVIDIA 論文 自動駕駛汽車的端到端學習 。詳情請參閱原文。
用卷積神經網絡處理視覺數據
CNNs [1] 使計算模式識別過程發生了革命性的變化 [2] ,在 CNNs 被廣泛采用之前,大多數模式識別任務都是在最初階段使用手工制作的特征提取和分類器來完成的。 CNNs 的一個重要突破是特征可以從訓練樣本中自動學習。 CNN 方法在應用于圖像識別任務時特別強大,因為卷積運算捕捉圖像的 2D 特性。通過使用卷積核來掃描整個圖像,與操作總數相比,需要學習的參數相對較少。
而具有學習特性的 cnn 已經在商業上使用了二十多年[3]近年來,由于兩個重要的發展,它們的采用呈爆炸式增長。首先,像 ImageNet 大規模視覺識別挑戰( ILSVRC ) [4] 這樣的大型標記數據集現在已經廣泛用于培訓和驗證。第二, CNN 學習算法現在在大規模并行圖形處理單元( GPUs )上實現,極大地提高了學習和推理能力。
我們在這里描述的 cnn 超越了基本的模式識別。我們開發了一個系統來學習駕駛汽車所需的整個處理流程。這個項目的基礎工作實際上是在 10 年前國防高級研究計劃局( DARPA )的苗木項目中完成的,這個項目被稱為 DARPA 自動車輛( DAVE ) [5] ,在這個項目中,一輛小規模無線電控制( RC )車開過一條垃圾堆滿的小巷。戴夫接受的訓練是在相似但不完全相同的環境中駕駛人的時間。訓練數據包括來自兩臺攝像機的視頻和一名操作員發出的轉向指令。
在很多方面,戴夫受到了波默洛的開創性工作的啟發 [6] 他于 1989 年在一個神經網絡( ALVINN )系統中制造了自動陸地車輛。 ALVINN 是 DAVE 的先驅,它提供了一個概念的初步證明,即有一天,一個端到端訓練的神經網絡 MIG ht 能夠在公共道路上駕駛汽車。 DAVE 展示了端到端學習的潛力,并確實被用來證明啟動 DARPA 學習應用于地面機器人( LAGR )項目 [7] ,但是戴夫的表現不夠可靠,不足以提供一個完整的替代方案,更模塊化的越野駕駛方法。( DAVE 在復雜環境中的平均相撞距離約為 20 米。)
大約一年前,我們開始了一項新的工作來改進原來的 DAVE ,并創建了一個在公共道路上行駛的強大系統。這項工作的主要動機是避免需要識別特定的人類指定特征,如車道標記、護欄或其他汽車,并避免創建“如果,那么,“ else ”規則,基于對這些特征的觀察。我們很高興與大家分享這項新工作的初步成果,這項工作的名稱很恰當: DAVE – 2 。
DAVE-2 系統
圖 2 顯示了 DAVE-2 訓練數據采集系統的簡化框圖。三個攝像頭安裝在數據采集車的擋風玻璃后面,攝像頭的時間戳視頻與駕駛員施加的轉向角同時捕獲。通過接入車輛控制器局域網( CAN )總線獲得轉向指令。為了使我們的系統獨立于車輛的幾何結構,我們將轉向命令表示為 1 / r ,其中 r 是轉彎半徑,單位為米。我們使用 1 / r 而不是 r 來防止直線行駛時出現奇點(直線行駛的轉彎半徑是無窮大)。 1 / r 從左轉彎(負值)平穩過渡到右轉彎(正值)。
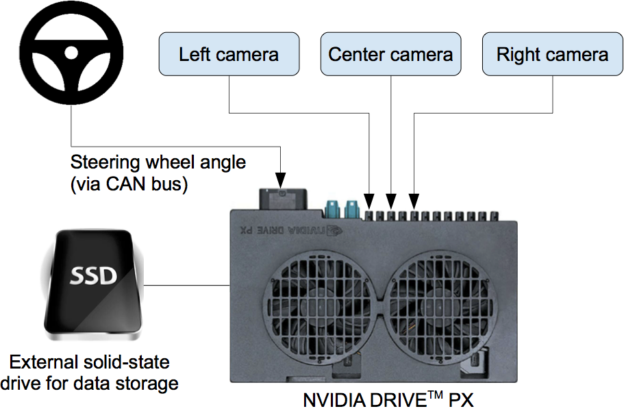
訓練數據包含從視頻中采樣的單個圖像,與相應的轉向指令( 1 / r )配對。僅僅使用人類駕駛員的數據進行培訓是不夠的;網絡還必須學會如何從任何錯誤中恢復,否則汽車將慢慢偏離道路。因此,訓練數據被附加的圖像增強,這些圖像顯示了汽車從車道中心的不同位移和從道路方向的旋轉。
兩個特定的偏離中心偏移的圖像可以從左右攝像機獲得。通過對來自最近攝像機的圖像進行視點變換,模擬攝像機之間的附加位移和所有旋轉。精確的視點變換需要我們沒有的三維場景知識,所以我們假設地平線以下的所有點都在平地上,地平線以上的所有點都是無限遠的,來近似地進行變換。對于平坦的地形,這很好,但是對于更完整的渲染,它會對粘在地面上的對象(如汽車、電線桿、樹木和建筑物)引入扭曲。幸運的是,這些扭曲并沒有給網絡培訓帶來重大問題。變換后的圖像的轉向標簽會快速調整為在兩秒鐘內將車輛正確地轉向到所需的位置和方向。
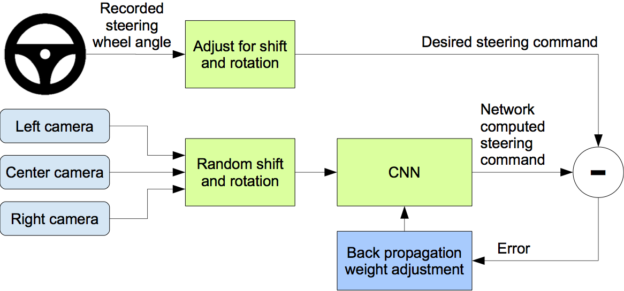
圖 3 顯示了我們的培訓系統的框圖。圖像被輸入 CNN ,然后由 CNN 計算出建議的轉向指令。將提出的命令與該圖像的所需命令進行比較,并調整 CNN 的權重以使 CNN 輸出更接近所需的輸出。重量調整是通過在 Torch 7 機器學習包中實現的反向傳播來完成的。
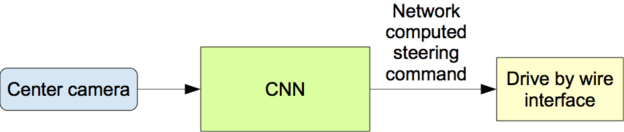
一旦經過訓練,網絡就能夠從單中心攝像機的視頻圖像中生成轉向指令。圖 4 顯示了這個配置。
數據收集
培訓數據是通過在各種各樣的道路上以及在不同的照明和天氣條件下駕駛來收集的。我們收集了來自新澤西州,伊利諾伊州和新澤西州的數據。其他道路類型包括雙車道道路(帶和不帶車道標線)、有停車場的住宅道路、隧道和未鋪面道路。數據收集在晴朗,多云,霧,雪和雨的天氣,白天和晚上。在某些情況下,太陽在天空中很低,導致眩光從路面反射并從擋風玻璃上散射。
這些數據是通過我們的線控測試車( 2016 款林肯 MKZ )或 2013 款福特福克斯( Ford Focus )獲得的,該車的攝像頭位置與林肯車相似。我們的系統不依賴于任何特定的車輛品牌或型號。司機們被鼓勵保持全神貫注,但在其他方面,他們通常會這樣開車。截至 2016 年 3 月 28 日,收集了大約 72 小時的駕駛數據。
網絡體系結構
我們訓練網絡的權值,以使網絡輸出的轉向命令與人類駕駛員的指令或偏離中心和旋轉圖像的調整后的轉向指令之間的均方誤差最小化(見后面的“增強”)。圖 5 顯示了網絡體系結構,它由 9 個層組成,包括一個規范化層、 5 個卷積層和 3 個完全連接的層。將輸入的圖像分割成 YUV 。
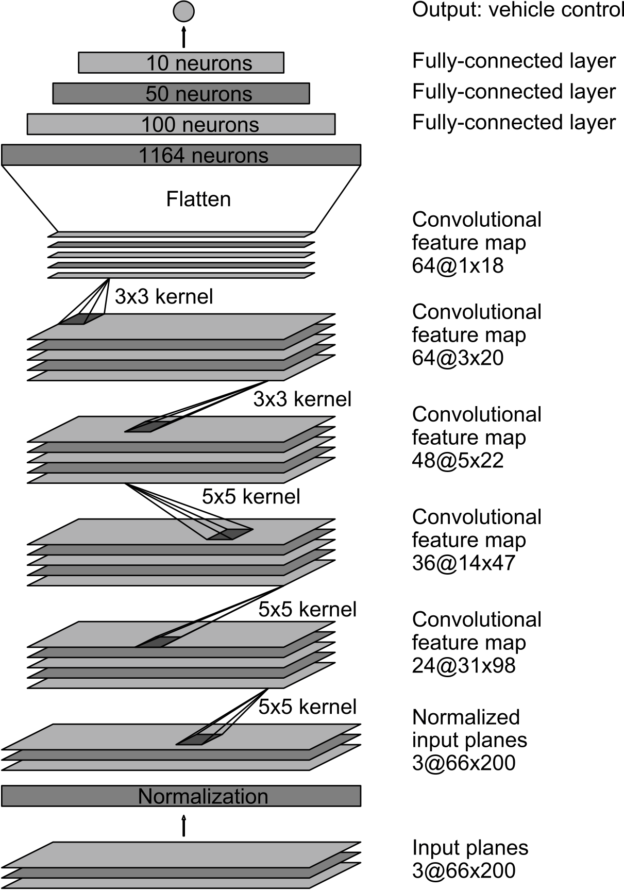
網絡的第一層執行圖像標準化。規范化器是硬編碼的,在學習過程中不會進行調整。在網絡中執行規范化允許標準化方案隨網絡架構改變,并通過 GPU 處理加速。
卷積層的設計是為了進行特征提取,并通過一系列不同層結構的實驗進行經驗選擇。然后,我們在前三個卷積層中使用跨步卷積,步長為 2 × 2 ,核為 5 × 5 ,最后兩個卷積層使用核大小為 3 × 3 的非跨步卷積。
我們跟隨五個卷積層和三個完全連接的層,得到最終的輸出控制值,即反向轉彎半徑。完全連接的層被設計成一個控制器來控制方向,但是我們注意到,通過端到端的訓練系統,不可能在網絡的哪些部分主要作為特征提取器,哪些部分作為控制器起作用。
培訓詳情
數據選擇
訓練 神經網絡 的第一步是選擇要使用的幀。我們收集的數據被標記為道路類型、天氣狀況和駕駛員的活動(停留在車道上、切換車道、轉彎等)。為了訓練 CNN 進行車道跟蹤,我們只需選擇駕駛員停留在車道上的數據,然后丟棄其余數據。然后,我們以 10 FPS 的速度對視頻進行采樣,因為更高的采樣率將包含高度相似的圖像,因此不會提供太多額外的有用信息。為了消除對直線行駛的偏見,訓練數據中包含了更高比例的表示道路曲線的幀。
增強
在選擇最后一組幀后,我們通過添加人工移動和旋轉來增加數據,以教網絡如何從不良位置或方向恢復。這些擾動的大小是從正態分布中隨機選取的。分布的平均值為零,標準差是我們用人類駕駛員測量的標準差的兩倍。隨著震級的增加,人為地增加數據確實會增加不需要的偽影(如前所述)。
仿真
在對經過訓練的 CNN 進行道路測試之前,我們首先在仿真中評估網絡的性能。圖 6 顯示了仿真系統的簡化框圖,圖 7 顯示了交互模式下模擬器的屏幕截圖。
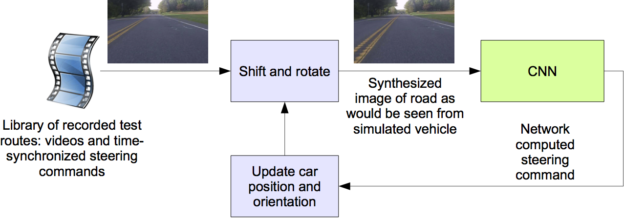
這個模擬器從一個連接到人類駕駛的數據采集車的前向車載攝像頭上獲取預先錄制的視頻,生成的圖像與 CNN 轉向車輛時的圖像大致相同。這些測試視頻與人類駕駛員生成的錄制的轉向指令時間同步。
由于人類駕駛員不是一直在車道中心行駛,我們必須手動校準車道中心,因為它與模擬器使用的視頻中的每個幀相關。我們稱這一立場為“基本事實”。
模擬器對原始圖像進行變換,以解釋與地面真實情況的偏差。請注意,這種轉換也包括了人類驅動的路徑和基本真相之間的任何差異。轉換是通過與前面描述的相同的方法完成的。
模擬器訪問錄制的測試視頻以及捕獲視頻時發生的同步轉向命令。模擬器將所選測試視頻的第一幀發送到經過訓練的 CNN 的輸入,該視頻根據地面真相的任何偏離進行調整,然后返回該幀的轉向命令。 CNN 轉向命令和記錄的人 – 駕駛員指令被輸入車輛的動態模型[7],以更新模擬車輛的位置和方向。

模擬器然后修改測試視頻中的下一幀,使圖像看起來像是車輛在遵循 CNN 的轉向命令而產生的位置。這個新的圖像然后被傳送到 CNN 并且這個過程重復。
模擬器記錄偏離中心的距離(從汽車到車道中心的距離)、偏航和虛擬汽車行駛的距離。當偏離中心距離超過 1 米時,將觸發虛擬人干預,并重置虛擬車輛的位置和方向,以匹配原始測試視頻對應幀的地面真實情況。
評價
我們通過兩個步驟來評估我們的網絡:首先在模擬中,然后在道路測試中。
在模擬中,我們的網絡在模擬器中提供了一組預先記錄的測試路線的指導命令,這些線路對應于新澤西州蒙茅斯縣大約 3 小時 100 英里的行駛。測試數據是在不同的照明和天氣條件下采集的,包括公路、當地道路和居民街。
我們通過計算模擬車輛偏離中心線超過 1 米時發生的模擬人類干預,來估計網絡能夠驅動汽車的時間百分比(自主)。我們假設,在現實生活中,實際干預總共需要 6 秒:這是人類重新控制車輛、重新居中,然后重新啟動自動轉向模式所需的時間。我們通過計算干預次數,乘以 6 秒,除以模擬測試的運行時間,然后從 1 減去結果來計算自主性百分比:
![\text{autonomy} = (1 - \frac{\text{\# of interventions} \cdot 6 \text{[seconds]}}{\text{elapsed time[seconds]}}) \cdot 100](https://s0.wp.com/latex.php?latex=%5Ctext%7Bautonomy%7D+%3D+%281+-+%5Cfrac%7B%5Ctext%7B%5C%23+of+interventions%7D+%5Ccdot+6+%5Ctext%7B%5Bseconds%5D%7D%7D%7B%5Ctext%7Belapsed+time%5Bseconds%5D%7D%7D%29+%5Ccdot+100&bg=ffffff&fg=000&s=0&c=20201002 "\text{autonomy} = (1 - \frac{\text{\# of interventions} \cdot 6 \text{[seconds]}}{\text{elapsed time[seconds]}}) \cdot 100")
因此,如果我們在 600 秒內進行 10 次干預,我們的自主性值將為
 \cdot 100 = 90\%")
道路試驗
經過訓練的網絡在模擬器中表現出良好的性能后,網絡被加載到我們的測試車的驅動器 PX 上,并被帶出進行道路測試。在這些測試中,我們用汽車自動轉向的時間來衡量性能。此時間不包括從一條道路到另一條道路的車道變更和轉彎。在新澤西州蒙茅斯縣,從我們在霍爾姆德爾的辦公室到大西洋高地的典型駕車旅行,我們大約 98% 的時間是自治的。我們還在花園州公園大道上行駛了 10 英里(一條有進出口匝道的多車道分車道高速公路),沒有攔截。
以下是我們的測試車在不同條件下駕駛的視頻。
CNN 內部狀態的可視化

圖 8 和圖 9 顯示了兩個不同示例輸入的前兩個要素地圖層的激活,即未鋪砌的道路和森林。對于未鋪筑的道路,特征地圖激活可以清楚地顯示道路的輪廓,而對于森林,特征地圖包含的大部分是噪音,即 CNN 在該圖像中找不到有用的信息。
這表明 CNN 學會了自己檢測有用的道路特征,即僅以人的轉向角作為訓練信號。例如,我們從來沒有明確訓練過它來檢測道路的輪廓。

結論
我們已經通過經驗證明, cnn 能夠學習車道和道路跟隨的整個任務,而無需手動分解為道路或車道標記檢測、語義抽象、路徑規劃和控制。從不到一百小時的駕駛中獲得的少量培訓數據就足以訓練汽車在不同的條件下運行,在高速公路、當地和居民道路上,在晴天、多云和下雨的條件下。 CNN 能夠從非常稀疏的訓練信號(單獨轉向)中學習有意義的道路特征。
例如,該系統學習如何檢測道路輪廓,而不需要在訓練過程中使用明確的標簽。
為了提高網絡的魯棒性,尋找驗證魯棒性的方法,提高網絡內部處理步驟的可視化程度,還需要做更多的工作。
有關詳細信息,請 看報紙 這篇博客文章是基于,和 如果您想了解更多信息,請與我們聯系 關于 NVIDIA 的自主汽車平臺!
參考
- Y 、 LeCun , B . Boser , J . S . Denker , D . Henderson , R . E . Howard , W . Hubbard 和 L . D . Jackel 。反投影算法在手寫郵政編碼識別中的應用。神經計算, 1 ( 4 ): 541-5511989 年冬天。網址: http :// yann . lecun . org / exdb / publis / pdf / lecun-89e . pdf 。
- Alex Krizhevsky , Ilya Sutskever 和 Geoffrey E . Hinton 。用深卷積神經網絡進行圖像網絡分類。在 F . Pereira , C . J . C . Burges , L . Bottou 和 K . Q . Weinberger ,《神經信息處理系統進展》 25 ,第 1097-1105 頁。 Curran Associates , Inc ., 2012 年。網址: http :// papers . nips . cc / paper / 4824 用深卷積神經網絡進行圖像網絡分類。 pdf 格式。
- 五十、 D .杰克爾、 D .沙曼、斯坦納德· C · E 、斯特羅姆· B · I 和 D ·扎克特。自助銀行的光學字符識別。 AT & T 技術期刊, 74 ( 1 ): 16-241995 。
- 大規模視覺識別挑戰賽( ILSVRC )。網址: http :// www . image-net . org /挑戰/ LSVRC /。
- Net Scale Technologies , Inc .使用端到端學習的自主越野車輛控制, 2004 年 7 月。最終技術報告。網址: http :// net-scale . com / doc / net-scale-dave-report . pdf 。
- 波默勞院長。阿爾文,一種神經網絡中的自動陸地車輛。技術報告,卡內基梅隆大學, 1989 年。網址: http :// repository . cmu . edu / cgi / viewcontent 。 cgi ?文章= 2874 & context = compsci 。
- 王丹薇和馮琦。四輪轉向車輛的軌跡規劃。 2001 年 IEEE 機器人與自動化國際會議記錄, 2001 年 5 月 21-26 日。網址: http :// www . ntu . edu . sg / home / edwwang / confpapers / wdwicar01 . pdf 。
?







