導讀:本文將介紹如何在GPU上高效地部署語音AI模型,主要內容如下:
- 語音AI部署背景介紹
- 基于GPU的ASR解決方案介紹
- 基于Triton的ASR部署方案
- 基于GPU的ASR decoding
- NST訓練方法優化
- 基于Tensor-LLM的Whisper模型加速推理
- 基于GPU的TTS解決方案介紹
- 基于FastPitch+Hifi-GAN的Streaming TTS 效果優化
- 關于聲音克隆的參考工作
- 未來規劃
▌語音AI部署背景介紹
首先介紹下搭建語音識別和語音生成類工作管線的痛點與挑戰。

首先,AI模型的部署,有端上和云上兩種不同的方式。在云上部署時,常常面對服務延時高、并發路數低、部署成本高等問題。我們希望通過更有效地利用 GPU 資源,服務更多的用戶,同時降低部署成本。
第二,語音 AI 與傳統的 CV 算法不同,其工作管線更為復雜,通常包含多個模塊,并且需要處理流之間的狀態維護、管理以及狀態切換。這使得開發難度大,有時簡單的 Python 腳本調度并不高效。
第三,當前許多從事語音 AI 服務的實踐者開始探索使用大型模型,如Whisper,來完成語音識別和語音模型的任務。然而,使用大型模型帶來了更大的計算需求,因此迫切需要提升大語言模型在 ASR、TTS領域中的推理效率。
▌基于GPU的ASR解決方案介紹
- 基于Triton的ASR部署方案
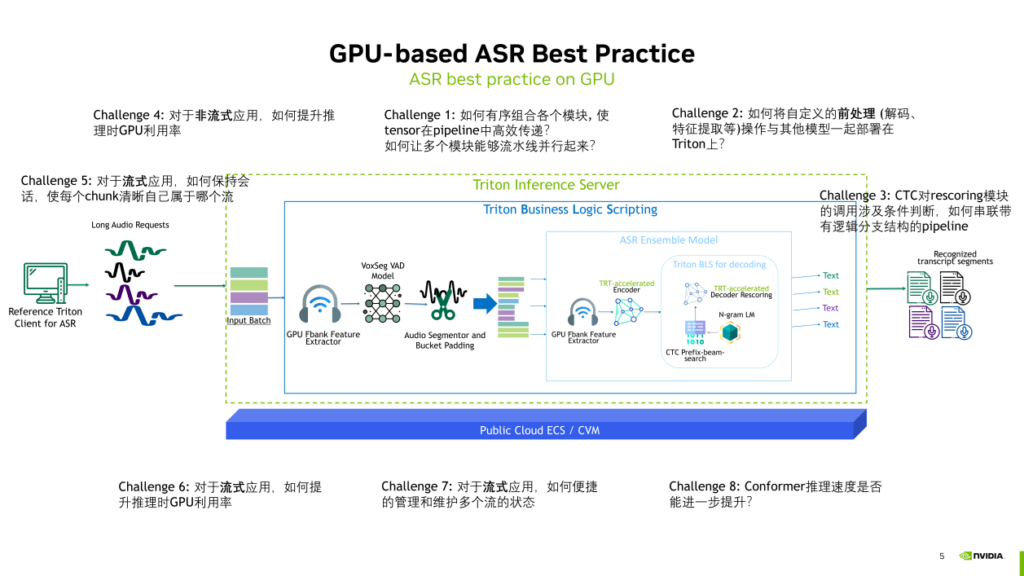
過去一年中,NVIDIA與WeNet社區緊密合作,利用Triton Inference Server這一推理服務的部署框架,構建了在GPU上部署WeNet模型的工作管線。在WeNet的架構下,進行了基本的音頻特征提取(Fbank特征),并采用了U2++或Conformer的編碼器來處理音頻信號。解碼的方式有很多選擇,我們通過CTC的prefix Beam search和Transformer 或者 Conformer 的 decoder 一起完成(類似于U2++解碼)。
整體來講,通過TensorRT加速模型推理,同時通過Triton部署整個管線。
在利用Triton部署整個WeNet管線的過程中,解決了如下一些問題:
- Challenge1:如何有序組合各個模塊, 使 tensor在pipeline中高效傳遞? 如何讓多個模塊能夠流水線并行起來?
在使用Triton時,它不僅能夠有序組合多個模塊,還允許用戶外接更多所需的模塊。例如,通過Triton的 business logic scripting功能,可以添加VAD模塊或者進行音頻切分,并將其與ASR模塊連接起來。這樣的流程串接都可以在Triton中實現,并且各個部分可以并行進行,實現高效的流水線運行。
- Challenge2:如何將自定義的前處理(解碼、特征提取等)操作與其他模型一起部署在Triton上?
Triton不僅能夠部署深度學習模型,還支持許多自定義操作,包括Python和C++的自定義前后處理。這些操作可以與深度學習模型對接,這也是Triton提供的custom backend功能。因此,NVIDIA的custom backend可以與deep learning、framework backend共同部署,并實現它們之間的橋接。
- Challenge3:CTC對rescoring模塊的調用涉及條件判斷,如何串聯帶有邏輯分支結構的pipeline?
在部署前后處理中,尤其是在解碼模塊,我們經常需要進行條件判斷等邏輯操作。這些邏輯操作可以用 Python 的business logic scripting 去實現,從而建立帶有邏輯分支結構的工作關系。
- Challenge4:對于非流式應用,如何提升推理時GPU利用率?
對于非流式應用,Triton提供了動態批處理和多模型實例并行執行等功能。這些功能可以在將ASR服務部署在GPU上時,最大化GPU的利用率,提升整個服務的吞吐。
- Challenge5:對于流式應用,如何保持會話,使每個chunk清晰自己屬于哪個流?
對于流式應用,Triton內置了流式狀態管理器,能夠有序地管理整個流式推理過程。每個流中的每個chunk都能清晰地知道自己屬于哪個流,狀態管理器在狀態發生切換時能夠自動地管理這個過程。最終,在推理完成后,客戶端也能明確地了解每個chunk的識別結果屬于最初輸入的哪個流。這種有序的管理確保了流式應用中音頻的輸入輸出流程的清晰性。
- Challenge6:對于流式應用,如何提升推理時GPU利用率?
針對流式應用,我們致力于提升GPU利用率。通過動態批處理,能夠有效推理多個流中的多個chunk,使GPU以批處理方式高效運行,從而最大程度地提升GPU資源利用率。
- Challenge7:對于流式應用,如何便捷地管理和維護多個流的狀態?
在流式應用方面,NVDIA提供了便捷的流狀態管理功能。這包括對多個流的狀態進行有效管理和維護,確保整個流式應用的狀態處理更加高效和便捷。
- Challenge8:Conformer推理速度是否能進一步提升?
對于類似Conformer和Transformer這樣的模型,我們不斷探索加速方法,主要集中在TensorRT這一加速框架。通過TensorRT對模型本身的推理速度進行優化,有效提高整個服務的效率。
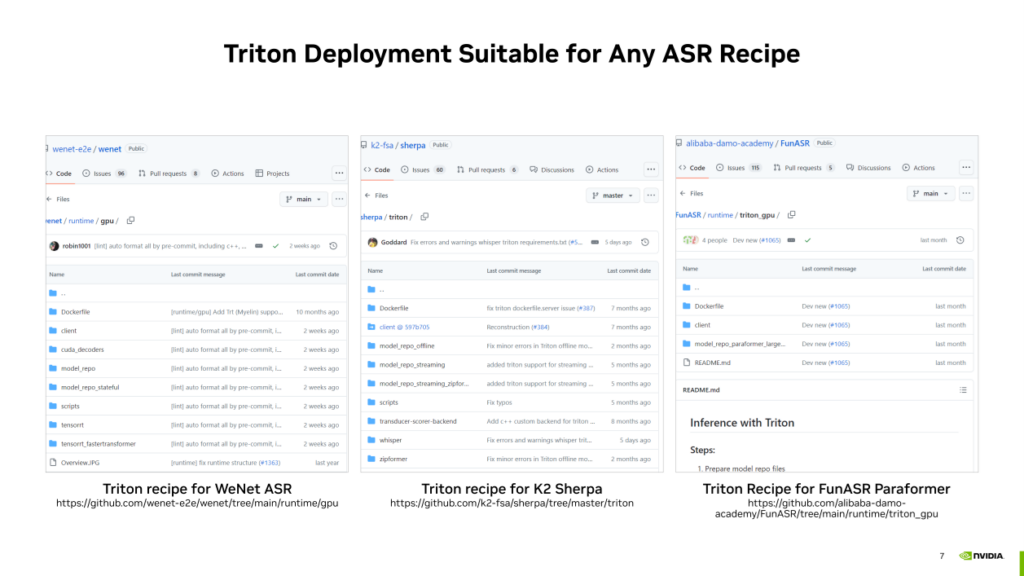
基于Triton的ASR部署方案實際上可以擴展到更通用的ASR工作管線,并不局限于WeNet的模型和管線。我們利用Triton,可以在很多其他的開源ASR方案架構下盡可能的提升ASR服務的吞吐。例如,以下是NVIDIA對除WeNet之外其他一些開源ASR項目貢獻的Triton部署方案,如果感興趣可以通過下方鏈接了解。
- 基于GPU的ASR的decoding

接下來介紹在解碼方面的加速優化工作,主要包括兩個方面。
- 對于CTC prefix Beam search的CUDA加速實現
之前,CTC prefix beam search主要在CPU上運行,而深度學習模型(如Conformer、Transformer、Zip Former)通常在GPU上運行。這導致深度學習模型和CTC解碼的prefix beam search在GPU和CPU上分別運行,可能產生一些CPU到GPU之間的拷貝開銷。為解決這個問題,我們通過CUDA實現了CTC prefix beam search,將解碼循環包含在一個GPU的kernel中,并實現了beam search的查找。
這個方案速度非常快,相較于Touch Audio中的Flashlight decoder在CPU上的版本,我們的CUDA decoder的速度提升了十倍以上,而且精度相比于Flashlight decoder也更好。如果感興趣,可以通過Torch Audio直接嘗試。但值得注意的是,CTC目前還不支持熱詞和語言模型,它只是一個單純的prefix beam search,這一局限性可能會影響在生產環境中的應用。
- 基于CUDA的TLG解碼
因為以上問題,我們還提供了另一種解碼實現,基于CUDA的TLG解碼。TLG解碼在包括Kaldi在內的很多ASR系統上應用廣泛。TLG解碼的速度相較于CTC加上一些blank skip的手段后,可能沒有太明顯的優勢。但CUDA的TLG使得深度學習模型和解碼全鏈路都在GPU上運行,避免了CPU到GPU之間的內存復制開銷。有時CPU的壓力也很大,因為CPU可能會運行其他前后處理操作,因此使用CUDA基礎的TLG解碼可以緩解CPU上的壓力。TLG解碼的優勢在于精度相比CTC更好,雖然速度可能稍慢一些,因此可以根據需要選擇是否使用基于CUDA的TLG解碼。如果想嘗試,可以在WeNet的開源方案中找到相關信息。
- NST訓練方法優化
在算法方面,我們聚焦于半監督的ASR訓練,采用了NST方法。

首先介紹一下NST的訓練過程:先使用有監督數據訓練teacher模型,然后使用該模型在無監督數據上運行,生成偽標簽。通過篩選,選擇有用或合理的帶有偽標簽的數據,與有監督數據一起訓練student模型。訓練完成后,student模型成為新的teacher模型,進行反復迭代。這種方式充分利用了有監督和無監督數據,得到了我們需要的ASR模型。
然而,NST方法面臨的一個主要挑戰就是噪聲。如果有監督和無監督數據集的Domain相似,該方法產生的模型精度是可靠的。但如果Domain之間存在較大差異,模型在某些領域上表現較差。為了解決領域差異問題,我們提出了一種語言模型篩選的方法。
該方法的核心思想是我們通過大量實驗發現CER Hypo (帶目標domain語言模型的解碼識別結果與不帶語言模型解碼方式識別的結果之間的CER) 與CER Label (帶目標domain語言模型的解碼識別結果與無標注數據的真實標簽之間的CER)總是呈正相關性的,一般前者高后者也會較高,前者低后者也會較低。由于我們實際上并沒有無標注數據的真實標簽,因此我們可以用前者的大小來估計后者,從而判斷teacher模型生成的偽標簽是否可靠。
這樣一來,我們可以為CER Hypo一個閾值,據此來篩選無監督數據,剔除那些CER Hypo較高(也意味著CER Label較高)的數據。經過這一篩選過程,使用剩下的數據進行學生模型的訓練,以提高在無監督數據集上的模型精度。
在實驗中,我們觀察到使用LM filter后,CER在不同數據集上都有顯著下降,分別為11.13% (AIshell1有標注數據+WenetSpeech無標注數據)和15.86% (AIShell2有標注數據+WenetSpeech無標注數據)。這表明LM filter對于降低無監督數據中的噪聲、提高模型性能起到了積極的作用。
- 基于Tensor-LLM的Whisper模型加速推理
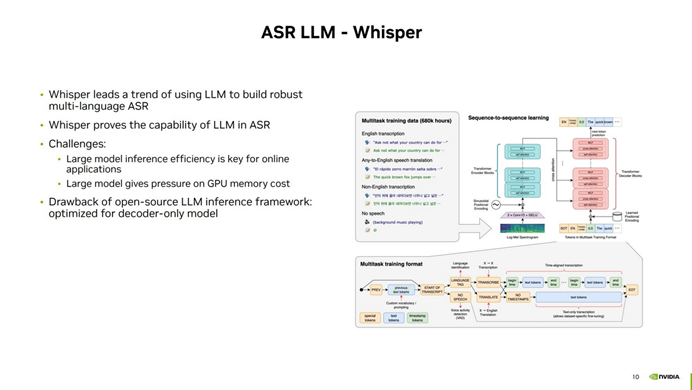
第四方面的工作是關于ASR 大模型的推理加速,其中 Whisper 模型在多語種 ASR 領域取得了顯著進展。盡管 Encoder-Decoder 算法在很久以前就存在,但是 Whisper 模型證明了大語言模型在 ASR 領域的強大能力,能夠使用單一模型準確預測多種不同語言的 ASR 任務。然而,使用 Whisper 進行 ASR 推理面臨一些挑戰,主要包括模型的大小帶來的推理速度下降和對 GPU 顯存的大量消耗。
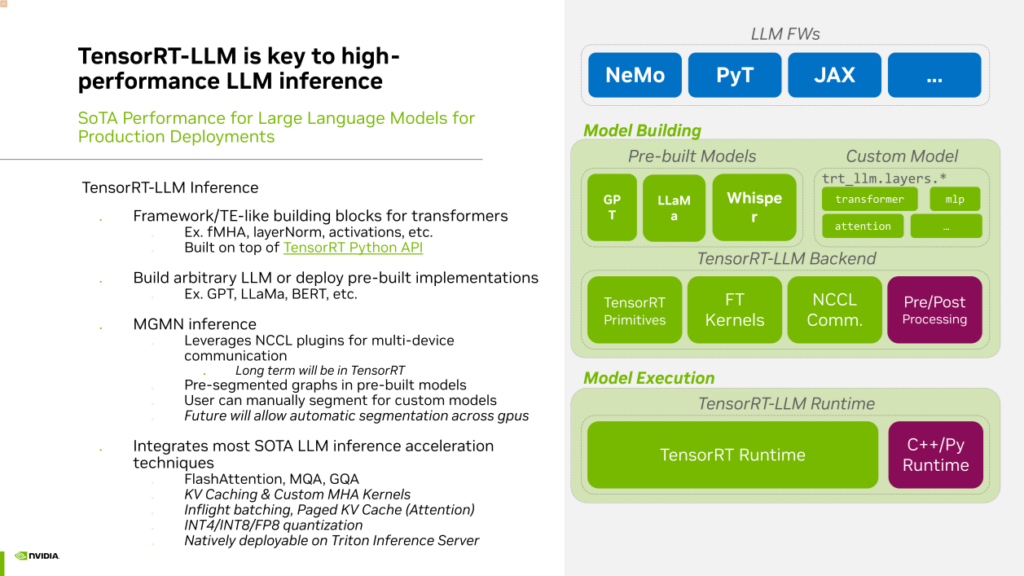
為了盡可能加速大語言模型的推理,解決當前使用現有框架進行 Whisper 推理可能會遇到的問題,在今年十月,NVIDIA推出了大語言模型推理加速框架,名為TensorRT-LLM(TensorRT Large Language Model)。TensorRT-LLM 是建立在TensorRT基礎上的,專門用于加速大語言模型推理的開源框架。使用TensorRT-LLM 進行推理,可以利用其中提供的各種layer或OP的 API 來構建自己的網絡結構。
在TensorRT-LLM中,我們提供了許多預先構建的模型示例,包括GPT、LLAMA、百川、chatGLM等主流模型。當然,TensorRT-LLM也天然地支持Whisper。TensorRT-LLM用于大型語言模型的推理,具有多項優勢,有助于提高效率。如果需要進行多機多卡推理,TensorRT-LLM具有內置的通信組件,支持Tensor并行和流水線并行。
此外,我們還整合了社區中幾乎所有的大型語言模型推理加速技術,如Flash Attention、MQH、GQA、KV Cache,以及用于服務端優化的Inflight Batching (Continuous Batching)和Paged Attention等。還采用低精度量化技術,如INT4、INT8、FP8,以提高推理速度。
最后,TensorRT-LLM是原生支持與Triton Inference Server結合使用的,通過TensorRT-LLM加速的大型語言模型,可以輕松在Triton上進行服務部署。這是NVIDIA提出的一種非常實用且目前性能最先進的大型模型推理框架。

在TensorRT-LLM中,我們利用了一些特性來提升Whisper模型的推理速度。
首先是對Whisper的encoder & decoder的GPU kernel進行了優化。利用TensorRT-LLM中的Fused MHA kernel,應用Flash Attention的優化技術,加速處理輸入是一個長序列的多頭注意力推理速度。在解碼器生成token的過程中,利用Masked Multi-Head Attention(MHA)的高性能GPU kernel,用于處理解碼過程中的Q等于1,而KV相對較長的情況。除了多頭注意力之外,還針對推理過程中的一些矩陣運算、Layernorm等操作,專門實現了高性能的GPU kernel,以替代PyTorch中相對低效的原生kernel。此外,我們對op與op之間,layer和layer之間進行了一些融合操作,以提高運行效率。
其次,是對大語言模型推理中KV Cache的優化。在Whisper中,有兩種類型的Key / Value緩存由TensorRT-LLM管理。第一種是self attention的緩存,它在解碼器迭代生成token的過程中持續生成。第二種是cross attention的key和value,在編碼器完成后,通過幾個線性層獲取cross attention的key和value的緩存,這也被緩存以用于后續的每個token生成。
此外,TensorRT-LLM還支持對Whisper進行INT 8的量化。它將權重量化到INT 8的精度,但計算時仍然使用FP 16。這種做法的優勢包括節省顯存和減少weight從顯存復制到寄存器的IO開銷。
這些優化使得Whisper在V100上的推理速度比Faster Whisper提高了近40%,同時保持更低的識別錯誤率。TensorRT-LLM還支持批量推斷,而Faster Whisper不支持。
這些優勢使得TensorRT-LLM成為Whisper推理的高效框架,而且我們還在逐步實現其他一些功能,包括Inflight batching、Paged attention和Speculative decoding等等。

使用TensorRT-LLM加速Whisper,步驟如下:
首先,需要一個經過訓練的Whisper模型,然后使用TensorRT進行模型初始化。由于Whisper是在TensorRT中原生支持的,所以只需運行初始化步驟,讀取權重并構建網絡即可。對于不是原生支持的模型,需要使用Python API重新構建模型,但Whisper不需要。
完成初始化后,進入第二步,即engine building過程,這是一個編譯的過程,根據Whisper網絡結構為每個操作和每個層找到最高效的kernel實現,并進行一些kernel fusion或layer fusion的優化操作。
最終得到TensorRT-LLM的Whisper engine后,可以使用TRT-LLM提供的C++或Python運行,或直接部署到Triton Inference Server上運行。這個流程相對簡單。如果在生產中使用Whisper模型,建議使用TensorRT-LLM進行高性能加速,可顯著提升Whisper推理速度并節省成本。
▌基于GPU的TTS解決方案介紹
- 基于FastPitch+Hifi-GAN的Streaming TTS 效果優化
NVIDIA在 TTS 領域也做了一些供大家參考的工作,例如提供了高效的流式 TTS 部署方案,利用 TensorRT 加速模型推理速度,并通過 Triton Inference Server 實現了高效的流水線。今年,我們對流式 TTS 的效果進行了提升,主要集中在兩個方面。
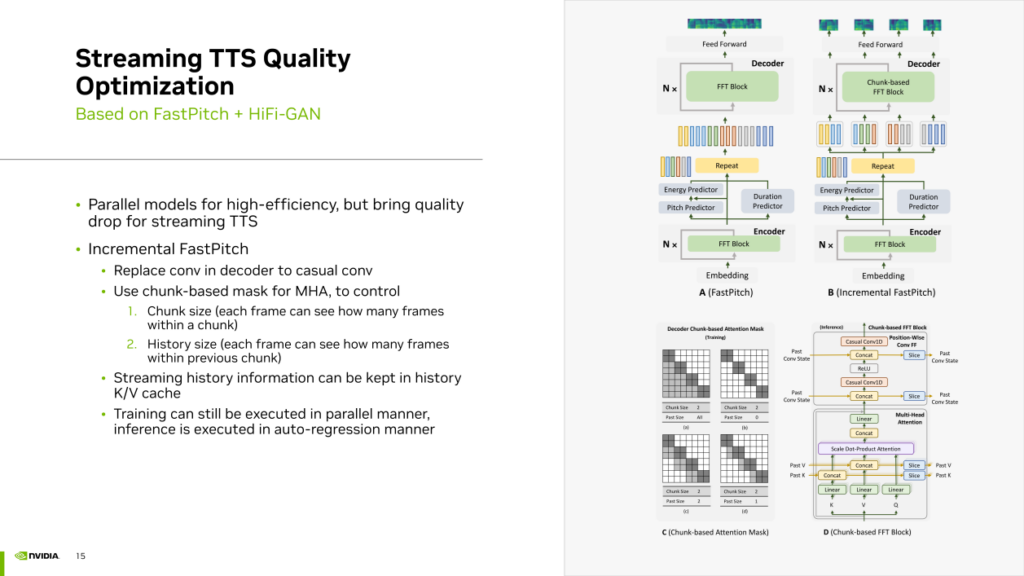
首先,我們發現許多 TTS 模型采用并行模型,其結構通常是非自回歸的,并使用卷積等網絡層一次性生成所有音頻幀。然而,這種并行模型并不適合流式 TTS 合成。尤其在 chunk 之間的接縫處可能存在抖動瑕疵。因此,我們引入了一種Incremental FastPitch的方法,將完全并行的 FastPitch 轉換為基于 chunk 的 FastPitch。通過使用casual卷積替代常規普通卷積,并采用基于 chunk 的mask MultiHeadAttention,可以控制 chunk size 和 history size。這種Mask使得每個 chunk 內的幀不僅可以看到chunk內的其他真,還能夠看到之前chunk的幀,通過這種方式實現了基于 chunk 的 FastPitch并且使得chunk之間的信息可以互相關聯提升流式TTS的質量。Incremental FastPitch的訓練過程仍然可以利用帶mask的注意力機制來實現并行運算。在推理過程中,可以逐個 chunk 地生成,實現類似迭代的自回歸生成過程,從而在流式生成中考慮到歷史信息,提升生成效果。
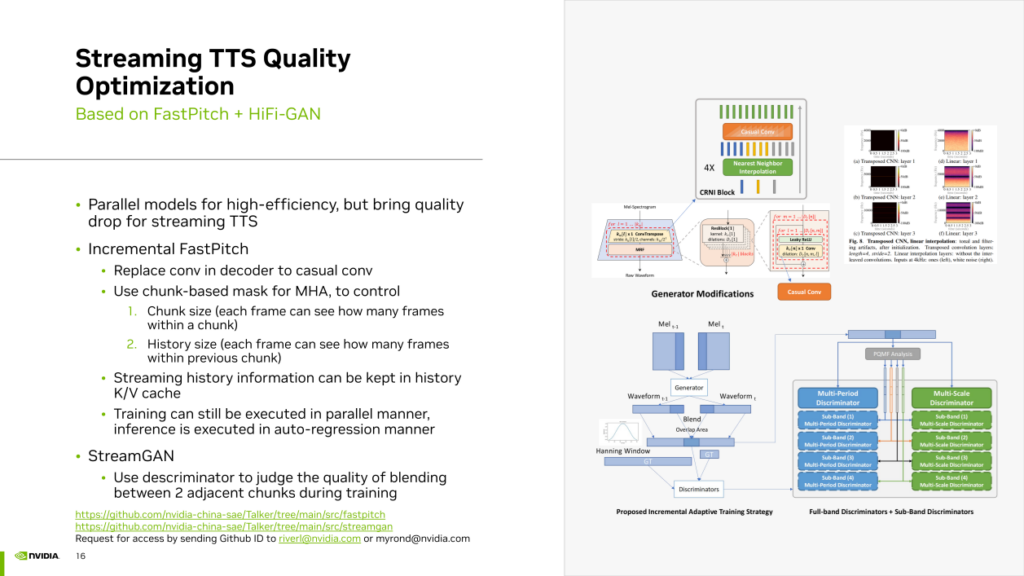
其次,我們采用了 stream GAN 邏輯,即在 Hifi GAN 的訓練中,利用 discriminator 強制學習如何讓Generator生成兩個能夠良好拼接的連續音頻 chunk。
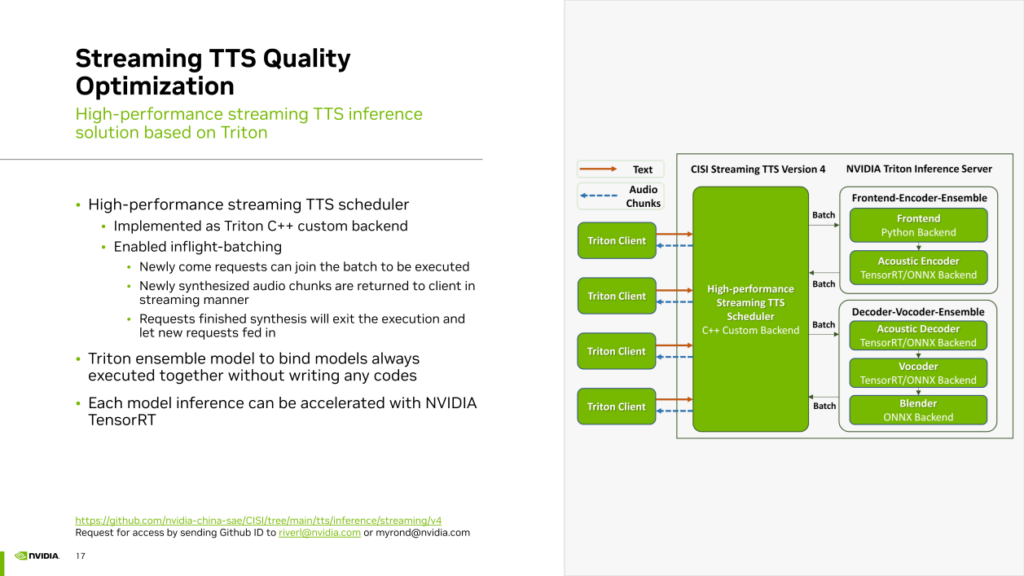
基于先前提到的兩種流式 TTS 優化方案,我們開發了相應的推理服務框架,同樣基于 Triton Inference Server 加上 TensorRT。
在這個框架中,使用 Triton 的 C++ custom backend實現了高性能的 TTS 調度器。該調度器負責組織整個 TTS 管線的各個模塊,并在這個過程中實現了“Inflight batching”,即連續批處理。新進來的請求可以隨時加入到正在執行的batch中。新合成的音頻 chunk 會以流式方式返回給 Triton Client。已完成的請求會立即終止,為新到達的請求騰出slot。
此外,我們使用 Triton 的 Ensemble Model 功能以零代碼的方式組合了需要同時運行的多個模塊,如Front End、聲學模型的編碼器總是要對輸入的文本共同做一次處理。我們使用 Triton Ensemble 將它們無縫組合在一起,而無需編寫任何串聯代碼,實現了零代碼的模型串聯功能。對于聲學模型的解碼器、vocoder以及最后的 Chunk 拼接的 Blender,同樣使用 Triton ensemble 功能以零代碼的方式將它們組合在一起。最后,對于每個模型,包括聲學模型的encoder和vocoder,都使用 TensorRT 來加速推理。
- 關于聲音克隆的參考工作
關于聲音克隆的工作
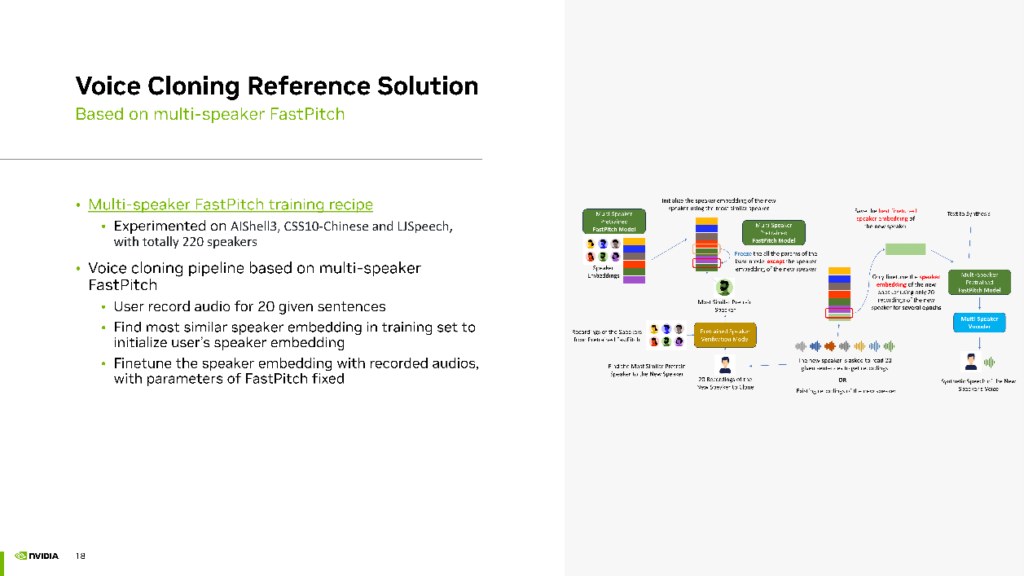
首先,我們開發了一個 Multi-speaker FastPitch 的訓練方案,并在開源項目中提供了這個解決方案。在我們的實驗中,混合了三個開源數據集(AIShell 3、CSS 10 Chinese、LJSpeech),共計 220 個Speaker,進行了訓練。
獲得了多說話人的FastPitch模型后,則可進入聲音克隆的Finetuning階段。用戶首先錄制 20 句話。接著,根據用戶的聲音在訓練集中找到一個與之最相似的Speaker,用其聲音的embedding初始化用戶的Speaker Embedding。然后,使用用戶上傳的 20 句話進 finetuning,保持 FastPitch 不變,但 finetuning Speaker的Embedding。最終,該模型使用 Multi-speaker FastPitch 生成與用戶聲音相似的音頻效果。
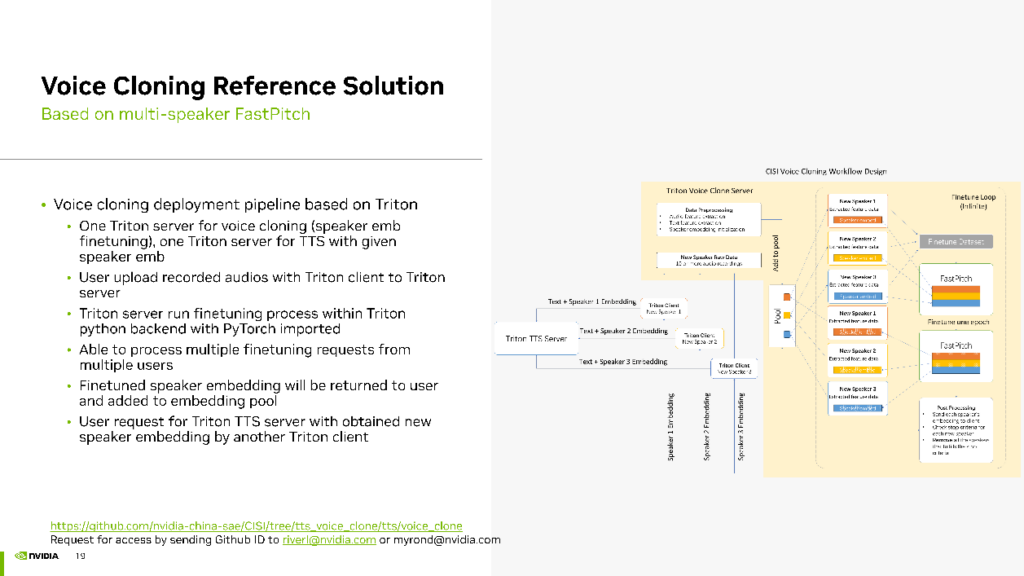
為了實現這一思路的工程化,我們同樣采用 Triton Inference Server 進行部署。在此我們配置了兩個 Triton Server,一個用于聲音克隆,另一個用于 TTS 生成。用戶錄制的 20 句話可以通過 Triton 的客戶端上傳到聲音克隆 Triton Server。在聲音克隆 Triton Server 上,運行聲音克隆的 finetuning 過程,使用 Triton 的 Python backend,在其中引用PyTorch包來 實現finetuning 流程。在這個管線中,能夠同時處理多個用戶的請求,以 batch 的方式進行finetuning提高 GPU 利用率和并發效率。
最后,將每個Speaker的Embedding返回給客戶端,并將 finetuning 完成的Speaker Embedding存儲在Embedding Pool中。用戶想要生成自己的聲音只需獲取返回的Speaker Embedding,并訪問我們的 Triton TTS Server,即我們部署的 Multi-speaker TTS 模型。該模型使用 fine-tuning 完成的Speaker Embedding生成與用戶聲音相似的音頻。這就是我們的聲音克隆工作的流程。
▌未來規劃

最后分享一下我們對未來工作的規劃。
- ASR方面
首先,不斷優化Whisper的推理,利用新的一些技術實現加速;使用TensorRT-LLM + Triton作為Whisper部署方案;提供更多的Whisper finetuning方案。
另外,我們正在做的一項工作是code-switched AST訓練方案。之前在NeMo中已經實現了基于字符的方法,現在正在嘗試基于拼音的東亞語言的方案。
- TTS方面
首先是提供針對其他SOTA模型的加速方案;
第二是提供多語種的TTS方案;
第三是基于LLM的TTS方案。
以上就是本次分享的內容,謝謝大家。