如今,針對 TensorFlow 、 ONNX 、 PyTorch 、 Keras 、 MXNet 等不同框架,出現了大量最先進( SOTA )模型和建模解決方案的實現。如果您對數據集中已有的類別感興趣,可以使用這些模型進行開箱即用的推斷,也可以通過微調將其嵌入到定制業務場景中。
本文概述了流行的 DL 模型類別,并介紹了使用 NVIDIA Triton Inference Server 部署這些模型的端到端示例。客戶端應用程序可以按原樣使用,也可以根據用例場景進行修改。我將帶領您使用 Triton 推理服務器完成圖像分類、對象檢測和圖像分割公共模型的部署。本文中概述的步驟也可以應用于其他開源模型,只需稍作修改。
深度學習推理挑戰
近年來,深度學習( DL )取得了顯著進步。通過解決多年來困擾人工智能界的眾多復雜問題,它徹底改變了人工智能的未來。目前,它正被用于醫療保健、航空航天工程、自動駕駛和用戶認證等不同行業的快速增長的應用。
然而,深度學習在推理方面面臨各種挑戰:
- 支持多個框架
- 易于使用
- 部署成本
支持多個框架
第一個關鍵挑戰是支持多種不同類型的模型框架。
今天,開發人員和數據科學家正在為他們的生產模型使用各種框架。例如,如果機器學習項目是用 Keras 編寫的,那么修改系統進行測試和部署可能會遇到困難,但團隊成員對 TensorFlow 有更多的經驗。
此外,轉換模型可能是昂貴和復雜的,特別是如果需要新的數據進行訓練。他們必須有一個服務器應用程序來支持這些模型中的每一個。
易于使用
下一個關鍵挑戰是要有一個能夠支持不同推理查詢和用例的服務應用程序。
在某些應用程序中,您專注于實時在線推理,其中的優先級是盡可能減少延遲。另一方面,可能有一些用例需要您進行離線批處理推斷,因為您專注于最大化吞吐量。
必須有能夠支持每種類型的查詢和用例并為其進行優化的解決方案。
部署成本
下一個挑戰是管理部署成本和降低推理成本。
其中的一個關鍵部分是有一個服務應用程序可以支持在混合基礎架構上運行。您可以創建一個單獨的服務解決方案,用于在 CPU 上運行,另一個用于 GPU ,另一種用于在數據中心和邊緣的云上部署。這將導致成本飆升,并導致無法擴展的實現。
Triton 推理服務器
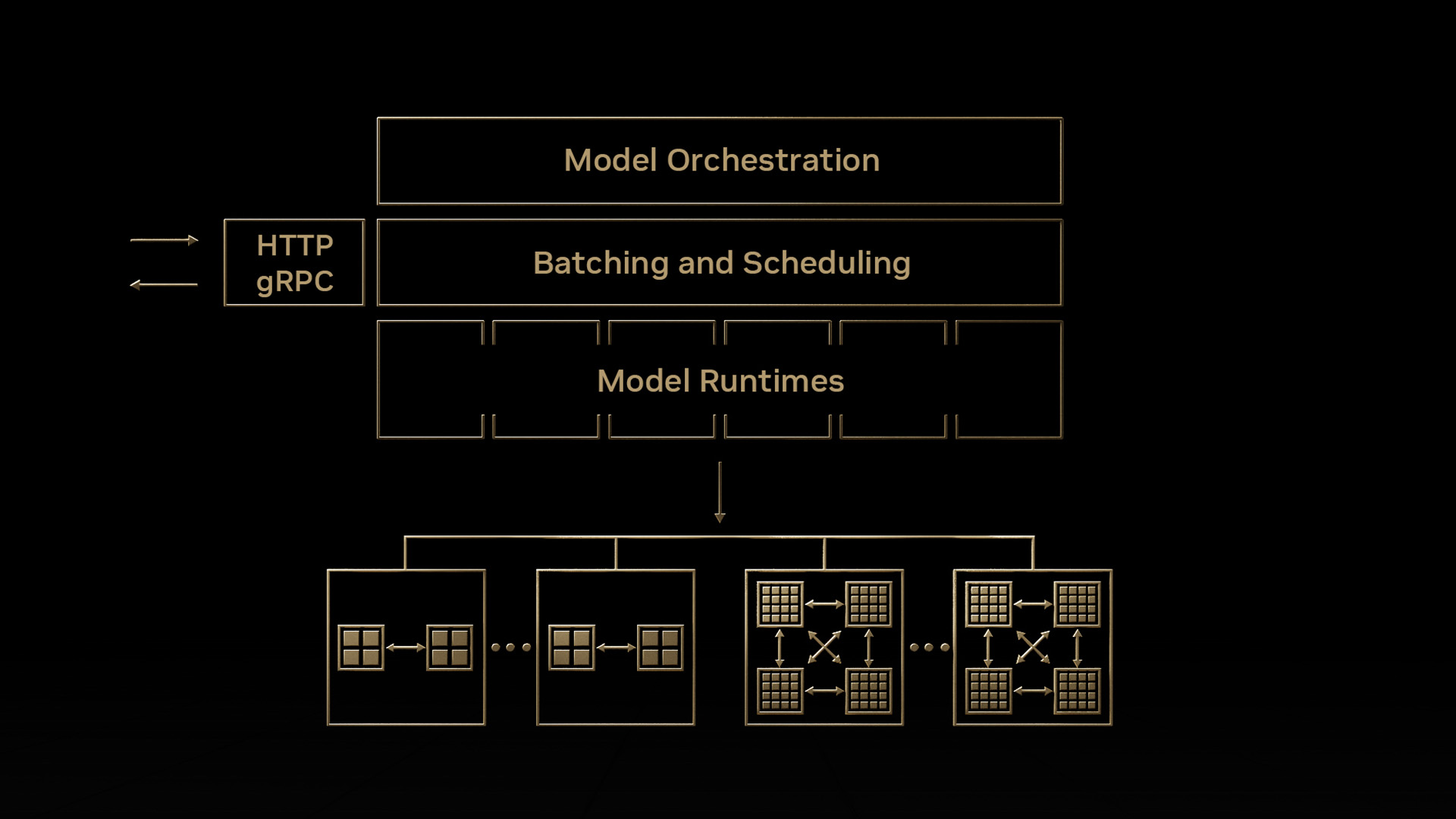
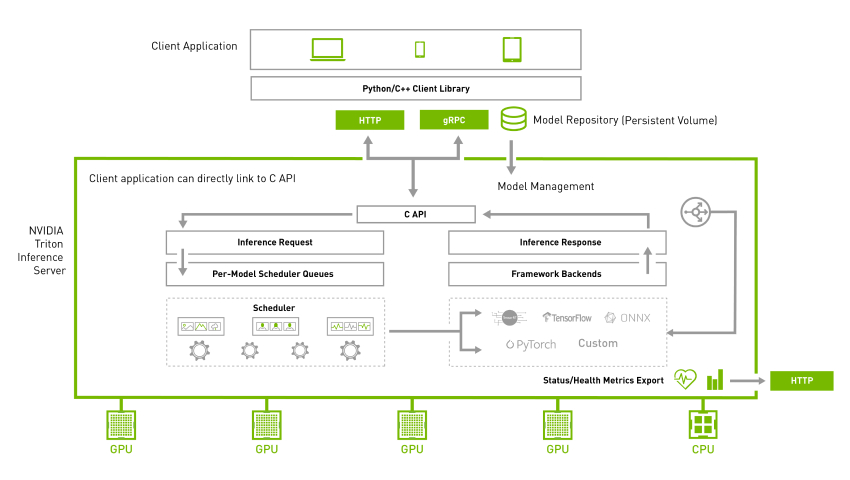
Triton 推理服務器是一個開源服務器推理應用程序,允許在不同環境中對 CPU 和 GPU 進行推理。它支持各種后端,包括 TensorRT 、 PyTorch 、 TensorFlow 、 ONNX 和 Python 。為了獲得最大的硬件利用率, NVIDIA Triton 允許不同型號的并行執行。進一步的動態批處理允許將推理查詢分組在一起,以最大化不同類型查詢的吞吐量。有關詳細信息,請參見 NVIDIA Triton Inference Server 。
使用 NVIDIA Triton 快速啟動
安裝和運行 NVIDIA Triton 的最簡單方法是使用 NGC 提供的預構建 Docker 映像。
服務器:拉取 Docker 鏡像
使用以下命令拉動圖像:
$ docker pull nvcr.io/nvidia/tritonserver:<xx.yy>-py3NVIDIA Triton 通過使用 GPU 進行了優化,以提供最佳的推理性能,但它也可以在僅 CPU 的系統上工作。在這兩種情況下,您都可以使用相同的 Docker 映像。
使用以下命令在您剛剛創建的示例模型存儲庫中運行 NVIDIA Triton :
docker run --gpus=1 --rm --net=host -v /path/to/the/repo/server/models:/models nvcr.io/nvidia/tritonserver:<xx.yy>-py3 tritonserver --model-repository=/models --exit-on-error=false --repository-poll-secs=10 --model-control-mode="poll"客戶端:獲取客戶端庫
使用 docker pull 獲取客戶端庫。
$ docker pull nvcr.io/nvidia/tritonserver:<xx.yy>-py3-sdk在此命令中,<xx.yy>是要拉取的版本。運行客戶端映像。
要啟動客戶端,請運行以下命令:
$ docker run -it --rm --net=host /path/to/the/repo/client/:/python_examples nvcr.io/nvidia/tritonserver:<xx.yy>-py3-sdk端到端模型部署
NVIDIA Triton 項目提供了 C ++和 Python 中的幾個客戶端庫,以簡化通信。這些 API 使與 NVIDIA Triton 的通信變得容易。在這些 API 的幫助下,客戶端應用程序處理輸入并與 NVIDIA Triton 通信以執行推理。
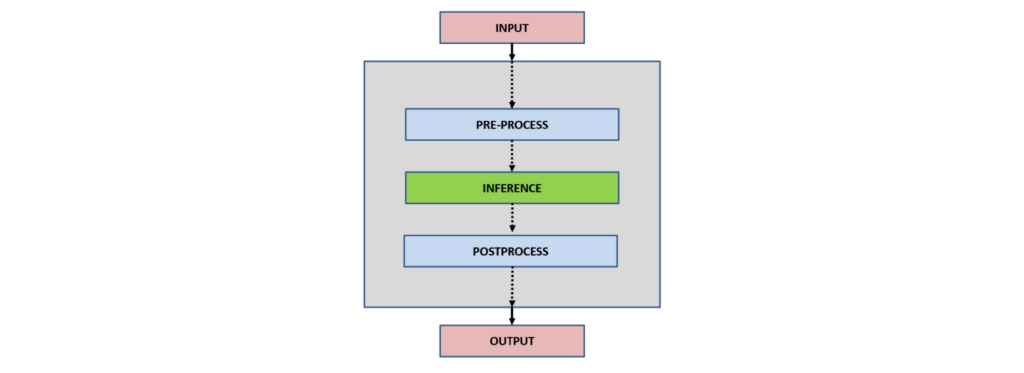
一般來說,客戶端應用程序與 NVIDIA Triton 的交互可以總結如下:
- 輸入
- 預處理
- 推論
- 后期處理
- 輸出
輸入: 根據應用類型,讀取一個或多個輸入以由神經網絡推斷。
預處理?:預處理數據是深度學習工作流中常見的第一步,以網絡可以接受的格式準備原始數據,例如,調整圖像大小、標準化或從輸入數據中去除噪聲。
推理?:對于推理部分,客戶端最初將推理請求序列化為消息,并將其發送到 Triton 推理服務器。消息通過網絡從客戶端傳輸到服務器,并被反序列化。請求被放置在隊列中。請求將從隊列中刪除并計算。完成的請求在消息中序列化并發送回客戶端。消息通過網絡從服務器傳輸到客戶端。消息到達客戶端并被反序列化。
后處理: 當消息到達客戶端應用程序時,它被處理為完成的推斷請求。根據網絡類型和應用程序用例,應用后處理。例如,在對象檢測中,后處理包括抑制多余的框,幫助選擇最佳可能的框,并將它們映射回輸入圖像。
輸出: 在推斷和處理之后,根據應用程序,輸出可以被存儲、顯示或傳遞到網絡。
圖像分類
Image classification 是理解整個圖像并為圖像指定特定標簽的任務。通常在圖像分類中,圖像中存在單個對象,并對其進行分析和理解。有關詳細信息,請參見 image classification 。
服務器:下載模型
從 ONNX 模型動物園下載 ResNet-18 圖像分類模型:
$ cd /path/to/the/repo/server/models/classification/1
$ wget https://github.com/onnx/models/raw/main/vision/classification/resnet/model/resnet18-v1-7.onnx && mv resnet18-v1-7.onnx model.onnx以下代碼示例顯示了模型配置文件:
name: "classification"
platform: "onnxruntime_onnx"
max_batch_size : 1
input [
{
name: "data"
data_type: TYPE_FP32
format: FORMAT_NCHW
dims: [ 3, 224, 224 ]
reshape { shape: [ 3, 224, 224 ] }
}
]
output [
{
name: "resnetv15_dense0_fwd"
data_type: TYPE_FP32
dims: [ 1000 ]
reshape { shape: [1000] }
label_filename: "labels.txt"
}
]名稱、平臺和后端
name屬性是可選的。如果未在配置中指定模型的名稱,則假定該名稱與包含該模型的模型存儲庫目錄相同。該模型由 NVIDIA Triton 后端執行,它只是一個 DL 框架(如 TensorFlow 、 PyTorch 、 TensorRT 等)的包裝器。有關更多信息,請參閱 backend 。
最大批量大小
模型可以支持的最大批處理大小由max_batch_size屬性指示。零尺寸表示不支持洗澡。有關詳細信息,請參見 batch size 。
輸入和輸出
對于每個模型,必須在 model configuration 文件中指定預期的輸入、輸出和數據類型。根據輸入和輸出張量,允許不同的數據類型。有關詳細信息,請參見 Datatypes 。
圖像分類模型接受單個輸入,推理后返回單個輸出。
在一個單獨的控制臺中,從 NGC NVIDIA Triton 容器中啟動image_client示例。
客戶端:運行圖像分類客戶端
要運行圖像分類客戶端,請使用以下命令:
$ python3 /python_examples/examples/classification/classification.py -m classification -s INCEPTION /python_examples/examples/images/tabby.jpg首先,根據模型對輸入進行預處理。對于該模型,應用了 Inception 縮放,按如下方式縮放輸入:
if scaling == 'INCEPTION':
scaled = (typed / 127.5) - 1推斷請求發送至 NVIDIA Triton ,并附上響應:
responses.append(
triton_client.infer(FLAGS.model_name,
inputs,
request_id=str(sent_count),
model_version=FLAGS.model_version,
outputs=outputs))最后,對從服務器獲得的響應進行后處理。
postprocess(response, output_name, FLAGS.batch_size, supports_batching)對于分類情況,模型返回包含輸入圖像的單個分類輸出。類在控制臺中被解碼和打印。
for results in output_array:
if not supports_batching:
results = [results]
for result in results:
if output_array.dtype.type == np.object_:
cls = "".join(chr(x) for x in result).split(':')
else:
cls = result.split(':')
print(" {} ({}) = {}".format(cls[0], cls[1], cls[2]))有關詳細信息,請參閱classification.py。
圖 4 顯示了示例輸出。

物體檢測
在圖像中查找特定類別的對象實例的過程稱為 object detection 。對象檢測問題將分類與定位結合起來。它還檢查了圖像可能包含多個對象的更合理的場景。有關詳細信息,請參見 object detection 。
服務器:下載模型
下載faster_rcnn_inception_v2_coco對象檢測模型:
$ cd /path/to/the/repo/server/models/detection/1
$ wget http://download.tensorflow.org/models/object_detection/faster_rcnn_inception_v2_coco_2018_01_28.tar.gz && tar xvf faster_rcnn_inception_v2_coco_2018_01_28.tar.gz && cp faster_rcnn_inception_v2_coco_2018_01_28/frozen_inference_graph.pb ./model.graphdef && rm -r faster_rcnn_inception_v2_coco_2018_01_28 faster_rcnn_inception_v2_coco_2018_01_28.tar.gz以下代碼示例顯示了對象檢測模型的模型配置文件:
name: "detection"
platform: "tensorflow_graphdef"
max_batch_size: 1
input [
{
name: "image_tensor"
data_type: TYPE_UINT8
format: FORMAT_NHWC
dims: [ 600, 1024, 3 ]
}
]
output [
{
name: "detection_boxes"
data_type: TYPE_FP32
dims: [ 100, 4]
reshape { shape: [100,4] }
},
{
name: "detection_classes"
data_type: TYPE_FP32
dims: [ 100 ]
reshape { shape: [ 1, 100 ] }
},
{
name: "detection_scores"
data_type: TYPE_FP32
dims: [ 100 ]
},
{
name: "num_detections"
data_type: TYPE_FP32
dims: [ 1 ]
reshape { shape: [] }
}
]檢測模型接受單個圖像作為輸入,并返回四個不同的輸出。
客戶端 :運行對象檢測客戶端
要運行對象檢測客戶端,請使用以下命令:
$ python3 /python_examples/examples/detection/detection.py -m detection /python_examples/examples/images/car.jpg對象檢測模型返回四個不同的輸出,這些輸出在后處理步驟中被解碼:
detection_boxes = results.as_numpy(output_name[0].name)
detection_classes = results.as_numpy(output_name[1].name)
detection_scores = results.as_numpy(output_name[2].name)
num_detections = results.as_numpy(output_name[3].name)最后,在輸入上繪制邊界框,如下所示:
for idx, detection_box in enumerate(detection_boxes[0,0:int(num_detections),:]):
y_min=int(detection_box[0]*w)
x_min=int(detection_box[1]*h)
y_max=int(detection_box[2]*w)
x_max=int(detection_box[3]*h)
start_point = (x_min,y_min)
end_point = (x_max,y_max)
shape = (start_point, end_point)
draw.rectangle(shape, outline ="red")
draw.text((int((x_min+x_max)/2),y_min), "class-"+str(int(detection_classes[0,idx])), fill=(0,0,0))有關詳細信息,請參閱detection.py。
圖 5 顯示了示例輸出。

圖像分割
對圖像中與同一對象類相對應的部分進行聚類的過程稱為 image segmentation 。圖像分割需要將圖像或視頻幀分割成多個對象或片段。有關詳細信息,請參見 image segmentation 。
服務器:下載模型
要下載模型,請使用以下命令:
$ cd /path/to/the/repo/server/models/segmentation/1
$ wget https://github.com/onnx/models/raw/main/vision/object_detection_segmentation/fcn/model/fcn-resnet50-11.onnx && mv fcn-resnet50-11.onnx model.onnx以下代碼示例顯示了圖像分割模型的模型配置文件:
name: "segmentation"
platform: "onnxruntime_onnx"
max_batch_size : 0
input [
{
name: "input"
data_type: TYPE_FP32
format: FORMAT_NCHW
dims: [ 3, -1, -1 ]
reshape { shape: [ 1, 3, -1, -1 ] }
}
]
output [
{
name: "out"
data_type: TYPE_FP32
dims: [ -1, 21, -1, -1 ]
}
]客戶端:運行圖像分類客戶端
要運行圖像分類客戶端,請運行以下命令:
$ pip install opencv-python
$ python3 /python_examples/examples/segmentation/segmentation.py -m segmentation -s INCEPTION /python_examples/examples/images/people.jpg分割模型接受單個輸入并返回單個輸出。推理后,模型返回基于生成分割和混合圖像的輸出。
# generate segmented image
result_img = colorize(raw_labels)
# generate blended image
blended_img = cv2.addWeighted(image[:, :, ::-1], 0.5, result_img, 0.5, 0)有關詳細信息,請參閱segmentation.py文件。
圖 6 顯示了示例輸出。

資源
立即在 GPU 、 CPU 或兩者上試用 Triton 推理服務器。 NVIDIA Triton Inference Server container 可以從 NGC 下載,其源代碼可以在 /triton-inference-server GitHub repo 上獲得。
- 有關文檔,請參閱 Triton 推理 服務器 在 GitHub 上。
- 如果您正在尋找動手技能實驗室,請參見 Efficient Cloud-based Deployment of Deep Learning Models using Triton Inference Server and TensorRT 。
- 有關 NVIDIA Triton 推理服務器的可擴展模型部署,請參閱 Fast and Scalable AI Model Deployment with NVIDIA Triton Inference Server 。
- 參見 Simplifying AI Inference in Production with NVIDIA Triton 。
- 如果您對大型模型的推理感興趣,請參見 Accelerated Inference for Large Transformer Models Using NVIDIA Triton Inference Server 。
- 有關本文中使用的代碼的副本,請參見 Gitlab 上的 /arslana/triton_blog_1 。
?