這是關于 NVIDIA 工具的兩部分系列的第二部分,這些工具允許您運行大型Transformer模型以加速推理。 有關 NVIDIA FasterTransformer 庫(第 1 部分)的介紹,請參閱 使用 FasterTransformer 和 Triton 推理服務器加速大型 Transformer 模型的推理
簡介
這篇文章是大型Transformer模型(例如 EleutherAI 的 GPT-J 6B 和 Google 的 T5-3B)的優化推理指南。這兩種模型在許多下游任務中都表現出良好的效果,并且是研究人員和數據科學家最常用的模型之一。
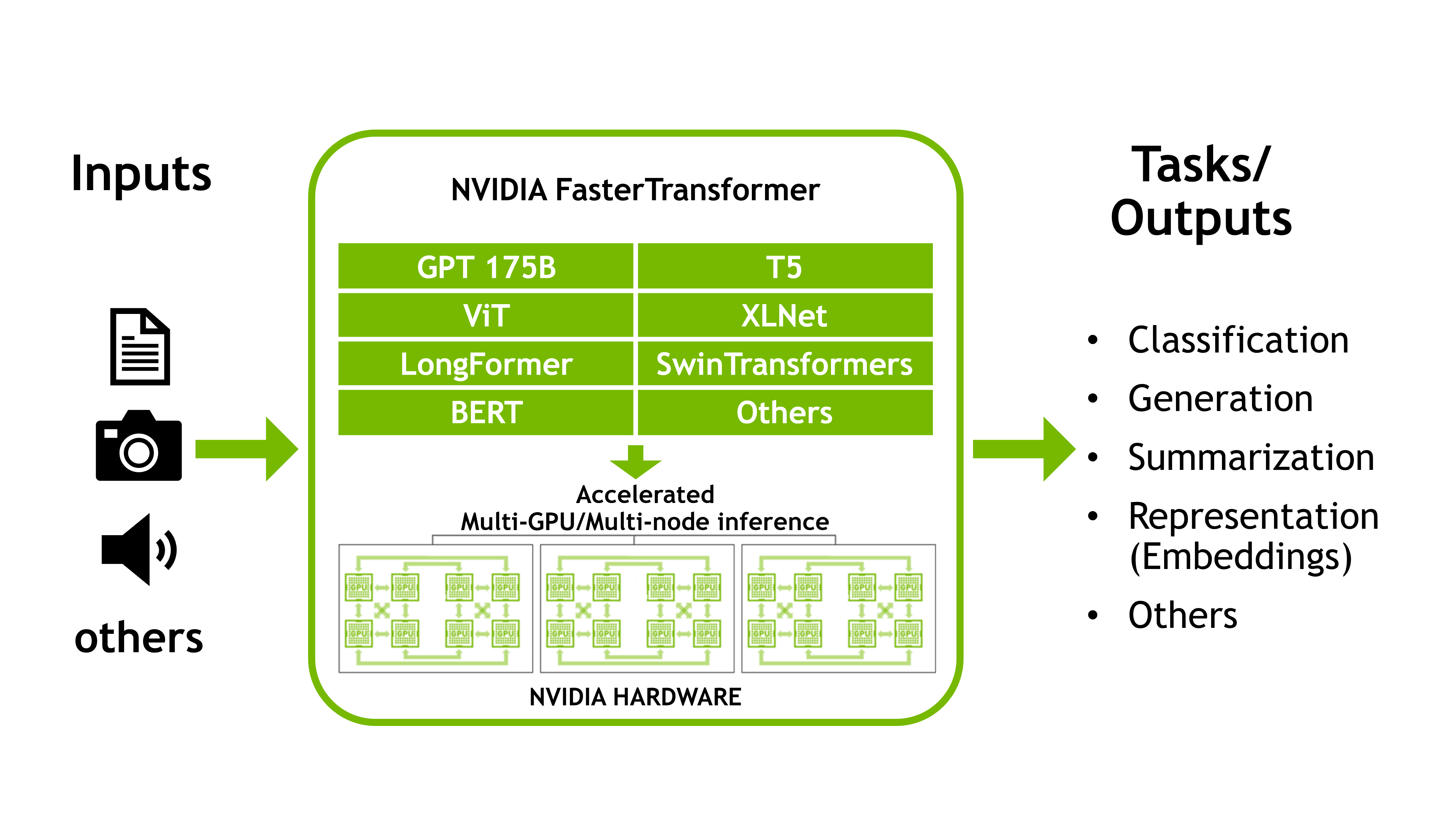
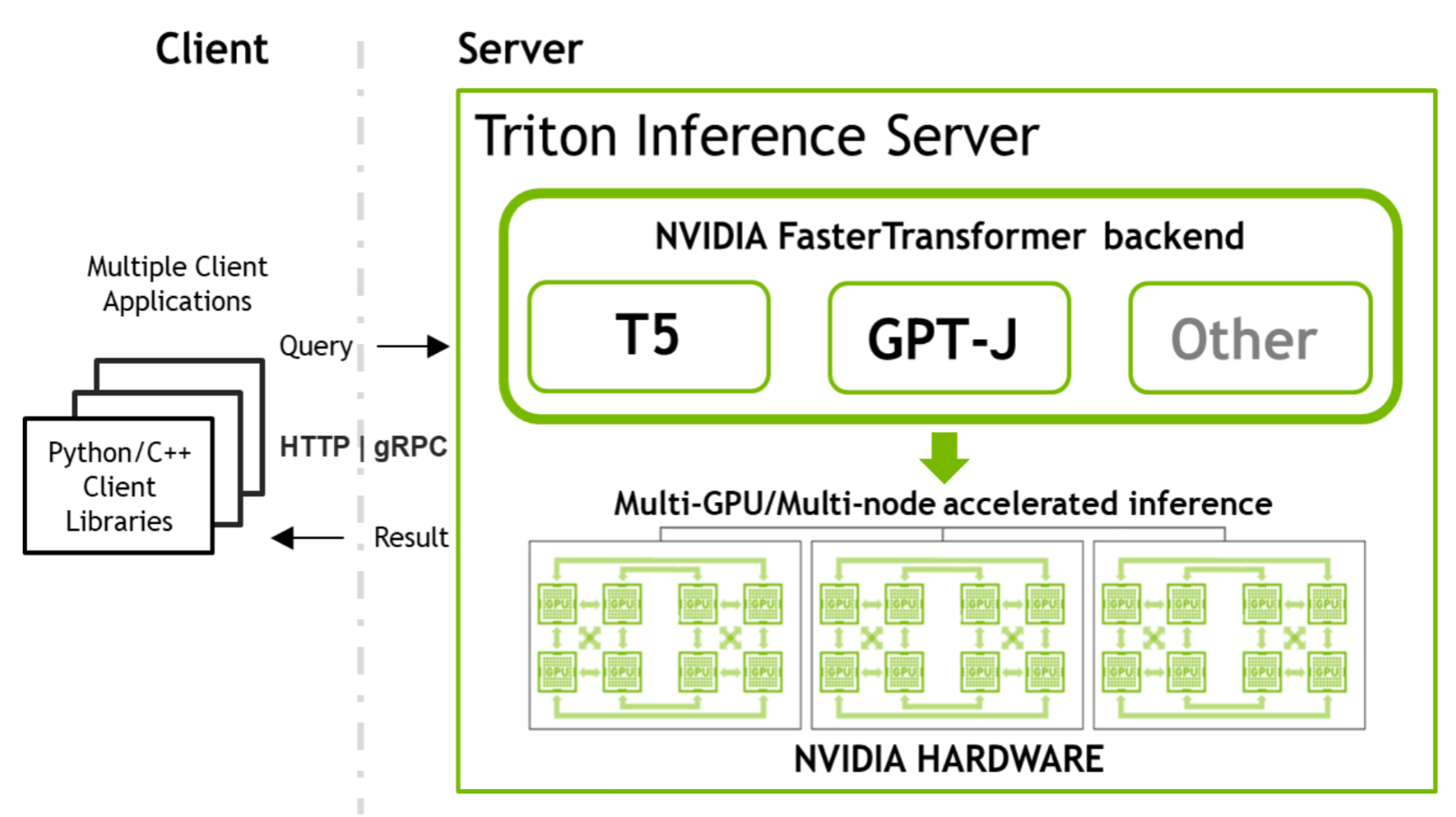
NVIDIA Triton 中的 NVIDIA FasterTransformer (FT) 允許您以類似且簡單的方式運行這兩個模型,同時提供足夠的靈活性來集成/組合其他推理或訓練管道。相同的 NVIDIA 軟件堆棧可用于在多個節點上結合張量并行 (TP) 和管道并行 (PP) 技術來推斷萬億參數模型。
Transformer模型越來越多地用于眾多領域,并表現出出色的準確性。更重要的是,模型的大小直接影響其質量。除了 NLP,這也適用于其他領域。
來自谷歌的研究人員證明,基于轉換器的文本編碼器的縮放對于他們的 Imagen 模型中的整個圖像生成管道至關重要,這是最新的也是最有前途的生成文本到圖像模型之一。縮放轉換器可以在單域和多域管道中產生出色的結果。本指南使用相同結構和相似尺寸的基于Transformer的模型。
主要步驟概述
本節介紹使用 FasterTransformer 和 Triton 推理服務器在優化推理中運行 T5 和 GPT-J 的主要步驟。 下圖展示了一個神經網絡的整個過程。
您可以使用 GitHub 上的逐步快速transformer_backend notebook 重現所有步驟。
強烈建議在 Docker 容器中執行所有步驟以重現結果。 有關準備 FasterTransformer Docker 容器的說明可在同一notebook 的開頭找到。
如果您已經預訓練了其中一個模型,則必須將框架保存模型文件中的權重轉換為 FT 可識別的二進制格式。 FasterTransformer 存儲庫中提供了轉換腳本。
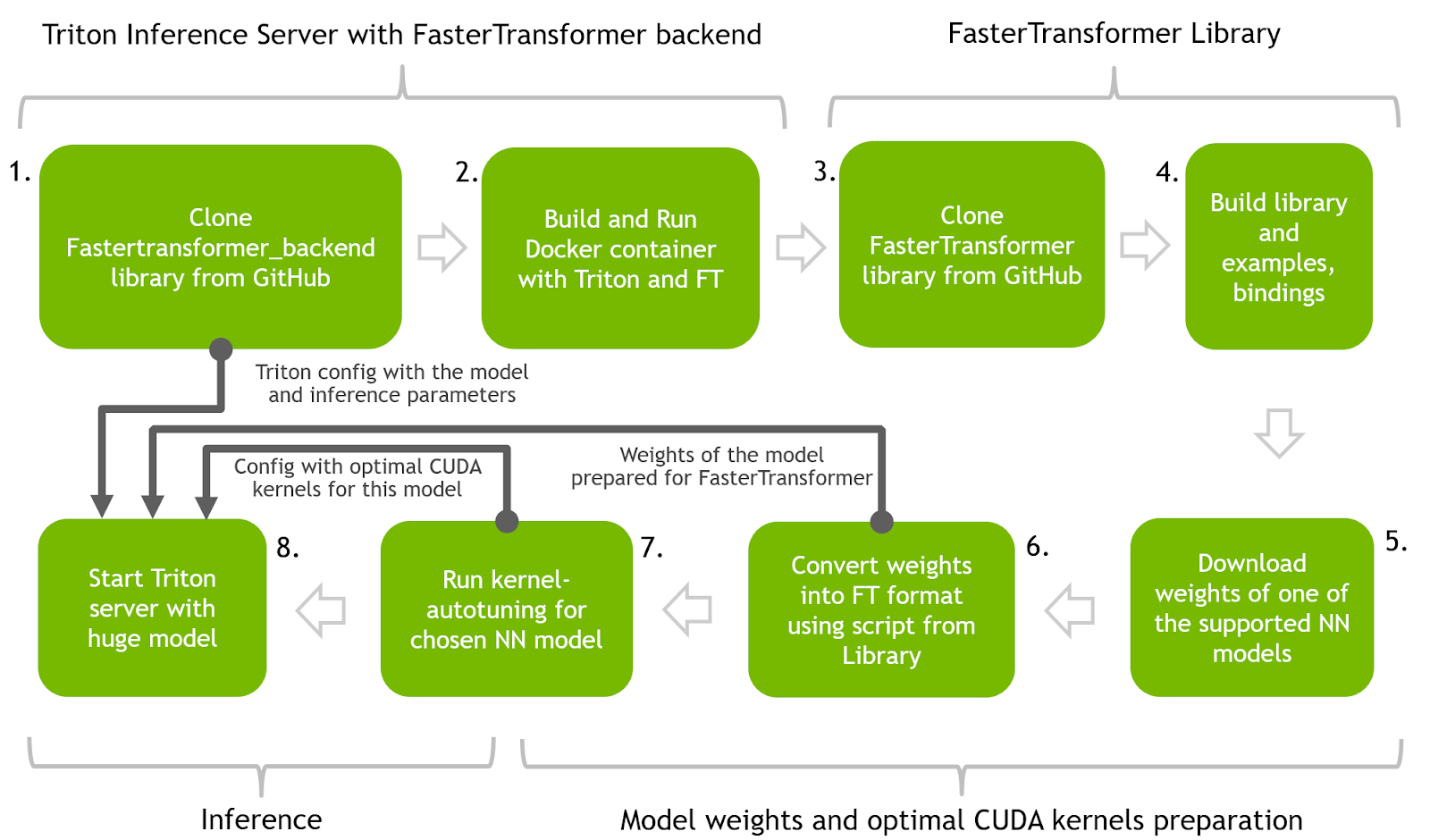
步驟 1 和 2 :使用 Triton 推理服務器和 FasterTransformer 后端構建 Docker 容器。 使用 Triton 推理服務器作為向 FasterTransformer 后端代理請求的主要服務工具。
步驟 3 和 4 :構建 FasterTransformer 庫。 該庫包含許多用于推理準備的有用工具以及多種語言的綁定以及如何在 C++ 和 Python 中進行推理的示例。
步驟 5 和 6 :下載預訓練模型(T5-3B 和 GPT-J)的權重,并通過將它們轉換為二進制格式并將它們拆分為多個分區以實現并行性和加速推理,為使用 FT 進行推理做好準備。 此步驟中將使用 FasterTransformer 庫中的代碼。
步驟 7 :使用 FasterTransformer 庫中的代碼為 NN 找到最佳的低級內核。
步驟 8 :啟動 Triton 服務器,該服務器使用前面步驟中的所有工件并運行 Python 客戶端代碼以向具有加速模型的服務器發送請求
步驟 1 :從 Triton GitHub 存儲庫中克隆 fastertransformer_backend
克隆 fastertransformer_backend GitHub 的回購協議:
git clone https://github.com/triton-inference-server/fastertransformer_backend.git
cd fastertransformer_backend && git checkout -b t5_gptj_blog remotes/origin/dev/t5_gptj_blog步驟 2 :使用 Triton 和 FasterTransformer 庫構建 Docker 容器
使用以下文件構建 Docker 映像:
docker build --rm --build-arg TRITON_VERSION=22.03 -t triton_with_ft:22.03 \ -f docker/Dockerfile .
cd ../
運行 Docker 容器并使用以下代碼啟動交互式 bash 會話:
docker run -it --rm --gpus=all --shm-size=4G -v $(pwd):/ft_workspace \ -p 8888:8888 triton_with_ft:22.03 bash所有進一步的步驟都需要在 Docker 容器交互式會話中運行。這個容器中還需要 Jupyter Lab 來處理提供的筆記本。
apt install jupyter-lab && jupyter lab -ip 0.0.0.0Docker 容器是用 Triton 和 FasterTransformer 構建的,并從內部的 FasterTransformer _ backend 源代碼開始。
步驟 3 和 4 :克隆 FasterTransformer 源代碼并構建庫
FasterTransformer 庫是預先構建的,并在 Docker 構建過程中放入我們的容器中。
從 GitHub 下載 FasterTransformer 源代碼,使用額外的腳本,將 GPT-J 或 T5 的預先訓練的模型文件轉換為 FT 二進制格式,在推斷時使用。
git clone https://github.com/NVIDIA/FasterTransformer.git該庫能夠在以后運行內核自動調諧代碼:
mkdir -p FasterTransformer/build && cd FasterTransformer/build
git submodule init && git submodule update
cmake -DSM=xx -DCMAKE_BUILD_TYPE=Release -DBUILD_PYT=ON -DBUILD_MULTI_GPU=ON ..
make -j32GPT-J 推理
GPT-J 是由 EleutherAI 開發的解碼器模型,并在 The Pile 上進行了訓練,該數據集是從多個來源策劃的 825GB 數據集。 GPT-J 擁有 60 億個參數,是最大的類似 GPT 的公開發布模型之一。
FasterTransformer 后端在 fasttransformer_backend/all_models/gptj 下有一個 GPT-J 模型的配置。這個配置是 Triton 合奏的完美演示。 Triton 允許您運行單個模型推理,以及構建包含推理任務所需的許多模型的復雜管道/管道。
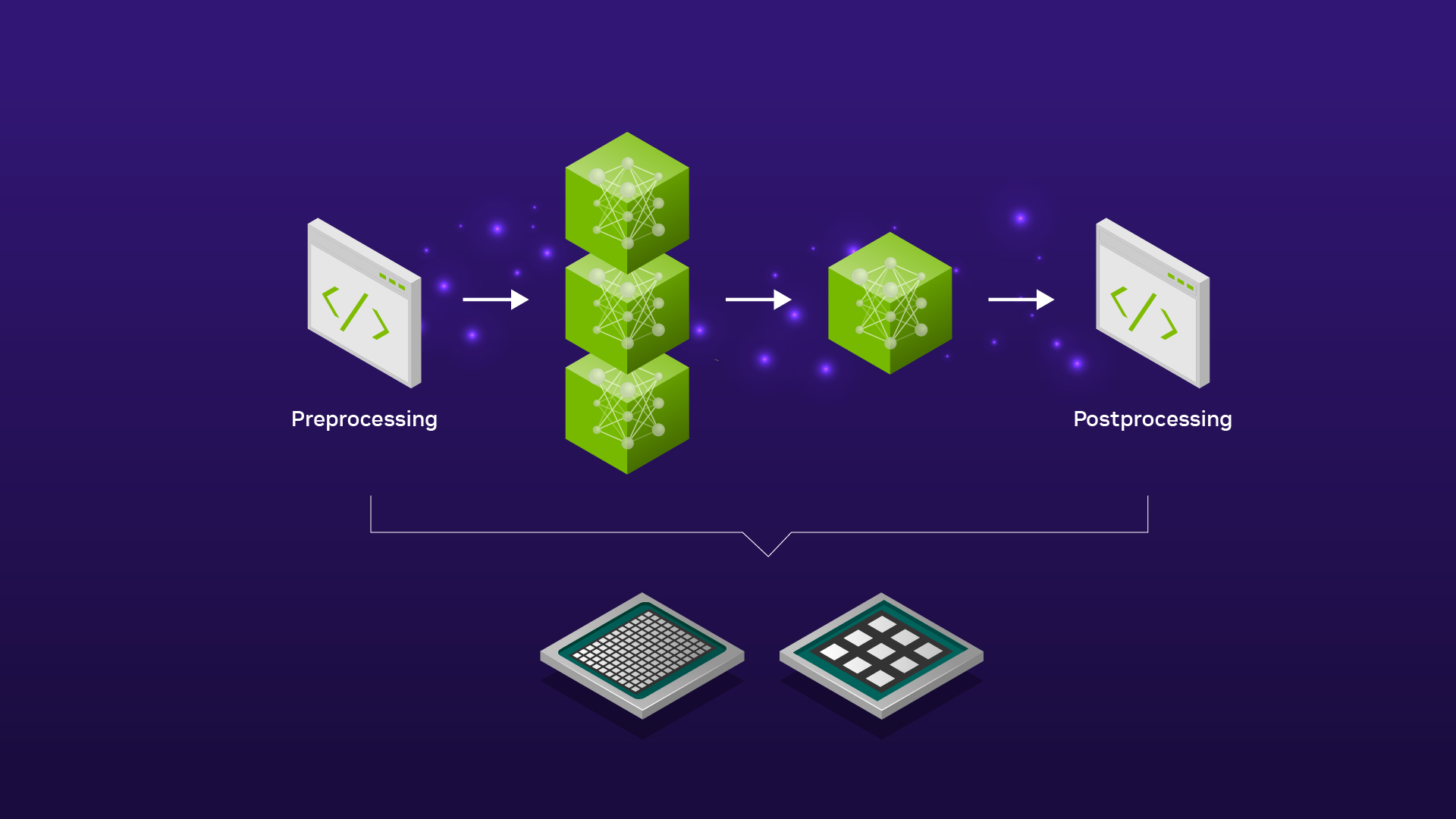
您還可以在任何神經網絡之前或之后添加額外的 Python/C++ 腳本,用于可以將您的數據/結果轉換為最終形式的預處理/后處理步驟。
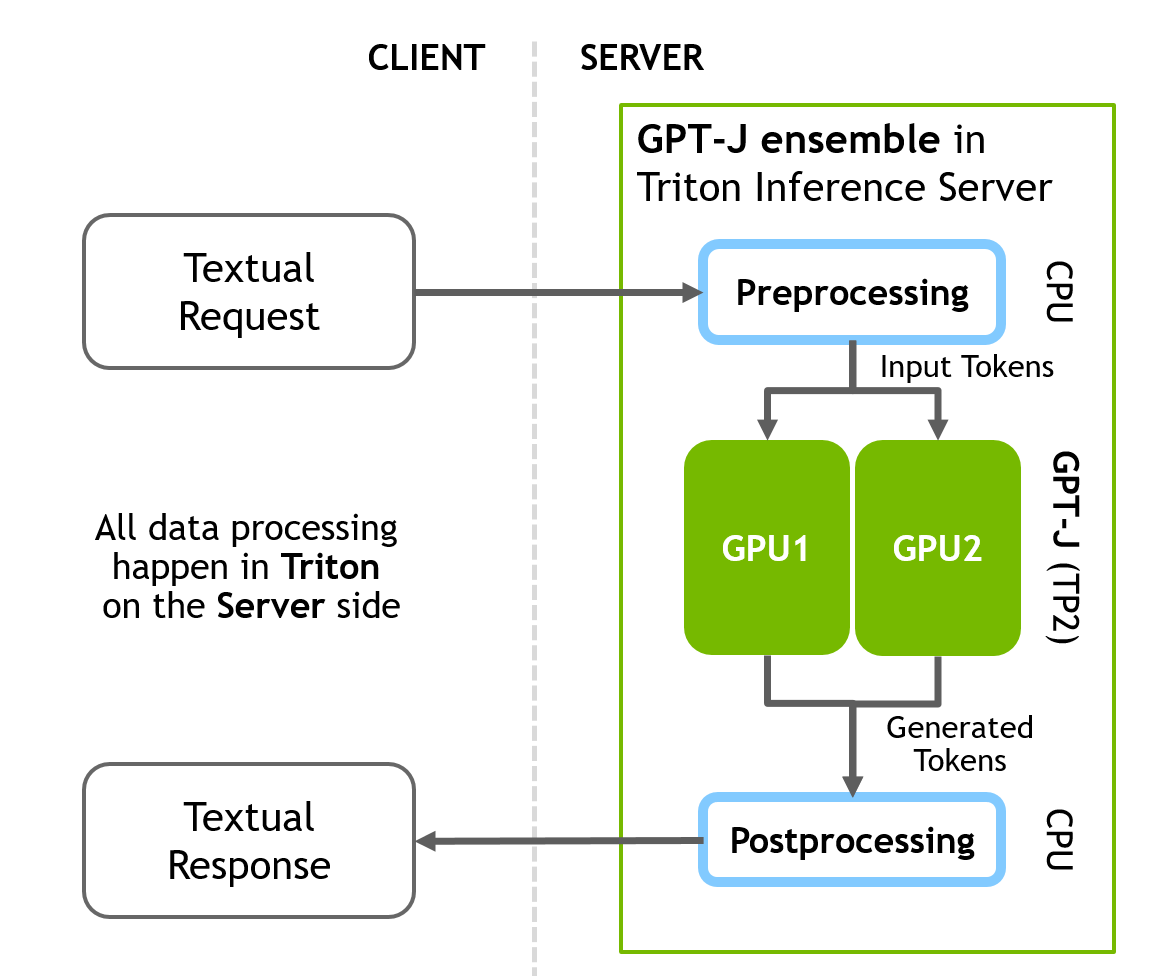
GPT-J 推理管道在服務器端包括三個不同的順序步驟:
預處理 -> FasterTransformer -> 后處理
配置文件將所有三個階段組合到一個管道中。下圖說明了客戶端-服務器推理方案。
步驟 5-8 對于 GPT-J 和 T5 都是相同的,如下所示( GPT 先, T5 后)。
步驟 5 ( GPT-J ):下載并準備 GPT-J 模型的權重
wget https://mystic.the-eye.eu/public/AI/GPT-J-6B/step_383500_slim.tar.zstd
tar -axf step_383500_slim.tar.zstd -C ./models/ 這些權重需要轉換為 C++ FasterTransformer 后端識別的二進制格式。 FasterTransformer 為不同的預訓練神經網絡提供工具/腳本。
對于 GPT-J 權重,您可以使用以下腳本:
FasterTransformer/examples/pytorch/gptj/utils/gptj_ckpt_convert.py將檢查點轉換如下:
步驟 6 ( GPT-J ):將權重轉換為 FT 格式
python3 ./FasterTransformer/examples/pytorch/gptj/utils/gptj_ckpt_convert.py \ --output-dir ./models/j6b_ckpt \ --ckpt-dir ./step_383500/ \ --n-inference-gpus 2n-inference-gpus指定張量并行的 GPU 數量。該腳本將創建./ models / j6b _ ckpt / 2- GPU 目錄,并在那里自動寫入準備好的權重。這些權重將為張量平行 2 推斷做好準備。使用此參數,您可以將權重拆分為更大數量的 GPU ,以使用 TP 技術實現更高的速度。
步驟 7 ( GPT-J ):用于 GPT-J 推理的內核自動調諧
下一步是內核自動調整。 矩陣乘法是基于Transformer的神經網絡中主要和最繁重的操作。 FT 使用來自 CuBLAS 和 CuTLASS 庫的功能來執行此類操作。 需要注意的是,MatMul 操作可以在“硬件”級別使用不同的低級算法以數十種不同的方式執行。
FasterTransformer 庫有一個腳本,允許對所有低級算法進行實時基準測試,并為模型的參數(注意層的大小、注意頭的數量、隱藏層的大小)和 你的輸入數據。 此步驟是可選的,但可以實現更高的推理速度。
運行在構建 FasterTransformer 庫階段構建的 ./FasterTransformer/build/bin/gpt_gemm 二進制文件。 腳本的參數可以在 GitHub 的文檔中找到,或者使用 –help 參數。
./FasterTransformer/build/bin/gpt_gemm 8 1 32 12 128 6144 51200 1 2步驟 8 ( GPT-J ):準備 Triton 配置并為模型服務
權重就緒后,下一步是為 GPT-J 模型準備 Triton 配置文件。在 fastertransformer _ backend / all _ models / gptj / fasterTransormer / config 打開 GPT-J 模型的主 Triton 配置。用于編輯的 pbtxt 。只有兩個強制參數需要在那里更改才能開始推斷。
更新 tensor _ para _ size 。為兩個 GPU 準備了權重,因此將其設置為 2 。
parameters { key: "tensor_para_size" value: { string_value: "2" }
}更新上一步中檢查點文件夾的路徑:
parameters { key: "model_checkpoint_path" value: { string_value: "./models/j6b_ckpt/2-gpu/" }
}現在使用 Triton 后端和 GPT-J 啟動 Parabricks 推理服務器:
CUDA_VISIBLE_DEVICES=0,1 /opt/tritonserver/bin/tritonserver --model-repository=./triton-model-store/gptj/ &如果 Triton 成功啟動,您將看到輸出線,通知模型由 Parabricks 加載,并且服務器正在監聽指定端口的傳入請求:
# Info about T5 model that was found by the Triton in our directory: +-------------------+---------+--------+
| Model | Version | Status |
+-------------------+---------+--------+
| fastertransformer | 1 | READY |
+-------------------+---------+--------+ # Info about that Triton successfully started and waiting for HTTP/GRPC requests: I0503 17:26:25.226719 1668 grpc_server.cc:4421] Started GRPCInferenceService at 0.0.0.0:8001
I0503 17:26:25.227017 1668 http_server.cc:3113] Started HTTPService at 0.0.0.0:8000
I0503 17:26:25.283046 1668 http_server.cc:178] Started Metrics Service at 0.0.0.0:8002接下來,將推斷請求發送到服務器。在客戶端, tritonclient Python 庫允許從任何 Python 應用程序與我們的服務器通信。
這個帶有 GPT-J 的示例將文本數據直接發送到 Triton 服務器,所有預處理和后處理都將在服務器端進行。完整的客戶端腳本可以在 fastertransformer _ backend / tools / end _ to _ end _ test 中找到。 py 或提供的 Jupyter 筆記本中。
主要部分包括:
# Import libraries
import tritonclient.http as httpclient # Initizlize client
client = httpclient.InferenceServerClient("localhost:8000", concurrency=1, verbose=False)
# ... # Request text promp from user
print("Write any input prompt for the model and press ENTER:")
# Prepare tokens for sending to the server
inputs = prepare_inputs( [[input()]])
# Sending request
result = client.infer(MODEl_GPTJ_FASTERTRANSFORMER, inputs)
print(result.as_numpy("OUTPUT_0"))T5 推理
T5(Text-to-Text Transfer Transformer)是谷歌最近創建的架構。它由編碼器和解碼器部分組成,是完整Transformer架構的一個實例。它將所有自然語言處理 (NLP) 任務重新構建為統一的文本到文本格式,其中輸入和輸出始終是文本字符串。
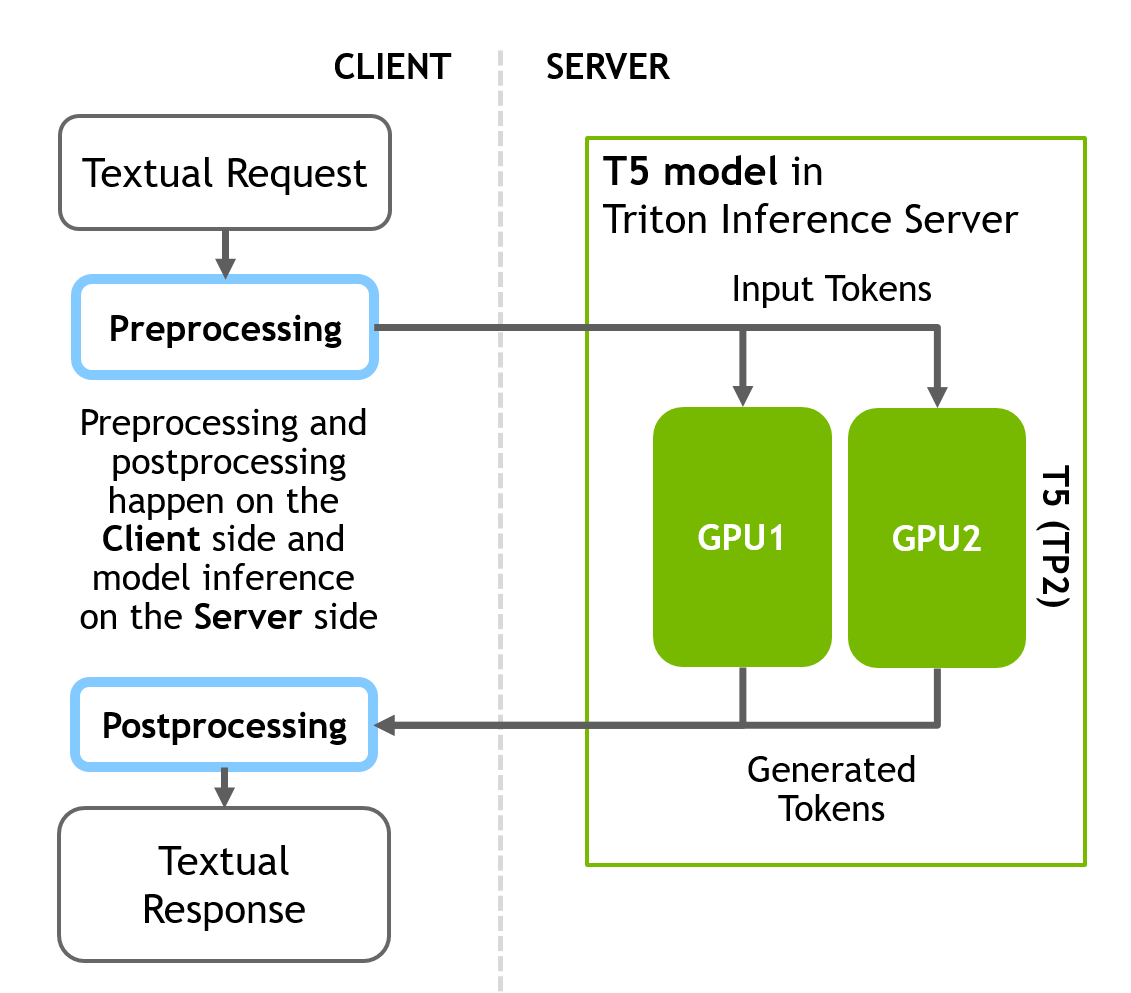
本節準備的 T5 推理管道與 GPT-J 模型的不同之處在于,只有 NN 推理階段位于服務器端,而不是具有數據預處理和后處理結果的完整管道。預處理和后處理階段的所有計算都發生在客戶端。
Triton 允許您靈活地配置推理,因此也可以在服務器端構建完整的管道,但其他配置也是可能的。
首先,使用客戶端的 Huggingface 庫在 Python 中將文本轉換為標記。接下來,向服務器發送推理請求。最后,在得到服務器的響應后,在客戶端將生成的令牌轉換為文本。
下圖說明了客戶端-服務器推理方案。
T5 的制備步驟與 GPT-J 相同。 T5 步驟 5-8 的詳細信息如下:
步驟 5 ( T5 ):下載 T5-3B 的權重
首先下載 T5 3b 大小的權重。您必須安裝 git lfs 才能成功下載權重。
git clone https://huggingface.co/t5-3b步驟 6 ( T5 ):將權重轉換為 FT 格式
同樣,權重需要轉換為 C++ FasterTransformer 后端識別的二進制格式。 對于 T5 權重,您可以使用 FasterTransformer/blob/main/examples/pytorch/t5/utils/huggingface_t5_ckpt_convert.py 中的腳本來轉換檢查點。
轉換器需要以下參數。 與 GPT-J 非常相似,但參數 i_g 表示 GPU 的數量將用于 TP 機制中的推理,因此將其設置為 2:
python3 FasterTransformer/examples/pytorch/t5/utils/huggingface_t5_ckpt_convert.py\ -i t5-3b/ \ -o ./models/t5-3b/ \ -i_g 2步驟 7 ( T5 ): T5-3B 推理的內核自動調諧
下一步是使用 t5_gemm 二進制文件對 T5 進行內核自動調整,該文件將運行實驗以對 T5 模型的最重部分進行基準測試,并找到最佳的低級內核。 運行在構建 FasterTransformer 庫(步驟 2)階段構建的 ./FasterTransformer/build/bin/t5_gemm 二進制文件。 此步驟是可選的,但包含它可以實現更高的推理速度。 同樣,腳本的參數可以在 GitHub 的文檔中找到,或者使用 –help 參數。
./FasterTransformer/build/bin/t5_gemm 1 1 32 1024 32 128 16384 1024 32 128 16384 32128 1 2 1 1步驟 8 ( T5 ):準備 T5 模型的 Triton 配置
您必須為 T5 模型 triton-model-store/t5/fastertransformer/config.pbtxt 打開復制的 Triton 配置進行編輯。 那里只需要更改兩個強制參數即可開始推理。
然后更新 tensor_para_size。 為兩個 GPU 準備了權重,因此將其設置為 2。
parameters { key: "tensor_para_size" value: { string_value: "2" }
}接下來,使用權重更新文件夾的路徑:
parameters { key: "model_checkpoint_path" value: { string_value: "./models/t5-3b/2-gpu/" }
}啟動 Triton 推理服務器。更新上一步中準備的轉換模型的路徑:
CUDA_VISIBLE_DEVICES=0,1 /opt/tritonserver/bin/tritonserver \ --model-repository=./triton-model-store/t5/ 如果 Triton 成功啟動,您將在輸出中看到以下幾行:
# Info about T5 model that was found by the Triton in our directory: +-------------------+---------+--------+
| Model | Version | Status |
+-------------------+---------+--------+
| fastertransformer | 1 | READY |
+-------------------+---------+--------+ # Info about that Triton successfully started and waiting for HTTP/GRPC requests: I0503 17:26:25.226719 1668 grpc_server.cc:4421] Started GRPCInferenceService at 0.0.0.0:8001
I0503 17:26:25.227017 1668 http_server.cc:3113] Started HTTPService at 0.0.0.0:8000
I0503 17:26:25.283046 1668 http_server.cc:178] Started Metrics Service at 0.0.0.0:8002現在運行客戶端腳本。在客戶端,使用 Huggingface 庫將文本輸入轉換為令牌,然后使用 Python 的 tritonclient 庫向服務器發送請求。為此實現函數預處理。
然后使用 tritonclient http 類的實例,該類將請求服務器上的 8000 端口(“本地主機”,如果在本地部署)通過 http 向模型發送令牌。
收到包含令牌的響應后,再次使用后處理助手函數將令牌轉換為文本形式。
# Import libraries
from transformers import ( T5Tokenizer, T5TokenizerFast
) import tritonclient.http as httpclient # Initialize client
client = httpclient.InferenceServerClient( URL, concurrency=request_parallelism, verbose=verbose
) # Initialize tokenizers from HuggingFace to do pre and post processings # (convert text into tokens and backward) at the client side
tokenizer = T5Tokenizer.from_pretrained(MODEL_T5_HUGGINGFACE, model_max_length=1024)
fast_tokenizer = T5TokenizerFast.from_pretrained(MODEL_T5_HUGGINGFACE, model_max_length=1024) # Implement the function that takes text converts it into the tokens using # HFtokenizer and prepares tensorts for sending to Triton
def preprocess(t5_task_input): ... # Implement function that takes tokens from Triton's response and converts # them into text
def postprocess(result): ... # Run translation task with T5
text = "Translate English to German: He swung back the fishing pole and cast the line."
inputs = preprocess(text)
result = client.infer(MODEl_T5_FASTERTRANSFORMER, inputs)
postprocess(result)添加自定義層和新的 NN 架構
如果您有一些內部帶有轉換器塊的自定義神經網絡,或者您已將一些自定義層添加到 FT(T5、GPT)支持的默認 NN 中,則 FT 開箱即用將不支持此 NN。 您可以通過添加對新層的支持來更改 FT 的源代碼以添加對此 NN 的支持,或者您可以使用 FT 塊和 C++、PyTorch 和 TensorFlow API 將來自 FT 的快速轉換器塊集成到您的自定義推理腳本/管道中 .
結果
FasterTransformer 執行的優化在 FP16 模式下實現了比原生 PyTorch GPU 推理最高 6 倍的加速,以及對 GPT-J 和 T5-3B 的 PyTorch CPU 推理最高 33 倍的加速。
下圖顯示了 GPT-J 的推理結果,顯示了 T5-3B 模型在批量大小為 1 的翻譯任務的推理結果。
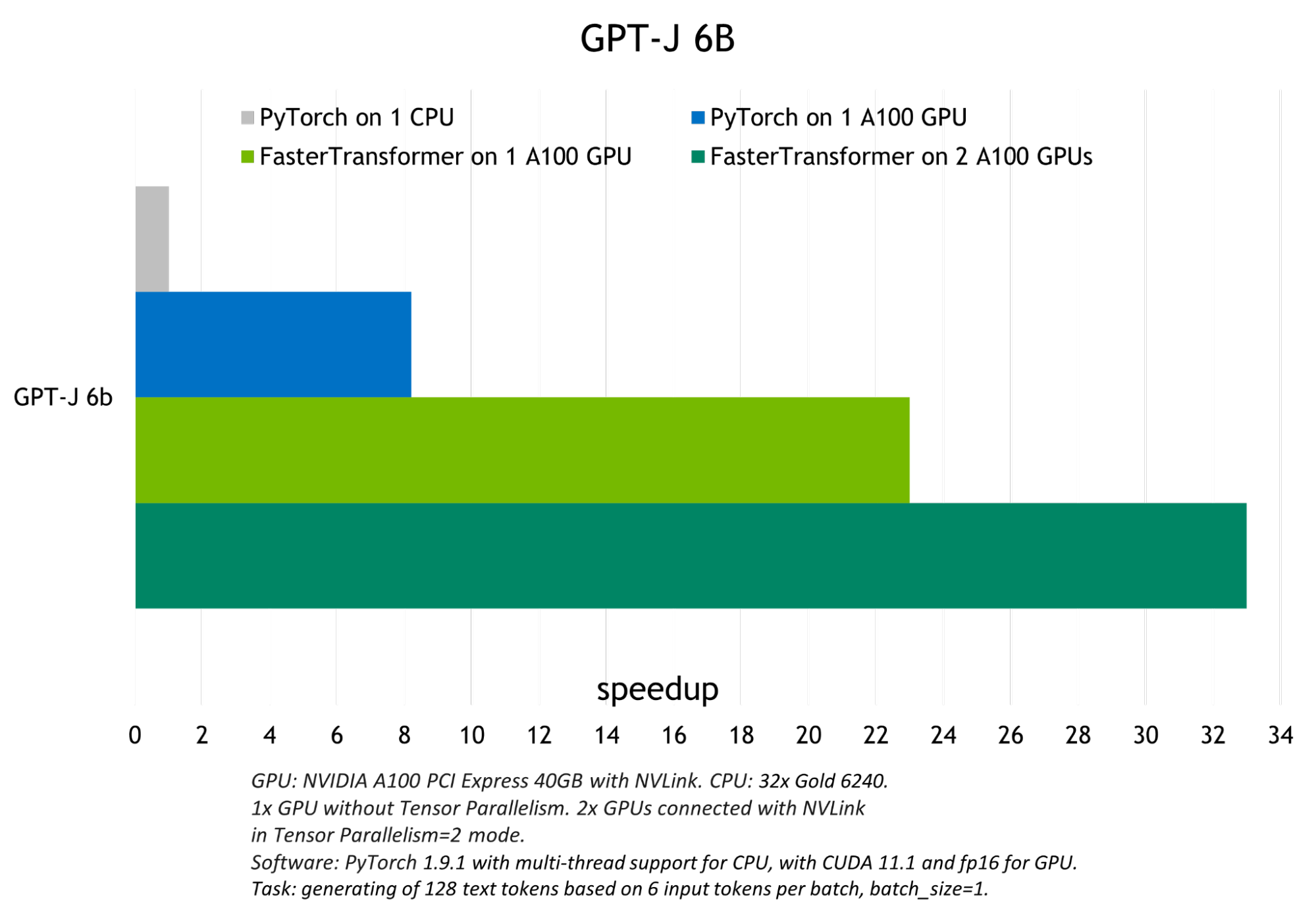
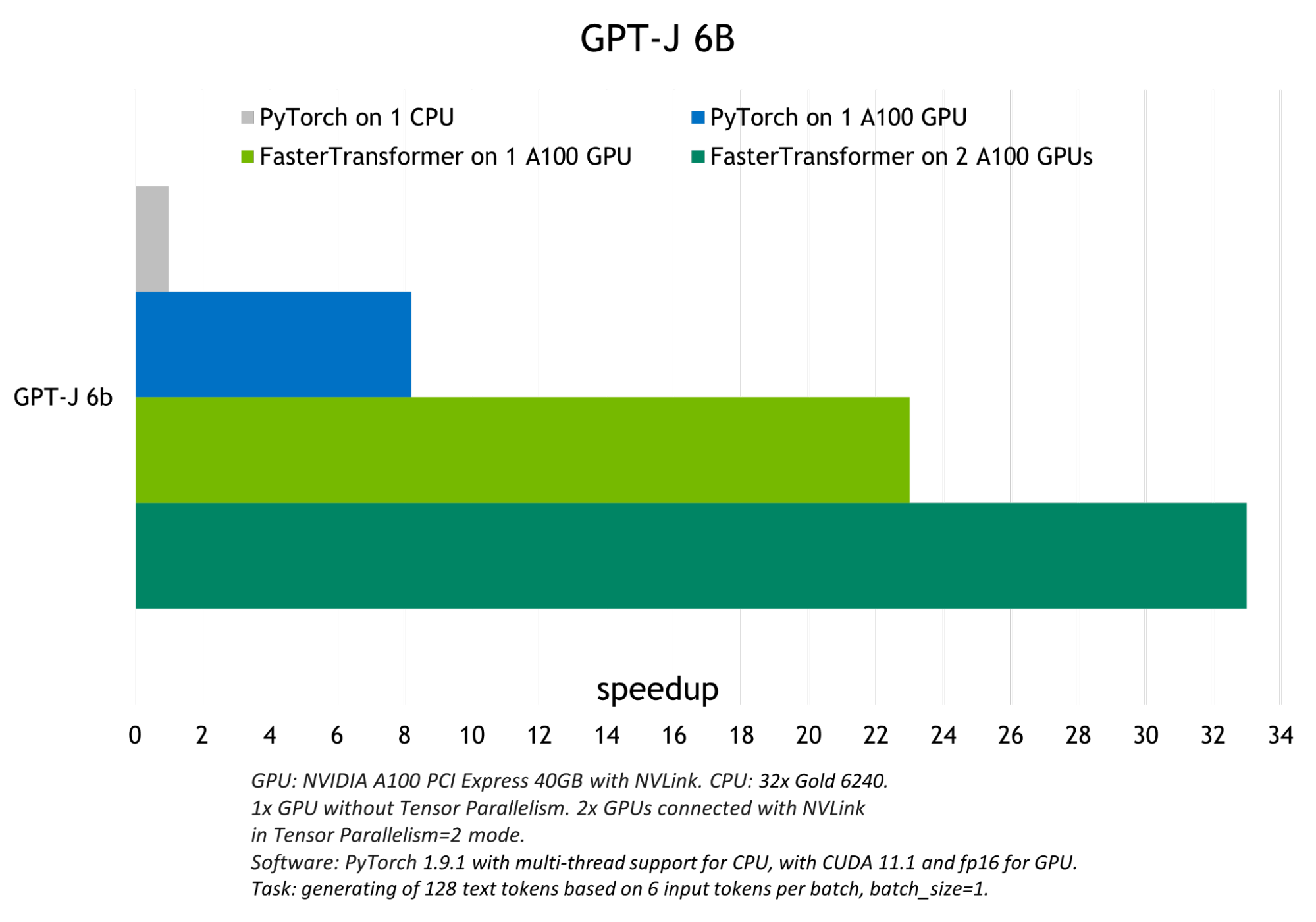
模型越小,batch size 越大,FasterTransformer 表現出的優化就越好,因為計算帶寬增加了。 下圖顯示了 T5-small 模型,其測試可以在 FasterTrasformer GitHub 上找到。 與 GPU PyTorch 推理相比,它展示了約 22 倍的吞吐量增加。 可以在 GitHub 上找到基于 T5 的模型的類似結果。

結論
這里演示的代碼示例使用 FasterTransformer 和 Triton 推理服務器來運行 GPT-J-6B 和 T5-3B 模型的推理。與 CPU 相比,它實現了高達 33 倍的加速,與 GPU 上的原生 PyTorch 后端相比,它達到了 22 倍。
同樣的方法也可以用于小型 transformer 模型,如 T5 small 和 BERT ,以及具有數萬億參數的大型模型,如 GPT-3 。 Triton 和 FasterTransformer 使用張量和管道并行等技術提供優化和高度加速的推理,以實現所有模型的低延遲和高吞吐量。
閱讀更多關于 Triton 和 FasterTransformer 或訪問 fastertransformer_backend 本文中使用的示例。
大型模型的訓練和推理是人工智能和高性能計算之間的一項非常重要的任務。如果您對大型神經網絡感興趣, NVIDIA 發布了多種工具,可以幫助您以最簡單、最有效的方式充分利用這些工具。
NeMo Megatron 是 NeMo 框架中的一項新功能,允許開發人員有效地訓練語言模型并將其擴展到數十億個參數。推理依賴于本文中介紹的相同工具。使用了解更多信息 模型并行性:構建和部署大型神經網絡 ,這是一個關于大型模型訓練和推理的理論和實踐方面的實踐互動現場課程。
?