自 2022 年 11 月 ChatGPT 發布以來, 大語言模型 (LLMs) 的能力激增,可用模型數量呈指數級增長。隨著此次擴展,LLMs 在成本、性能和專業領域的差異很大。例如,小型通用模型可以高效處理文本摘要等簡單任務。相比之下,代碼生成等復雜操作可受益于具有高級推理能力和擴展測試時計算的大型模型。
對于 AI 開發者和 MLOps 團隊而言,挑戰在于為每個提示選擇合適的模型 – 平衡準確性、性能和成本。一個一刀切的方法效率低下,導致不必要的支出或結果欠佳。
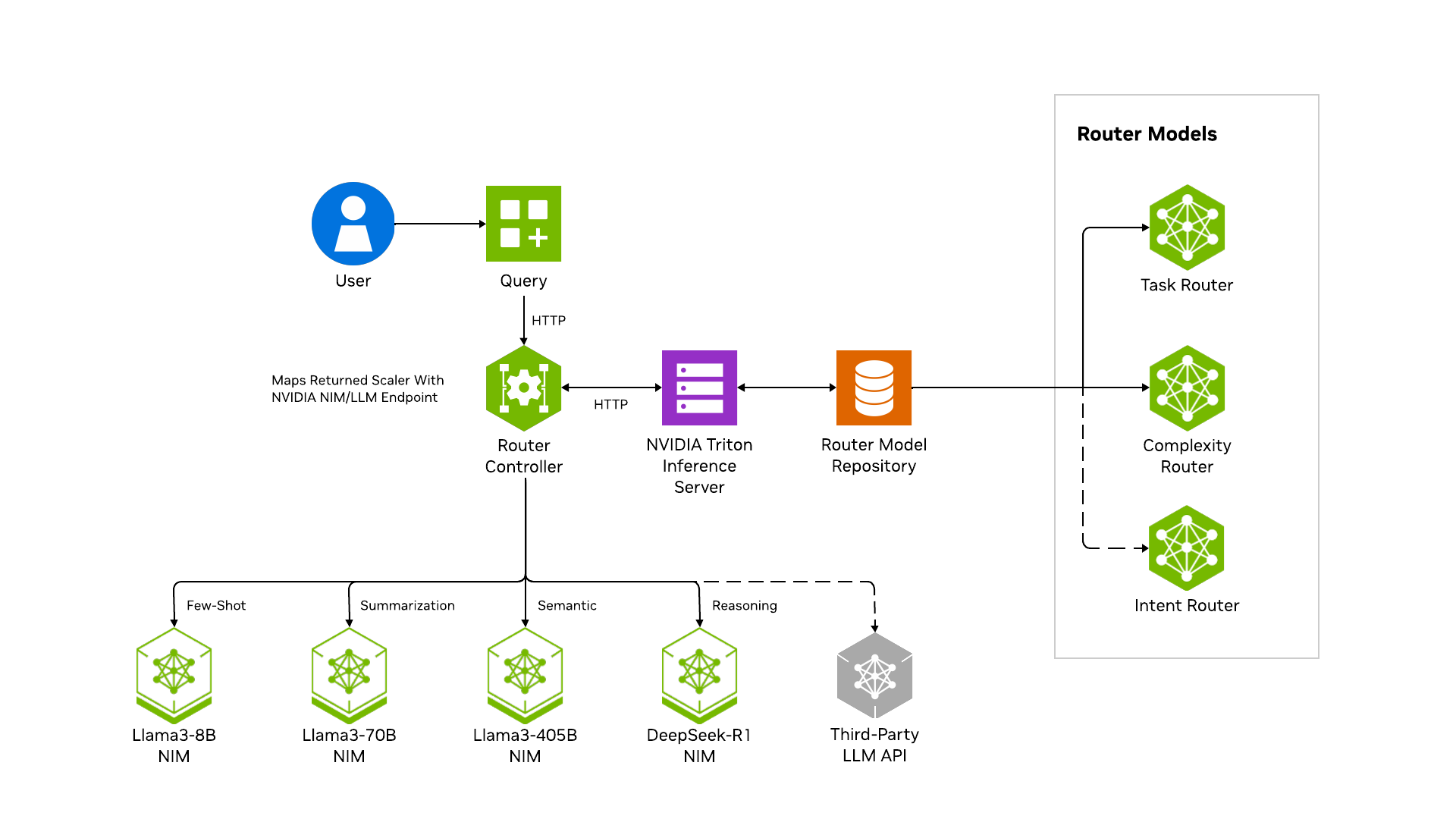
為了解決這個問題,適用于 LLM 路由器的 NVIDIA AI Blueprint 為多 LLM 路由提供了一個經過成本優化的加速框架。它無縫集成了 NVIDIA 工具和工作流,可將提示動態路由到最合適的 LLM,為企業級 LLM 運營提供強大的基礎。
LLM 路由器的主要特性包括:
- 可配置:輕松與基礎模型集成,包括 NVIDIA NIM 和第三方 LLMs。
- 高性能 :基于 Rust 構建,由 NVIDIA Triton Inference Server 提供支持,與直接模型查詢相比,可確保更低的延遲。
- 符合 OpenAI API :可替代現有的基于 OpenAI API 的應用。
- 靈活 :包含默認路由行為,并支持根據業務需求進行微調,例如使用 Python 和 PyTorch 等技術進行定制。
LLM 路由器的 AI Blueprint 不僅展示了如何部署和配置路由器,還提供了用于監控性能、自定義路由行為以及與客戶端應用集成的工具。這使企業能夠根據自己的需求構建可擴展、經濟高效且高性能的 AI 工作流。在本文中,我們將提供有關部署和管理 LLM 路由器的說明,以及使用 LLM 路由器處理多輪對話的示例。
預備知識
要部署 LLM 路由器,請確保您的系統滿足以下要求:
- 操作系統 :Linux (Ubuntu 22.04 或更高版本)
- 硬件: NVIDIA V100 GPU (或更新版本) ,顯存為 4 GB
- 軟件 :
- CUDA 和 NVIDIA 容器工具包
- Docker 和 Docker Compose
- Python
- API 密鑰 (請參閱 NVIDIA NIM for LLMs 入門指南 – 選項 1 和 2) :NVIDIA NGC API 密鑰 NVIDIA API Catalog 密鑰
部署和管理 LLM 路由器的步驟
部署 LLM 路由器
按照 藍圖 notebook 安裝必要的依賴項,并使用 Docker Compose 運行 LLM 路由器服務。
測試路由行為
使用示例 Python 代碼或示例 Web 應用向 LLM 路由器發出請求。LLM 路由器充當反向代理來處理請求:
- LLM 路由器接收請求并解析 payload
- LLM 路由器將解析后的負載轉發到分類模型
- 模型返回分類
- LLM 路由器根據分類將負載轉發給 LLM
- LLM 路由器會將 LLM 的結果代理返回給用戶
表 1 提供了按任務分類并路由到相應模型的示例提示。
| 用戶提示 | 任務分類 | 路線 |
| 幫我編寫一個 Python 函數,將 Salesforce 數據加載到我的倉庫中。 | 代碼生成 | Llama Nemotron Super 49B |
| “請告訴我您的退貨政策。” | 開放問答 | Llama 3 70B |
| 重寫此用戶提示,使其更適合 LLM 代理。用戶提示:什么是最好的咖啡配方? | 重寫 | Llama 3 8B |
代碼生成任務是最復雜的,需要路由到推理 LLM。此 LLM 的成本相對較高,這是為了確保準確的響應。相比之下,“Rewrite the user prompt” 的用戶提示并不那么復雜,而是由更具成本效益的 LLM 準確回答。
自定義路由器
按照藍圖中的說明更改路由策略和 LLMs。默認情況下,該藍圖包含基于任務分類或復雜性分類的路由示例。 自定義模板 notebook 中展示了微調自定義分類模型的過程。
監控性能
按照藍圖負載測試演示中的說明 運行負載測試 。路由器捕獲可在 Grafana 控制面板中查看的指標。
多圈路由示例
LLM 路由器的關鍵功能之一是通過將每個新查詢發送到最佳 LLM 來處理多輪對話。這可確保以最佳方式處理每個請求,同時維護不同類型任務的上下文。示例概述如下。
用戶提示 1:
“ 農民需要將狼、山羊和卷心菜運過河。船只一次只能攜帶一件物品。如果獨自一人呆在一起,狼會吃掉山羊,而山羊會吃掉卷心菜。農民如何安全地將這三種物品運過河流?”
復雜度路由器 → 所選分類器:推理
- 第一個提示需要邏輯推理來分解經典謎題并確定正確的步驟。
- 響應建立了進一步探索所需的基礎理解。
用戶提示 2:
“ 使用圖論解決這個問題。將節點定義為有效狀態 (例如,FWGC-left) ,將邊緣定義為允許的船只移動。將解決方案形式化為最短路徑算法。”
復雜度路由器 → 所選分類器:領域知識
- 雖然本提示討論的問題與之前相同,但它需要一種不同的方法:應用圖論。
- 對話以先前的推理為基礎,但轉向結構化的數學框架。
- 響應通過將農民的動作形式化為狀態空間搜索來連接到第一個答案。
用戶提示 3:
分析解決方案中的第 2 步如何具體地防止第 4 步中提到的狼白菜沖突。使用原始步驟編號來追蹤這些操作之間的依賴關系。
復雜度路由器 → 所選分類器:約束
- 現在,用戶正在深入研究解決方案的特定部分,專注于約束分析。
- 此步驟與之前的響應直接關聯,可確保問題解決過程中的依賴項清晰明了。
- 此響應不會再次解決問題,而是驗證正確性和邏輯一致性。
用戶提示 4:
基于以上內容,寫一個科幻故事。
復雜度路由器 → 所選分類器:創造力
- 重點從結構化推理大幅轉移到創造性的敘事。
- 然而,在受限條件下運輸物品的上下文仍然存在,確保故事受到前面討論的邏輯問題的啟發。
- 這凸顯了 AI 如何在保持連續性的同時連接分析任務和富有想象力的任務。
用戶提示 5:
現在,請簡要總結一下以上內容。
任務路由器 → 所選分類器:總結
- 最后一步從整個討論中提取關鍵見解,將邏輯推理、數學建模、依賴追蹤和故事講述壓縮成簡短、連貫的摘要,并使用任務路由器而不是復雜性路由器。
- 這展示了 LLM 路由器如何確保所有響應在優化任務執行的同時保持上下文關聯。
通過使用不同的 LLM,LLM 路由器可讓每次對話由最合適的模型處理。
開始使用
通過為 LLM 路由器實施 NVIDIA AI Blueprint,企業組織能夠確保對特定用戶意圖的高性能和準確性響應,同時保持即插即用模型擴展的靈活性。與將所有請求路由到最復雜模型的基準方法相比,還可以節省成本。
總體而言,部署 LLM 路由器使 AI 團隊能夠:
- 降低成本:通過將簡單的任務與更小。
- 提升性能:將更復雜的查詢路由到最適合的模型,確保更高的準確性和效率。
- 無縫擴展 :無論您是需要開源模型、閉源模型,還是兩者兼而有之,該藍圖都能靈活地擴展和適應您組織的需求。
立即通過 NVIDIA Launchables 體驗此藍圖。在 NVIDIA-AI-Blueprints/llm-router GitHub 資源庫中查看完整的源代碼。如需詳細了解路由器分類模型,請閱讀 NVIDIA NeMo Curator Prompt Task 和 Complexity Classifier。
想要詳細了解 AI 智能體?查看這些 NVIDIA GTC 2025 代理式 AI 會話 。
?