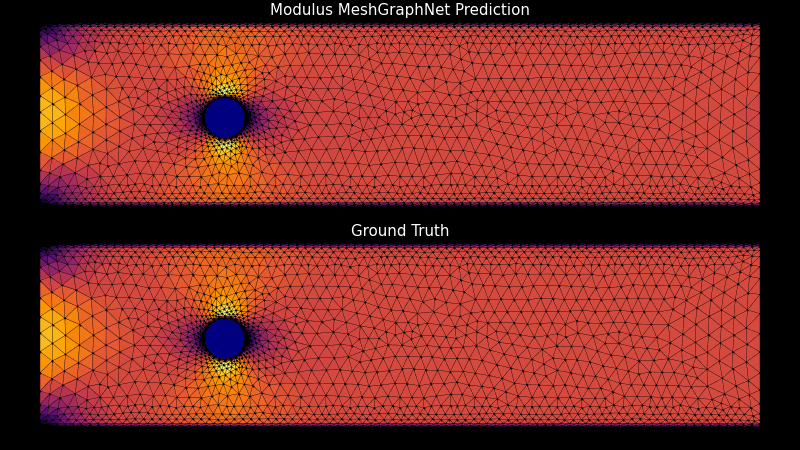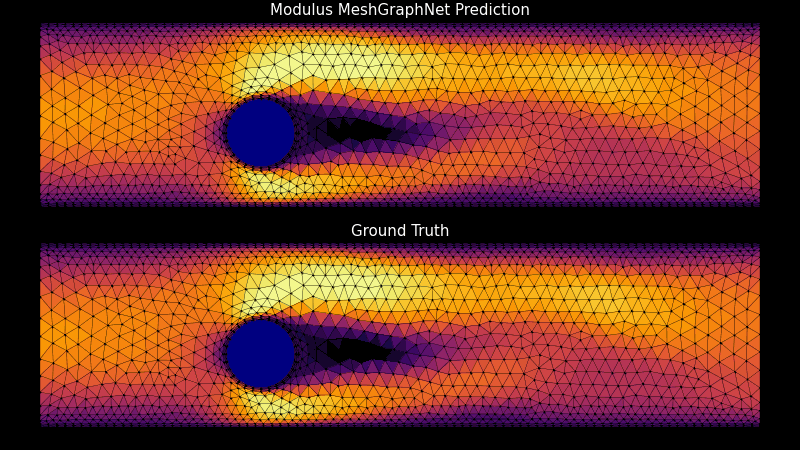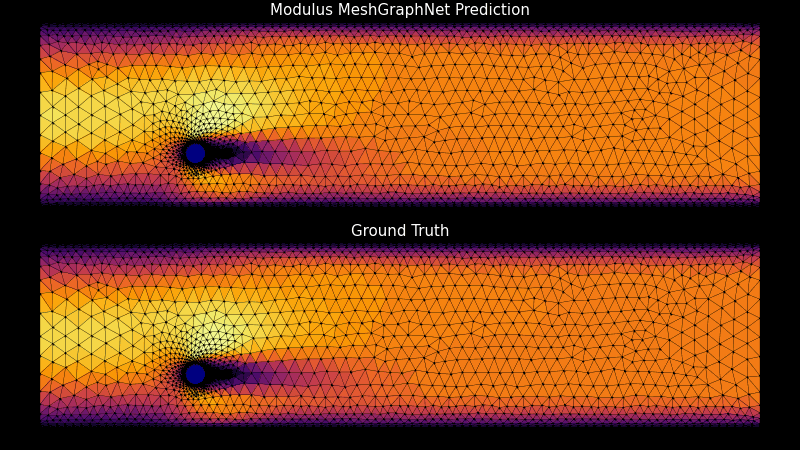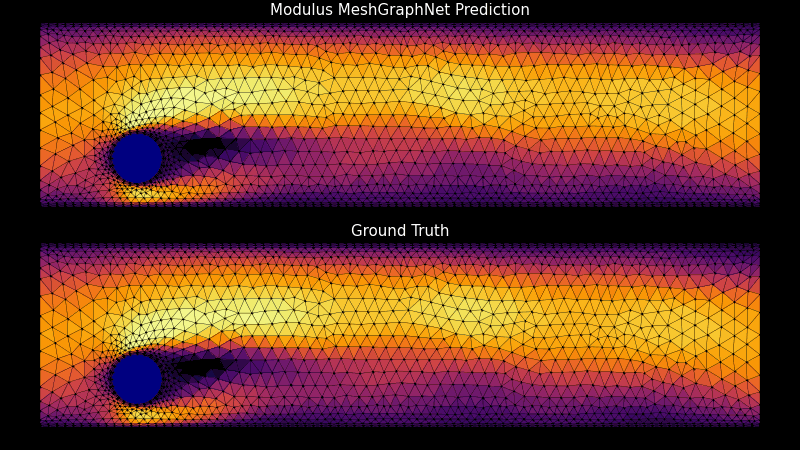
NVIDIA Base Command Platform 提供了自信地開發復雜軟件的能力,這些軟件符合科學計算工作流程所需的性能標準。該平臺為開發人員提供高效配置和管理人工智能工作流程所需的工具,從而為人工智能開發提供云托管和本地解決方案。集成的數據和用戶管理簡化了用戶和管理員的體驗。
現在,使用 NVIDIA PhysicsNeMo 和基本指揮平臺在團隊和地點之間創建高保真數字雙胞胎是 high-performance computing ( HPC )工作流可用的最新工具。對于從預測最優 airplane maintenance schedules 到 simulating wind farms 的許多用例來說,創建和使用數字雙胞胎對于節省時間和金錢至關重要。
開始使用這些用例可能會讓人望而卻步。然而,一個集成良好的解決方案會帶來所有的不同,并使開發人員能夠專注于解決問題。 Base Command Platform 只需點擊幾下即可實現 NGC 目錄軟件的全方位功能,并能夠創建強大的物理知情機器學習( physics ML )神經網絡和氣候模型。
利用 FourCastNet 進行氣候建模
FourCastNet 是開源 PhysicsNeMo 平臺的一部分,專注于以以前不可能的速度創建全球天氣預報。它依靠傅立葉神經算子和變換器在性能和分辨率上實現了這一令人難以置信的飛躍。 FourCastNet 現在與基本命令平臺兼容。
視頻1. 使用 FourCastNet 加速極端天氣預測
ERA5 dataset 是一個幾十年來整個地球的復雜天氣數據集,用于訓練和驗證這樣一個復雜的模型。 FourCastNet 是實現 NVIDIA Earth-2 數字孿生的關鍵技術。有關更多信息,請參閱 NVIDIA to Build Earth-2 Supercomputer to See Our Future 。
PhysicsNeMo 團隊一直在尋求提高 FourCastNet 的性能,最近更新了它,使用 NVIDIA Data Loading Library ( DALI )將數據攝入 GPU ,進一步加快了洞察時間。
在基本指揮平臺上使用 PhysicsNeMo 提高可擴展性
當在一個可以擴展到幾個基于 GPU 的系統的環境中運行時, PhysicsNeMo 的全部功能就會釋放出來。沒有比基本命令平臺更好的方法來運行像 PhysicsNeMo 這樣的高度可擴展平臺來訓練像 FourCastNet 這樣的大型模型。
為了運行這些示例,我們將稍微修改過的 PhysicsNeMo NGC container 版本上傳到了一個基本指揮平臺組織,該組織可以訪問由 NVIDIA DGX A100 系統組成的加速計算環境。我們將 1TB 的 ERA5 數據集上傳到同一環境中的工作空間。
為了支持協調的多實例工作負載, Base Command Platform 集成了一個名為 bcprun 的工具。bcprun通過抽象機器學習( ML )從業者的復雜性并消除工作負載容器(如mpirun)中對額外軟件的需求,簡化了多實例工作負載部署。它還為最初為 HPC 調度器(如 Slurm )編寫的應用程序提供了一個更容易的入門路徑。
以下代碼示例顯示了 FourCastNet 在 Base Command Platform 上的單實例作業啟動:
ngc batch run \
--name "bcp-dali.fcn.training.ml-model.modulus" \
--total-runtime 12H \
--org org-name \
--ace ace-name \
--instance dgxa100.80g.8.norm \
--workspace ERA5_test_21Vars:/era5/ngc_era5_data/:RO \
--result /results \
--image "nvcr.io/org-name/team-name/modulus:22.09-examples_0.4" \
--commandline "\
set -x && \
cd /examples/fourcastnet/ && \
ln -s /era5/stats . && \
python fcn_era5.py \
custom.train_dataset.kind=dali \
custom.num_workers.grid=1 \
training.max_steps=50000 \
training.print_stats_freq=500 \
network_dir=/results/network_checkpoint
"要擴展到兩個 NVIDIA DGX A100 八個 GPU 實例(共 16 個),請使用以下命令(在 bold 中突出顯示更改):
ngc batch run \
--name "bcp-dali.fcn.training.ml-model.modulus" \
--total-runtime 12H \
--org org-name \
--ace ace-name \
--replicas "2" \
--array-type "PYTORCH" \
--instance dgxa100.80g.8.norm \
--workspace ERA5_test_21Vars:/era5/ngc_era5_data/:RO \
--result /results \
--image "nvcr.io/org-name/team-name/modulus:22.09-examples_0.4" \
--commandline "\
set -x && \
cd /examples/fourcastnet/ && \
mkdir -p /results/network_checkpoint && \
ln -s /era5/stats . && \
bcprun --nnodes \$NGC_ARRAY_SIZE \
--npernode \$NGC_GPUS_PER_NODE \
--cmd '\
python fcn_era5.py \
custom.train_dataset.kind=dali \
custom.num_workers.grid=1 \
training.max_steps=50000 \
training.print_stats_freq=500 \
network_dir=/results/network_checkpoint
'
"bcprun的添加以及添加的參數確保指定的命令(來自--cmd參數)在為作業創建的每個副本上運行(如--replicas和--nnodes參數所指定)。--npernode參數確保在每個實例上為該實例中的每個 GPU 運行一個進程。這導致此作業總共啟動了 16 個進程(每個復制副本中有 8 個,總共兩個復制副本)。要擴展到使用四個實例,請將--replicas參數設置為四個而不是兩個。
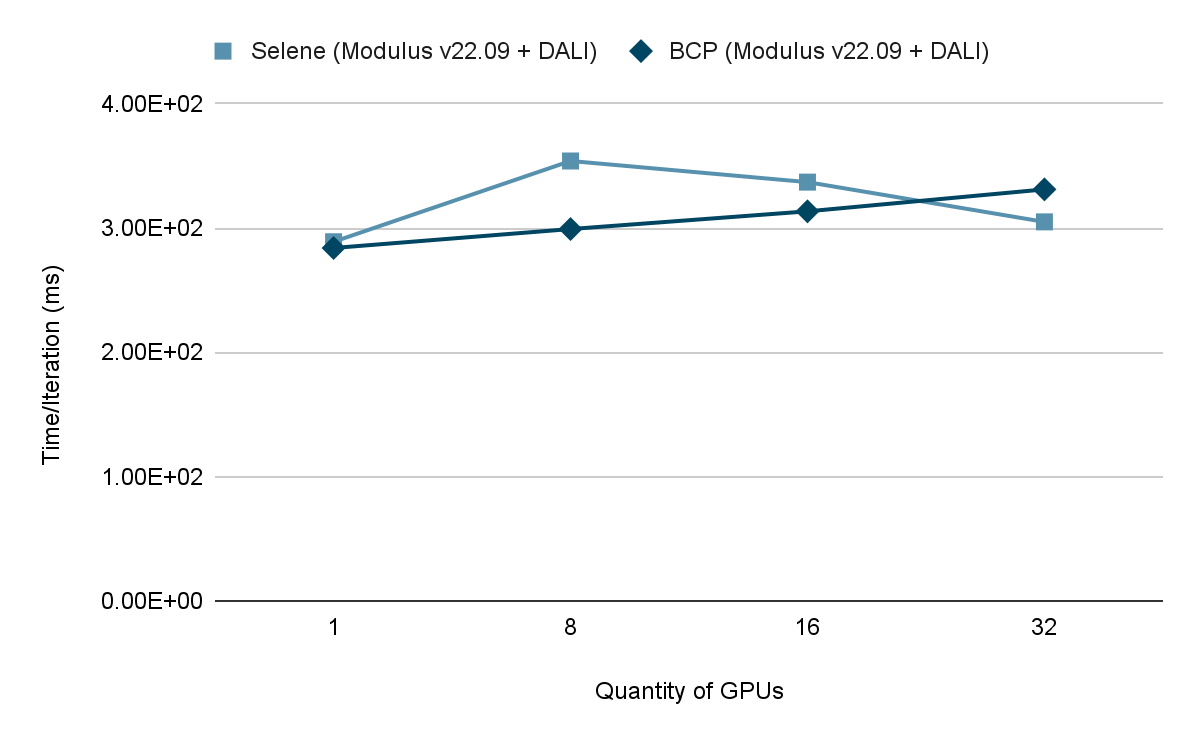
基本命令平臺不僅為 ML 從業者和管理員提供了易用性,而且證明了已經實現了最高性能。 NVIDIA Selene supercomputer 與 PhysicsNeMo 運行 FourCastNet 訓練進行比較。
在 Selene 上測試了工作負載后,我們在基本指揮平臺部署上無縫復制了工作負載,并在兩個環境之間獲得了幾乎相同的結果。這一結果有力地證明,基本指揮平臺可以支持企業和科學計算用例中客戶最苛刻的性能要求。
對開發者 Kaustubh Tangsali 的采訪
為了了解更多關于在 Base Command Platform 上使用 NVIDIA PhysicsNeMo 的經驗,我們采訪了 PhysicsNeMo 團隊的開發人員 Kaustubh Tangsali 。 Kaustubh 領導了在基本指揮平臺上運行 FourCastNet 和其他幾個軟件示例的調查。
簡要描述您的行業背景和經驗。
我主要在軟件行業工作,應用于模擬和計算流體動力學。我致力于 PhysicsNeMo 平臺的開發,這是一個領域專家和人工智能從業者開發物理 ML 模型的框架。我曾與 NVIDIA Thermal 團隊等內部合作伙伴密切合作,使用 PhysicsNeMo 設計散熱器,還與幾個外部合作伙伴合作,使用 PhysicsNeMo 加快工作流程。
您在基礎指揮平臺上使用 PhysicsNeMo 工作了多長時間?
自 2020 年年中以來,我一直在基地指揮平臺上使用 PhysicsNeMo 。
在基地指揮平臺上,日常使用是什么樣子的?您的開發周期是什么樣子的?
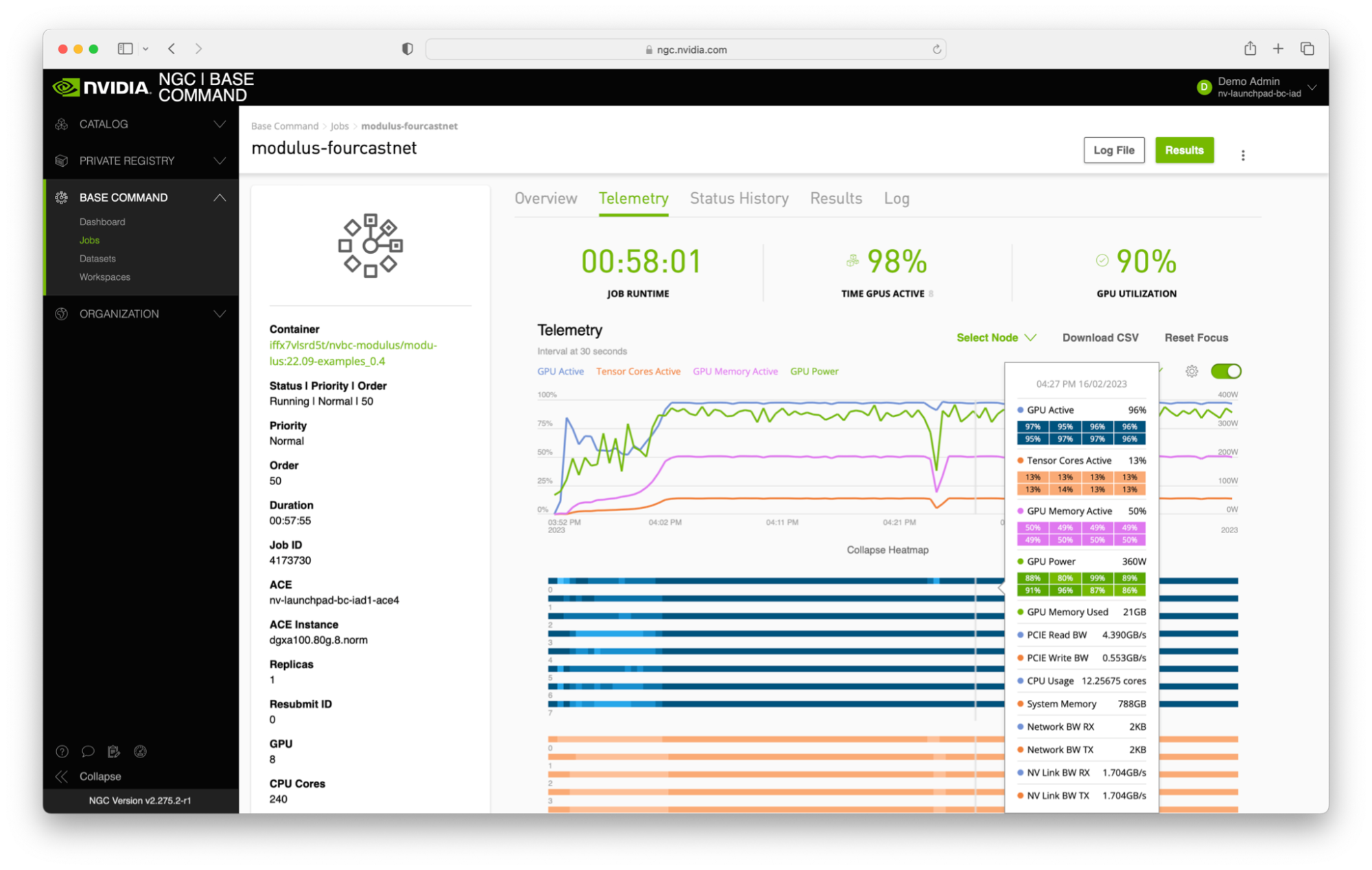
在我對代碼或模型進行了一些本地測試后,我通常會將代碼安裝在基本命令平臺工作區中,然后使用 NGC web 界面或僅使用命令行界面( CLI )啟動作業。 Jupyter 接口非常適合早期調試。當模型運行到完成時,我下載檢查點和結果以進行進一步分析。在運行時,我還使用日志功能和遙測技術來監視作業的狀態。
基本指揮平臺環境與您使用過的其他環境相比如何?
基本指揮平臺的 web 界面是我覺得有用的東西。監視作業、查看用于啟動作業的命令、克隆作業以及使用不同的實例類型等功能都很容易。我認為獲得最新和最好的 NVIDIA 硬件是一大優勢。
對于剛開始使用基地指揮平臺的人,你有什么建議嗎?
NVIDIA Base Command Platform User Guide 有很好的文檔記錄,涵蓋了數據科學家可能遇到的許多常見用例,包括單 GPU 、多[Z1K1’和多實例作業的命令示例。正如我前面提到的,在擴展作業之前,我喜歡在開發的早期階段利用運行作業的交互式特性,CLI會對其進行優化。
總結
NVIDIA PhysicsNeMo 等尖端數字孿生技術依靠強大的計算環境不斷進步。基本指揮平臺在一組易于使用的界面中利用 NVIDIA GPU 的強大功能,繼續 NVIDIA 的使命,即讓高級軟件功能廣泛可訪問,以解決重要問題。有關更多信息,請參閱 Simplifying AI Development with NVIDIA Base Command Platform 。
通過 NVIDIA LaunchPad for PhysicsNeMo 中的短期訪問開啟您的推理之旅。沒有必要設置自己的環境。
有關 NVIDIA PhysicsNeMo 的更多信息,請參閱 NVIDIA 深度學習研究所課程 Introduction to Physics-Informed Machine Learning with PhysicsNeMo 。
要獲取最新版本的詳細信息,請訪問 download and try NVIDIA PhysicsNeMo 。
Register for NVIDIA GTC 2023 for free 并參加 Enterprises Share Their Experience with DGX Cloud 會議,了解由基本指揮平臺提供支持的廣泛用例。
?
?