
準確、快速的目標檢測是機器人導航和避碰的重要任務。自主代理需要一張清晰的周圍地圖,才能導航到目的地,同時避免碰撞。例如,在使用自主移動機器人( AMR )運輸物品的倉庫中,避免可能損壞機器人的危險機器已成為一個具有挑戰性的問題。
本文介紹了一個 ROS 2 節點,用于使用基于 PointPillars 的 NVIDIA TAO Toolkit 預處理模型檢測點云中的對象。該節點將點云作為真實或模擬激光雷達掃描的輸入,執行 TensorRT 優化推斷以檢測該輸入數據中的對象,并將生成的 3D 邊界框作為每個點云的 Detection3DArray 消息輸出。
雖然存在多個 ROS 節點用于從圖像中檢測目標,但從激光雷達輸入執行目標檢測的優點包括:
- 激光雷達可以同時計算到許多被探測物體的精確距離。利用激光雷達直接提供的目標距離和方向信息,可以獲得精確的環境三維地圖。為了在基于相機/圖像的系統中獲得相同的信息,需要單獨的距離估計過程,這需要更多的計算能力。
- 與相機不同,激光雷達對不斷變化的光照條件(包括陰影和強光)不敏感。
通過使用激光雷達和相機的組合,可以使自主系統更加穩健。這是因為攝像機可以執行激光雷達無法執行的任務,例如檢測標志上的文字。
TAO PointPillars 基于論文 PointPillars: Fast Encoders for Object Detection from Point Clouds 中的工作,該論文描述了一個編碼器,用于從垂直列(或柱)中組織的點云中學習特征。 TAO PointPillars 既使用了編碼特征,也使用了本文描述的下游檢測網絡。
在我們的工作中,根據 Zvision 的固態激光雷達采集的點云數據集訓練了 PointPillar 模型。 The PointPillar model 檢測三類物體:車輛、行人和自行車手。您可以按照 TAO Toolkit 3D Object Detection 步驟訓練自己的檢測模型,并將其用于此節點。
有關運行節點的詳細信息,請訪問 GitHub 上的 NVIDIA-AI-IOT/ros2_tao_pointpillars 。您還可以查看 NVIDIA Isaac ROS ,了解 NVIDIA 為各種感知任務提供的更多硬件加速 ROS 2 軟件包。
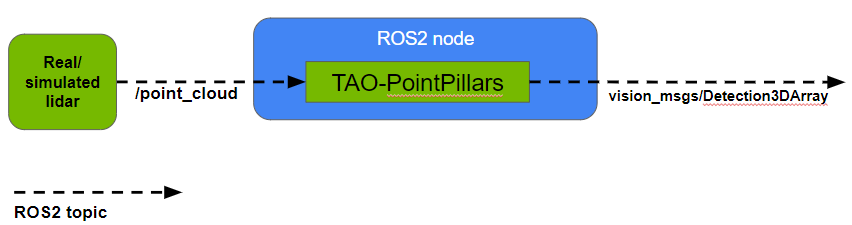
ROS 2 TAO PointPillars 節點
本節提供有關在機器人應用程序中使用 ROS 2 TAO PointPillars 節點的更多詳細信息,包括輸入/輸出格式以及如何可視化結果。
Node Input: 節點以 PointCloud2 消息格式將點云作為輸入。除其他信息外,點云必須包含每個點( x 、 y 、 z 、 r )的四個特征,其中( x 、 y 、 z 、 r )分別表示 x 坐標、 y 坐標、 z 坐標和反射率(強度)。
反射率表示激光束在 3D 空間某一點反射回來的分數。請注意,在訓練數據和推斷數據中,反射率值的范圍應相同。可以從節點的啟動文件中設置強度范圍、類名、 NMS IOU 閾值等參數。
您可以訪問 GitHub 上的 ZVISION-lidar/zvision_ugv_data ,找到用于測試節點的 ROS 2 包。
?

Node Output: 節點以 Detection3DArray 消息格式輸出點云中檢測到的每個對象的 3D 邊界框信息、對象類 ID 和分數。每個 3D 邊界框用( x , y , z , dx , dy , dz , yaw )表示,其中( x , y , z , dx , dy 、 dz , haw )分別是對象中心的 x 坐標、對象中心的 y 坐標、對象中央的 z 坐標、長度( x 方向)、寬度( y 方向)、高度( z 方向)和 3D 歐氏空間中的方向。
對于有意義的結果,模型在訓練期間使用的坐標系和輸入數據在推理期間使用的座標系必須相同。圖 3 顯示了 TAO PointPillars 模型使用的坐標系。

由于 Detection3DArray 消息目前無法在 RViz 上可視化,因此您可以通過訪問 GitHub 上的 NVIDIA-AI-IOT/viz_3Dbbox_ros2_pointpillars 找到一個簡單的工具來可視化結果。
對于下圖 4 所示的示例, Jetson AGX Orin 上輸入點云的頻率為~ 10 FPS ,輸出 Detection3DArray 消息的頻率為~ 10 FPS 。

總結
實時準確的目標檢測是自治主體安全導航環境所必需的。本文展示了一個 ROS2 節點,它可以使用預處理的 TAO PointPillars 模型檢測點云中的對象。(請注意,該模型的 TensorRT 引擎目前僅支持一個批次大小。)該模型直接對激光雷達輸入進行推斷,這與使用基于圖像的方法相比具有優勢。為了對激光雷達數據進行推斷,必須使用根據同一激光雷達數據訓練的模型。否則,除非采用統計歸一化等方法,否則準確度將大幅下降。
?





