生成式 AI 在計算領域發生了翻身,為人類以自然、直觀的方式與計算機交互打開了新方式。對于企業來說,生成式 AI 的潛力巨大。他們可以利用其豐富的數據集簡化耗時的任務,從文本摘要和翻譯到見解預測和內容生成。然而,他們也面臨著采用挑戰。
例如,云服務通過使用通用型 大型語言模型 簡化了探索。然而,這些功能可能并不總是與企業需求保持一致,因為模型基于廣泛的數據集而不是特定領域的數據進行訓練,這可能會導致安全漏洞。
因此,組織正在使用大量開源工具構建定制解決方案。從驗證兼容性到提供自己的技術支持,這可以延長在企業中成功采用生成式 AI 的時間。
專為企業開發,NVIDIA NeMo 是一個端到端平臺,可隨時隨地構建自定義生成式 AI 應用。它提供了一套先進的微服務,可實現完整的工作流程,從自動化分布式數據處理,到使用復雜的 3D 并行技術訓練大規模定制模型,再到使用 檢索增強生成(RAG) 技術。
使用 NeMo 創建的自定義生成式 AI 模型可以部署在 NVIDIA NIM 上,它是一套易于使用的微服務,旨在隨時隨地 (本地或云端) 加速生成式 AI 部署。NVIDIA NIM 提供優化的推理,以在微服務中部署 AI 模型。
對于在 AI 上運營業務的企業來說,NVIDIA AI Enterprise 是一款端到端軟件平臺,可為生成式 AI 基礎模型提供更快速、更高效的運行時。它包含 NeMo 和 NIM,可簡化采用流程,并提供安全性、穩定性、可管理性和企業級支持。
現在,組織可以將 AI 集成到其運營中,簡化流程,增強決策能力,并推動實現更高的價值。
借助 NVIDIA NeMo 實現生產就緒型生成式 AI
NeMo 通過提供端到端功能 (微服務) 以及適用于各種模型架構的方法,簡化了構建自定義企業級生成式 AI 模型的路徑 (圖 1)。
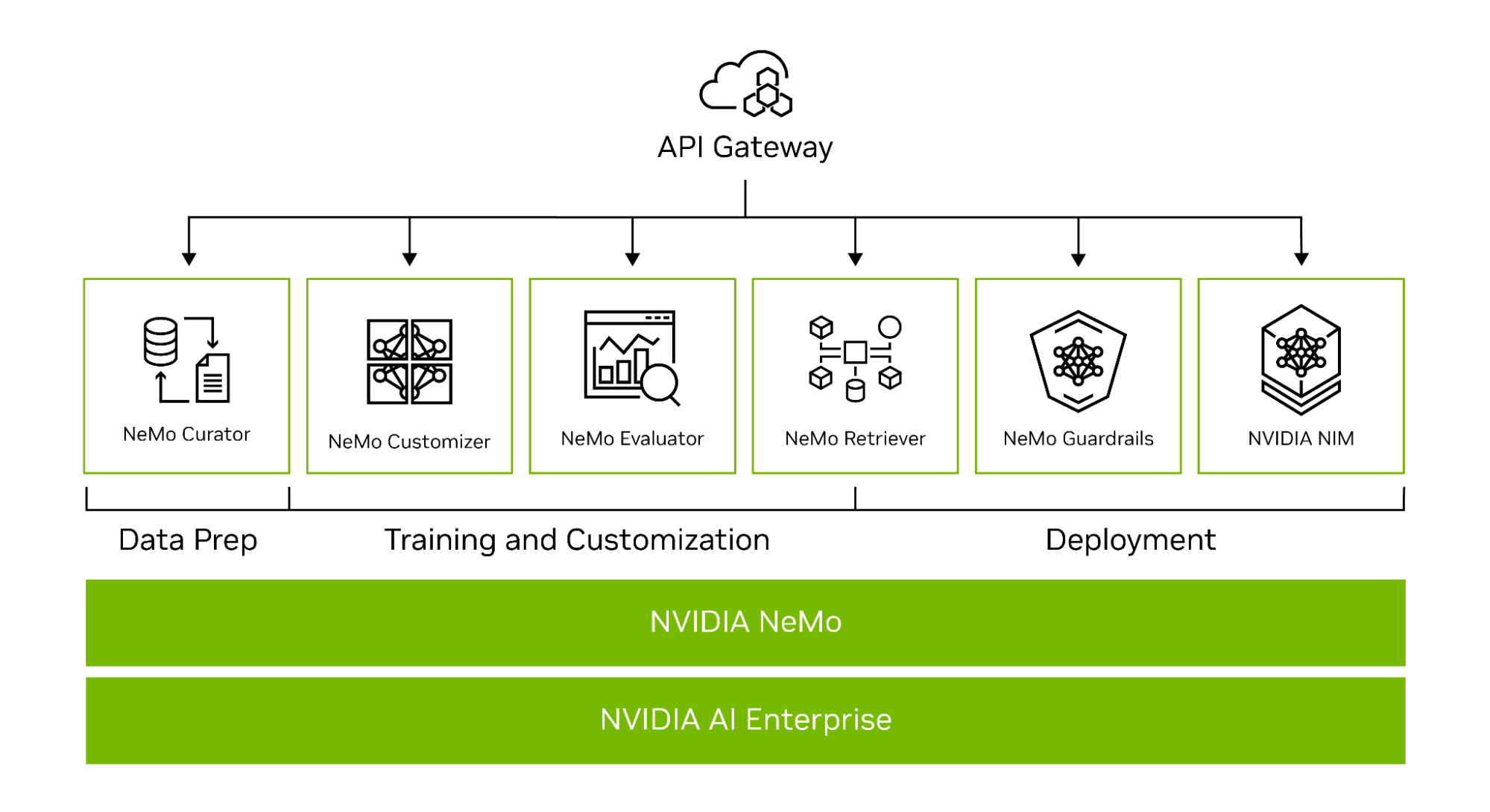
為幫助您創建自定義 LLM,NeMo 框架提供了功能強大的工具:
- NeMo Curator 提供 GPU 加速的高質量訓練數據集數據管護功能。
- NVIDIA NeMo 定制器 簡化了 LLM 的微調和對齊過程。
- NVIDIA NeMo Evaluator 提供了自動評估 LLM 準確性的功能。
- NeMo Retriever 利用 RAG 將自定義模型與專有業務數據聯系起來。
- NeMo 護欄 可保護組織的生成式 AI 應用。
NeMo 策展人
對高質量數據集的需求已成為構建功能性 LLM 的關鍵因素。
NeMo 利用 NVIDIA NeMo Curator 簡化了通常復雜的 datasets 管護流程。此工具可解決多語種數據集中管護數萬億令牌的挑戰。它提供了可擴展性,使您能夠輕松處理數據下載、文本提取、清理、過濾、精確或模糊重復數據消除以及多語種下游任務消除污染等任務。有關詳細信息,請參閱 使用 NeMo Curator 擴展和整理用于 LLM 訓練的高質量數據集。
利用 Dask、RAPIDS cuDF、RAPIDS cuGraph 和 PyTorch 等尖端技術的強大功能,NeMo Curator 可以跨數千個網絡 GPU 擴展數據管護流程,從而顯著減少手動工作并加速開發工作流程。
其中一個最顯著的進步是在數據刪除重復數據的過程中,事實證明 GPU 加速的性能明顯優于傳統的 CPU 方法。與依賴基于 CPU 的方法相比,使用 GPU 進行重復數據刪除的速度提高了 26 倍,成本降低了 6.5 倍。這種顯著的改進不僅降低成本,而且還提高了效率,使開發者能夠以前所未有的速度處理數據。
NVIDIA 技術具有無與倫比的可擴展性,能夠利用數千個 GPU.這種可擴展性對于在真實的時間框架內準備大型預訓練數據集至關重要,隨著 AI 模型的復雜性和規模的增長,這項任務變得越來越重要。
在性能方面,使用 NeMo Curator 準備的令牌進行訓練時,LLM 受益匪淺。此工具可確保輸入 LLM 的數據具有最高質量,從而生成性能更好的模型。
在不久的將來,NeMo Curator 還將支持模型自定義的數據管護,例如監督式微調 (SFT),以及包括 LoRA 和 P-tuning 在內的參數高效微調 (PEFT) 方法。
申請搶先體驗 NVIDIA NeMo 微服務 獲取最新的 NeMo Curator 微服務。它還包含在 NeMo 框架容器 可通過 NVIDIA NGC 目錄獲取。
大規模分布式訓練
訓練具有十億參數的 LLM 時,存在加速和擴展的獨特挑戰。這項任務需要廣泛的分布式計算能力、基于加速的硬件和內存集群、可靠且可擴展的機器學習 (ML) 框架和容錯系統。
NeMo 框架的核心是統一分布式訓練和高級并行。NeMo 熟練地跨節點使用 GPU 資源和內存,從而實現突破性的效率提升。通過除以模型和訓練數據,NeMo 實現了無縫的多節點和多 GPU 訓練,顯著減少訓練時間并提高整體生產力。
并行技術
NeMo 的一個顯著特點是整合了各種并行技術:
- 數據并行
- 完全分片數據并行 (FSDP)
- 張量并行度
- 管道并行
- 序列并行
- 專家并行
- 上下文并行
節省內存技術
此外,NeMo 還支持多種節省內存的方法:
- 選擇性激活重計算 (SAR)
- CPU 卸載 (激活、權重)
- Flash Attention (FA)、Grouped Query Attention (GQA)、Multi-Query Attention (MQA)、Sliding Window Attention (SWA)
NeMo 支持大規模多模態訓練,包括語言和多模態模型。支持的模型包括 Lama 2、Falcon、CLIP、Stable Diffusion、LLAVA,以及各種基于文本的生成式 AI 架構,例如 GPT、T5、BERT、多專家模型 (MoE) 和復古 (RETRO)。除了 LLM 之外,NeMo 還支持多個預訓練模型,包括計算機視覺、自動語音識別和自然語言處理。例如,text-to-speech 等。
NVIDIA NGC 目錄中的 NeMo 框架容器 提供所有工具,供組織自行訓練模型。
NVIDIA AI 基礎模型
盡管一些生成式 AI 應用需要從頭開始訓練 LLM,但大多數組織都使用 預訓練模型 來構建自定義 LLM。這種方法可以快速啟動該過程,從而節省時間和資源。
跳過用于從頭開始訓練 LLM 的龐大數據集所需的數據收集和清理階段,您可以專注于使用更小的數據集來根據自己的需求微調模型。這縮短了找到最終解決方案的時間。此外,預訓練模型帶有預先存在的知識,可隨時進行定制,從而大大降低基礎設施設置和模型訓練的負擔。
準確性是用于評估預訓練模型的常見測量方法之一,但還有其他考慮因素,包括模型大小、微調成本、延遲、吞吐量和商業許可選項。
NVIDIA 幫助開發者更輕松地實現出色性能,并簡化向生產級 AI 的過渡。NVIDIA AI 基礎模型 提供了加速基礎架構的必要工具。
NVIDIA AI Foundation 模型包括針對性能優化的領先社區模型和基于責任來源數據構建的企業級 NVIDIA 模型。
NVIDIA TensorRT-LLM 可以優化 NVIDIA AI Foundation 模型的延遲和吞吐量,以提供更高的性能。它使用負責任的來源數據進行訓練,以確保模型提供與大型模型相媲美的結果。這意味著它成為企業應用的理想選擇。
這些模型經過格式化,可利用 NeMo 自定義和并行技術,并利用專有數據加快調整速度。
新推出的 NVIDIA API 目錄 開發者可以使用 NVIDIA 托管的 API 端點,在瀏覽器或原型中直接體驗這些模型。準備好自我部署后,可以下載基礎模型,并在任何 GPU 加速的數據中心、云或工作站上運行。
NeMo 定制器
各行各業的企業都需要獨特的功能,而生成式 AI 模型定制也在不斷發展,以滿足其需求。NeMo 提供各種 大語言模型定制技術,以專業用例優化通用的預訓練 LLM。NVIDAI NeMo Customizer 是一種新的高性能、可擴展的微服務,可幫助開發者簡化 LLM 的微調和比對。
NeMo Customizer 將一系列先進功能引入機器學習模型開發的前沿。其突出的功能之一是支持先進的微調和比對技術,使用戶能夠根據特定需求精確調整模型,從而實現出色的模型性能。
NeMo Customizer 利用先進的并行技術,不僅提高了訓練性能,而且大大縮短了訓練復雜模型所需的時間。在當今速度和效率至關重要的快節奏開發環境中,這一點尤其有益。
NeMo Customizer 旨在通過跨多個 GPU 和多個節點進行擴展來支持大型模型的微調,從而解決深度學習領域的一項重大挑戰。
這種可擴展性確保即使是要求非常嚴格的模型也能得到有效訓練,從而使 NeMo Customizer 成為研究人員和從業者的寶貴工具。更多信息請參閱 NVIDIA NeMo Customizer:輕松微調和對齊 LLM。
組織可以申請搶先體驗 NVIDIA NeMo 微服務,并開始使用 NeMo Customizer 微服務。開發者可以使用 NGC 目錄中的 NeMo 框架容器 進行獲取。
NeMo 評估器
隨著組織越來越多地定制 LLM 以滿足其獨特的運營需求,因此出現了持續評估和優化這些模型的關鍵需求,以確保這些模型提供更高水平的準確性和響應速度。
這種持續的評估過程至關重要,不僅可以在最初訓練的任務中保持模型的性能,而且可以確保模型有效適應新的應用程序特定要求。
NeMo Evaluator 通過自動基準測試功能簡化了這項復雜任務,從而能夠全面評估預訓練和微調的 LLM.此工具支持各種模型,包括基礎模型、對齊模型和任務特定的 LLM 等,可為各種應用提供通用的評估功能。
該微服務提供開放式可擴展的設計,并支持根據流行的學術基準測試和自定義數據集評估模型。NeMo Evaluator 的目的是確保在云或數據中心本地運行的 LLM 的效率和靈活性。有關更多詳細信息,請參閱 NVIDIA NeMo Evaluator:簡化 LLM 的準確性評估。
NeMo Evaluator 擴展了 NeMo Curator 和 NeMo Customizer 的功能,為組織構建自定義生成式 AI 模型提供一整套工具。申請搶先體驗 NVIDIA NeMo 微服務。
NeMo Retriever
NeMo Retriever 是一個微服務集合,可加速企業數據的語義搜索。它通過檢索增強提供高度準確的響應。有關更多詳細信息,請參閱 使用 NVIDIA NeMo Retriever 將企業數據轉換為可行見解。
這些微服務專為處理特定任務而定制,包括:
- 以 PDF 文件、Office 文檔和其他富文本文件的形式提取大量文檔。
- 對這些文檔進行編碼和存儲,以進行語義搜索。
- 與現有關系數據庫交互。
- 搜索相關信息以回答問題。
借助 NeMo Retriever,組織可以以更低的延遲、更高的吞吐量和更大的數據隱私來訪問出色的信息檢索功能,從而更好地利用專有數據實時生成業務見解。
立即開始在 NVIDIA Omniverse 中使用 NeMo Retriever 微服務,以從 NVIDIA API 目錄 探索更多示例。有關更多信息,請查看 NVIDIA 生成式 AI 示例 和代碼示例。
NeMo 護欄
在生成式 AI 迅速發展的格局中,實施穩健的安全措施的重要性無論怎么強調都不過分。隨著這些 AI 應用程序越來越多地集成到各行各業中,確保其安全可靠的運行至關重要。
在這方面,護欄是一種重要機制,可作為調節用戶與 LLM 之間交互的可編程約束或規則。與高速公路上的物理護欄防止車輛偏離軌道的方式類似,這些數字護欄旨在監控、影響和控制用戶與 AI 系統的交互。
它們有助于將 AI 交互的焦點保持在預定邊界內,防止產生幻覺、劇毒或誤導性內容,并阻止惡意命令或未經授權訪問第三方應用程序。這種制勝系統對于在各個領域維護生成式 AI 應用程序的完整性和安全性至關重要。
NeMo Guardrails?通過提供復雜的對話管理系統來應對這些挑戰,該系統優先考慮由 LLM 提供支持的應用程序的準確性、適當性和安全性。它為組織提供有效執行安全和安保協議所需的工具,以確保其 AI 系統在所需參數內運行。
NeMo Guardrails 有助于輕松編程和實施這些安全措施,提供模糊可編程的護欄,從而實現靈活且可控的用戶交互。其與企業就緒型解決方案 (包括 Langchain 和其他第三方應用程序) 的集成功能增強了 LLM 系統的安全性,以抵御潛在威脅。
通過與更廣泛的 LLM 生態系統深度集成并支持流行框架,NeMo Guardrails 可確保生成式 AI 應用始終安全可靠,并與組織的價值觀、策略和目標保持一致。有關更多詳細信息,請參閱 NVIDIA 實現值得信賴、安全可靠的大型語言模型對話系統。
NeMo Guardrails 是一個開源工具包,可輕松開發與所有 LLM(包括 OpenAI 的聊天 GPT 和 NVIDIA NeMo)兼容的安全可靠的 LLM 對話系統。要開始使用,請訪問 NVIDIA/NeMo-Guardrails 在 GitHub 上的發布頁面。
NVIDIA NIM
為支持生產環境中的 AI 推理,基礎設施和支持系統必須穩健、可擴展且高效,以促進過渡。各組織現已認識到需要投資和開發此類基礎設施,以保持競爭力并充分利用生成式 AI 的全部潛力。
NVIDIA NIM 推理微服務簡化了在企業環境中部署優化的生成式 AI 模型的流程。NIM 支持廣泛的 AI 模型,包括開源社區模型、NVIDIA AI 基礎模型和自定義 AI 模型。有關更多詳細信息,請參閱 NVIDIA NIM 提供經過優化的推理微服務,以大規模部署 AI 模型。
利用行業標準 API,開發者只需幾行代碼即可快速構建企業級 AI 應用。基于可靠的基礎構建,包括開源推理引擎,例如 NVIDIA Triton Inference Server 和 NVIDIA TensorRT-LLM,以及 PyTorch、NIM 可促進大規模 AI 推理,確保可以大規模部署 AI 應用程序,并滿懷信心地投入生產。
要開始使用 NIM,請探索 NVIDIA API 目錄。
實現無縫的企業級生成式 AI
作為 NVIDIA AI Enterprise 的 NeMo 提供跨多個平臺的兼容性,包括云、數據中心,以及現在由 NVIDIA RTX 提供支持的工作站和 PC。這實現了真正的“一次開發”和“隨處部署”體驗,消除了集成的復雜性,并更大限度地提高了運營效率。
行業 AI 采用者
NeMo 在尋求構建自定義 LLM 的前瞻性組織中獲得了巨大的吸引力。ServiceNow、Amdocs、Dropbox、Writer 和韓國電信等組織已采用 NeMo,以利用其功能推動其 AI 驅動的計劃。
憑借出色的靈活性和支持,NeMo 開啟了一個充滿可能性的世界。企業可以設計、訓練和部署針對特定需求和行業垂直領域定制的復雜 LLM 解決方案。通過利用 NVIDIA AI Enterprise 并將 NeMo 集成到您的工作流程中,您的組織可以開辟新的發展道路,獲得寶貴的見解,并為客戶、客戶和員工等提供先進的 AI 應用程序。
開始使用 NVIDIA NeMo
作為一款顛覆性解決方案, NVIDIA NeMo 正在彌合生成式 AI 的巨大潛力與企業面臨的實際現實之間的差距。作為用于 LLM 開發和部署的綜合平臺,NeMo 幫助企業以經濟高效的方式采用 AI 技術。
借助 NVIDIA NeMo 的強大功能,企業可以將 AI 集成到運營中,簡化流程,增強決策能力,并開辟發展和成功的新途徑。
要開始使用 NVIDIA NeMo,請訪問 NVIDIA NeMo 頁面。要使用 NVIDIA NeMo 微服務,請 申請搶先體驗。您也可以在 NVIDIA NGC 目錄中獲取 NeMo 框架容器。
?






