將 ML 模型部署到生產環境的方法有很多。有時,模型每天運行一次,以更新數據庫中的預測。有時,它為移動設備上的小型但關鍵的決策控制面板或語音轉文本提供支持。如今,該模型也可以是自定義的大型語言模型 (LLM),支持新的 AI 驅動的產品體驗。
通常情況下,模型通過帶有微服務的 API 端點暴露在其環境中,從而能夠實時查詢模型。雖然這聽起來很簡單,但由于通常有大量用于構建和部署微服務的框架,因此在嚴格的生產環境中服務模型并非易事。
請考慮以下典型挑戰(表 1)。
| 模型訓練 | 您能否在沒有人工干預的情況下持續訓練和部署模型? | 您能否輕松開發新模型、在本地測試部署并自信地進行實驗? | 您能否在開發和部署期間持續管理功能? |
| 模型部署 | 部署能否處理您想使用的各種類型的模型? | 模型能否快速生成響應,以支持所需的產品體驗? | 如果響應不佳,會出現什么情況?您能否追蹤血脈和生成血脈的模型? |
| 基礎架構 | 部署是否高度可用,足以支持 SLA 目標? | 部署是否高效使用硬件資源? | 能否輕松監控請求和響應? |
| 部署是否與您現有的基礎架構和策略集成? | 您能否以經濟高效的方式部署模型? | 部署能否擴展到每秒足夠的請求? | |
| 基礎架構是否提供對敏感數據集和模型的安全訪問? | 基礎架構是否可以擴展以滿足計算需求?不使用時,成本是否為零? | 用戶能否調整性能旋鈕(例如 GPU 卡的類型和數量)以降低 TCO? |
從原型設計到生產
為全面應對這些挑戰,請考慮 ML 系統從開發的早期階段到部署(及后續)的整個生命周期。
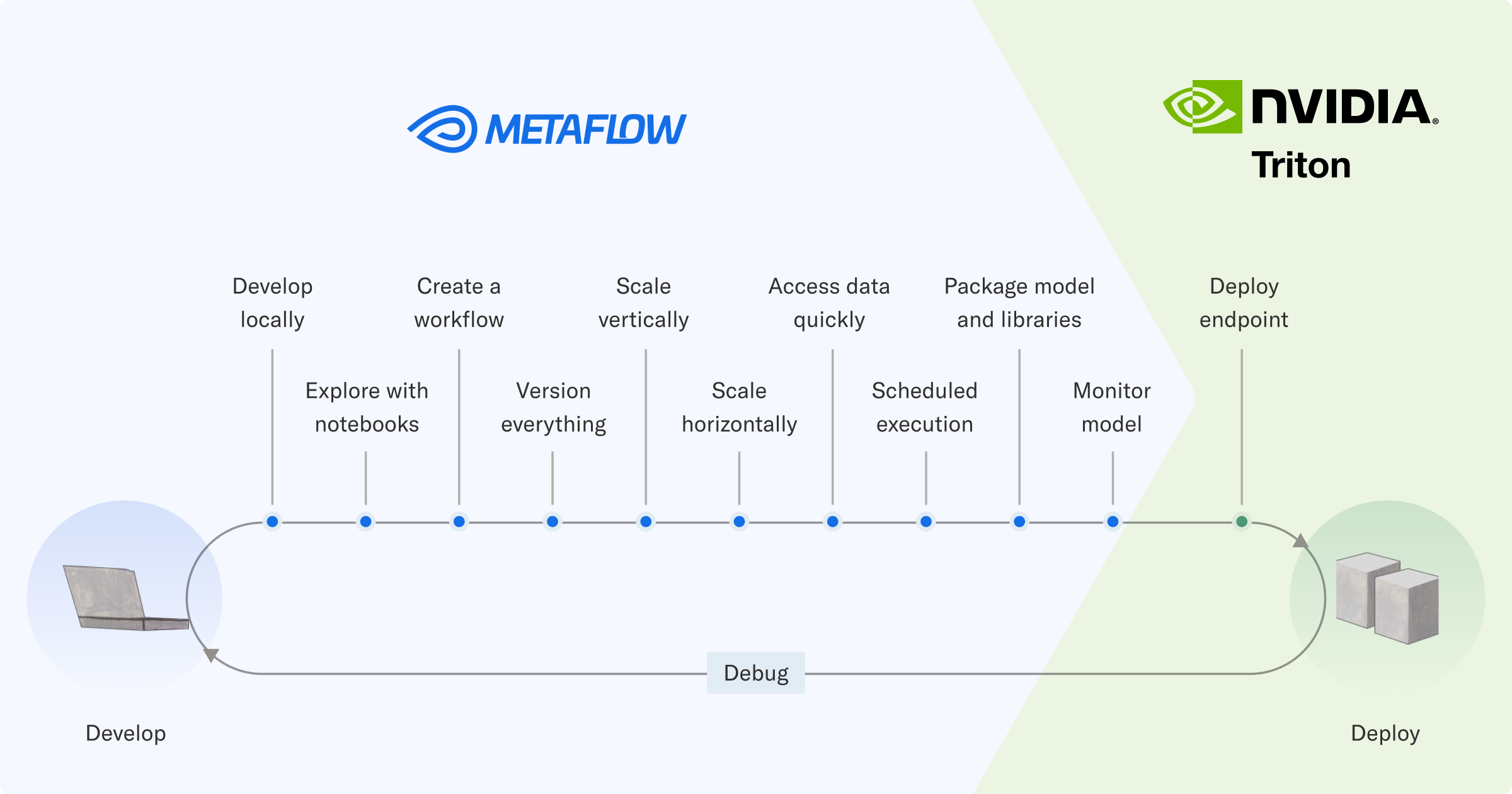
雖然您可以通過為每個步驟采用單獨的工具來完成整個過程,但通過提供連接各個點的一致 API,可以實現更流暢的開發者體驗和更快的部署速度。
出于這一愿景,Netflix 于 2017 年開始開發名為 Metaflow 的 Python 庫,該庫于 2019 年開源。自那時起,該庫已被房地產、無人機、游戲和醫療健康等各行各業的數千家領先的 ML 和 AI 組織采用。
Metaflow 涵蓋了第一個階段的所有問題:如何開發生產級反應性 ML 工作流程、輕松訪問數據和大規模訓練模型,以及全面跟蹤所有工作。
現在,您可以將 Metaflow 作為開源軟件采用,也可以在您的云賬戶中部署 Metaflow。此外,Outerbounds 提供了一個完全托管的 ML 和 AI 平臺,在開源軟件包的基礎上增加了額外的安全性、可擴展性和開發者生產力功能。
通過 Metaflow,您可以應對開發和生成模型相關的前三大挑戰。而要部署用于實時推理的模型,則需要一個模型服務堆棧。這正是 NVIDIA Triton 推理服務器 發揮作用的地方。
NVIDIA Triton 推理服務器是 NVIDIA 開發的開源模型服務框架。它支持各種模型,可以在 CPU 和 GPU 上高效處理。
Outerbounds 和 NVIDIA 正在合作,使各種 ML 和 AI 用例更容易訪問 NVIDIA 推理堆棧。這兩個開源框架的結合使您能夠快速開發機器學習和 AI 驅動的模型和系統,并將其部署為高性能、生產級服務。
在 NVIDIA Triton 推理服務器上部署
為支持企業級生產級 AI, NVIDIA Triton 推理服務器包含在 NVIDIA AI Enterprise 軟件平臺中,可提供企業級安全性、支持和穩定性。
雖然有許多模型服務框架可作為開源和托管服務使用,但 NVIDIA Triton 推理服務器因以下原因而脫穎而出:
- 它采用 C++實現,性能出色,并且能夠高效使用 GPU.這使其成為對延遲和吞吐量敏感的應用程序的絕佳選擇。
- 由于具有可插拔的后端,它用途廣泛,能夠處理許多不同的模型系列。
- 得益于 NVIDIA 的多年開發和大規模使用,它已經過測試和調優。
這些功能使 NVIDIA Triton 推理服務器成為功能非常強大的模型,可服務于工作流程向其推送經過訓練的模型的堆棧。
Metaflow 可幫助您對模型及其周圍的工作流進行原型設計,并對其進行大規模測試,同時跟蹤所執行的所有工作。當工作流顯示出足夠的前景時,可以直接將其集成到周圍的軟件系統,并在生產中進行可靠的編排。
雖然 Metaflow 通過以開發者為中心的簡單 Python API 提供了所有必要的功能,但它由大量基礎設施提供支持。該堆棧與 Amazon S3 等數據存儲集成,促進了 Kubernetes 上的大規模計算,并使用 Argo Workflows 等生產級工作流編排器。
成功訓練模型后,責任轉移到 NVIDIA Triton 推理服務器。與訓練基礎設施類似,推理方面需要一個驚人的非簡單的基礎設施堆棧。
模型服務基礎設施
通過 HTTPS 實現一個簡單的服務來公開簡單的模型(例如邏輯回歸模型)并不難。使用 FastAPI 等框架,可以在數百行 Python 中實現類似的基本版本。
然而,像這樣的簡易模型服務解決方案的性能并不特別出色。Python 是一種富有表現力的語言,但它在快速處理請求方面并不擅長。如果沒有額外的基礎設施,它就無法擴展:單個 FastAPI 進程每秒只能處理這么多請求。此外,如果您想將邏輯回歸模型替換為更復雜的深度回歸模型,該解決方案也不是通用型的。
您可以嘗試逐步解決這些不足之處。但隨著解決方案變得越來越復雜,錯誤、安全問題和其他故障的表面積也變得越來越復雜,這也是我們尋求更穩健解決方案的動力。
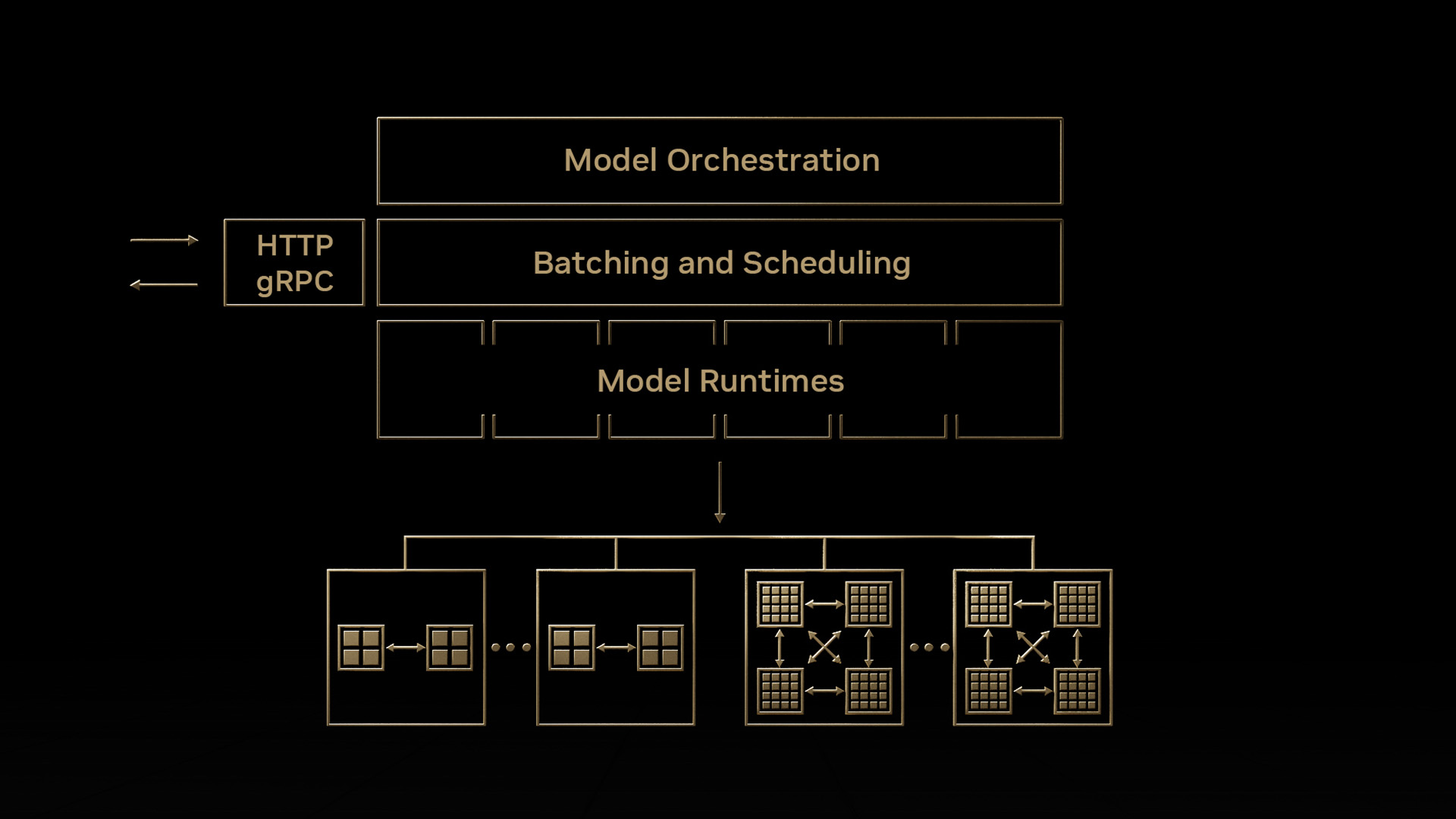
NVIDIA Triton 推理服務器通過將堆棧解構為以下關鍵組件來應對這些挑戰。
- 前端 負責通過 HTTP 或 gRPC 接收請求并將其路由到后端。
- 一個或多個后端負責與特定模型系列交互的層。
NVIDIA Triton 推理服務器支持可插拔后端,這些后端適用于 ONNX、Python 原生模型、基于樹的模型、LLM 和許多其他模型類型。這使得使用一個堆棧處理通用模型成為可能。
高性能前端(每秒可處理數萬次請求)與針對特定模型類型優化的后端相結合,可提供從請求到響應的低延遲路徑。借助 NVIDIA Triton 推理服務器,整個請求處理路徑可以保留在原生代碼中,從而相對于基于 Python 的模型服務解決方案降低請求延遲并提高吞吐量。
低級服務器優化對于利用自定義 LLM(大型語言模型)的應用非常重要,因為這些應用需要為具有低延遲推理的大型深度學習模型提供服務。為了進一步優化 LLM 推理,NVIDIA 推出了 TensorRT-LLM。TensorRT-LLM 是一個 SDK,它讓 Python 開發者能夠更輕松地構建生產級的 LLM 服務器。TensorRT-LLM 開箱即用,可作為 NVIDIA Triton 推理服務器的后端。
無論規模大小或服務器后端如何,單個 NVIDIA Triton Inference Server 實例通常都與 Kubernetes 等容器編排器一起部署。需要一個單獨的層(部署編排器)來管理實例、按需自動擴展集群、管理模型生命周期、請求路由和其他基礎架構問題,如表 1 的最后兩行所示。
集成訓練和服務堆棧
雖然訓練和服務都需要各自的基礎架構堆棧,但出于以下原因,您希望將其緊密對齊。
首先,部署模型應該是常規操作,不需要多行代碼,更糟糕的是,不需要手動操作。
其次,您希望保持已部署模型的完整沿襲,以便您可以了解從原始數據和預處理到經過訓練的模型的整個鏈,并最終部署生成實時推理的模型。在處理 A/B 實驗、部署數百個并行模型或從端點調試響應時,此功能會派上用場。
在本文的指導工作流中,您將模型部署到 NVIDIA Triton Inference Server,以便在堆棧中傳輸版本信息。這樣,您可以回溯推理,一直到原始數據。
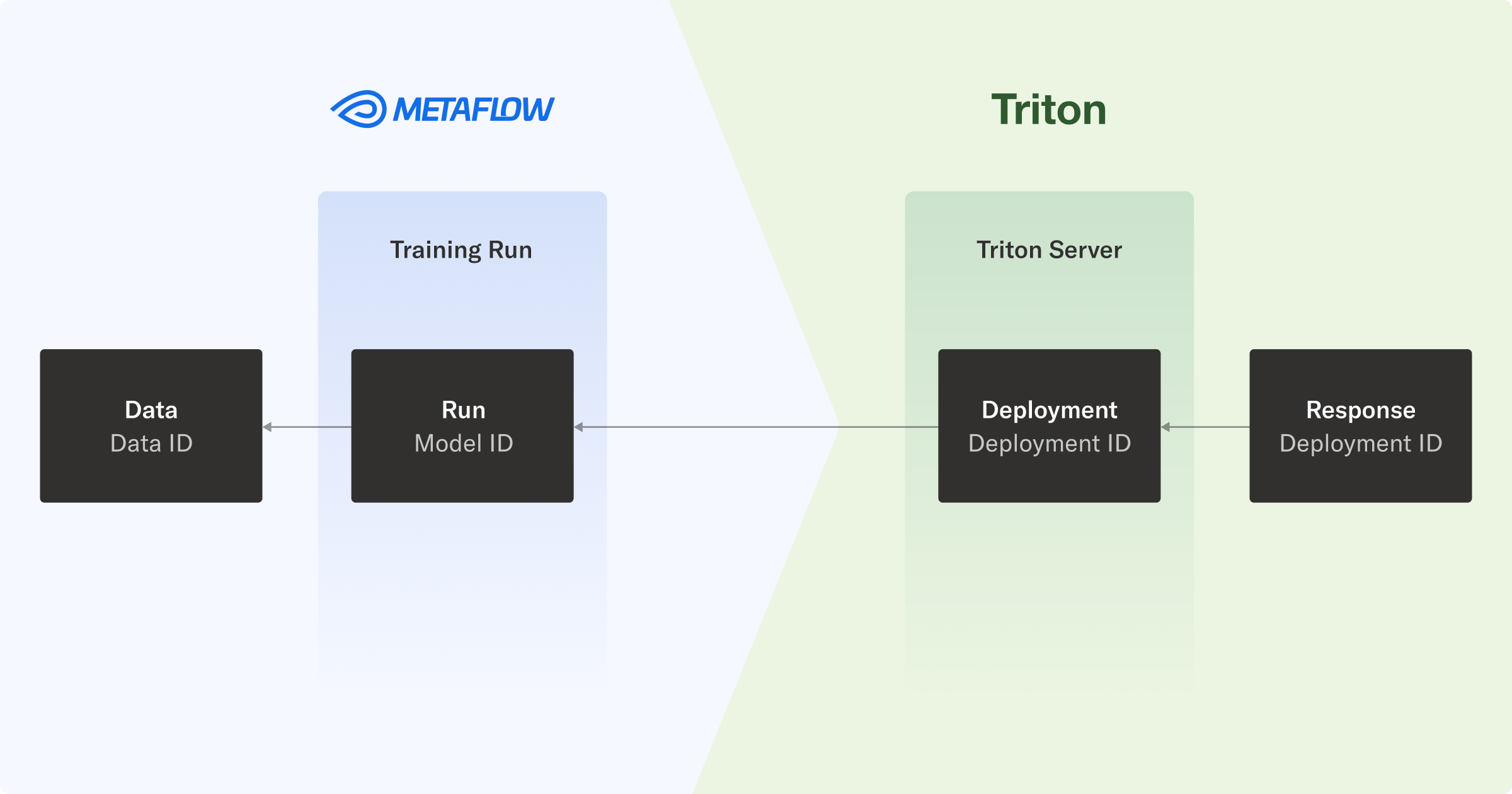
端到端沿襲和可調試性意味著,當托管模型的端點響應請求時,您可以將預測追蹤到生成模型及其訓練數據的工作流。
在實踐中,每個響應都包含 NVIDIA Triton 推理服務器部署 ID,該 ID 映射到 Metaflow 運行 ID,進而使您能夠檢查用于生成模型的數據。
示例:訓練并提供基于樹的模型
為了展示端到端工作流程的實際應用,我們提供了一個實際示例。您可以使用 triton-metaflow-starter-pack GitHub 庫。
我們的工作流程示例解決了欺詐檢測問題,這是一項用于預測貸款違約情況的分類任務。它并行訓練多個 Scikit-learn 模型,選擇性能最佳的模型,并將該模型推送到 NVIDIA Triton 推理服務器所使用的基于云的模型注冊表中。
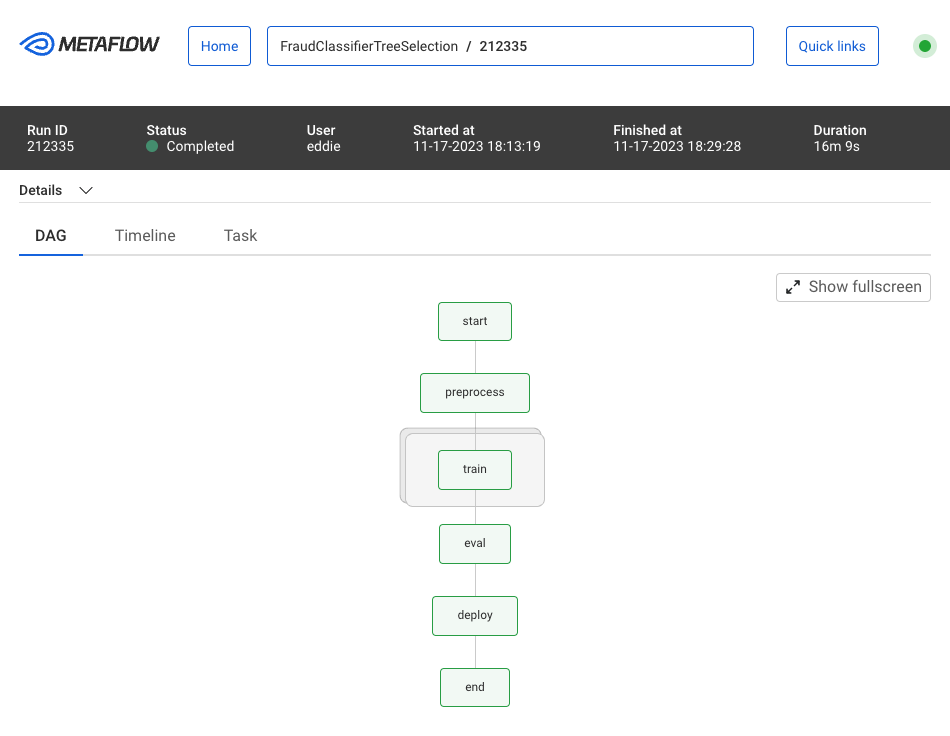
Metaflow UI 支持監控和可視化您的工作流程運行,通過運行 ID 組織工作流程,并無縫跟蹤工作流程運行產生的所有構件。
為了讓您了解工作流代碼的內容,以下代碼示例定義了前三個步驟:start、preprocess 和 train.
class FraudClassifierTreeSelection(FlowSpec): @step def start(self): self.next(self.preprocess) @batch(cpu=1, memory=8000) @card @step def preprocess(self): self.compute_features() self.setup_model_grid(model_list=["Random Forest"]) self.next(self.train, foreach="model_grid") @batch(cpu=4, memory=16000) @card @step def train(self): self.model_name, self.model_grid = self.input self.best_model = self.smote_pipe( self.model_grid, self.X_train_full, self.y_train_full ) self.next(self.eval) ... |
訓練步驟采用了Metaflow 的 foreach 結構。在這種情況下,您可以通過指定 @batch 裝飾器,使用 AWS Batch 來執行。以下命令可用于手動運行工作流程:
python train/flow.py run \--model-repo s3://outerbounds-datasets/triton/tree-models/ |
在您的環境中部署 Metaflow 后,除了編寫和執行工作流程之外,您無需編寫任何其他配置或 Dockerfile。您可以使用單個命令部署工作流程,以便在更廣泛的系統中定時或者由事件觸發。
為 NVIDIA Triton 推理服務器準備模型
工作流的部署步驟負責準備使用 NVIDIA Triton 推理服務器部署的模型。這通過以下步驟完成:
- 在 NVIDIA Triton 推理服務器的模型配置中,您可以設置后端屬性和其他屬性。其中一些屬性取決于訓練過程中的變量,因此您可以動態創建配置文件,并將其作為構件包的一部分,在模型訓練期間上傳到云存儲。
- NVIDIA Triton 推理服務器還需要模型的具體表示形式。考慮到您對服務效率的關注,可以使用 Treelite,這個工具支持 Scikit-learn 樹模型、XGBoost 和 LightGBM。將生成的 checkpoint.tl 文件放置在模型庫中后,NVIDIA Triton 推理服務器便能知曉如何處理。
- 序列化模型文件是使用Metaflow 內置優化的 Amazon S3 客戶端命名的,該命名基于獨特的工作流運行 ID,該 ID 可用于訪問用于訓練模型的所有信息。這樣做可以保持從推理響應到數據處理和訓練工作流的完整溯源。
NVIDIA Triton 推理服務器性能
在提供樹模型方面,NVIDIA Triton 推理服務器搭配了 FIL 后端。我們進行了一個簡單的基準測試,以了解推理延遲與使用 FastAPI 作為前端和 Uvicorn 作為后端的基于 Python 的基準 API 服務器相比如何。您可以通過 triton-metaflow-starter-pack GitHub 庫來使用這些資源。
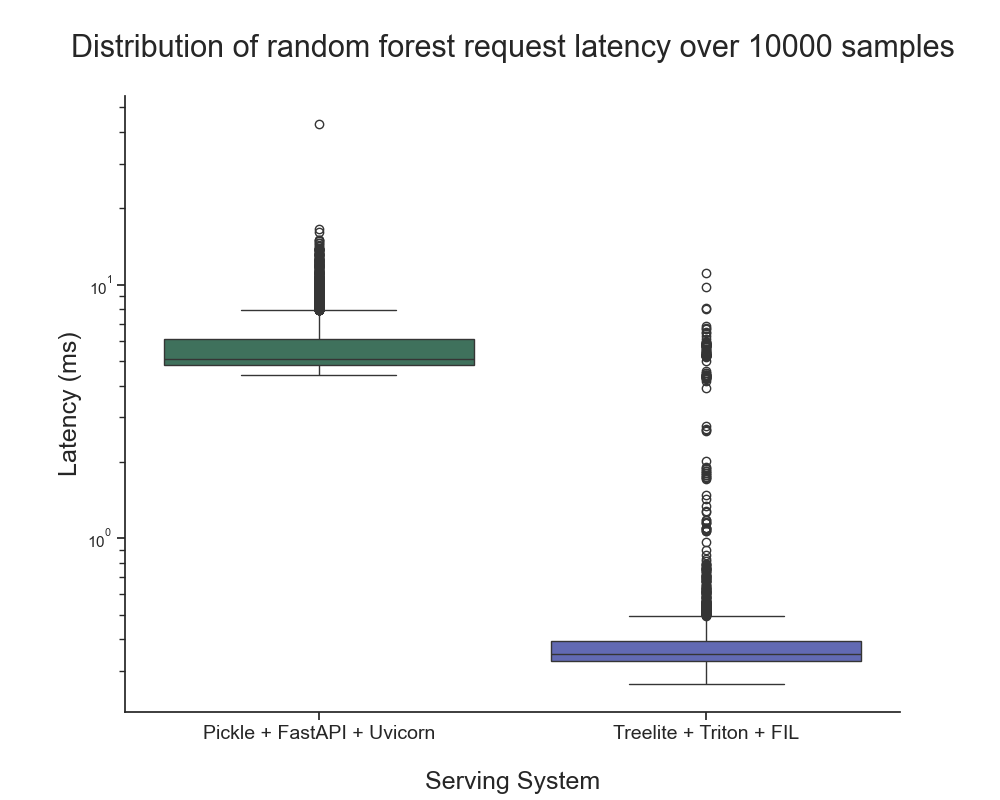
我們觀察到, NVIDIA Triton 推理服務器的響應時間(不包括網絡開銷)為 0.44 毫秒 × 0.64 毫秒,而 FastAPI 為 5.15 毫秒 × 0.9 毫秒。這一差異超過一個數量級。
基準測試是在配備了 8 個至強處理器核心的CoreWeave服務器上進行的,結果表明 NVIDIA Triton 推理服務器能夠在各種環境中提供顯著的加速效果,而不僅限于 NVIDIA GPU。
我們計劃比較更有趣的服務器組合,探索 NVIDIA Triton 推理服務器優化(例如動態請求批處理),并擴展到網絡開銷的實際復雜性。
用于生產推理的 NVIDIA Triton 推理服務器
安全性、可靠性和企業級支持對于生產級 AI 至關重要。
NVIDIA AI Enterprise 是一個包含 NVIDIA Triton 推理服務器的生產就緒型推理平臺。它旨在通過企業級安全性、支持和 API 穩定性來加速價值實現,以確保性能和高可用性。
您可以使用此推理平臺減輕維護和保護復雜的 AI 軟件平臺的負擔。
微調并服務于 LLM
2023 年,在討論模型服務時,我沒有提及 LLM。NVIDIA Triton 推理服務器為深度學習模型提供支持,并且針對服務 LLM 提供了日益復雜的支持。然而,高效地服務 LLM 是一個深入且快速發展的領域。
為了向您展示如何使用 NVIDIA Triton 推理服務器為 LLM 提供服務的示例,我采用了這個工作流程,從 HuggingFace 微調 Lama2 模型以生成 QLoRA,并利用 NVIDIA Triton 推理服務器為生成的模型提供服務。欲了解更多信息,請參閱使用 Metaflow 微調大型語言模型,結合 LLaMA 和 LoRA以及更好、更快、更強的 LLM 微調。
與之前一樣,我構建了 NVIDIA Triton 推理服務器 的 配置,以便在工作流程完成模型訓練后動態運行。此示例旨在作為概念驗證。
后續步驟
在您自己的環境中開始嘗試使用本文重點介紹的端到端 AI 堆棧。有關更多信息,請參閱以下資源:
- 安裝 Metaflow
- Outerbounds
- NVIDIA Triton 推理服務器 可與 NVIDIA AI Enterprise 一起使用,并享受 90 天免費試用 軟件評估許可證
如果您有任何疑問或反饋,請加入Metaflow 社區的 Slack 頻道,與數千名 ML/AI 開發者和工程師交流。
?