
想象一下,你是一名機器人或機器學習( ML )工程師,負責開發一個檢測托盤的模型,以便叉車能夠操縱托盤。?您熟悉傳統的深度學習管道,策劃了手動注釋的數據集,并培訓了成功的模型。
你已經為下一個挑戰做好了準備,它以密集堆放的托盤的形式出現。你可能會想,我應該從哪里開始?? 2D 邊界框檢測或實例分割對此任務最有用嗎??我應該進行三維邊界框檢測嗎?如果是,我將如何對其進行注釋??最好使用單眼相機、立體相機或激光雷達進行檢測嗎??考慮到自然倉庫場景中出現的托盤數量之多,手動注釋并非易事。如果我弄錯了,代價可能會很高。
這就是我在面對類似情況時所想的。幸運的是,我有一個簡單的方法來開始相對較低的承諾:合成數據。
合成數據概述
合成數據生成(SDG)是一種使用渲染圖像而不是真實世界圖像來訓練神經網絡的技術。使用合成渲染數據的優勢在于,您可以隱式地獲取場景中對象的完整形狀和位置,并可以生成注釋,如 2D 邊界框、關鍵點、3D 邊界框、分割遮罩等。
合成數據是引導深度學習項目的有效方法,因為它使您能夠在不需要大規模手動數據注釋的情況下,或者在數據有限、受限或根本不存在的情況下,快速迭代想法。對于這種情況,您可能會發現域隨機化可以為您的應用程序提供有效的即用解決方案。此外,您還可以節省時間。
或者,你可能會發現你需要重新定義任務或使用不同的傳感器模式。使用合成數據,你可以嘗試這些決策,而無需付出昂貴的注釋工作。
在許多情況下,您仍然可以從使用一些真實世界的數據中受益。?好的部分是,通過對合成數據進行實驗,您將更加熟悉這個問題,并可以將注釋工作投入到最重要的地方。每項 ML 任務都有其自身的挑戰,因此很難準確確定合成數據將如何融入,您是否需要使用真實世界的數據,或者混合使用合成數據和真實數據。
使用合成數據訓練托盤分割模
當考慮如何使用合成數據來訓練托盤檢測模型時,我們的團隊從小處著手。在我們考慮 3D 盒子檢測或任何復雜的東西之前,我們首先想看看我們是否可以使用用合成數據訓練的模型來檢測任何東西。為此,我們渲染了一個簡單的場景數據集,其中只包含一個或兩個托盤,頂部有一個盒子。?我們使用這些數據來訓練語義分割模型。
我們之所以選擇訓練語義分割模型,是因為任務定義得很好,而且模型架構相對簡單。還可以直觀地識別模型的故障位置(不正確分割的像素)。
為了訓練分割模型,團隊首先渲染了粗略的合成場景(圖 1 )。

該團隊懷疑,僅憑這些渲染圖像就缺乏訓練有意義的托盤檢測模型的多樣性。因此,我們決定使用生成式 AI來產生更逼真的圖像。在訓練之前,我們將應用人工智能來對這些圖像進行變換,以增加模型推廣到現實世界的能力。
這是使用深度條件生成模型完成的,該模型大致保留了渲染場景中對象的姿勢。請注意,使用 SDG 時不需要使用生成人工智能。你也可以嘗試使用傳統的領域隨機化,比如改變托盤的合成紋理、顏色、位置和方向。?您可能會發現,通過改變渲染紋理的傳統域隨機化對于應用程序來說已經足夠了。

在繪制了大約 2000 幅這些合成圖像后,我們使用 PyTorch 訓練了一個基于 resnet18 的 Unet 分割模型。?很快,結果在真實世界的圖像上顯示出了巨大的前景(圖 3 )。

該模型可以精確地分割托盤。基于這一結果,我們對工作流程有了更多的信心,但挑戰遠未結束。到目前為止,該團隊的方法沒有區分托盤的實例,也沒有檢測到沒有放置在地板上的托盤。?對于如圖 4 所示的圖像,結果幾乎不可用。這可能意味著我們需要調整我們的訓練分布。

不斷增加數據多樣性以提高準確性
為了提高分割模型的準確性,該團隊添加了更多以不同隨機配置堆疊的各種托盤的圖像。我們在數據集中又添加了大約 2000 張圖像,使總數達到 4000 張。我們使用 USD 場景構建實用程序 開源項目。
USD 場景構建實用程序用于在反映您可能在現實世界中看到的分布的配置中,相對于彼此定位托盤。我們曾經提供 Universal Scene Description (OpenUSD) SimReady Assets,其中包含多種托盤型號可供選擇。

使用堆疊的托盤進行訓練,并使用更廣泛的視角,我們能夠提高這些情況下模型的準確性。
如果添加這些數據有助于模型,那么如果沒有添加注釋成本,為什么只生成 2000 張圖像?我們沒有從很多圖像開始,因為我們是從相同的合成分布中采樣的。?添加更多的圖像并不一定會給我們的數據集增加太多的多樣性。相反,我們可能只是添加了許多類似的圖像? 從而提高了模型的真實世界的準確性。
從小處著手使團隊能夠快速訓練模型,查看其失敗的地方,并調整 SDG 管道和添加更多數據。?例如,在注意到模型對托盤的特定顏色和形狀有偏見后,我們添加了更多的合成數據來解決這些故障案例。

這些數據變化提高了模型處理遇到的故障場景(塑料和彩色托盤)的能力。
如果數據變化是好的,為什么不全力以赴,一次增加很多變化呢?在我們的團隊開始對真實世界的數據進行測試之前,很難判斷可能需要什么樣的方差。?我們可能錯過了使模型正常工作所需的重要因素。或者,我們可能高估了其他因素的重要性,不必要地耗盡了我們的努力。?通過迭代,我們可以更好地了解任務需要什么數據。
擴展托盤側面中心檢測模
一旦我們在分割方面取得了一些有希望的結果,下一步就是將任務從語義分割調整為更實用的任務。?我們決定最簡單的下一個評估任務是檢測托盤側面的中心。

托盤側面中心點是叉車在操作托盤時將自身居中的位置。?雖然在實踐中可能需要更多的信息來操作托盤(例如此時的距離和角度),但我們認為這一點是該過程中的一個簡單的下一步,使團隊能夠評估我們的數據對任何下游應用的有用程度。
檢測這些點可以通過熱圖回歸來完成,與分割一樣,熱圖回歸是在圖像域中完成的,易于實現,并且易于視覺解釋。?通過為這項任務訓練模型,我們可以快速評估我們的合成數據集在訓練模型以檢測操作的重要關鍵點方面的有用性。
訓練后的結果很有希望,如圖 8 所示。

該團隊確認了使用合成數據檢測托盤側面的能力,即使是緊密堆疊的托盤。我們繼續對數據、模型和訓練管道進行迭代,以改進該任務的模型。
擴展拐角檢測模
?當我們達到側面中心檢測模型的滿意點時,我們探索將任務提升到下一個層次:檢測盒子的角。最初的方法是對每個角使用熱圖,類似于托盤側面中心的方法。
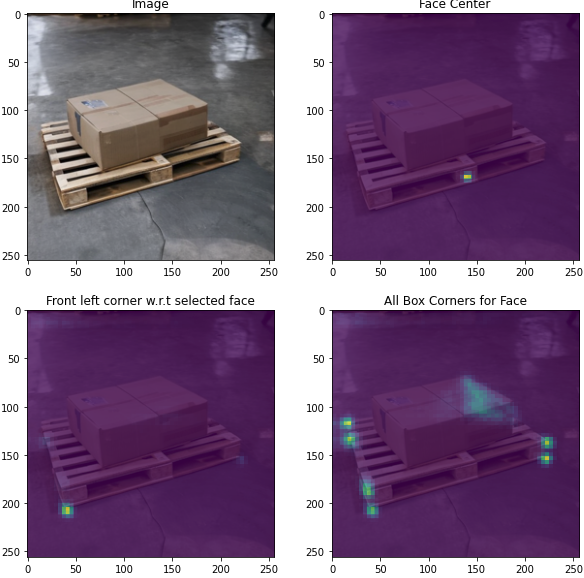
然而,這種方法很快提出了挑戰。由于用于檢測的對象具有未知的尺寸,因此如果托盤的角不直接可見,則模型很難精確推斷出托盤的角應該在哪里。使用熱圖,如果峰值不一致,則很難可靠地解析它們。
因此,我們沒有使用熱圖,而是選擇在檢測到人臉中心峰值后對角點位置進行回歸。我們訓練了一個模型來推斷向量場,該向量場包含角與給定托盤面中心的偏移。?這種方法很快就顯示出了這項任務的前景,即使在大的遮擋情況下,我們也可以提供有意義的拐角位置估計。
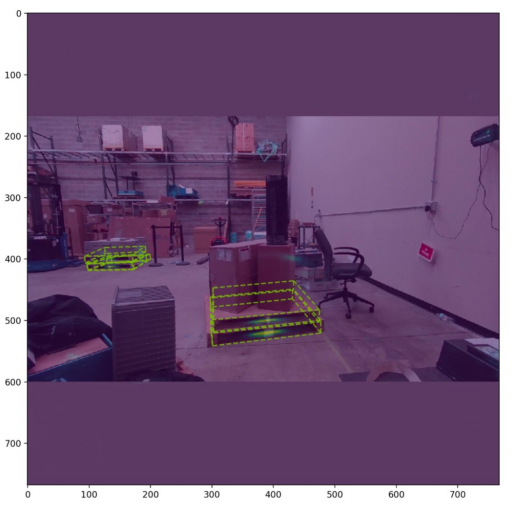
現在團隊有了一個有希望的工作管道,我們迭代并擴展了這個過程,以解決出現的不同故障案例。總的來說,我們的最終模型是在大約 25000 張渲染圖像上進行訓練的。我們的模型以相對較低的分辨率( 256 x 256 像素)進行訓練,能夠通過以更高的分辨率運行推理來檢測小托盤。最終,我們能夠以相對較高的精度檢測到具有挑戰性的場景,如上面的場景。
這是我們可以使用的東西——所有這些都是用合成數據創建的。這就是我們今天的托盤檢測模型。


開始使用合成數據構建自己的模
通過使用合成數據迭代開發,我們的團隊開發了一個適用于真實世界圖像的托盤檢測模型。更多的迭代可能會取得進一步的進展。除此之外,我們的任務可能會受益于添加真實世界的數據。然而,如果沒有合成數據生成,我們就不可能快速迭代,因為我們所做的每一次更改都需要新的注釋工作。
如果您有興趣嘗試這個模型,或者正在開發一個可以使用托盤檢測模型的應用程序,您可以通過訪問 SDG Pallet Model GitHub 找到模型和推理代碼。回購包括預訓練的 ONNX 模型,以及使用 TensorRT 優化模型和對圖像運行推理的指令。該模型可以在 NVIDIA Jetson AGX Orin 上實時運行,因此您可以在邊緣運行它。
您還可以查看最新的開源項目,USD 場景構建實用程序,其中包含使用 USD Python API 構建 Python 場景的示例和實用程序。
我們希望我們的經驗能激勵您探索如何使用合成數據來引導您的人工智能應用程序。如果您想開始合成數據生成, NVIDIA 提供了一套簡化過程的工具。其中包括:
- Universal Scene Description (OpenUSD):被稱為宇宙的 HTML,USD 是一個完整描述 3D 世界的框架。它不僅包括 3D 對象網格等基本元素,還能夠描述材料、照明、相機、物理等。
- NVIDIA Omniverse Replicator:作為NVIDIA Omniverse的核心擴展,Replicator 平臺使開發人員能夠生成大量多樣的合成訓練數據,以引導感知模型訓練。Replicator 具有易于使用的 API 、域隨機化和多傳感器模擬等功能,可以解決數據不足的問題,并加快模型訓練的進程。
- SimReady Assets:支持模擬的資產是物理上精確的 3D 對象,包含精確的物理屬性、行為和連接的數據流,以在模擬的數字世界中表示真實世界。 NVIDIA 提供了一系列逼真的資產和材料,可用于構建 3D 場景。這包括與倉庫物流相關的各種資產,如托盤、手推車和紙箱。要在將 SimReady 資產添加到活動階段之前搜索、顯示、檢查和配置這些資產,可以使用SimReady Explorer擴大每個 SimReady 資產都有自己預定義的語義標簽,從而更容易生成用于分割或對象檢測模型的注釋數據。
如果您對托盤模型、使用 NVIDIA Omniverse 生成合成數據或使用 NVIDIA Jetson 進行推理有疑問,請訪問 GitHub 或訪問 NVIDIA Omniverse 合成數據生成開發者論壇 以及 NVIDIA Jetson Orin Nano 開發者論壇。
在 SIGGRAPH 探索人工智能的下一步
參加我們的 SIGGRAPH 2023,NVIDIA 首席執行官黃仁勛將發表強有力的主題演講。您將有機會獨家了解我們的一些最新技術,包括屢獲殊榮的研究、OpenUSD 開發以及最新的人工智能內容創作解決方案。
?





