引文的準確性對于保持學術和 AI 生成內容的完整性至關重要。當引用不準確或錯誤時,它們可能會誤導讀者并散布虛假信息。作為一支由悉尼大學機器學習和 AI 研究人員組成的團隊,我們正在開發一種 AI-powered 工具,能夠高效地交叉檢查和分析語義引用的準確性。
提及事實聲明可以幫助讀者相信其有效性,增強作者的可信度,并通過顯示信息來源來提高透明度。然而,確保語義引用的準確性(即確認聲明不僅匹配,而且忠實地代表引用來源的結論,而不會失真或誤解)非常耗時,而且通常需要深入的主題理解。
我們親身經歷了不準確的引用所帶來的挫折和挑戰,這促使我們開發了一個強大且可擴展的解決方案 — Semantic Citation Validation 工具。該解決方案簡化了引文驗證過程,并增強了各個領域的研究完整性。
隨著 大語言模型 (LLM) 的日益普及,對引文驗證的需求變得更加迫切。 檢索增強生成 (RAG) 方法的最新進展有助于減少生成內容中的幻覺。但是,如果沒有額外的驗證方法,在建立可信度方面仍然存在重大挑戰。
我們在開發 Research Impact Assessment App 時遇到了這個問題,該應用程序可為醫學和健康領域的科學工作生成自定義影響報告。雖然功能強大,但該應用目前無法獨立驗證引用聲明,也無法驗證其與原始來源聲明的一致性。
本文將介紹語義引文驗證工具,該工具旨在加速驗證過程、保持較高的準確性,并提供相關的上下文片段,以便更深入地理解所引用的材料。此工具通過將事實陳述與引用的文本進行比較,自動驗證引用。它使用 NVIDIA NIM 微服務構建,并為主流 LLM API 提供商提供額外支持,將基于參考數據集訓練的自定義微調模型與靈活的部署選項相結合。

技術實施和 NVIDIA 集成
2024 年 12 月,語義引文驗證工具在 生成式 AI CodeFest 澳大利亞大會 上嶄露頭角,該活動聚焦于實用 AI 工具開發和技能增強。實施策略的核心是利用 NVIDIA NIM 生態系統開發基于微服務的應用,特別是使用 NVIDIA NeMo Retriever 執行嵌入和檢索任務,以及使用微調語言模型進行語義分析和驗證。NeMo Retriever 是微服務的集合,可提供出色的信息檢索,并具有較高的準確性和更大的數據隱私性。
NVIDIA 核心組件包括:
- 高級嵌入和重排序 :NVIDIA 專業服務可將文本轉換為高維嵌入,并根據聲明相關性對段落進行排序,從而通過優化的語義匹配顯著減少內容過濾中的誤報。
- 由 LLM 提供支持的驗證:使用適用于 LLM 的 NVIDIA NIM,該系統可以對已排名的段落進行深度語義分析,為符合專家判斷的驗證決策提供詳細推理。
- 模型微調 :為了優化準確性和處理速度,我們使用由引用聲明、引用和驗證結果組成的自定義數據集微調了 LLama 3.1 模型 (8B 和 70B 變體)。該數據集源自 2024 年引用次數最多的出版物,涵蓋 Medicine、Physics、Mathematics、Computer Science、Geology 和 Environmental Science 等多個研究領域。提取并標注了 2023 年及以后的引文聲明和參考資料。我們還使用 GPT-4o 生成的合成聲明和注釋來增強數據集。在模型訓練中,我們使用了 8 塊 NVIDIA A100 Tensor Core GPU ,GPU 總顯存為 640 GB (由 NVIDIA 作為 Generative AI CodeFest Australia 的一部分提供)。
工作流架構
語義引文驗證工具經過五個簡化階段的運行:
- 輸入處理:通過具有內置格式驗證和錯誤處理功能的強大接收系統處理引文語句和引用文檔。文檔上傳程序支持文本、.pdf 和 .docx 文件。
- 文檔處理 :執行格式驗證、解析和戰略分塊,同時生成用于語義匹配的優化嵌入。它還使用 LLM 將引文文本處理為結構化聲明。
- 向量管理 :實現文檔和向量存儲的雙緩存架構,實現快速檢索并減少處理開銷。
- 匹配和分析 :以多層方法結合相似性匹配、重排序和 LLM 分析,實現全面驗證。
- 輸出生成:生成支持分類、驗證推理、相關片段和 confidence scores。
處理流程使用 LangChain 和 ChromaDB 實現 RAG,并可以與 OpenAI 和 NVIDIA 語言和嵌入模型進行交互。圖 2 概述了語義引文驗證工具的流程流程。

Web 應用程序概述和主要功能
作為初始原型,我們使用 Streamlit 開發了直觀的 Web 界面,使引用驗證工具易于訪問,并簡化了自動引用驗證的工作流程。
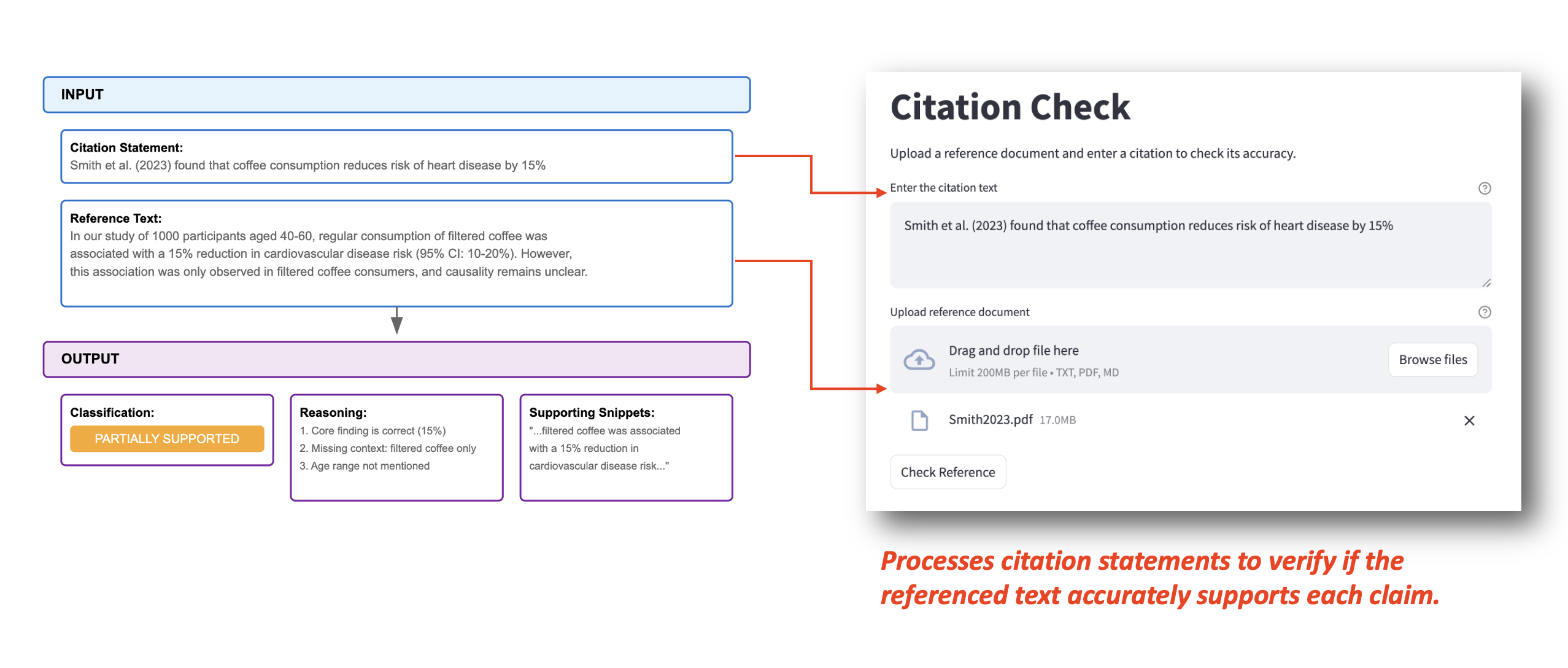
用戶可以直接輸入引文語句和參考文件,如下例所示。系統會處理這些信息并生成三個關鍵輸出:
- “分類 (在本例中顯示為 PARTIALLY_SUPPORTED)”
- 分類的詳細推理 (在本例中列出有關核心發現、缺失上下文和年齡范圍的三個具體點)
- 源文本中的相關支持片段
利用 NVIDIA 微服務實施 LLM、文檔檢索和排序
配置界面通過靈活的 LLM 提供商選擇、優化的嵌入服務以及使用 Chroma vector store 和 FlashrankRerank 的強大檢索機制來展示核心 NVIDIA 集成。本地端點配置可確保安全處理敏感數據,同時保持性能。

準確性分類
驗證工具通過四個不同的類別提供細致入微的引用評估:
- 支持:指示完全對齊和正確的上下文
- 部分支持 :顯示受支持的核心聲明,但缺少上下文或細微差別
- 不支持: 對于與來源不符或來源缺失的索賠
- 不確定: 適用于信息不明確或不充分的情況
該分類方案旨在平衡粒度和簡單性,確保研究人員和審查人員的潛在行動保持一致。支持的引用無需更改,部分支持的引用可能需要進行細微修改,不支持的引用需要進行重大修改或刪除,并且不確定的案例需要進一步審查。

推理和支持證據
該工具還通過分析引文和源文本之間的具體差距 (例如缺失的細節、方法上的細微差別、上下文遺漏或對結果的潛在曲解) ,為其分類提供詳細的推理。支持證據通過參考文檔中的相關文本片段提供,并附帶相關性分數,使用戶能夠直接驗證工具的決策過程。

總結
語義引文驗證工具通過將事實陳述與引用文本進行比較來自動驗證引文。它使用 NVIDIA NIM 微服務構建,并為主流 LLM API 提供商提供額外支持,將基于參考數據集訓練的自定義微調模型與靈活的部署選項相結合。該工具執行語義聲明驗證并提取支持證據,將引用分為四類:支持、部分支持、不支持和不確定。該工具可輕松部署為 Web 應用程序,實現對引文的系統審查,將檢查時間從幾小時縮短到幾秒鐘,同時提高研究的準確性和質量。
未來,我們計劃簡化引文驗證過程。我們將實現從任何文檔中自動引用和引用,以及開源引用的完整文本檢索。這種增強功能將消除手動輸入要求,顯著縮短傳統學術內容和 AI 生成的輸出的驗證時間。這將通過與學術數據庫和預打印服務器集成,實現直接的來源檢索和驗證。
進一步的開發包括同時處理多次引用的批量處理功能,使其對文稿編輯、系統審查和快速驗證 AI 生成的內容非常重要。這些改進將把該工具轉變為全面的引用完整性解決方案,支持研究人員、編輯團隊和內容創作者在人類創作和 AI 生成的作品中保持高標準的準確性。有關更多信息和更新,請訪問 RefCheckAI 。
探索 NVIDIA NIM ,加速 AI 開發并解決實際挑戰。詳細了解 NIM 及其構建創新解決方案的功能,例如此引文驗證工具。
致謝
這項工作在澳大利亞生成式 AI Codefest ( Open Hackathons 計劃的一部分) 上完成。我們感謝 OpenACC-Standard.org 的支持。我們在此感謝澳大利亞工業、科學和資源部通過國家 AI 中心和國家計算基礎設施 (NCI) 與 NVIDIA 和 Sustainable Metal Cloud (SMC) 共同舉辦生成式 AI CodeFest 澳大利亞大會。該項目得到了悉尼大學悉尼信息學中心 (SIH) 的支持。