
精確標注的數據集對于基于相機的深度學習算法執行自動駕駛車輛感知至關重要。然而,手動標記數據是一個耗時且成本密集的過程。
我們開發了一個自動標記管道,作為基于 Tata Consultancy Services (TCS) 人工智能( AI )的自動駕駛汽車平臺的一部分。該管道使用 NVIDIA DGX A100 和 TCS 功能豐富的半自動標簽工具進行檢查和糾正。這篇文章介紹了標簽流水線的設計、 NVIDIA DGX A100 如何加速標簽,以及通過實施自動標簽流程實現的節約。
設計自動標記管道
自動標記管道必須能夠從網絡存儲驅動器中下載的圖像中生成以下注釋:
- 具有可見性屬性(例如完全可見和遮擋)的 2D 對象檢測
- 具有可見性屬性(例如完全可見和遮擋)的 3D 對象檢測
- 帶有屬性(如車道分類和車道顏色)的車道檢測
我們為 2D 對象檢測、 3D 對象檢測和車道檢測任務設計并訓練了定制的深度神經網絡( DNN )。然而,當測試用于自動標記目的的檢測器輸出時,我們觀察到輕微的漏檢。這為執行標簽的人增加了更多的工作。此外,為每個對象或車道指定屬性需要相當長的時間。
為了解決這些問題,我們添加了一種有效的跟蹤算法,該算法為所有檢測提供了跟蹤標識。該算法與 TCS 半自動標記工具中增強的按軌跡 ID 復制功能相結合,有助于使用相同的軌跡 ID 糾正屬性或檢測。
一幀中的校正被復制到軌道 ID 相同的后續幀,從而加速校正。端到端管道由以下附加模塊組成:
- 2D 對象跟蹤器
- 車道跟蹤器
優化管道
由于底層模塊之間的相互依賴性,所有模塊不能并行運行。作為一種解決方案,我們將整個管道執行分為三個階段,以實現模塊的并行執行。
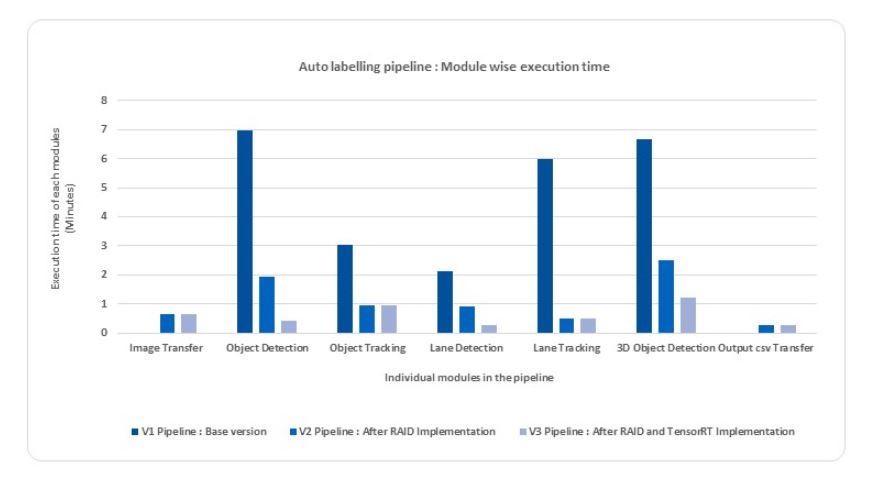
管道的輸入是 206 個圖像序列,每個圖像的分辨率為 1920 x 1280 像素。圖 1 、圖 2 和圖 3 中提供的時序基于每個模塊的批處理。
最初,在管道的基礎版本中,當部署在 NVIDIA DGX A100 GPU 上時,批處理的端到端執行時間為 16 分 40 秒,即每幀 4.854 秒。
圖 1 顯示了基本版本的模塊化時間分析。該執行時間包括從存儲原始圖像的網絡驅動器讀取圖像,處理所有管道模塊,并將自動注釋保存到網絡驅動器。
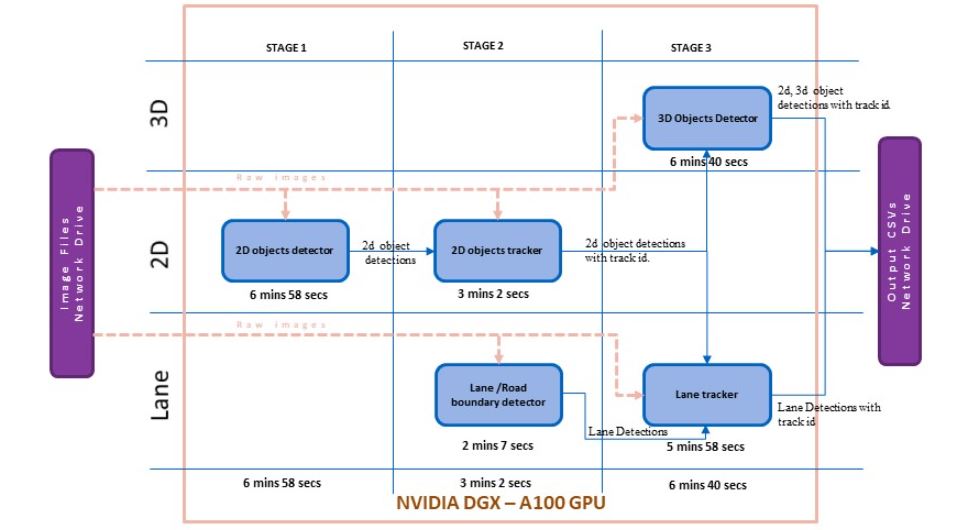
時間分析器分析了處理時間,顯示從網絡驅動器讀取原始圖像的速度相當高。這些模塊使用原始圖像作為輸入之一,從網絡驅動器讀取圖像的延遲會導致整個管道執行的巨大開銷。
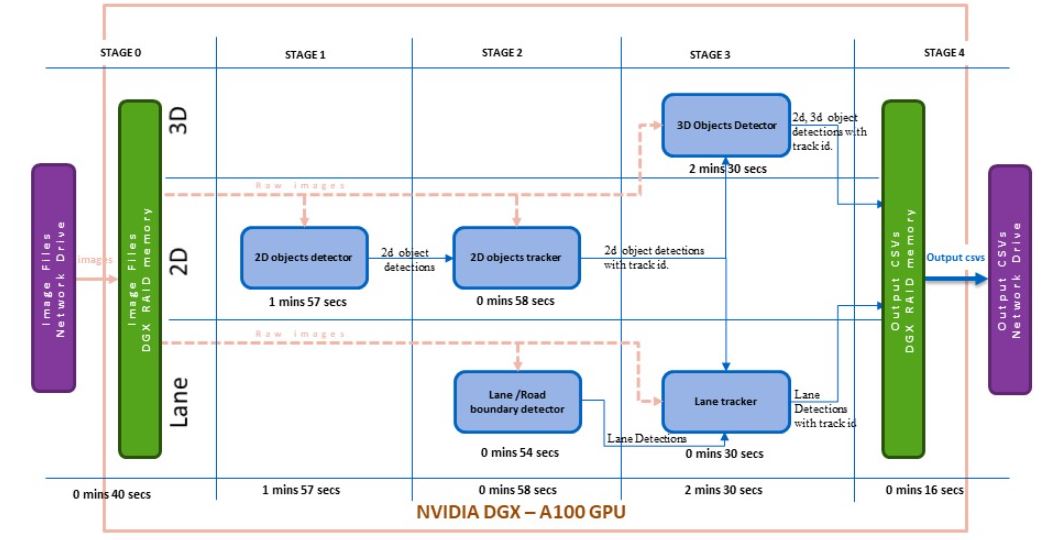
DGX RAID 內存被設置為管道第二版本的中間存儲。在階段 0 中,所有原始映像都從網絡驅動器讀取到 DGX RAID 內存(圖 2 )。
模塊從 RAID 內存加載原始圖像,所有輸出都存儲在 RAID 內存中。管道執行后,最終的注釋輸出被移動到網絡驅動器。
具有管道版本 2 的一批 206 個圖像的總執行時間減少到 6 分 21 秒,即每幀 1.84 秒。圖 2 顯示了管道版本 2 的模塊化時間分析。
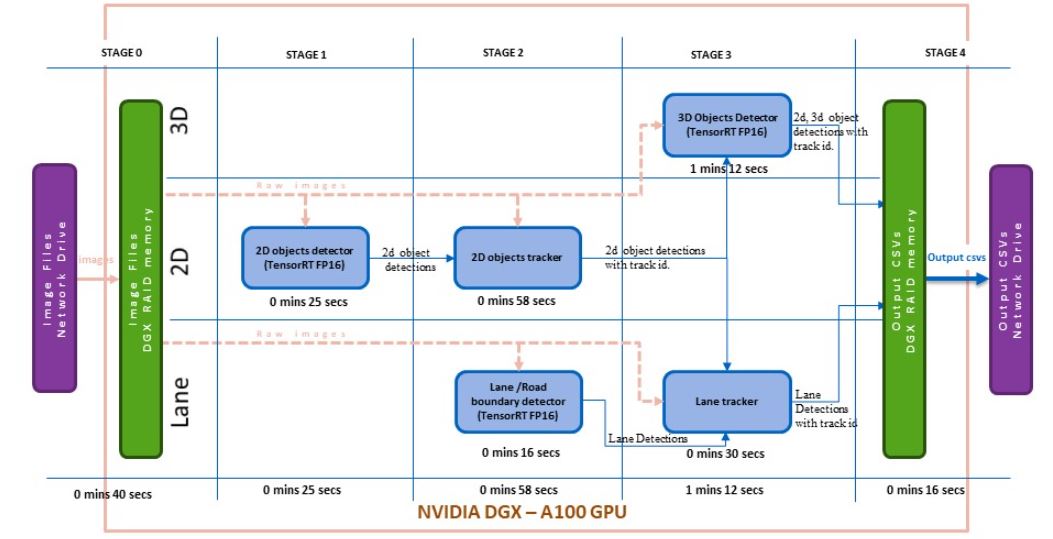
管道的版本 3 使用 NVIDIA NGC 容器和 TensorFlow 2.5 和 NVIDIA CUDA 11.4.1 ( TensorFlow : 21.08-tf2-py3 )。 PyTorch 的安裝是為了滿足底層 DNN 模塊的依賴性。 GPU – 支持的 OpenCV 是在這個基礎圖像之上從源代碼構建的。
核心深度學習算法需要進一步加速以達到所需的處理時間。通過利用 NGC Docker 中的 NVIDIA TensorRT 8.0.1.6 ,車道檢測模型、 2D 物體檢測模型和 3D 物體檢測模型都被轉換為 FP16 TensorRT 模型,并在管道的第 3 版中實現。
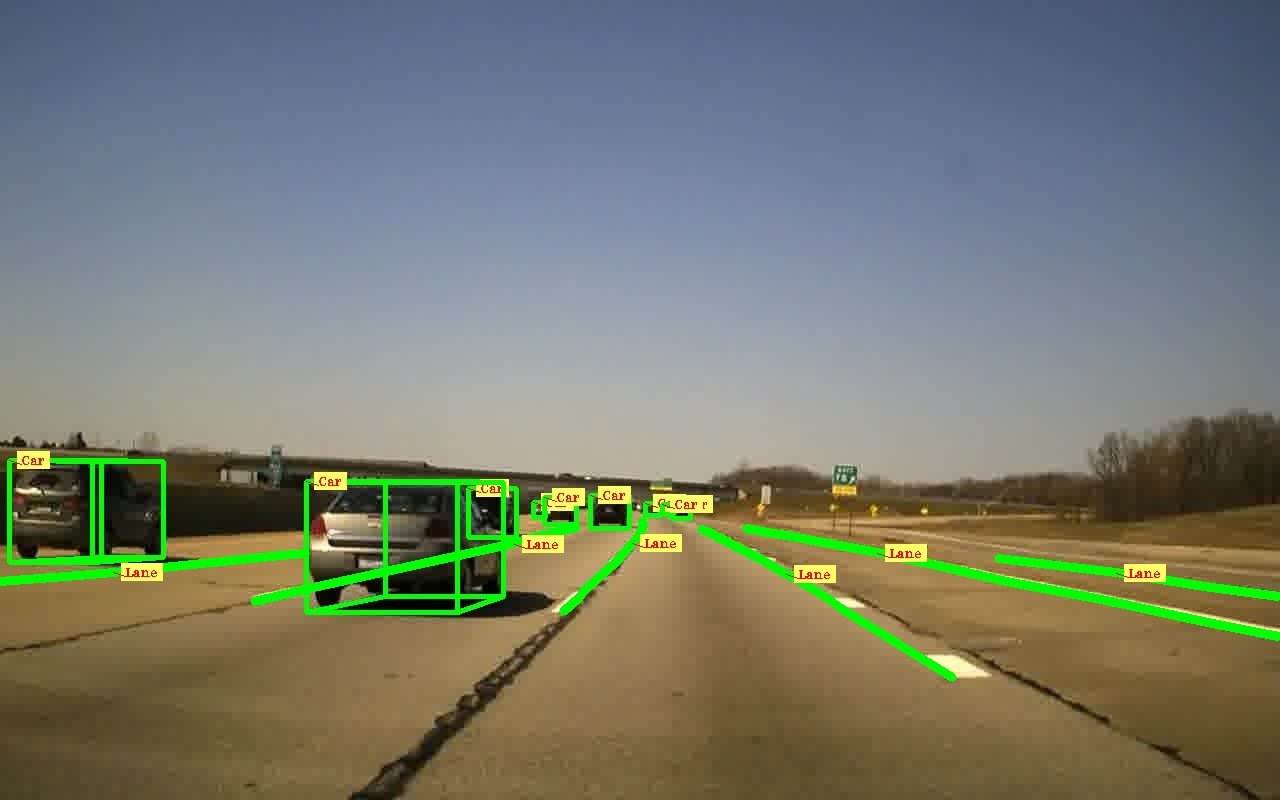
因此,對于 206 幀,管道的端到端執行時間降至 3 分 30 秒,即每幀 1.01 秒。圖 3 顯示了版本 3 的模塊化時間分析。我們在不影響模型所需精度的情況下獲得了結果。圖 4 顯示了這個自動標記管道的結果。
在管道的端到端執行期間,每個模塊的處理時間節省如圖 5 所示。通過 NVIDIA DGX 中的一個 NVIDIA A100 40 GB GPU ,深度學習算法被優化以減少模型加載時間的開銷,從而實現更大的節約,以實現全天候自動標記所需的放大。
結論
憑借 NVIDIA DGX A100 GPU 的計算性能,加上 TCS 在 AI 和深度學習算法部署方面的專業知識,我們開發了一個高效的自動標記流水線,用于 AV 攝像機感知算法。 DGX RAID 內存和 NVIDIA TensorRT 的有效利用將自動標記管道的處理時間減少到總時間的四分之一。
部署了這條自動標記管線的國際汽車零部件供應商達到了65%的人工工作量的減少,而使用目前最先進的開放模型比如YOLOX,LaneNet只能提供34%的工作量的減少。
想了解更多信息嗎? 免費注冊 NVIDIA GTC 2023 ?, 3 月 20-23 日加入我們 為 AV 感知開發強大的多任務模型 。查看自動駕駛汽車開發人員的目標會話軌跡,包括 映射, 模擬, 安全性, 和更多?。
?






