從制造汽車到幫助外科醫生和送披薩,機器人不僅自動化,而且將人類任務的速度提高了許多倍。隨著人工智能的出現,你可以建造更智能的機器人,它們可以更好地感知周圍環境,并在最少的人工干預下做出決策。
例如,一個用于倉庫的自動機器人將有效載荷從一個地方移動到另一個地方。它必須感知周圍的自由空間,檢測并避免路徑中的任何障礙,并做出“即時”決定,毫不拖延地選擇新路徑。
這就是挑戰所在。這意味著構建一個由人工智能模型支持的應用程序,該模型經過訓練和優化,可以在這種環境下工作。它需要收集大量高質量的數據,并開發一個高度精確的人工智能模型來驅動應用程序。這些是將應用程序從實驗室轉移到生產環境的關鍵障礙。
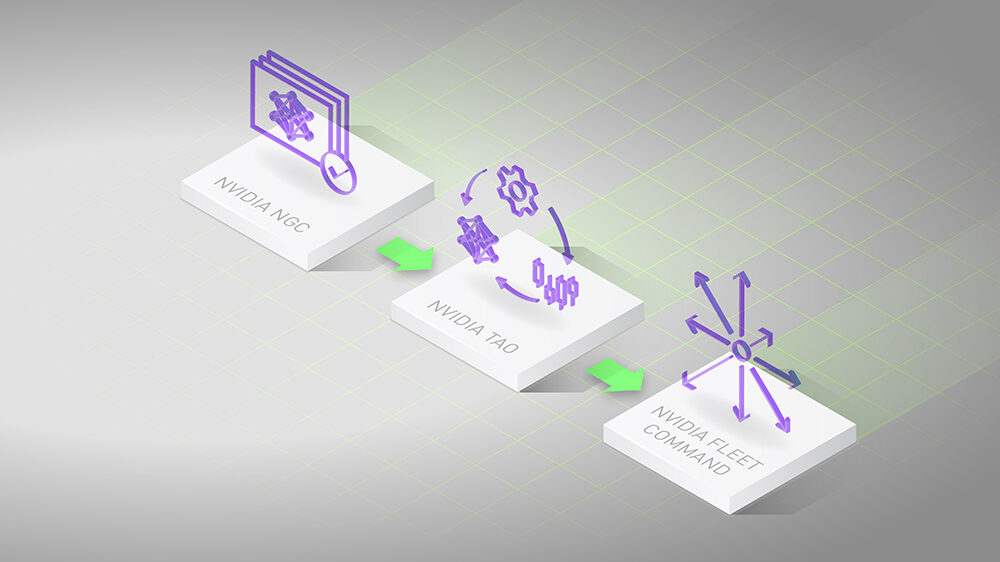
在這篇文章中,我們將展示如何使用 NVIDIA ISAAC 平臺和 TAO 框架解決數據挑戰和模型創建挑戰。你使用 NVIDIA ISAAC Sim?,一個機器人模擬應用程序,用于創建虛擬環境和生成合成數據。這個 NVIDIA TAO 工具包 是一種低代碼人工智能模型開發解決方案,與從頭開始的訓練相比,它具有內置的轉移學習功能,可以用一小部分數據微調預訓練模型。最后,使用 NVIDIA ISAAC ROS 將優化模型部署到機器人上,并將其應用于現實世界。
先決條件
開始之前,您必須擁有以下用于培訓和部署的資源:
- NVIDIA GPU 驅動程序版本:> 470
- NVIDIA Docker: 2.5.0-1
- NVIDIA GPU 云端或內部:
- NVIDIA A100
- NVIDIA V100
- NVIDIA T4
- NVIDIA RTX 30 × 0 ( NVIDIA ISAAC 是也支持 NVIDIA RTX 20 系列)
- NVIDIA Jetson Xavier 或 Jetson Xavier NX
- NVIDIA TAO 工具包: 4.22 。有關更多信息,請參閱 TAO 工具包快速入門指南
- NVIDIA ISAAC Sim 和 ISAAC ROS
使用 NVIDIA ISAAC Sim 生成合成數據
在本節中,我們將概述在 NVIDIA ISAAC Sim 中生成合成數據的步驟。 Synthetic data 是計算機模擬或算法生成的注釋信息。當真實數據難以獲取或成本高昂時,合成數據可以幫助解決數據難題。
NVIDIA ISAAC Sim 提供三種生成合成數據的方法:
- 復制器作曲家
- Python 腳本
- GUI
在這個實驗中,我們選擇使用 Python 腳本生成具有領域隨機化的數據。 Domain randomization 改變在模擬環境中定義場景的參數,包括場景中各種對象的位置、比例、模擬環境的照明、對象的顏色和紋理等。
添加域隨機化以同時改變場景的多個參數,通過將其暴露于現實世界中看到的各種域參數,提高了數據集質量并增強了模型的性能。
在本例中,您使用兩個環境來培訓數據:一個倉庫和一個小房間。接下來的步驟包括向場景中添加符合物理定律的對象。我們使用了 NVIDIA ISAAC Sim 卡中的示例對象,其中還包括 YCB dataset 中的日常對象。

安裝 NVIDIA ISAAC Sim 卡后 ISAAC Sim 卡應用程序選擇器 為包含python.sh腳本的 在文件夾中打開 提供一個選項。這用于運行用于生成數據的腳本。
按照列出的步驟生成數據。
選擇環境并將攝影機添加到場景中
def add_camera_to_viewport(self): # Add a camera to the scene and attach it to the viewport self.camera_rig = UsdGeom.Xformable(create_prim("/Root/CameraRig", "Xform")) self.camera = create_prim("/Root/CameraRig/Camera", "Camera")
將語義 ID 添加到樓層:
def add_floor_semantics(self): # Get the floor from the stage and update its semantics stage = kit.context.get_stage() floor_prim = stage.GetPrimAtPath("/Root/Towel_Room01_floor_bottom_218") add_update_semantics(floor_prim, "floor")
在具有物理特性的場景中添加對象:
def load_single_asset(self, object_transform_path, object_path, usd_object): # Random x, y points for the position of the USD object translate_x , translate_y = 150 * random.random(), 150 * random.random() # Load the USD Object try: asset = create_prim(object_transform_path, "Xform", position=np.array([150 + translate_x, 175 + translate_y, -55]), orientation=euler_angles_to_quat(np.array([0, 0.0, 0]), usd_path=object_path) # Set the object with correct physics utils.setRigidBody(asset, "convexHull", False)
初始化域隨機化組件:
def create_camera_randomization(self): # A range of values to move and rotate the camera camera_tranlsate_min_range, camera_translate_max_range = (100, 100, -58), (220, 220, -52) camera_rotate_min_range, camera_rotate_max_range = (80, 0, 0), (85, 0 ,360) # Create a Transformation DR Component for the Camera self.camera_transform = self.dr.commands.CreateTransformComponentCommand( prim_paths=[self.camera.GetPath()], translate_min_range=camera_tranlsate_min_range, translate_max_range=camera_translate_max_range, rotate_min_range=camera_rotate_min_range, rotate_max_range=camera_rotate_max_range, duration=0,5).do()
確保模擬中的攝影機位置和屬性與真實世界的屬性相似。為生成正確的自由空間分段掩碼,需要向地板添加語義 ID 。如前所述,應用領域隨機化來幫助提高模型的 sim2real 性能。
NVIDIA ISAAC Sim 文檔中提供的 離線數據生成 示例是我們腳本的起點。對這個用例進行了更改,包括使用物理向場景添加對象、更新域隨機化,以及向地板添加語義。我們已經為數據集生成了近 30000 張帶有相應分割模板的圖像。
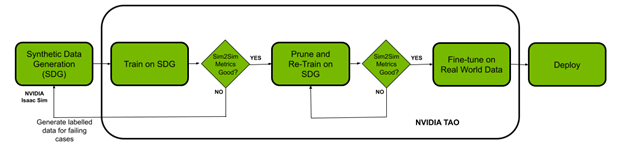
使用 TAO 工具包進行培訓、調整和優化
在本節中,您將使用 TAO 工具包使用生成的合成數據對模型進行微調。為了完成這項任務,我們選擇了 NGC 提供的 UNET 模型進行實驗。
!ngc registry model list nvidia/tao/pretrained_semantic_segmentation:*
設置數據、規格文件( TAO 規格)和實驗目錄:
%set_env KEY=tlt_encode %set_env GPU_INDEX=0 %set_env USER_EXPERIMENT_DIR=/workspace/experiments %set_env DATA_DOWNLOAD_DIR=/workspace/freespace_data %set_env SPECS_DIR=/workspace/specs
下一步是選擇模型。
選擇正確的預訓練模型
預訓練人工智能和深度學習模型是在代表性數據集上進行訓練并使用權重和偏差進行微調的模型。與從頭開始的訓練相比,只需使用一小部分數據就可以應用遷移學習,您可以快速輕松地微調預訓練模型。
在預訓練模型領域中,有一些模型執行特定任務,比如檢測人、汽車、車牌等。
我們首先選擇了一個帶有 ResNet10 和 ResNet18 主干的 U-Net 型號。從模型中獲得的結果顯示,在真實數據中,墻和地板合并為一個實體,而不是兩個單獨的實體。即使模型在模擬圖像上的性能顯示出較高的精度,這也是事實。
| BackBone | Pruned | Dataset Size | Image Size | Training Evaluations | ? | |||
| ? | ? | Train | Val | ? | F1 Score | mIoU (%) | Epochs | ? |
| RN10 | NO | 25K | 4.5K | 512×512 | 89.2 | 80.1 | 50 | ? |
| RN18 | NO | 25K | 4.5K | 512×512 | 91.1 | 83.0 | 50 | ? |
我們用不同的主干和圖像大小進行實驗,觀察延遲( FPS )與準確性之間的權衡。表中所有型號均相同( UNET );只有脊柱不同。

根據結果,我們顯然需要一個更適合用例的不同模型。我們選擇了 NGC 目錄中提供的 PeopleSemSeg 型號。該模型在“ person ”類的 500 萬個對象上進行了預訓練,數據集由相機高度、人群密度和視野( FOV )組成。該模型還可以將背景和自由空間分割為兩個獨立的實體。
在使用相同的數據集對該模型進行訓練后,平均 IOU 增加了 10% 以上,得到的圖像清楚地顯示了地板和墻壁之間更好的分割。
| BackBone | Pruned | Dataset Size | Image Size | Training Evaluations | |||
| ? | ? | Train | Val | ? | F1 Score | mIoU (%) | Epochs |
| PeopleSemSegNet | NO | 25K | 4.5K | 512×512 | 98.1 | 96.4 | 50 |
| PeopleSemSegNet | NO | 25K | 4.5K | 960×544 | 99.0 | 98.1 | 50 |

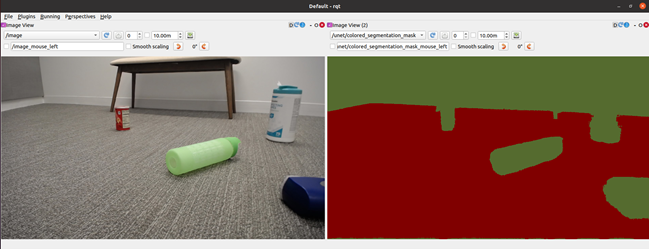
圖 4 顯示了在使用真實數據對 PeopleSeg 模型進行微調之前,從機器人的角度在模擬圖像和真實圖像上識別自由空間。也就是說,使用純 NVIDIA ISAAC Sim 卡數據訓練的模型。
關鍵的一點是,雖然可能有許多經過預訓練的模型可以完成這項任務,但選擇一個最接近當前應用程序的模型是很重要的。這就是陶的特制模型有用的地方。
!tao unet train --gpus=1 --gpu_index=$GPU_INDEX \ -e $SPECS_DIR/spec_vanilla_unet.txt \ -r $USER_EXPERIMENT_DIR/semseg_experiment_unpruned \ -m $USER_EXPERIMENT_DIR/peoplesemsegnet.tlt \ -n model_freespace \ -k $KEY
培訓模型后,根據驗證數據評估模型性能:
!tao unet evaluate --gpu_index=$GPU_INDEX -e$SPECS_DIR/spec_vanilla_unet.txt \ -m $USER_EXPERIMENT_DIR/semseg_experiment_unpruned/weights/model_freespace.tlt \ -o $USER_EXPERIMENT_DIR/semseg_experiment_unpruned/ \ -k $KEY
當您對 NVIDIA ISAAC Sim 數據的模型性能和 Sim2Sim 驗證性能感到滿意時,請刪減模型。
要以最小的延遲運行此模型,請將其優化為在目標 GPU 上運行。有兩種方法可以實現這一點:
- Pruning : TAO 工具包中的修剪功能會自動刪除不需要的層和神經元,有效地減小模型的大小。必須重新訓練模型,以恢復修剪過程中丟失的精度。
- Post-training quantization : TAO 工具包中的另一項功能可以進一步縮小模型尺寸。這將其精度從 FP32 更改為 INT8 ,在不犧牲精度的情況下提高了性能。
首先,刪減模型:
!tao unet prune \ -e $SPECS_DIR/spec_vanilla_unet.txt \ -m $USER_EXPERIMENT_DIR/semseg_experiment_unpruned/weights/model_freespace.tlt \ -o $USER_EXPERIMENT_DIR/unet_experiment_pruned/model_unet_pruned.tlt \ -eq union \ -pth 0.1 \ -k $KEY
重新訓練并修剪模型:
!tao unet train --gpus=1 --gpu_index=$GPU_INDEX \ -e $SPECS_DIR/spec_vanilla_unet_retrain.txt \ -r $USER_EXPERIMENT_DIR/unet_experiment_retrain \ -m $USER_EXPERIMENT_DIR/unet_experiment_pruned/model_unet_pruned.tlt \ -n model_unet_retrained \ -k $KEY
當您對修剪模型的 Sim2Sim 驗證性能感到滿意時,請轉至下一步,對真實數據進行微調。
!tao unet train --gpus=1 --gpu_index=$GPU_INDEX \ -e $SPECS_DIR/spec_vanilla_unet_domain_adpt.txt \ -r $USER_EXPERIMENT_DIR/semseg_experiment_domain_adpt \ -m $USER_EXPERIMENT_DIR/semseg_experiment_retrain/model_unet_pruned.tlt\ -n model_domain_adapt \ -k $KEY
后果
表 1 顯示了未運行和修剪模型之間的結果摘要。最終選擇用于部署的經過修剪和量化的模型比在 NVIDIA Jetson Xavier NX 上測量的原始模型小 17 倍,推理性能快 5 倍。
| Model | Dataset | Training Evaluations | Inference Performance | ||||
| Pruned | Fine-Tune on Real World Data |
Training Set | Validation Set | F1 Score (%) | mIoU (%) | Precision | FPS |
| NO | NO | Sim | Sim | 0.990 | 0.981 | FP16 | 3.9 |
| YES | NO | Sim | Sim | 0.991 | 0.982 | FP16 | 15.29 |
| YES | NO | Sim | Real | 0.680 | 0.515 | FP16 | 15.29 |
| YES | YES | Real | Real | 0.979 | 0.960 | FP16 | 15.29 |
| YES | YES | Real | Real | 0.974 | 0.959 | INT8 | 20.25 |
sim 數據的訓練數據集由 25K 個圖像組成,而用于微調的真實圖像的訓練數據僅由 44 個圖像組成。真實圖像的驗證數據集僅包含 56 幅圖像。對于真實世界的數據,我們收集了三種不同室內場景的數據集。模型的輸入圖像大小為 960 × 544 。推理性能是使用 NVIDIA TensorRT trtexec 工具 .

部署 NVIDIA ISAAC ROS
在本節中,我們展示了采用經過訓練和優化的模型并使用 NVIDIA ISAAC ROS 在 Xavier Jetson NX 驅動的 iRobot 的 Create 3 機器人上進行部署的步驟。 Create 3 和 NVIDIA ISAAC ROS 圖像分割節點均在 ROS2 上運行。
本例使用 /isaac_ros_image_segmentation/isaac_ros_unet GitHub repo 部署空閑空間分段。
要使用自由空間分段模型,請從 /NVIDIA-ISAAC-ROS/isaac_ros_image_segmentation GitHub repo 執行以下步驟。
創建 Docker 交互式工作區:
$isaac_ros_common/scripts/run_dev.sh your_ws
克隆所有包依賴項:
isaac_ros_dnn_encodersisaac_ros_nvengine_interfaces- 推理包(您可以選擇其中一個)
isaac_ros_tensor_rtisaac_ros_triton
構建并獲取工作區的源代碼:
$cd /workspaces/isaac_ros-dev $colcon build && . install/setup.bash
從您的工作機器下載經過培訓的自由空間標識(. etlt )模型:
$scp <your_machine_ip>:<etlt_model_file_path> <ros2_ws_path>
將加密的 TLT 模型(. etlt )和格式轉換為 TensorRT 引擎計劃。對 INT8 模型運行以下命令:
tao converter -k tlt_encode \ -e trt.fp16.freespace.engine \ -p input_1,1x3x544x960,1x3x544x960,1x3x544x960 \ unet_freespace.etlt
按照以下步驟進行演練: ISAAC ROS 圖像分割 :
- 將 TensorRT 模型引擎文件保存在正確的目錄中。
- 創建
config.pbtxt. - 更新
isaac_ros_unet啟動文件中的模型引擎路徑和名稱。 - 重新生成并運行以下命令:
$ colcon build --packages-up-to isaac_ros_unet && . install/setup.bash $ ros2 launch isaac_ros_unet isaac_ros_unet_triton.launch.py
總結
在本文中,我們向您展示了一個端到端的工作流程,首先是在 NVIDIA ISAAC Sim 中生成合成數據,使用 TAO 工具包進行微調,然后使用 NVIDIA ISAAC ROS 部署模型。
NVIDIA ISAAC Sim 和 TAO Toolkit 都是抽象出人工智能框架復雜性的解決方案,使您能夠在生產中構建和部署人工智能驅動的機器人應用程序,而無需任何人工智能專業知識。
通過拉動 /NVIDIA-AI-IOT/robot_freespace_seg_Isaac_TAO GitHub 項目開始這個實驗。
?