作為人類,我們每天都在不停地移動,做一些動作,比如走路、跑步和坐著。這些行為是我們日常生活的自然延伸。構建能夠捕獲這些特定動作的應用程序在體育分析領域、醫療保健領域、零售領域以及其他領域都非常有價值。
然而,構建和部署能夠理解人類行為的時間信息的人工智能應用程序既具有挑戰性又耗時,需要大量培訓和深入的人工智能專業知識。
在這篇文章中,我們將展示如何快速跟蹤 AI 應用程序的開發,方法是采用預訓練的動作識別模型,使用 NVIDIA TAO Toolkit 自定義數據和類對其進行微調,并通過 NVIDIA DeepStream 部署它進行推理,而無需任何 AI 專業知識。
動作識別模型
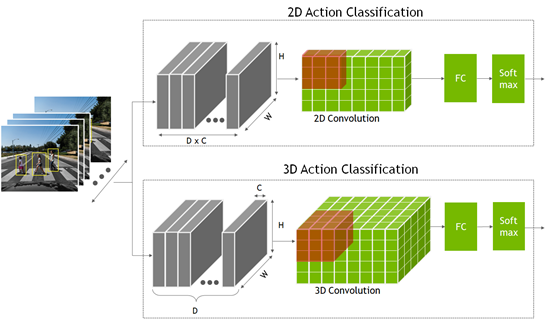
要識別一個動作,網絡不僅要查看單個靜態幀,還要查看多個連續幀。這提供了理解操作的時間上下文。這是與分類或目標檢測模型相比的額外時間維度,其中網絡僅查看單個靜態幀。
這些模型是使用二維卷積神經網絡創建的,其中的尺寸是寬度、高度和通道數。 2D 動作識別模型與其他 2D 計算機視覺模型類似,但通道維度現在也包含時間信息。
- 在 2D 動作識別模型中,將時間幀 D 與通道計數 C 相乘,形成通道維度輸入。
- 對于三維模型,添加了表示時間信息的新維度 D 。
2D 和 3D 卷積網絡的輸出進入一個完全連接的層,然后是一個 Softmax 層來預測動作。
pretrained model 是在代表性數據集上經過訓練并使用權重和偏差進行微調的數據集。 NGC catalog 提供的動作識別模型已在五個常見類別上進行了培訓:
- 行走
- 跑步
- 推
- 騎自行車
- 墜落
這是一個示例模型。更重要的是,該模型可以很容易地用自定義數據重新訓練,只需花費很少的時間和從頭開始訓練所需的數據。
預訓練模型是在 HMDB51 數據集中的幾百個短視頻剪輯上訓練的。對于模型培訓的五個類, 2D 模型的精度達到 83% , 3D 模型的精度達到 86% 。此外,如果選擇按原樣部署模型,下表顯示了各種 GPU 上的預期性能。
| Inference Performance (FPS) | 2D ResNet18 | 3D ResNet18 |
| Nano | 30 | 0.6 |
| NVIDIA Xavier NX | 250 | 5 |
| NVIDIA AGX Xavier | 490 | 33 |
| NVIDIA A30 | 5,809 | 356 |
| NVIDIA A100 | 10,457 | 640 |
在本實驗中,您將使用三個新類對模型進行微調,這些新類包含簡單動作,如俯臥撐、仰臥起坐和引體向上。您使用 HMDB51 數據集的子集,其中包含 51 個不同的操作。
先決條件
開始之前,您必須擁有以下培訓和部署資源:
- NVIDIA GPU 驅動程序版本:> 470
- NVIDIA Docker:2.5.0-1
- 云中或本地的 NVIDIA GPU :
- 英偉達 A100
- 英偉達 V100
- 英偉達 T4
- 英偉達 RTX 30×0
- 工具包 NVIDIA:3.0-21-11
- NVIDIA DeepStream:6.0
有關更多信息,請參閱 TAO 工具包快速入門指南 。
使用 TAO 工具包進行培訓、調整和優化
在本節中,您將使用 TAO 工具包使用新類對模型進行微調。
TAO 工具包使用 transfer learning ,其中使用從現有神經網絡模型學習的特征,并將其應用于新的神經網絡模型。 TAO 工具包是 NVIDIA TAO 框架 基于 CLI 和 Jupyter 筆記本的解決方案,它抽象了 AI / DL 框架的復雜性,使您能夠在沒有任何 AI 專業知識的情況下為您的用例創建定制和生產就緒的模型。
您可以在 CLI 窗口中提供簡單指令,也可以使用交鑰匙 Jupyter 筆記本進行培訓和微調。您可以使用 NGC 中的動作識別筆記本來訓練自定義的三類模型。
下載 TAO Toolkit 計算機視覺示例工作流 的 1.3 版并解壓縮包。在/action_recognition_net目錄中,找到用于動作識別培訓的 Jupyter 筆記本(actionrecognitionnet.ipynb),以及/specs目錄,其中包含用于培訓、評估和模型導出的所有規范文件。您可以為培訓配置這些等級庫文件。
啟動 Jupyter 筆記本并打開action_recognition_net/actionrecognitionnet.ipynb文件:
jupyter notebook --ip 0.0.0.0 --port 8888 --allow-root
步驟 1 :設置并安裝 TAO 工具包
所有培訓步驟都在 Jupyter 筆記本中運行。啟動筆記本后,運行筆記本中提供的 設置環境變量和映射驅動器 和 安裝 TAO 發射器 步驟。
步驟 2 :下載數據集和預訓練模型
安裝 TAO 后,下一步是下載并準備數據集進行培訓。 Jupyter 筆記本提供了下載和預處理 HMDB51 數據集的步驟。如果您有自己的自定義數據集,則可以在步驟 2.1 中使用它。
對于本文,您將使用 HMDB51 數據集中的三個類。修改幾行以添加俯臥撐、引體向上和仰臥起坐課程。
$ wget -P $HOST_DATA_DIR http://serre-lab.clps.brown.edu/wp-content/uploads/2013/10/hmdb51_org.rar $ mkdir -p $HOST_DATA_DIR/videos && unrar x $HOST_DATA_DIR/hmdb51_org.rar $HOST_DATA_DIR/videos $ mkdir -p $HOST_DATA_DIR/raw_data $ unrar x $HOST_DATA_DIR/videos/pushup.rar $HOST_DATA_DIR/raw_data $ unrar x $HOST_DATA_DIR/videos/pullup.rar $HOST_DATA_DIR/raw_data $ unrar x $HOST_DATA_DIR/videos/situp.rar $HOST_DATA_DIR/raw_data
每個類的視頻文件存儲在$HOST_DATA_DIR/raw_data下各自的目錄中。這些是經過編碼的視頻文件,必須解壓縮為幀才能訓練模型。已經提供了一個腳本來幫助您為培訓準備數據。
下載幫助程序腳本并安裝依賴項:
$ git clone https://github.com/NVIDIA-AI-IOT/tao_toolkit_recipes.git $ pip3 install xmltodict opencv-python
將視頻文件解壓縮為幀:
$ cd tao_recipes/tao_action_recognition/data_generation/ $ ./preprocess_HMDB_RGB.sh $HOST_DATA_DIR/raw_data \ $HOST_DATA_DIR/processed_data
下面的代碼示例中顯示了每個類的輸出。f cnt: 82表示此視頻剪輯已解壓縮到 82 幀。對目錄中的所有視頻執行此操作。根據類的數量以及數據集和視頻剪輯的大小,此過程可能需要一些時間。
Preprocess pullup f cnt: 82.0 f cnt: 82.0 f cnt: 82.0 f cnt: 71.0 ...
處理后的數據的格式類似于下面的代碼示例。如果您正在對自己的數據進行培訓,請確保數據集也遵循此目錄格式。
$HOST_DATA_DIR/processed_data/ |--> <Class name> |--> <Video 1> |--> rgb |--> 000001.png |--> 000002.png |--> 000003.png …
下一步是將數據拆分為培訓和驗證集。 HMDB51 數據集為每個類提供了一個拆分文件,因此只需下載該文件,并將數據集劃分為 70% 的培訓和 30% 的驗證。
$ wget -P $HOST_DATA_DIR http://serre-lab.clps.brown.edu/wp-content/uploads/2013/10/test_train_splits.rar $ mkdir -p $HOST_DATA_DIR/splits && unrar x \ $HOST_DATA_DIR/test_train_splits.rar $HOST_DATA_DIR/splits
使用助手腳本split_dataset.py拆分數據。這僅適用于 HMDB 數據集提供的拆分文件。如果您正在使用自己的數據集,那么這將不適用。
$ cd tao_recipes/tao_action_recognition/data_generation/ $ python3 ./split_dataset.py $HOST_DATA_DIR/processed_data \ $HOST_DATA_DIR/splits/testTrainMulti_7030_splits $HOST_DATA_DIR/train \ $HOST_DATA_DIR/test
用于培訓的數據在$HOST_DATA_DIR/train下,用于測試和驗證的數據在$HOST_DATA_DIR/test下。
準備好數據集后,從 NGC 下載預訓練模型。按照 Jupyter 筆記本 2.1 中的步驟操作。
$ ngc registry model download-version "nvidia/tao/actionrecognitionnet:trainable_v1.0" --dest $HOST_RESULTS_DIR/pretrained
步驟 3 :配置培訓參數
spec YAML 文件中提供了培訓參數。在/ specs 目錄中,查找所有用于培訓、微調、評估、推斷和導出的 spec 文件。對于培訓,您可以使用train_rgb_3d_finetune.yaml。
對于本實驗,我們將向您展示一些可以修改的超參數。有關所有不同參數的更多信息,請參閱 ActionRecognitionNet 。
您還可以在運行時覆蓋任何參數。大多數參數保留為默認值。下面的代碼塊中突出顯示了正在更改的少數代碼。
## Model Configuration model_config: model_type: rgb input_type: "3d" backbone: resnet18 rgb_seq_length: 32 ## Change from 3 to 32 frame sequence rgb_pretrained_num_classes: 5 sample_strategy: consecutive sample_rate: 1 # Training Hyperparameter configuration train_config: optim: lr: 0.001 momentum: 0.9 weight_decay: 0.0001 lr_scheduler: MultiStep lr_steps: [5, 15, 25] lr_decay: 0.1 epochs: 20 ## Number of Epochs to train checkpoint_interval: 1 ## Saves model checkpoint interval ## Dataset configuration dataset_config: train_dataset_dir: /data/train ## Modify to use your train dataset val_dataset_dir: /data/test ## Modify to use your test dataset
第四步:訓練你的人工智能模型
對于培訓,請遵循 Jupyter 筆記本中的步驟 4 。設置環境變量。
訓練動作識別的 TAO 工具包任務稱為action_recognition。要進行培訓,請使用tao action_recognition train命令。指定培訓規范文件,并提供輸出目錄和預培訓模型。或者,也可以在model_config規范中設置預訓練模型。
$ tao action_recognition train \ -e $SPECS_DIR/train_rgb_3d_finetune.yaml \ -r $RESULTS_DIR/rgb_3d_ptm \ -k $KEY \ model_config.rgb_pretrained_model_path=$RESULTS_DIR/pretrained/actionrecognitionnet_vtrainable_v1.0/resnet18_3d_rgb_hmdb5_32.tlt ognition train \
根據您的 GPU 、序列長度或年代,這可能需要幾分鐘到幾小時的時間。因為要保存每個歷元,所以可以看到與歷元數量相同的模型檢查點。
模型檢查點另存為ar_model_epoch=<EPOCH NUM>-val_loss=<VAL LOSS>.tlt。選擇模型評估和導出的最后一個歷元,但可以使用驗證損失最小的歷元。
步驟 5 :評估經過培訓的模型
有兩種不同的抽樣策略來評估視頻剪輯上的訓練模型:
- Center mode: 拾取序列的中間幀進行推斷。例如,如果模型需要 32 幀作為輸入,而視頻剪輯有 128 幀,則可以從索引 48 到索引 79 中選擇幀進行推斷。
- Conv mode: 對單個視頻中的 10 個序列進行卷積采樣并進行推斷。結果取平均值。
對于評估,請使用/specs目錄中提供的評估規范文件(evaluate_rgb.yaml)。這就像訓練配置。修改dataset_config參數以使用您正在培訓的三個類。
dataset_config: ## Label maps for new classes. Modify this for your custom classes label_map: pushup: 0 pullup: 1 situp: 2
使用tao action_recognition evaluate命令進行計算。如前所述,對于video_eval_mode,您可以在中心模式或 conv 模式之間進行選擇。使用訓練運行中最后保存的模型檢查點。
$ tao action_recognition evaluate \ -e $SPECS_DIR/evaluate_rgb.yaml \ -k $KEY \ model=$RESULTS_DIR/rgb_3d_ptm/ar_model_epoch=<EPOCH NUM>-val_loss=<VAL LOSS>.tlt \ batch_size=1 \ test_dataset_dir=$DATA_DIR/test \ video_eval_mode=center
評價產出:
100%|███████████████████████████████████████████| 90/90 [00:03<00:00, 29.82it/s] ******************************* pushup 56.67 pullup 100.0 situp 90.0 ******************************* Total accuracy: 82.222 Average class accuracy: 82.222 2021-11-17 17:46:52,590 [INFO] tlt.components.docker_handler.docker_handler: Stopping container.
這是在 90 個視頻數據集上評估的,該數據集包含所有三個動作的剪輯。總體準確率約為 82% ,這對于數據集的大小來說是合適的。數據集越大,模型的通用性越好。您可以嘗試使用自己的剪輯測試準確性。
步驟 6 :導出以進行 DeepStream 部署
最后一步是導出用于部署的模型。要導出,請運行tao action_recognition export命令。您必須提供導出規范文件,該文件作為export_rgb.yaml包含在/specs目錄中。修改export_rgb.yaml中的dataset_config值,以使用您培訓的三個類。這類似于evaluate_rgb.yaml中的dataset_config。
$ tao action_recognition export \ -e $SPECS_DIR/export_rgb.yaml \ -k $KEY \ model=$RESULTS_DIR/rgb_3d_ptm/ar_model_epoch=<EPOCH NUM>-val_loss=<VAL LOSS>.tlt \ /export/rgb_resnet18_3.etlt
祝賀您,您已成功培訓了自定義 3D 動作識別模型。現在,使用 DeepStream 部署此模型。
使用 DeepStream 部署
在本節中,我們將展示如何使用 NVIDIA DeepStream 部署經過微調的模型。
DeepStream SDK 幫助您快速構建高效、高性能的視頻 AI 應用程序。 DeepStream 應用程序可以在由 NVIDIA Jetson 提供動力的邊緣設備、本地服務器或云中運行。
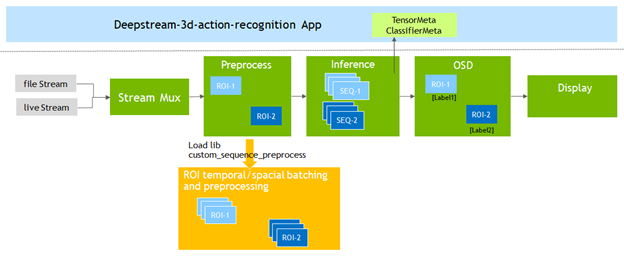
為了支持動作識別模型, DeepStream 6.0 添加了Gst-nvdspreprocess插件。該插件加載一個自定義庫( custom _ sequence _ preprocess.so ),以執行時間序列捕獲和感興趣區域( ROI )部分批處理,然后將批處理的張量緩沖區轉發給下游推理插件。
您可以修改 DeepStream SDK 中包含的deepstream-3d-action-recognition應用程序,以測試使用 TAO 微調的模型。
示例應用程序同時對四個視頻文件運行推斷,并以 2 × 2 平鋪顯示結果。
在進行修改之前,先運行標準應用程序。首先,啟動 DeepStream 6.0 開發容器:
$ xhost +
$ docker run --gpus '"'device=0'"' -it -v /tmp/.X11-unix:/tmp/.X11-unix -e DISPLAY=$DISPLAY -w /opt/nvidia/deepstream/deepstream-6.0 nvcr.io/nvidia/deepstream:6.0-devel
有關 NVIDIA 提供的 DeepStream 集裝箱的更多信息,請參閱 NGC catalog 。
在容器中,導航到 3D 動作識別應用程序目錄,從 NGC 下載并安裝標準 3D 和 2D 模型。
$ cd sources/apps/sample_apps/deepstream-3d-action-recognition/
$ wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/tao/actionrecognitionnet/versions/deployable_v1.0/zip -O actionrecognitionnet_deployable_v1.0.zip
$ unzip actionrecognitionnet_deployable_v1.0.zip
現在,您可以使用 3D 推理模型執行應用程序并查看結果。
$ deepstream-3d-action-recognition -c deepstream_action_recognition_config.txt

預處理器插件配置
在修改應用程序之前,請熟悉運行應用程序所需的預處理器插件的關鍵配置參數。
從/app/sample_apps/deepstream-3d-action-recognition文件夾中,打開config_preprocess_3d_custom.txt文件并查看三維模型的預處理器配置。
第 13 行定義了三維模型所需的 5 維輸入形狀:
network-input-shape = 4;3;32;224;224
對于此應用程序,您將使用四個輸入,每個輸入有一個 ROI :
- 您的批次號為 4 (#輸入*每個輸入的 ROI )。
- 您的輸入是 RGB ,因此通道數為 3 。
- 序列長度為 32 ,輸入分辨率為 224 × 224 ( HxW )。
第 18 行告訴預處理器庫您正在使用自定義序列:
network-input-order = 2
第 51 行和第 52 行定義了如何將幀傳遞給推理機:
stride=1
subsample=0
subsample值為 0 意味著您按順序將幀(第 1 幀、第 2 幀……)傳遞到推斷步驟。stride值為 1 表示序列之間存在單個幀的差異。例如:- 序列 A :幀 1 , 2 , 3 , 4 …
- 序列 B :幀 2 , 3 , 4 , 5 …
最后,第 55-60 行定義了輸入和 ROI 的數量:
src-ids=0;1;2;3
process-on-roi=1
roi-params-src-0=0;0;1280;720
roi-params-src-1=0;0;1280;720
roi-params-src-2=0;0;1280;720
roi-params-src-3=0;0;1280;720
有關所有應用程序和預處理器參數的更多信息,請參閱 DeepStream 文檔的 Action Recognition 部分。
運行新模型
現在,您可以修改應用程序配置并測試練習動作識別模型。
因為您使用的是 Docker 映像,所以在主機文件系統和容器之間傳輸文件的最佳方法是在啟動容器以設置可共享位置時使用-v mount標志。例如,使用-v /home:/home將主機的/home目錄裝載到容器的/home目錄。
將新模型、標簽文件和文本視頻復制到/app/sample_apps/deepstream-3d-action-recognition folder.
# back up the original labels file $ cp ./labels.txt ./labels_bk.txt $ cp /home/labels.txt ./ $ cp /home/Exercise_demo.mp4 ./ $ cp /home/rgb_resnet18_3d_exercises.etlt ./
打開deepstream_action_recognition_config.txt并將第 30 行更改為指向運動測試視頻。
uri-list=file:////opt/nvidia/deepstream/deepstream-6.0/sources/apps/sample_apps/deepstream-3d-action-recognition/Exercise_demo.mp4
打開config_infer_primary_3d_action.txt并將第 63 行用于推斷的模型和第 68 行的批次大小從 4 更改為 1 ,因為您將從四個輸入更改為一個輸入:
tlt-encoded-model=./rgb_resnet18_3d_exercises.etlt .. batch-size=1
最后,打開config_preprocess_3d_custom.txt。更改network-input-shape值以反映第 35 行上運動識別模型的單個輸入和配置:
network-input-shape= 1;3;3;224;224
修改第 77 – 82 行中單個輸入和 ROI 的源設置:
src-ids=0
process-on-roi=1
roi-params-src-0=0;0;1280;720
#roi-params-src-1=0;0;1280;720
#roi-params-src-2=0;0;1280;720
#roi-params-src-3=0;0;1280;720
現在可以使用以下命令測試新模型:
$ deepstream-3d-action-recognition -c deepstream_action_recognition_config.txt

應用程序源代碼
動作識別示例應用程序使您能夠靈活地更改輸入源、輸入數量和使用的模型,而無需修改應用程序源代碼。
要查看應用程序是如何實現的,請參閱/sources/apps/sample_apps/deepstream-3d-action-recognition文件夾中的應用程序源代碼以及預處理器插件使用的自定義序列庫。
總結
在這篇文章中,我們分別使用 TAO Toolkit 和 DeepStream 向您展示了一個端到端的工作流程,用于微調和部署動作識別模型。 TAO 工具包和 DeepStream 都是抽象出 AI 框架復雜性的解決方案,使您能夠在生產中構建和部署 AI 應用程序,而無需任何 AI 專業知識。
通過從 NGC catalog 下載模型,開始使用動作識別模型。
有關更多信息,請參閱以下參考資料:
- 開始使用 TAO 工具包
- 開始使用 DeepStream SDK
- 使用 DeepStream 6.0 加速下一代人工智能應用程序的開發 GTC 會議
- Train, 適應, 優化使用 NVIDIA TAO Toolkit 增強您的 AI 開發工作流和應用程序開發 GTC 會議
?