
智能城市代表了城市生活的未來。然而,它們可能會給城市規劃者帶來各種挑戰,尤其是在交通領域。為了取得成功,城市的各個方面——從環境和基礎設施到商業和教育——必須在功能上進行整合。
這可能很困難,因為單獨管理交通流量是一個復雜的問題,充滿了擁堵、事故應急響應和排放等挑戰。
為了應對這些挑戰,開發人員正在開發具有現場可編程性和靈活性的人工智能軟件。這些軟件定義的物聯網解決方案可以應用于實時環境,如交通管理,車牌識別,智能停車和事故檢測等。
盡管如此,建立有效的人工智能模型說起來容易做起來難。遺漏值、重復示例、錯誤標簽和錯誤特征值是訓練數據的常見問題,這些問題可能導致模型不準確。在自動駕駛汽車的情況下,不準確的結果可能是危險的,也可能導致交通系統效率低下或城市規劃不佳。
實時城市交通的數字孿生
端到端人工智能工程公司 SmartCow,作為 NVIDIA Metropolis 的合作伙伴,已在 數字孿生技術上創建了交通場景,這些場景在 NVIDIA Omniverse 中進行模擬。這些數字孿生技術可以用于設置并驗證 AI 模型的性能,使用的是 合成數據。
該團隊正在使用 NVIDIA Omniverse Replicator。
所有 Omniverse 擴展的基礎是被稱為 OpenUSD 的 Universal Scene Description (USD)。USD 是一個功能強大的交換平臺,具有高度可擴展的屬性,虛擬世界就是在其上構建的。智能城市的數字孿生依賴于 USD 的高度可擴展和可互操作的功能,用于精確模擬真實世界的大型高保真場景。
Omniverse Replicator 是 Omniverse 平臺的核心擴展,使開發人員能夠以編程方式生成帶注釋的合成數據,以引導人工智能模型感知的訓練。當真實數據集有限或難以獲得時,合成數據尤其有用。
通過使用數字孿生, SmartCow 團隊生成了準確表示真實世界交通場景和違規行為的合成數據。這些合成數據集有助于驗證人工智能模型并優化人工智能訓練管道。
建設車牌檢測分機
智能交通管理系統面臨的最重大挑戰之一是車牌識別。開發一個適用于具有不同規則、法規和環境的各種國家和市鎮的模型需要多樣化和穩健的培訓數據。為了為模型提供足夠和多樣化的訓練數據, SmartCow 在 Omniverse 中開發了一個擴展,以生成合成數據。
Omniverse 中的擴展是可重復使用的組件或工具,它們提供強大的功能以增強管道和工作流。在Omniverse Kit中構建擴展后,開發人員可以輕松地將其分發給客戶,以便在Omniverse USD Composer,Omniverse USD Presenter和其他應用程序中使用。
SmartCow 的擴展名為車牌合成生成器( LP-SDG ),使用環境隨機化器和物理隨機化器使合成數據集更加多樣化和逼真。
環境隨機化器模擬數字孿生環境中的照明、天氣和其他因素的變化,如雨、雪、霧或灰塵。物理隨機發生器模擬可能影響模型識別車牌號碼能力的劃痕、污垢、凹痕和變色。
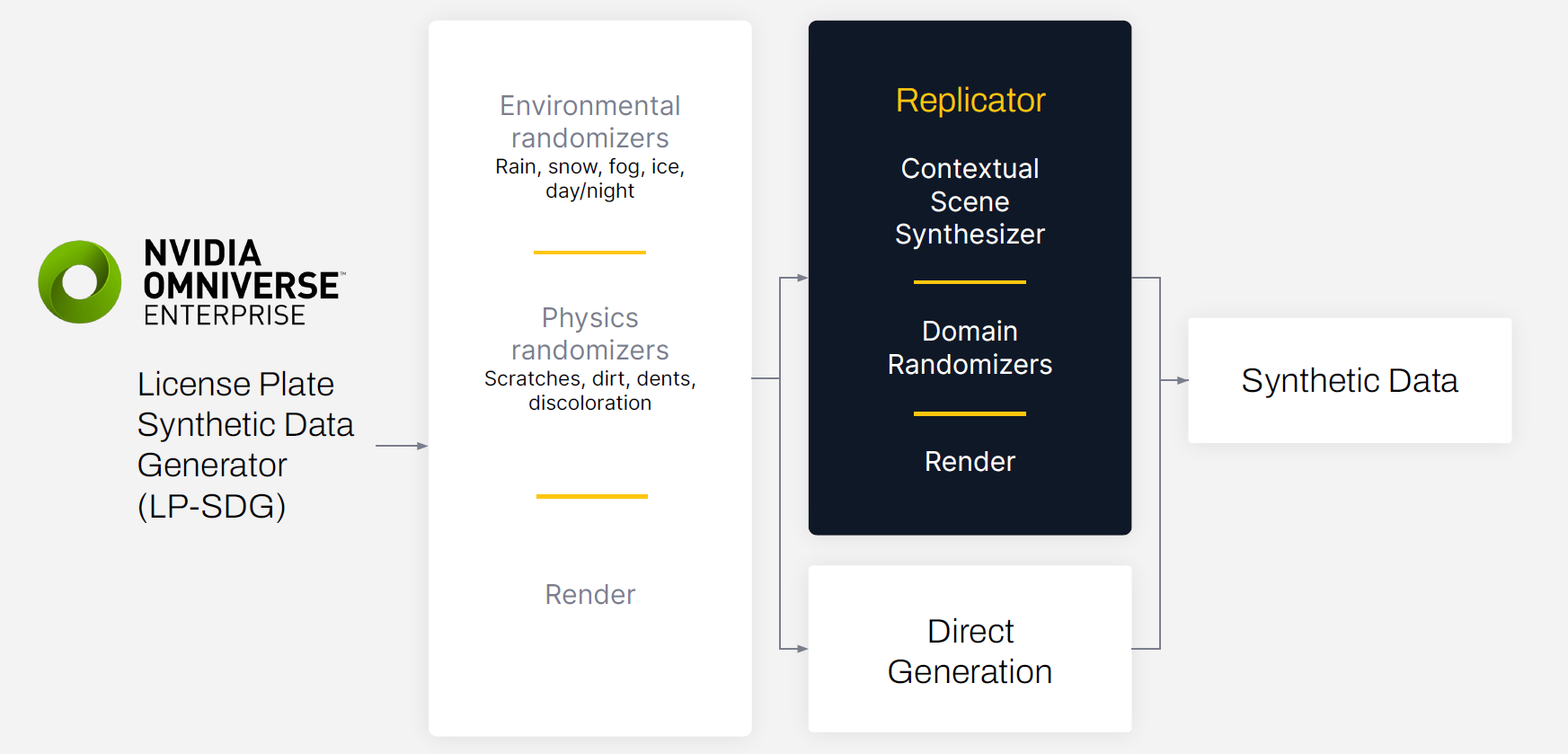
使用 NVIDIA Omniverse Replicator 生成合成數據
數據生成過程從 Omniverse 中創建 3D 環境開始。 Omniverse 中的數字孿生可以用于許多模擬場景,包括生成合成數據。最初的 3D 場景是由 SmartCow 的內部技術藝術家構建的,確保了數字孿生的匹配?現實盡可能好。

在生成場景后,我們使用域隨機化來改變光源、紋理、攝像機位置和材質。這整個過程都是通過使用內置的Omniverse Replicator APIs來完成的。
生成的數據導出時帶有邊界框注釋和訓練所需的其他輸出變量。
模型培訓
最初的模型是在 3000 張真實圖像上訓練的。目標是了解基準模型性能,并驗證正確的邊界框尺寸和光線變化等方面。
接下來,該團隊進行了實驗,在 3000 個樣本、 30000 個樣本和 300000 個樣本的合成數據集上比較基準。

SmartCow 的軟件工程師 Natalia Mallia 說:“通過 Omniverse 獲得的真實感,在合成數據上訓練的模型偶爾會優于在真實數據上訓練。”。“使用合成數據實際上消除了真實圖像訓練數據集中自然存在的偏見。”
為了提供準確的基準測試和比較,該團隊在對三種大小的合成數據集進行訓練時,將數據隨機分配到一致的參數中,如一天中的時間、劃痕和視角。為了保持相對準確性,真實世界的數據沒有與用于訓練的合成數據混合。每個模型都是根據大約 1000 幅真實圖像的數據集進行驗證的。
SmartCow 的團隊將 Omniverse LP-SDG 擴展的訓練數據與 NVIDIA TAO,一個低代碼的人工智能模型訓練工具包,結合使用,并利用遷移學習的力量對模型進行微調。
該團隊使用了 NGC 目錄,并利用 TAO 對 NVIDIA DGX A100 系統進行了微調。
NVIDIA 的模型部署〔 DeepStream 〕
然后,人工智能模型將被部署到自定義邊緣設備上,使用 NVIDIA DeepStream SDK。
然后,他們實現了一個連續學習循環,包括從邊緣設備收集漂移數據,將數據反饋到 Omniverse Replicator ,并合成可重新訓練的數據集,這些數據集通過自動標記工具傳遞并反饋到 TAO 進行訓練。
這種閉環管道有助于創建準確有效的人工智能模型,用于自動檢測每條車道上的交通方向以及任何停滯異常時間的車輛。
開始使用合成數據、數字孿生和人工智能智慧城市交通管理
生成合成數據集和驗證人工智能模型性能的數字雙工作流是在智能城市中為交通構建更有效的人工智能模型的重要一步。使用合成數據集有助于克服有限數據集的挑戰,并提供準確有效的人工智能模型,從而實現高效的交通系統和更好的城市規劃。
如果您希望直接采用此解決方案,請查看SmartCow RoadMaster和SmartCow PlateReader的解決方案。
如果您是一名對構建自己的合成數據生成解決方案感興趣的開發人員,可以免費下載 NVIDIA Omniverse 并嘗試 Omniverse Code 中的 Replicator API。歡迎加入NVIDIA 開發者論壇的討論。
參加NVIDIA at SIGGRAPH 2023,了解圖形、Open USD 和 AI 的最新進展。記得保存會議日期,并查看“利用通用場景描述加速自動駕駛汽車和機器人的開發”的演講。
下載標準許可證,開始使用NVIDIA Omniverse,或學習如何Omniverse 企業可以連接您的團隊。如果你是一名開發人員,開始使用 Omniverse 資源。通過訂閱新聞稿、 Twitch ,以及YouTube通道。
?






