
NVIDIA 最近發布了 SIGGRAPH Asia 2023 的研究論文,SLANG.D:快速、模塊化和可微分的著色器編程。這篇論文展示了一種語言如何作為一個統一的平臺進行實時、反向和可微分的繪制。這項工作是麻省理工學院、加州大學圣地亞哥分校、華盛頓大學和 NVIDIA 研究人員的合作成果。
這是關于可微分俚語系列的一部分。有關 Slang 與各種機器學習( ML )渲染應用程序的實際示例的更多信息,請參閱 Differential Slang:應用實例。
Slang 是一種用于實時圖形編程的開源語言,它為編寫和維護大規模、高性能、跨平臺的圖形代碼庫帶來了新的功能。Slang 使現代語言結構適應實時圖形的高性能需求,并為 Direct 3D 12、Vulkan、OptiX、CUDA 和 CPU 生成代碼。
雖然 Slang 最初是一個研究項目,但現在已經發展成為一個實用的解決方案,被用于 NVIDIA Omniverse 和 NVIDIA RTX Remix 渲染器,以及 NVIDIA Game Works Falcor 研究基礎設施。
這項新研究開創了一種共同設計的方法。這種方法表明,如果將差異化作為一等公民納入整個系統,那么可以很好地處理自動差異化的復雜性:
- 語言
- 類型系統
- 中間表示(IR)
- 優化過程
- 自動完成引擎
Slang 的自動差異化與 Slang 的模塊化編程模型、GPU 圖形管道、Python 和 PyTorch 無縫集成。Slang 支持區分任意控制流、用戶定義類型、動態調度、泛型和全局內存訪問。使用 Slang,可以使現有的實時渲染器變得可微分 并且可以在沒有重大源代碼更改的情況下學習。
連接計算機圖形學和機器學習
數據驅動的渲染算法正在改變計算機圖形,為shape,textures,volumetrics,materials和post-processing提高性能和圖像質量的算法。與此同時,計算機視覺和 ML 研究人員越來越多地利用計算機圖形學來改進三維重建通過反向渲染。
由于不同的工具、庫、編程語言和編程模型,連接實時圖形、ML 和計算機視覺開發環境具有挑戰性。憑借最新研究,Slang 使您能夠輕松完成以下任務:
- 將學習融入渲染。Slang 使圖形開發人員能夠使用基于梯度的優化,并以數據驅動的方式解決傳統的圖形問題,例如,使用基于外觀的優化來學習 mipmap 層次結構。
- 從現有的圖形代碼中構建可微分的渲染器。 我們使用 Slang 將預先存在的實時路徑跟蹤器轉換為可微分路徑跟蹤器,重用了 90% 的 Slang 代碼。
- 將圖形引入 ML 培訓框架。Slang 從圖形著色器代碼生成自定義 PyTorch 插件。在這篇文章中,我們演示了如何在Nvdiffrec中生成自動區分的 CUDA 內核。
- 在渲染器中引入 ML 培訓 Slang 可以幫助在實時渲染器中訓練小型神經網絡,例如神經輻射緩存。
可微分編程和機器學習需要梯度



圖 1 顯示了斯坦福兔子被放置在康奈爾大學的盒子里。左列顯示渲染的場景。中間一列顯示了關于兔子在 y 軸上的平移的參考導數。右欄顯示了由 Slang 的 autodiff 功能計算的相同導數,它看起來與參考圖像相同。
ML 方法的一個關鍵支柱是基于梯度的優化。具體來說,大多數 ML 算法由反向模式自動微分,是通過一系列計算傳播導數的有效方法。這不僅適用于大型神經網絡,也適用于許多需要使用梯度和梯度下降的更簡單的數據驅動算法。
像 PyTorch 這樣的框架公開了對張量(多維矩陣)的高級操作,這些張量帶有手動編碼的反向模式內核。當你組成張量運算來創建神經網絡時,PyTorch 會通過鏈接這些內核來自動組成導數計算。其結果是一個易于使用的系統,您不必手動編寫梯度流,這也是 ML 研究加快步伐的原因之一。
不幸的是,一些計算不容易被數組上的高級操作捕獲,這給高效表達它們帶來了困難。光柵化器或光線跟蹤器等圖形組件就是這種情況,其中發散的控制流和復雜的訪問模式需要大量低效的主動掩模跟蹤和其他解決方案。這些解決方案不僅難以寫入和讀取,而且還具有顯著的性能和內存使用開銷。
因此,大多數高性能可微分圖形管道,例如 nvdiffrec,InstantNGP 和 Gaussian splatting,并非完全使用純 Python 編寫。相反,研究人員會選擇更接近底層硬件的語言,如 CUDA、HLSL 或 GLSL,來編寫高性能內核。
因為這些語言不提供自動區分,所以這些應用程序使用手工派生的漸變。手工微分是乏味的,容易出錯,使其他人很難使用或修改這些算法。這就是 Slang 的用武之地,因為它可以自動為多個后端生成差異化著色器代碼。
設計 Slang 的自動微分
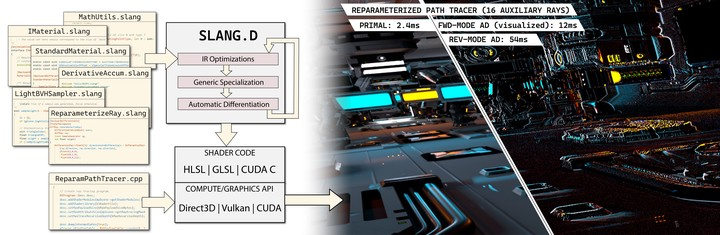
圖 2 顯示了 Zero Day 場景中的傳播導數,該導數由 Falcor 框架 的可微分路徑跟蹤器構建,它是通過重用超過 5K 行的預先存在的著色器代碼來實現的。
Slang 的起源可以追溯到 Spark 在 SIGGRAPH 2011 上展示的編程語言,以其當前的形式在 SIGGRAPH 2018 上展示。為 Slang 添加自動差異化需要多年的研究和多次語言設計迭代。語言和編譯器的每一部分——包括解析器、類型系統、標準庫、IR、優化過程和 Intellisense 引擎——都需要進行修改,以支持自動 diff 作為語言的一級成員。
Slang 的類型系統已經擴展,將可微性視為函數和類型的一種屬性。這個類型系統允許在編譯時進行檢查,以防止在使用可微編程框架時出現常見錯誤,例如無意中通過調用不可微函數刪除導數。我們在技術論文中描述了這些以及更多的挑戰和解決方案,SLANG.D:快速、模塊化和可微分著色器編程。
在 Slang 中,自動微分被表示為函數上的可組合算子。應用自動微分于一個函數會產生另一個函數,這個函數可以像任何其他函數一樣被使用。這種功能設計實現了高階差分,這在許多其他框架中是不存在的。能夠在正向和反向模式的任何組合中多次區分函數的能力,大大簡化了高級渲染算法的實現,例如翹曲區取樣和Hessian 哈密頓 MLT。
Slang 的標準庫也得到了擴展,以支持可微計算,并且大多數現有的 HLSL 內部函數都被視為可微函數,允許使用這些內部函數的現有代碼在不進行修改的情況下自動進行區分。
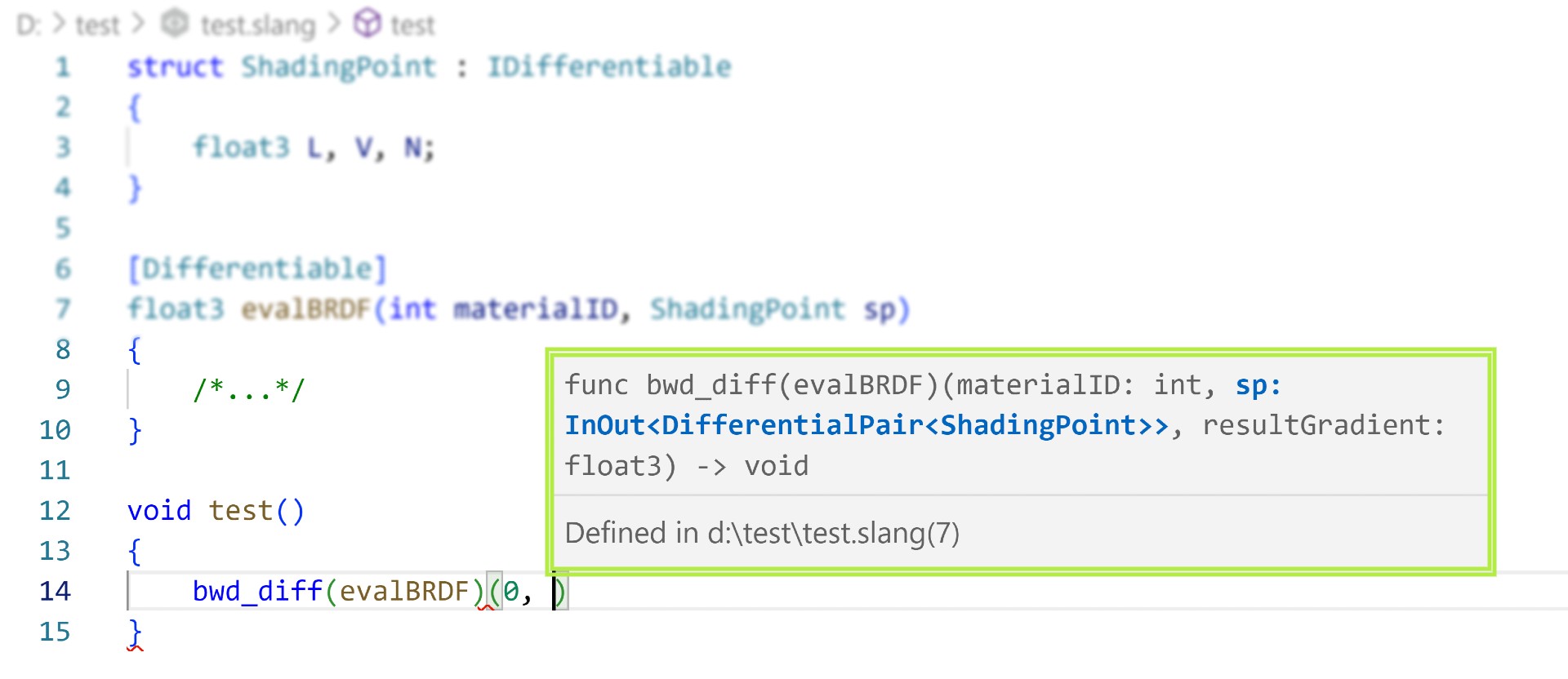
Slang 提供了一個完整的開發工具集,包括 Visual Studio 代碼擴展,具有對可微分實體的全面提示和自動完成支持,這提高了我們內部項目的生產力。
可微編程生態系統中的實時圖形
Slang 編譯器可以發出以下語言的派生函數代碼:
- HLSL:用于 Direct3D 管道。
- GLSL 或 SPIR-V:這兩種都是用于 OpenGL 和 Vulkan 的。
- CUDA 或 OptiX:適用于獨立應用程序、Python 或 PyTorch 等張量框架。
- 標量 C++:用于調試。
可以向多個目標發射相同的代碼。例如,您可以使用 PyTorch 優化器訓練高效的模型,然后將它們部署在 Vulkan 或 Direct3D 上運行的視頻游戲或其他交互式體驗中,而無需編寫新的或不同的代碼。用一種語言編寫的單一表示對于長期代碼維護和避免兩個版本細微不同時出現的錯誤非常有益。
類似于 NVIDIA WARP 框架 對于可微分模擬,Slang 為不斷增長的可微分編程生態系統做出了貢獻。Slang 允許自動生成導數,并將其與較低級別和較高級別的編程環境一起使用。可以將 Slang 與手寫的、經過大量優化的 CUDA 內核一起使用 庫。
如果您更傾向于使用高級方法,并希望使用 Python 交互式筆記本進行研究和實驗,您可以通過 slangpy 包(pip 安裝 slangpy)在 Jupyter 筆記本等環境中使用。Slang 可以成為豐富的筆記本、Python、PyTorch 和 NumPy 生態系統的一部分,與各種格式的數據進行交互,使用小部件與數據交互,并通過繪圖和數據分析庫進行可視化,同時提供更適合某些應用程序的附加編程模型。
張量與著色語言
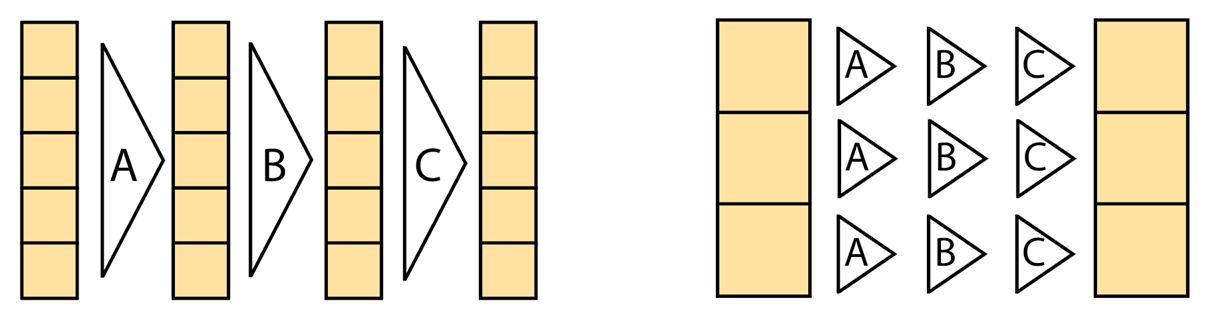
PyTorch 和其他基于張量的庫,如 NumPy、TensorFlow 和 Jax,提供了與 Slang 以及通常的著色語言截然不同的編程模型。PyTorch 主要用于前饋神經網絡,其中對每個元件的操作是相對一致的,而沒有發散的控制流。NumPy 和 PyTorch n 維陣列(ndarray)模型對整個張量進行運算,使得指定水平約簡(如軸上求和和和大矩陣乘法)變得微不足道。
相比之下,著色語言占據了光譜的另一端,并暴露了單指令多線程(SIMT)模型,使您能夠指定在單個元素或一小塊元素上運行的程序。這使得表達復雜的控制流變得容易,其中每組元素執行一系列截然不同的操作,例如當路徑跟蹤器的光線撞擊不同的表面并為其下一次反彈執行不同的邏輯時。
這兩個模型共存,應該被視為互補的,因為它們實現了不同的目標:張量上的降和運算需要一行 ndarray 代碼,但需要數百行代碼和多個內核啟動才能以 SIMT 風格高效表達。
相反,使用動態循環和停止條件,可以以 SIMT 風格優雅地編寫可變步長的射線標記,但相同的射線標記將演變為復雜且不可維護的主動掩模跟蹤 ndarray 代碼。這樣的代碼不僅很難寫和讀,而且可能會執行得更糟,因為根據活動狀態,每個分支都會針對每個元素執行,而不是只執行一個或另一個。
性能優勢
PyTorch 和其他 ML 框架是為大型神經網絡的訓練和推理而構建的。他們使用經過大量優化的平臺庫來執行大型矩陣乘法和卷積運算。
雖然每個單獨的操作都非常高效,但它們之間的中間數據被序列化到主內存并進行檢查點操作。在訓練過程中,前向和反向傳播傳球是連續和單獨計算的。這使得 PyTorch 的開銷對于實時圖形中的微小神經網絡和其他可微編程用途來說意義重大。
Slang 的自動微分功能使您能夠控制梯度值的存儲、累積和計算方式,從而實現顯著的性能和內存優化。通過避免多次內核啟動、過多的全局內存訪問和不必要的同步,與使用標準 PyTorch 操作編寫的相同小型網絡和圖形工作負載相比,它能夠融合前向和后向傳遞以及高達 10 倍的訓練加速。
這種加速不僅加快了 ML 模型的訓練,而且使許多新的應用程序能夠在圖形工作負載中使用較小的內聯神經網絡。內聯神經網絡開辟了計算機圖形學研究的一個全新領域,如神經輻射緩存、神經紋理壓縮和神經外觀模型。
放碼過來!
有關 Slang 的開源存儲庫和 slangpy Python 包,請參閱 /shader-slang GitHub 倉庫和 用俚語寫 PyTorch 內核。自動區分語言功能記錄在 俚語用戶指南。我們還包括了幾個 Slang 的可微教程,這些教程在介紹 Slang 面向對象的可微編程模型的同時,也介紹了 Slang 中常見圖形組件的代碼。
如果你想了解更多關于 Slang 和 PyTorch 的教程,可以使用 slangpy,請參閱以下資源:
想要查看更多示例,請訪問 可微分俚語:應用實例。
結論
差分渲染是計算機圖形學、計算機視覺和圖像合成的強大工具。盡管研究人員多年來一直在提高其能力、構建系統并探索應用程序,但最終形成的系統很難與現有的大型代碼庫相結合。現在,對于 Slang,現有的實時渲染器可以變得可微分。
Slang 極大地簡化了將著色器代碼添加到 ML 管道,反之亦然,將學習組件添加到渲染管道。
實時渲染專家現在可以探索構建 ML 渲染組件,而無需重寫 ML 框架中的渲染代碼。Slang 促進了數據驅動的資產優化和改進,并有助于研究傳統渲染中的新型神經組件。
另一方面,ML 研究人員現在可以利用現有的渲染器和具有復雜著色器的資源,并在新的架構中融入富有表現力的最先進的著色模型。
我們期待看到實時圖形和機器學習如何為新的真實感神經和數據驅動技術做出貢獻。有關 Slang 的自動區分功能的更多信息,請參閱 SLANG.D:快速、模塊化和可微分著色器編程 的論文。
?





