NVIDIA 發布了 CUDA 開發環境 CUDA 11 . 4 的最新版本。此版本包括 GPU – 加速庫、調試和優化工具、編程語言增強功能,以及一個運行庫,用于跨 CPU 主要體系結構( x86 、 Arm 和 POWER )在 GPU 上構建和部署應用程序。
CUDA 11 . 4 專注于增強您的 CUDA 應用程序的編程模型和性能。 CUDA 繼續推動 GPU 加速的邊界,并為 HPC 、圖形、 CAE 應用、 AI 和深度學習、汽車、醫療和數據科學中的新應用奠定基礎。
CUDA 11 . 4 有幾個重要特性。這篇文章概述了關鍵功能:
- CUDA 編程模型增強功能:
- CUDA 圖
- 多進程服務( MPS )
- 形式化異步數據移動
- C ++語言支持 – CUDA
- 編譯器增強功能
- CUDA 驅動程序增強功能
CUDA 11 . 4 附帶 R470 驅動程序,它是 長期支助處 。 GPU 直接 RDMA 和 GPU 直接技術存儲( GDS )現在是 CUDA 驅動程序和工具包的一部分。這簡化了工作流程,使我們的開發人員能夠利用這些技術,而無需單獨安裝其他軟件包。該驅動程序為最近推出的 NVIDIA A30 GPU 啟用了新的 MIG 配置 ,使每個 MIG 片的內存增加了一倍。這使得 A30 GPU 上的各種工作負載具有更高的峰值性能,尤其是 AI 推理工作負載。
CUDA 編程模型增強
此版本引入了關鍵增強功能,以提高 CUDA 圖形的性能,而無需對應用程序進行任何修改或任何其他用戶干預。它還提高了多進程服務( MPS )的易用性。我們在 CUDA 編程指南中正式定義了 異步編程模型 。
CUDA 圖
減少圖形啟動延遲是開發人員社區的常見要求,特別是在具有實時約束的應用程序中,如 5G 電信工作負載或 AI 推理工作負載。 CUDA 11 . 4 在減少 CUDA 圖形啟動時間方面提供了性能改進。此外,我們還集成了 CUDA 11 . 2 中引入的流順序內存分配功能。
有關更多信息,請參閱 CUDA 工具包編程指南中的 CUDA 圖 和 CUDA 圖形入門 。
性能改進
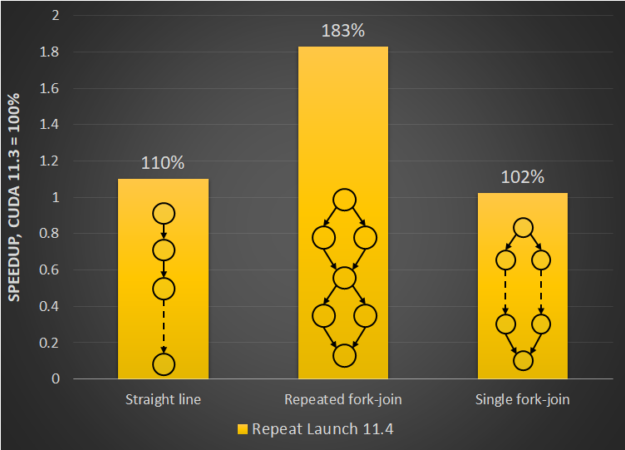
CUDA 圖形非常適合于多次執行的工作負載,因此,在為工作負載選擇圖形時,一個關鍵的折衷辦法是將創建圖形的成本分攤到重復啟動上。重復次數或迭代次數越多,性能改進越大。
在 CUDA 11 . 4 中,我們對 CUDA 圖形內部進行了兩項關鍵更改,進一步提高了啟動性能。 CUDA 圖形已經避開了流,以實現更低的延遲運行時執行。我們對此進行了擴展,甚至在啟動階段也繞過了流,將圖形作為單個工作塊直接提交給硬件。對于單線程和多線程應用程序,我們已經看到了這些主機改進帶來的良好性能提升。
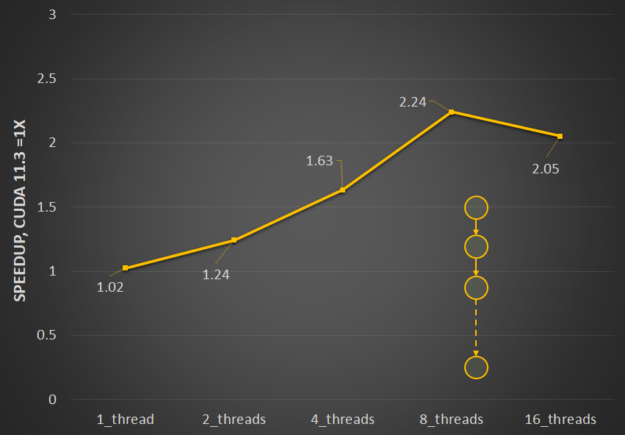
圖 1 顯示了重新啟動不同圖形模式的啟動延遲的相對改進。對于具有 fork 或 join 模式的圖,有很大的好處。
多線程啟動性能尤其受到并行啟動多個圖形時發生的資源爭用的影響。我們已經優化了線程間鎖定以減少爭用,因此多線程啟動現在效率顯著提高。圖 2 顯示了 CUDA 11 . 4 中為緩解資源爭用而進行的更改的相對性能優勢,以及它如何隨線程數擴展。
流順序內存分配器支持
流排序內存分配器使應用程序能夠針對 CUDA 流中啟動的其他工作排序內存分配和釋放。這還支持分配重用,這可以顯著提高應用程序性能。有關該特性和功能的更多信息,請參閱 使用新的 NVIDIA CUDA 11 . 2 功能增強內存分配 。
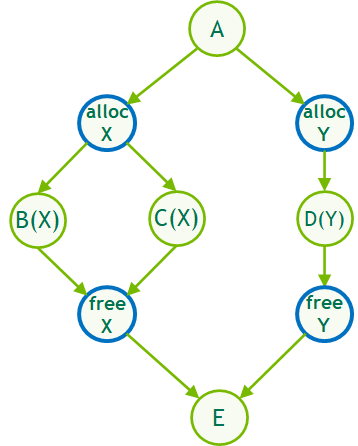
在 CUDA 11 . 4 中, CUDA 圖形現在通過流捕獲或通過新的 allocate 和 free node 類型在本機圖形構造中支持流順序內存分配,從而在圖形中實現相同的高效、延遲內存重用邏輯。
這些節點類型統稱為內存節點。它們可以通過多種方式創建:
- 使用顯式 API
- 分別使用
cudaGraphAddMemAllocNode和cudaGraphAddMemFreeNode
- 分別使用
- 使用流捕獲
- 分別使用
cudaMallocAsync/cudaMallocFromPoolAsync和cudaFreeAsync
- 分別使用
與流順序分配使用隱式流順序和事件依賴來重用內存的方式相同,圖順序分配使用由圖的邊定義的依賴信息來執行相同的操作。
有關更多信息,請參閱 流順序內存分配器 。
增強 MPS
多進程服務( MPS )是 CUDA API 的二進制兼容客戶機 – 服務器運行時實現,旨在透明地支持協作多進程 CUDA 應用程序。
它由一個控制守護進程、客戶端運行時和服務器進程組成。在單個進程不使用所有計算和內存帶寬的情況下, MPS 可以實現更好的 GPU 利用率。 MPS 還減少了 on- GPU 上下文存儲和上下文切換。有關更多信息,請參閱 GPU 管理和部署指南中的 多進程服務 。
在這個版本中,我們做了幾個關鍵的增強,以提高 MPS 的易用性。
SM 分區的編程配置
某些用例具有以下特點:
- 它們由很少或沒有交互的內核組成,從而支持并發執行。
- 這些工作負載所需的 SMs 比率可能會發生變化,并且需要靈活分配正確數量的 SMs 。
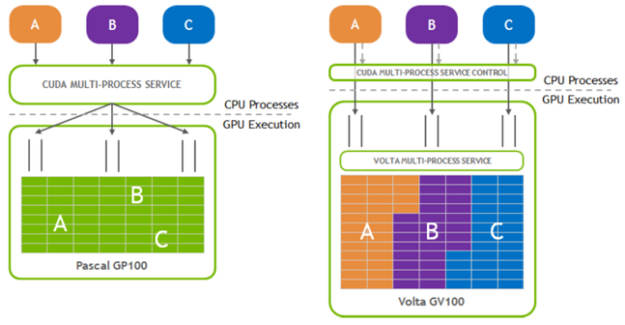
MPS 活動線程百分比 設置允許您將執行限制到 SMs 的一部分。在 CUDA 11 . 4 之前,這是一個固定值,為流程中的所有客戶機平等設置。在 CUDA 11 . 4 中,這已被擴展,以提供一種機制,通過編程接口在每個客戶端級別對 SMs 進行分區。這使您能夠在同一應用程序進程中創建具有不同 SM 分區的上下文。
名為 CU_EXEC_AFFINITY_TYPE_SM_COUNT 的新資源類型使您能夠指定上下文所需的最小數量 N 。系統保證至少分配這么多的 SMs ,但可能會保留更多的 SMs 。 CUDA 11 . 4 還引入了相關的關聯 API cuCtxGetExecAffinity ,該 API 查詢為上下文分配的資源(如 SM 計數)的確切數量。有關更多信息,請參閱 API 文檔中的 cuCtxGetExecAffinity 部分。
錯誤報告
為了改進錯誤報告和易于診斷 MPS 問題的根本原因,我們引入了新的詳細的驅動程序和運行時錯誤代碼。這些錯誤代碼提供了有關錯誤類型的更多具體信息。它們用附加信息補充常見的 MPS 錯誤代碼,以幫助您追蹤故障原因。將應用程序中的這些錯誤代碼與服務器日志中的錯誤消息一起使用,作為根本原因分析的一部分。
新的錯誤代碼:
CUDA_ERROR_MPS_CONNECTION_FAILED CUDA_ERROR_MPS_SERVER_NOT_READY CUDA_ERROR_MPS_RPC_FAILURE CUDA_ERROR_MPS_MAX_CLIENTS_REACHED CUDA_ERROR_MPS_MAX_CONNECTIONS_REACHED
形式化異步數據移動
為了支持 CUDA 11 . 4 中 NVIDIA A100 C ++ 20 障礙 微體系結構啟用的異步內存傳輸操作,我們對 異步 SIMT 編程模型 進行了形式化定義。異步編程模型定義了 GPU 上 C ++ 20 障礙 和 GPU 的行為和 API 。
有關如何使用異步 API 將全局內存中的內存操作與流式多處理器( SMs )中的計算重疊的更多信息,請參閱 異步 SIMT 編程模型 。
其他增強功能
除了前面列出的關鍵功能外, CUDA 11 . 4 中還有一些增強功能,旨在提高多線程提交吞吐量,并將 CUDA 前向兼容性支持擴展到 NVIDIA RTX GPU s 。
多線程提交吞吐量
在 11 . 4 中,我們減少了 CPU 線程之間 CUDA API 的序列化開銷。默認情況下,將啟用這些更改。但是,為了幫助對潛在更改導致的可能問題進行分類,我們提供了一個環境變量 CUDA_REDUCE_API_SERIALIZATION ,以關閉這些更改。這是前面討論的基礎更改之一,有助于 CUDA 圖的性能改進。
CUDA 前向兼容性
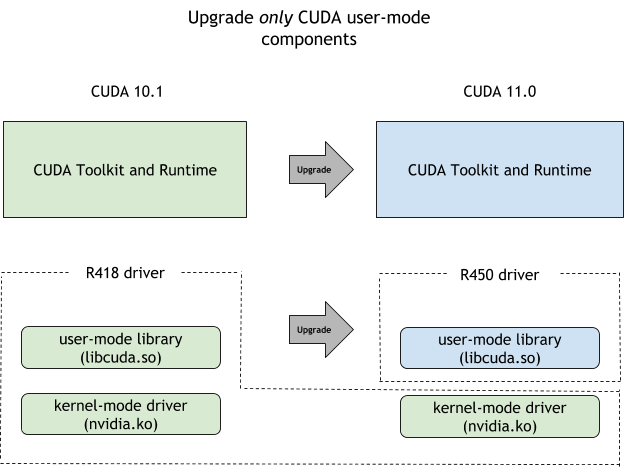
要啟用希望更新 CUDA 工具包但仍保留當前驅動程序版本的用例,例如,為了降低轉移到新驅動程序所需的額外驗證的風險或開銷, CUDA 提供了 CUDA 前向兼容路徑 。這是在 CUDA 10 . 0 中引入的,但最初僅限于數據中心 GPU s 。 CUDA 11 . 4 簡化了這些限制,現在您也可以利用 NVIDIA RTX GPU 的前向兼容性路徑。
C ++語言對 CUDA 的支持
以下是一些在 CUDA 11 . 4 中使用 C ++語言支持的關鍵增強。
- 主要版本:
- NVIDIA C ++標準庫( LIbCu +++) 1 . 5 . 0 被 CUDA 11 . 4 發布。
- 推力 1 . 12 . 0 具有新的
thrust::universal_vectorAPI ,使您能夠將 CUDA 統一內存與推力一起使用。
- Bug 修復版本: CUDA 11 . 4 工具包版本包括 CUB 1 . 12 . 0 。
- 添加了新的異步
thrust::async:exclusive_scan和inclusive_scan算法,這些算法的同步版本已更新為直接使用cub::DeviceScan。
CUDA 編譯器增強功能
CUDA 11 . 4 NVCC C ++編譯器在預覽中有 JIT LTO 支持,提供更多的 L1 和 L2 緩存控制,并公開了一個 C ++符號分散靜態庫以及 NVIDIA nVIEW 調試器支持 alloca 。
JIT 鏈路時間優化
JIT 鏈接時間優化( LTO )是一項預覽功能,僅在 CUDA Toolkit 11 . 4 上可用,在嵌入式平臺上不可用。此功能允許在運行時執行 LTO 。使用 NVRTC 生成 NVVM IR ,然后使用 cuLink 驅動程序 API 鏈接 NVVM IR 并執行 LTO 。
下面的代碼示例顯示如何在程序中使用運行時 JIT LTO 。
使用帶有 -dlto 選項的 nvrtcCompileProgram 生成 NVVM IR ,并使用新引入的 nvrtcGetNVVM 檢索生成的 NVVM IR 。現有的 cuLink API 被擴充,以采用新引入的 JIT LTO 選項,以接受 NVVM IR 作為輸入并執行 JIT LTO 。將 CU_JIT_LTO 選項傳遞給 cuLinkCreate API 以實例化鏈接器,然后將 CU_JIT_INPUT_NVVM 用作 cuLinkAddFile 或 cuLinkAddData API 的選項以進一步鏈接 NVVM IR 。
nvrtcProgram prog1, prog2;
CUlinkState linkState;
int err;
void* cubin;
size_t cubinSize;
char *nvvmIR1, *nvvmIR2;
NVRTC_SAFE_CALL(
nvrtcCompileProgram(&prog1, ...);
NVRTC_SAFE_CALL(
nvrtcCompileProgram(&prog2, ...);
const char* opts = (“--gpu-architecture=compute_80”, “--dlto”);
nvrtcGetNVVM(prog1, &nvvmIR1);
nvrtcGetNVVM(prog1, &nvvmIR2);
options[0] = CU_JIT_LTO;
values[0] = (void*)&walltime;
...
cuLinkCreate(..., options, values, &linkState);
err = cuLinkAddData(linkState, CU_JIT_INPUT_NVVM,
(void*)nvvmIR1, strlen(nvvmIR1) + 1, ...);
...
err = cuLinkAddData(linkState, CU_JIT_INPUT_NVVM,
(void*)nvvmIR2, strlen(nvvmIR2) + 1, ...);
...
cuLinkComplete(linkState, &cubin, &cubinSize);
...
Libcu ++ flt 庫支持
CUDA SDK 現在使用 LIbCu +++ FILT 來傳輸,這是一個靜態的庫,它將編譯器損壞的 C ++符號轉換成用戶可讀的名稱。 nv_decode.h 頭文件中的以下 API 是該庫的入口點:
char* __cu_demangle(const char* id, char *output_buffer, size_t *length, int *status)
下面的 C ++示例代碼顯示用法:
#include <iostream>
#include "/usr/local/cuda-14.0/bin/nv_decode.h"
using namespace std;
int main(int argc, char **argv)
{
const char* mangled_name = "_ZN6Scope15Func1Enez";
int status = 1;
char* w = __cu_demangle(mangled_name,0,0,&status);
if(status != 0)
cout<<"Demangling failed for: "<<mangled_name<<endl<<"Status: "<<status<<endl;
else
cout<<"Demangling Succeeded: "<<w<<endl;
}
此代碼示例輸出如下:
Demangling Succeeded: Scope1::Func1(__int128, long double, ...) Demangling Succeeded: Scope1::Func1(__int128, long double, ...)
有關更多信息,請參閱 CUDA 二進制實用程序文檔中的 Library 可用性 。
在 PTX 中配置緩存行為
PTX ISA 7 . 4 使您能夠更好地控制一級緩存和二級緩存的緩存行為。本 PTX ISA 版本中引入了以下功能:
- 增強的數據預取: 新的
.level::prefetch_size限定符可用于預取附加數據以及內存加載或存儲操作。這使得能夠利用數據的空間局部性。 - 驅逐優先權控制: PTX ISA 7 . 4 引入了四種緩存逐出優先級。可以在內存加載或存儲操作(適用于一級緩存)和
prefetch指令(適用于二級緩存)上使用.level::eviction_priority限定符指定這些逐出優先級。evict_normal(默認值)evict_last(數據應在緩存中保留更長時間時有用)evict_first(用于流式傳輸數據)no_allocate(完全避免緩存數據)
- 增強的二級緩存控制: 這有兩種口味:
- 特定地址上的緩存控制: 新的 discard 指令允許從緩存中丟棄數據,而無需將其寫回內存。僅當不再需要數據時才應使用。新的
applypriority指令將特定數據的逐出優先級設置為evict_normal。當數據不再需要在緩存中持久化時,這對于從[articularly useful in downgrading the eviction priority fromevict_last降級逐出優先級非常有用。 - 內存操作的緩存提示: 新的
createpolicy指令允許創建緩存策略描述符,該描述符為不同的數據區域編碼一個或多個緩存收回優先級。使用.level::cache_hint限定符時,一些內存操作(包括加載、存儲、異步復制、 atom 、 red 等)可以接受緩存策略描述符作為操作數。
- 特定地址上的緩存控制: 新的 discard 指令允許從緩存中丟棄數據,而無需將其寫回內存。僅當不再需要數據時才應使用。新的
這些擴展僅被視為性能提示。緩存系統不保證使用這些擴展指定的緩存行為。有關用法的更多信息,請參閱 PTX ISA 規范 。
調用堆棧 11 . 4 中的其他編譯器增強功能包括支持新的主機編譯器: ICC 2021 。 CUDA 前端編譯器發出的診斷現在是 ANSI 顏色的, Nsight debugger 現在可以在 CUDA 視圖中通過 alloca 調用正確展開 CUDA 應用程序。
Nsight 開發工具
NVIDIA Nsight Visual Studio 代碼版( VSCE )和 Nsight Compute 2021 . 2 現在提供了新版本,為 CUDA 編程的開發人員體驗增加了增強功能。
NVIDIA Nsight VSCE 是一種針對異構平臺的應用程序開發環境,將 CUDA 對 GPU 的開發納入 Microsoft Visual Studio 代碼中。 NVIDIA Nsight VSCE 使您能夠在同一會話中構建和調試 GPU 內核和本機 CPU 代碼,并檢查 GPU 和內存的狀態。
它包括 CUDA 應用程序的 IntelliSense 代碼突出顯示和 IDE 的集成 GPU 調試體驗,支持單步執行代碼、設置斷點以及檢查 CUDA 內核中的內存狀態和系統信息。現在,直接從 VisualStudio 代碼開發和調試 CUDA 應用程序很容易。
Nsight Compute 2021 . 2 添加了新功能,有助于檢測更多性能問題,并使其更易于理解和修復。新的寄存器依賴關系可視化(圖 6 )有助于識別可能限制性能的長依賴鏈和低效的寄存器使用。此版本還添加了一個經常請求的功能,使您能夠在源代碼視圖中查看 CUDA 內核的并行程序集和相關源代碼,而無需收集概要文件。此獨立源代碼查看器功能允許您直接從 GUI 中的磁盤打開. cubin 文件,以查看代碼相關性。
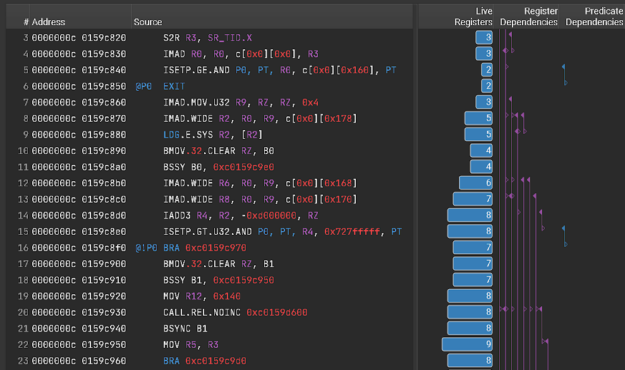
一些功能,包括突出顯示的焦點指標、報告交叉鏈接、增強的規則可見性和文檔參考,都添加到了 Nsight Compute 提供的內置概要文件和優化指導分析中,以幫助您了解和修復性能瓶頸。
此版本還包括對 OptiX 7 資源跟蹤的支持,用于讀取報告數據的新 Python 接口,以及對基線報告、字體設置和 CLI 過濾器的管理的改進。
有關整體更新,請參閱 NVIDIA 開發人員工具概述 。 下載工具 以了解您的代碼。
有關 CUDA 11 代工具包功能和介紹的更多信息,請參閱 CUDA 11 項特色展示 并遵循 所有 CUDA 崗位 。
致謝
感謝以下主要貢獻者:斯蒂芬·瓊斯、阿瑟·桑德拉姆、弗雷德·吳和薩利·史蒂文森。
?