聯邦學習 (Federated Learning, FL) 已成為一種在分布式數據源中訓練機器學習模型的有前景的方法,同時還能保護數據隱私。但是,在平衡模型要求和通信能力時,FL 面臨著與通信開銷和本地資源限制相關的重大挑戰。
特別是在當前的大語言模型 (LLMs) 時代,FL 在部署具有數十億參數的 LLMs 時面臨著計算挑戰。這些模型的龐大規模加劇了通信和內存限制。由于帶寬限制,一次性傳輸完整的模型更新可能不可行,并且本地內存限制可能會使處理大型模型進行通信具有挑戰性。解決這些問題需要創新策略。
NVIDIA FLARE 是一款與領域無關、開源且可擴展的聯邦學習 SDK,通過引入可靠的通信功能、對多個并發訓練作業的支持以及針對可能因網絡條件而中斷的作業的魯棒性,增強了現實世界的聯邦學習體驗。
NVFlare 2.4.0 版本引入了流式傳輸 API,有助于傳輸超過 gRPC 規定的 2GB 大小限制的對象。它添加了一個新的流層,旨在可靠地處理大數據消息的傳輸。
借助流式傳輸 API,您將不再受到 gRPC 2-GB 大小限制的限制。然而,隨著先進模型的日益壯大,兩個挑戰正在成為使用 LLM 的 FL 工作流的瓶頸:
- 默認 fp32 精度下的傳輸消息大小
- 分配本地內存,用于在傳輸過程中固定 object
為了實現更高效、更可靠的聯邦管道,我們在 NVFlare 2.6.0 中引入了兩項關鍵技術,以促進消息大小縮減和內存高效傳輸:
- 消息量化: 使用 NVFlare 過濾器 實現量化和去量化,并將其添加到聯合方案中,從而減少傳輸過程中的消息大小。
- 容器和文件串流: 串流功能基于 ObjectStreamer 實現。我們支持兩種對象類型 (容器和文件) ,并開發了 ObjectRetriever 類,以便更輕松地與現有代碼集成。
流式傳輸功能:減少本地內存占用
FL 的主要瓶頸之一是遠程參與者和服務器之間的模型更新交換。這些消息的大小可能非常大,令人望而卻步,導致延遲和帶寬消耗增加。鑒于最近的 LLMs 訓練精度降低,NumPy 格式下的默認 fp32 消息精度甚至可能會人為地增大消息大小。
在本例中,我們實現了兩項功能:native tensor transfer 和消息量化,通過實現原生訓練精度,以及降低傳輸更新的精度和壓縮消息大小,提供高效的消息傳遞解決方案。
圖 1 展示了使用此 過濾器機制 實現量化和去量化的情況。在傳輸前對輸出模型權重執行量化,而去量化在另一端接收消息時恢復原始精度。
這種實施有兩個好處:
- 用戶無需更改代碼。相同的訓練腳本可通過簡單的配置設置用于和不用于消息量化
- 訓練和聚合均以原始精度(而非量化數據)執行,從而最大限度地減少消息量化對訓練過程的潛在影響。
我們使用直接裁剪和投射將 fp32 轉換為 fp16,并利用 bitsandbytes 執行 8– 和 4-bit 量化。借助這些新功能,我們既支持 NumPy 數組 (之前的默認值) ,也支持直接用于訓練 LLM 的 PyTorch Tensors。
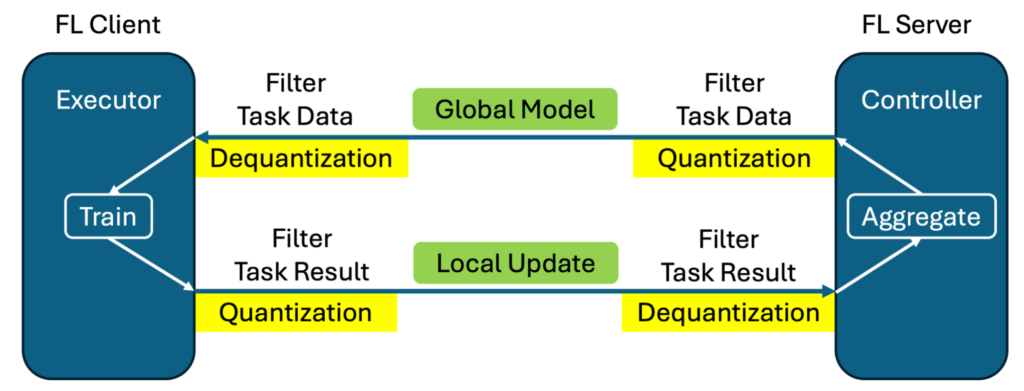
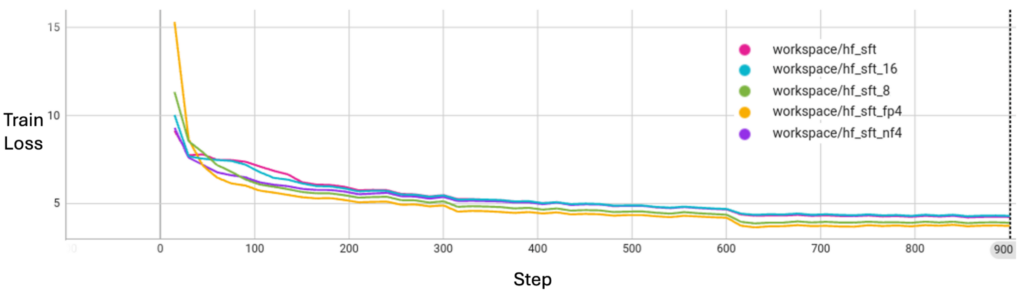
表 1 顯示了不同精度下 1B 參數 LLM 的消息大小 (以 MB 為單位) 。有關訓練損失曲線對齊的更多信息,請參閱通過 Hugging Face SFT/PEFT API 進行 LLM 調整的示例。
| 精度 | 模型 大小 (MB) | 量化 元大小 (MB) | fp32 大小 百分比 |
| 32 位 (fp32) | 5716.26 | 0.00 | 100.00% |
| 16 位 ( fp16、bf16) | 2858.13 | 0.00 | 50.00% |
| 8 位 | 1429.06 | 1.54 | 25.03% |
| 4 位 ( fp4、nf4) | 714.53 | 89.33 | 14.06% |
通過應用消息量化技術,FL 可以顯著節省帶寬,并在我們的實驗中使用 Supervised Fine-Tuning (SFT) 訓練 LLM。
如圖 2 所示,message quantization 不會在訓練損失方面犧牲模型收斂質量。
流式傳輸功能:減少本地內存占用
FL 的另一個關鍵挑戰是用于發送和接收消息的內存開銷。
在默認設置下,要發送模型,您需要額外的內存來準備和接收模型塊,這需要加倍本地內存使用量。必須分配額外的內存來保存整個消息以重新組合對象,盡管傳輸本身是通過 1M 流式傳輸塊完成的。
如果系統性能出色且模型大小適中,這種內存開銷是可以承受的,但如果考慮使用 70B 或更大的參數模型,則可能會迅速耗盡可用的系統內存。 70B 模型 的大小可以為 140 GB。要加載并發送它,您需要 140 + 140 = 280 GB 的內存。
盡管整個 LLM 參數字典可能非常龐大,但在分解為單個層和項目時,每層的最大大小要小得多,通常在 1 GB 左右。升級的流式傳輸功能通過兩項新功能解決了內存使用方面的挑戰:
- 對象容器流: 以增量方式處理和傳輸模型,而無需一次性將整個對象存儲在內存中。容器流式傳輸一次對一個對象的一個項目 (例如包含模型權重的字典) 進行序列化。在之前的示例中,如果 ContainerStreamer 整體發送最大容量為 1 GB 的 140 GB 模型,則為 280 GB,而加載和發送 ContainerStreamer 只需要 140 + 1 = 141 GB 的內存。
- 文件流:流式傳輸文件而非結構化對象容器。文件流式傳輸逐塊讀取文件,并且僅消耗容納一個數據塊所需的內存。FileStreamer 所需的額外內存與模型大小或最大項目大小無關,并且僅依賴于文件 I/O 設置,這可以將傳輸內存占用率降至最低并實現無限流式傳輸。在這種情況下,無需加載模型,因此您可以根據需要選擇進一步節省內存使用量。
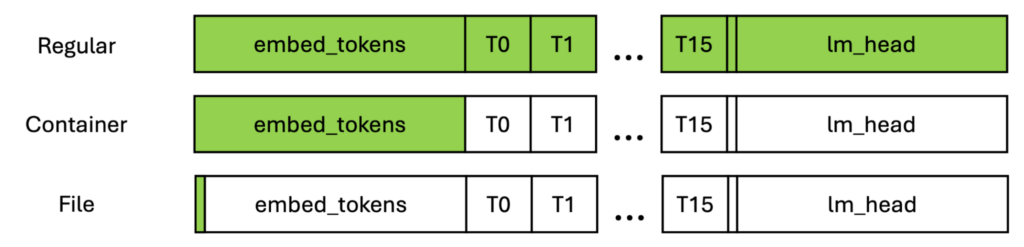
在圖 3 中,綠色框顯示了必須為消息傳輸分配的最大本地內存。如圖所示,常規傳輸必須為整個模型分配內存,因此隨著模型的擴大,它可以是無限的。
對于對象容器,內存的大小與最大層相同,而最大層通常以第一層和最后一層為界。對于文件,內存需求獨立于模型結構,并且可針對任何文件進行配置。
通過在 FL 中調整流式傳輸,您可以將更新分解為更小的塊并按順序進行處理,從而提高內存效率。流式傳輸可減少峰值內存占用,在優化計算資源的同時實現 FL。
借助此解決方案,您甚至可以實現實時處理,使設備能夠在繼續計算的同時傳輸部分更新,從而提高響應速度并減少空閑時間。在接收端,更新策略還可以從自適應傳輸中受益,其中可以根據網絡條件和客戶端可用性以不同粒度發送更新。
表 2 顯示了一次性發送 1B 模型與本地模擬的內存比較。我們記錄了系統內存占用情況,并比較了三種設置(regular、container streaming 和 file streaming)的峰值內存使用情況。
您可以看到,通過使用 streaming,memory usage 顯著減少,尤其是 file streaming。但是,由于 file I/O 效率問題,file streaming 可能需要較長時間才能完成工作。
| 設置 | 顯存占用峰值 (MB) | 作業完成時間 (秒) |
| 定期傳輸 | 42427 | 47 |
| 容器流 | 23265 | 50 |
| 文件流 | 小行星 19176 | 170 |
流增強功能尚未集成到高級 API 或現有的 FL 算法控制器和執行程序中。但是,您可以按照此 Streaming 示例構建自定義控制器或執行程序,以利用此功能。
總結
在本文中,我們展示了如何通過將消息量化和流式傳輸功能集成到 FL 框架來緩解通信瓶頸和內存限制。通過升級功能,我們提高了 Federated Learning 的效率和可擴展性。隨著這些技術的不斷發展,它們將在支持在不同環境中實際部署 FL 方面發揮至關重要的作用。
有關更多信息,請參閱以下資源:
- 在 GitHub 上的 / NVFlare 教程
- GitHub 上的/NVIDIA/NVFlare 量化示例
- GitHub 上的 /NVIDIA/NVFlare 流式傳輸示例
- NVIDIA FLARE 開發者門戶
- 醫學影像領域的 Federated Learning:增強數據隱私并推進醫療健康 GTC 2025 會議
要聯系 NVIDIA FLARE 團隊,請聯系 federatedlearning@nvidia.com 。
?