如何搭建一個高效的推薦系統?
簡單來說,現代推薦系統由訓練/推理流水線(pipeline)組成,涉及數據獲取、數據預處理、模型訓練和調整檢索、過濾、排名和評分相關的超參數等多個階段。走遍這些流程之后,推薦系統能夠給出高度個性化的推薦結果,從而提升產品的用戶體驗。
為了方便大家對此進行深入了解,我們邀請到 NVIDIA Merlin 團隊,他們將詳細介紹推薦系統的上述多個階段的工作流程,以及推薦系統在電商、流媒體、社交媒體等多個行業領域的實踐和用例。
NVIDIA Merlin & Milvus
推薦系統 pipeline 中至關重要的一環便是為用戶檢索并找到最相關的商品。為了實現這一目標,通常會使用低維向量(embedding)表示商品,使用數據庫存儲及索引數據,最終對數據庫中數據進行近似最近鄰(ANN)搜索。這些向量表示是通過深度學習模型獲取的,而這些深度學習模型基于用戶和產品或服務之間的交互進行訓練。使用計算機視覺算法或語言模型,還可以從各種數據模態(例如圖像、視頻或產品與用戶的文本描述)中生成向量表示。獲取向量表示后便迎來關鍵步驟——對數十萬甚至數百萬/數十億的向量嵌入數據集(例如電商庫存產品 embedding)進行高效的 top-k(即 k 個最相似)搜索。
NVIDIA Merlin 是一個開源框架,用于訓練端到端模型,從而為各類規模的數據生成推薦,輕松集成高效的向量數據庫索引和搜索框架。而 Milvus 作為大模型時代備受關注的向量數據庫可以提供高效索引和查詢功能。
最近,Milvus 新增支持 NVIDIA GPU加速,可提升查尋的并發和速度,這對于現代推薦系統十分有用。截至 2023 年 10月,Milvus 獲得了 689 萬次 docker pull 及 2.3 萬顆 GitHub Star,被業界廣泛應用 https://zilliz.com.cn/blog?tag=4。
接下來,我們將演示 Milvus 如何與 Merlin RecSys 框架集成、Milvus 如何在項目檢索階段與高效的 top-k 向量搜索技術相結合以及如何在推斷時使用 NVIDIA Triton Inference Server (TIS)。根據 NVIDIA 性能測試結果顯示:使用 Merlin 模型生成向量并使用 GPU 加速版的 Milvus 可以將搜索速度提升 37 至 91 倍。我們使用的 Merlin-Milvus 集成代碼和詳細性能測試結果均可在 https://github.com/bbozkaya/merlin-milvus/tree/main 處獲取。
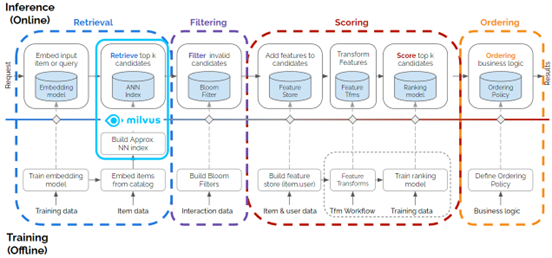
圖1. Milvus 框架為多階段推薦系統的檢索階段做出貢獻。(原始多階段圖的來源:https://medium.com/nvidia-merlin/recommender-systems-not-just-recommender-models-485c161c755e)
挑戰
由于推薦系統具備的多階段的性質以及各種組件和庫的可用性問題,其主要挑戰就是在端到端流程中無縫集成所有組件,因此我們的目標是在示例 notebook 中盡可能簡化集成工作。
另一個挑戰是加速整個推薦流程。雖然加速在訓練大型神經網絡中扮演著重要的角色,但 GPU 是在近期才被添加到向量數據庫和 ANN 搜索領域中的。隨著電商庫存產品、流媒體等數據規模爆炸式增長和用戶數量的井噴,CPU 從性能上而言已經無法滿足服務數百萬用戶的推薦系統的需求。為了解決這個挑戰,需要在流程的其他部分進行 GPU 加速。本文提出的解決方案展示了 ANN 搜索時使用 GPU 加速可以有效解決這一問題。
技術棧
現在,先介紹一下即將用到的技術棧。
首先需要一個推薦系統框架作為基礎,本例中我們使用 NVIDIA Merlin,因為這個開源庫提供在 NVIDIA GPU 上加速推薦系統的高級 API (high-level API)。Merlin 可以助力數據科學家、機器學習工程師和研究人員構建高性能推薦系統。除了 Merlin 以外,本例中還使用了以下開源工具/庫:
- NVTabular:用于預處理輸入表格數據和特征工程。
- Merlin Models:用于訓練深度學習模型,從用戶交互數據中學習獲取用戶和商品向量。
- Merlin Systems:用于集成基于 TensorFlow 的推薦模型與其他組件(例如特征存儲、Milvus 的 ANN 搜索功能),以便在 TIS 中提供服務。
- Triton Inference Server:用于在推斷階段傳遞用戶特征向量并生成產品推薦。
- 容器化:上述所有內容都可以在 NVIDIA 提供的 NGC 目錄中獲取。本例使用 Merlin TensorFlow 23.06 容器。
- Milvus 2.3:用于啟用 GPU 加速的向量索引和查詢。
- Milvus 2.2.11:與上述相同,但在 CPU 上執行向量索引和查詢。
- pymilvus SDK:用于連接 Milvus 服務器、創建向量數據庫索引并通過 Python 接口運行查詢命令。
- Feast:用作端到端 RecSys 流程中保存和檢索用戶、商品向量的(開源)特征存儲。
此外,我們還用到了許多底層庫和框架。例如,Merlin 依賴于 cuDF 和 Dask 等其他 NVIDIA 庫,這兩個庫均可在 RAPIDS cuDF 中獲取。同樣,Milvus 依賴于 NVIDIA RAFT 實現 GPU 加速,HNSW 和 FAISS 等進行搜索。
了解向量數據庫
ANN 搜索是關系型數據庫無法提供的功能。關系型數據庫只能用于處理具有預定義結構、可直接比較值的表格型數據。因此,關系數據庫索引也是基于這一點來比較數據。但是 Embedding 向量無法通過這種方式直接相互比較。因為我們不知道向量中的每個值代表什么意思,無法使用關系型數據庫來確定一個向量是否一定小于另一個向量,唯一能做的就是計算兩個向量之間的距離。
如果兩個向量之間的距離很小,可以假設它們所代表的特征相似;如果距離很大,可以假設它們代表的數據十分不同。對我們而言,向量距離及其含義是有用的。我們可以創建索引結構,高效搜索這些數據。但是為向量數據構建索引也有不小挑戰:計算兩個向量間距離成本高昂,而且向量索引一旦構建完成后,不易于修改。因此,我們無法直接使用傳統的關系型數據庫來處理向量數據,需要使用專為向量數據而打造的向量數據庫。
Milvus 是一款專為向量數據處理而設計的向量數據庫,可以解決傳統關系型數據庫無法處理向量的問題,為海量向量數據高效構建索引。為了滿足云原生的要求,Milvus 將計算和存儲以及不同的計算任務(查詢、數據處理和索引)分離開來。用戶可以根據不同的應用靈活擴展每個組件。無論是數據插入密集型應用還是搜索密集型應用, Milvus 都能夠輕松應對。如果有大量插入請求涌入,用戶可以臨時水平和垂直擴展索引節點以處理數據。同樣,如果沒有大量插入數據,但有大量搜索操作,用戶可以減少索引節點的數量,并提高查詢節點的吞吐量。Milvus 的系統架構設計(見圖2)采用并行計算的思維方式,助力我們進一步優化本例中的推薦系統應用。
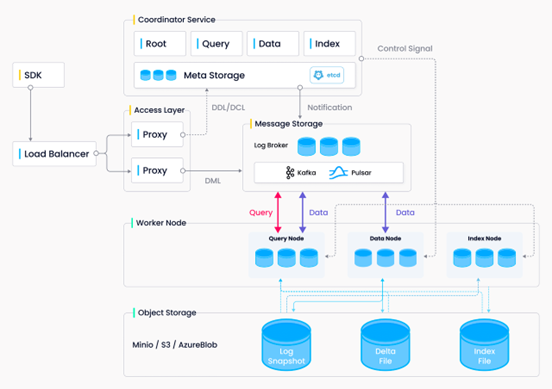
圖2. Milvus 架構設計
此外,Milvus 還整合了許多最先進的索引庫,以便為用戶提供盡可能多的系統自定義功能。稍后,我們將討論這些索引的區別以及各自的優缺點。
向量數據索引
大多數向量索引可以分成兩種類型——聚類和圖。IVF 是聚類類別中的一種算法,它使用 k-means 來計算最近鄰的聚類。然后,將查詢向量與最近的質心聚類進行比較,并在搜索時進行搜索。HNSW、DiskANN 和圖類別中的其他基于圖的算法主要圍繞著導航擴展圖進行搜索,這些圖在 ANN 搜索時效率更高。但是圖算法往往也更加復雜。如果大家對此感興趣,可以閱讀這篇文章 https://zilliz.com/learn/hierarchical-navigable-small-worlds-HNSW。
除了上述這些算法,還有一類叫做乘積量化 (PQ) 的算法。PQ 是一種將向量數據壓縮以減少資源使用并提高性能的方法,但其代價是降低召回率/準確性。該領域中的大多數算法都是量化的變體,以允許降低內存使用或提高其方法的性能。
所有這些算法和組合之間的區別是什么?為什么有這么多算法呢?它們之間的區別在于性能、召回率和內存使用之間的權衡。例如,IVF_FLAT 索引是一個平衡了上述 3 個方面的索引,可以在不過多增加內存開銷的情況下以較快的速度獲得良好的結果。基于壓縮的索引,如 IVF_SQ8 和 IVF_PQ,在速度和減少內存使用方面更強大,但根據所使用的壓縮級別,會降低召回率。HNSW 則以性能和召回率為目標,但代價是內存消耗。與其他索引相比,DiskANN 是最獨特的,因為它是一種基于磁盤的索引。前面的索引都完全存儲在內存中,需要大量的 RAM。DiskANN 只在內存中保存少量索引數據,并將大部分數據保存在磁盤存儲器中,這樣可以大大減少內存使用量,同時仍然保持較高的召回率。但是,使用 DiskANN 會降低吞吐性能,并且根據所使用的 SSD 類型,會影響延遲性能。
如今,并非只有大型用戶/公司才能訪問非常大的數據集,小型用戶可能會從其數據中生成數十億個向量,并需要以最經濟的方式進行搜索。相比之下,大型用戶有時雖然只有幾十萬個數據,但每秒需要處理數萬個查詢。為了解決這些問題,索引層面提供很多定制化的參數來支持不同的用例。更多詳情,請訪問 https://milvus.io/docs/index.md 查看。
GPU vs CPU
對于大多數用戶來說,GPU 索引是獲得所需性能的關鍵。GPU 索引提供了許多用例所需的高吞吐量,同時從長期而言可以節省成本。
構建和搜索索引主要依賴向量化計算,可以在 CPU 上完成,但使用 GPU 效率大大提升。Milvus 將搜索計算遷移到 GPU 后,查詢每秒 (QPS) 的性能提高了 37 至 91 倍,性能提升非常顯著。想要獲得如此大的性能提升的唯一其他途徑就是擴展集群規模。但是這種方式開銷較大。通過使用 GPU,用戶可以提升性能的同時簡化集群,減少額外節點和調度開銷。
然而,基于 GPU 的搜索有一個限制,那就是低并發情況。Milvus 對高并發有優化,會嘗試合并查詢并一起做主存和 GPU 內存的搬移,來降低單個查詢需要的搬移次數。在低并發情況下,GPU 的延遲較大,因為 CPU 可以比將數據傳輸到 GPU 再從 GPU 傳回的時間內更快地完成搜索。
示例
我們提供的示例演示了在商品檢索階段如何集成 Milvus 與 Merlin,其中用到了來自 RecSys Challenge 2015 的真實數據集進行訓練。同時,我們也訓練了一個雙塔深度學習模型,用于學習用戶和商品向量。在本章節的最后,我們還會提供一些性能測試相關的信息,包括在性能測試過程中觀察的指標和使用的參數范圍。
數據集
在集成和性能測試時,我們使用了由 YOOCHOOSE GmbH 在 RecSys Challenge 2015 中提供的數據集,可在 Kaggle 上下載。這個數據集中包含了歐洲在線零售商提供的用戶點擊/購買事件,其中包括與點擊/購買相關的會話 ID、時間戳、商品 ID和商品類別等信息。這些內容均可在文件 yoochoose-clicks.dat 中獲取。各個會話都是獨立的,不考慮回購用戶的情況。因此我們將每個會話視為屬于不同用戶的會話。該數據集包含 9,249,729 個會話(用戶)和 52,739 個商品。
工作流程主要包括:a) 數據獲取和預處理。b) 搭建雙塔深度學習模型,訓練數據。c) 在 Milvus 向量數據庫中創建索引。 d) 在 Milvus 向量數據庫中進行向量相似性搜索。接下來,我們會簡要描述每個步驟,如果大家對每個步驟的詳情感興趣,請參考 https://github.com/bbozkaya/merlin-milvus/tree/main/notebooks。
數據獲取和預處理
用 NVTabular 對數據進行預處理。這個工具利用了 Merlin 的 GPU 加速能力,是高度可擴展的特征提取和預處理組件,能夠幫助我們輕松處理 T 字節級別的數據集、搭建訓練基于深度學習的推薦系統。
NVTabular 經過抽象,提供一套簡化的代碼,使用 RAPIDS 的 Dask-cuDF 庫在 GPU 上實現加速計算。用 NVTabular 將數據讀入 GPU 內存,并按需重新排列特征,最終導出為 Parquet 文件。最終得到了 7,305,761 個用戶向量和 49,008 個商品向量以供后續訓練使用。在預處理時,我們還會將每列數據和值進行分類,轉換為整數值。
模型訓練
用雙塔https://github.com/NVIDIA-Merlin/models/blob/main/examples/05-Retrieval-Model.ipynb深度學習模型來生成用戶和商品向量,隨后為這些向量創建索引并查詢向量。我們將用戶屬性(user_id, user_age)和商品屬性(item_id, item_category)輸入到 Two-Tower 模型中。這個過程中,可以選擇是否要包含一個目標列,只包括具有正交互作用的行。模型訓練完成后,提取學習到的用戶和商品嵌入向量。
接下來是兩個可選步驟:
1. 使用 DLRM 模型對檢索到的商品進行排序。
2. 使用特征存儲(在本例中為 Feast)存儲和檢索用戶和商品特征。在本示例中,加入了這兩個步驟從而更為完整地展示推薦系統的多階段工作流程。
最后,將用戶和商品向量導出為 parquet 文件,稍后可以重新加載并為其在 Milvus 中創建向量索引。現在,可以啟動 Milvus 服務器并上傳商品向量、創建向量索引。然后,在推理時使用NVIDIA TIS 和自定義的 Merlin 系統 Operator 對現有用戶和新用戶進行相似性搜索查詢。請參見 notebook 中的第二個示例。
構建和查詢 Milvus 索引
Milvus 通過在推理機上啟動一個服務來實現向量索引和相似度搜索。在 notebook 2 中,我們通過 pip 安裝了 milvus 服務器和 pymilvus,然后使用默認的監聽端口啟動了服務器。接下來,我們將演示如何使用兩個函數 setup_milvus 和 query_milvus 來構建一個簡單的索引 (IVF_FLAT) 并對其進行查詢。
當我們將相同任務作為 TIS 框架中的多階段推理的一部分完成時,事情變得更有趣了。Merlin 提供了一個高級 API,Merlin Systems,允許將推薦系統的不同階段組合成一個單獨的鏈式“集成模型”。因此,上述所有階段都在對 TIS 發送的單個請求中執行。在這里,我們實現了一個自定義的 Merlin Systems 操作符作為集成的一部分,名為 QueryMilvus。
細心的朋友可以已經注意到,pymilvus 庫沒有使用 GPU 加速,而 NVTabular 和 Merlin Models 卻使用了 GPU。這是因為 Milvus 的 GPU 加速版本需要啟動多個容器,而我們使用的 Merlin 容器不支持這樣做。相反,通過 pymilvus,在 notebook 所在的同一個容器中將 Milvus 服務器作為一個進程啟動。要在 GPU 上運行 Milvus,可以參考最新的 Milvus 發版說明 https://github.com/milvus-io/milvus/releases/tag/v2.3.1。下面性能測試是在 GPU 上完成的,使用的是 Milvus 最新版。
基準測試
為了證明使用快速高效的向量索引/搜索庫(如 Milvus)的必要性,我們設計了兩組性能測試。
- 使用 Milvus 構建向量索引,我們生成了兩組向量:1)針對 730 萬個用戶向量,按照 85% 的訓練集(用于索引)和 15% 的測試集(用于查詢)進行劃分;2)針對 4.9 萬個商品向量,按照 照 50% 的訓練集(用于索引)和 50% 的測試集(用于查詢)進行劃分。性能測試針對每個向量數據集獨立進行,生成獨立的結果。
- 使用 Milvus 構建一個針對 4.9 萬個商品向量數據集的索引,并基于該索引使用 730 萬個用戶向量進行相似性搜索。
在性能測試中,我們使用了 Milvus 的 HNSW(僅 CPU)和IVF_PQ(CPU 和 GPU),并嘗試了各種參數組合。詳細信息請參見 https://github.com/bbozkaya/merlin-milvus/tree/main/results。
在生產環境中,一個重要的性能考量指標是搜索質量和吞吐量之間的平衡(tradeoff)。Milvus 允許完全控制索引參數,以探索這個 tradeoff,以達到與基準結果相關的更好搜索結果。這可能意味著減少吞吐量或每秒查詢數(QPS),增加計算成本。我們使用召回率指標來衡量 ANN 搜索的質量,并提供了 QPS-召回率 曲線來展示 tradeoff。然后,您可以根據計算資源、延遲/吞吐量需求來決定可接受的搜索質量水平。
還請注意我們基準測試中使用的查詢批處理大小(nq)。這在工作流中非常有用,其中會同時向推理發送多個請求(例如,將離線推薦請求發送給一系列電子郵件收件人,或者通過匯集并同時處理到達的并發請求生成在線推薦)。根據具體情況,TIS 還可以幫助以批處理方式處理這些請求。
結果
以下展示基于 CPU 和 GPU 的 3 組性能測試結果。該測試使用了 Milvus 的 HNSW(僅 CPU)和IVF_PQ(CPU 和 GPU)索引類型。
商品向量間相似度搜索
對于給定的參數組合,將 50% 的商品向量作為查詢向量,并從剩余的向量中查詢出 top-100 個相似向量。我們發現,在測試的參數設置范圍內,HNSW 和 IVF_PQ 的召回率很高,分別在 0.958-1.0 和 0.665-0.997 之間。這表明 HNSW 在召回率方面表現更好,但是 IVF_PQ 在 nlist 較小的情況下也能得到非常高的召回率。此外,召回率的值隨著索引和查詢參數的變化也會發生很大的變化。報告結果在對一般參數范圍進行初步實驗并進一步深入選擇子集之后獲得的。
在給定參數組合下,使用 HNSW 在 CPU 上執行所有查詢的總時間范圍在 5.22 到 5.33 秒之間(在 ef不變的情況下,隨著 m 的增大而更快),而使用 IVF_PQ 在 13.67 到 14.67 秒之間(隨著 nlist 和 nprobe 的增大而變慢)。如圖 3 所示,GPU 加速確實效果更明顯。
圖 3 顯示了在 CPU 和 GPU 上,使用 IVF_PQ 和這個小數據集時召回率和吞吐量之間的 tradeoff。我們發現,GPU 在所有測試的參數組合下都實現了 4 到 15 倍的加速(隨著 nprobe 的增大而加速更明顯)。這個結果是比較每個參數組合下 GPU 的每秒查詢數與 CPU 的每秒查詢數得出的。總體而言,這個小數據集對于 CPU 或 GPU 來說都很容易處理,而且不難看出,還有進一步加速空間。
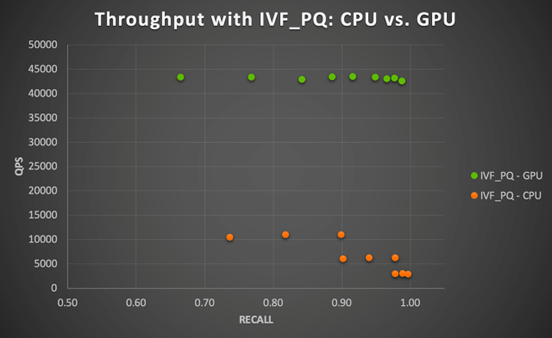
圖3. 在 NVIDIA A100 GPU 上運行 Milvus IVF_PQ 算法的 GPU 加速(商品與商品相似性搜索)
用戶向量間相似性搜索
對于更大的第二個數據集(730 萬個用戶),我們將 85%(約 620萬個)的向量用于“訓練”(要建立索引的向量集),剩下的 15%(約 110 萬個)作為“測試”或查詢向量集。在這種情況下,HNSW 和 IVF_PQ 表現非常出色,召回率分別為 0.884-1.0 和 0.922-0.999。然而,它們在計算上要求更高,尤其是在 CPU 上使用 IVF_PQ 的情況。使用 HNSW 在 CPU 上執行所有查詢的總時間范圍為 279.89 至 295.56 秒,而使用 IVF_PQ 的總時間范圍為 3082.67 至 10932.33 秒。注意,這些查詢時間是對 110 萬個向量進行查詢的累積時間,因此可以說針對索引的單個查詢仍然非常快。然而,如果推理服務器要對數百萬個商品并發請求運行查詢,不推薦使用 CPU 查詢。
使用 IVF_PQ 和 A100 GPU 時,吞吐量(QPS)提升 37 至 91倍 (平均為 76.1 倍)。這與我們在小數據集中觀察到的結果一致,這表明處理數百萬向量數據時,Milvus 結合 GPU 加速可以大幅提升性能。
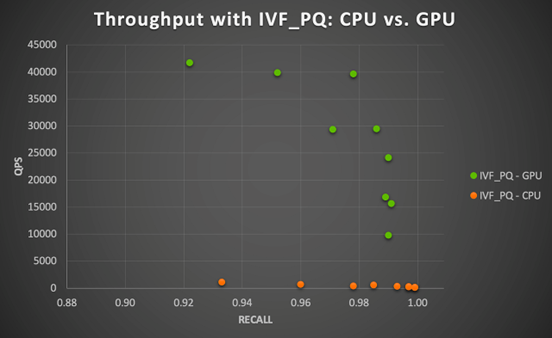
圖4. 在 NVIDIA A100 GPU 上運行 Milvus IVF_PQ 算法的 GPU 加速比(用戶-用戶相似性搜索)
此外,圖 5 顯示了在 CPU 和 GPU 上使用 IVF_PQ 測試的所有參數組合的召回率-QPS tradeoff。該圖中每個點(上為GPU,下為 CPU)展示了在改變向量索引/查詢參數時召回率和吞吐量的 tradeoff:更高召回率的代價是較低吞吐量。注意,在使用 GPU 的情況下,提高召回率時,QPS 會大幅降低。
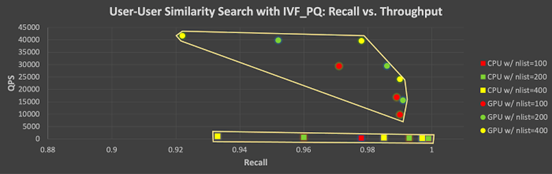
圖 5. 在 CPU和 GPU 上使用 IVF_PQ 進行測試的參數組合及其召回率-吞吐量tradeoff(User vs. User)。
用戶與商品向量間相似度搜索
最后,考慮另一個現實場景,即將用戶向量與商品向量進行比較(如上面的 notebook 1 所示)。在這種情況下,我們為 49000 個商品向量創建索引,為每個用戶向量查詢其 top-100 最相似的商品。
在 CPU 上進行向量批量查詢非常耗時,無論是使用 HNSW 還是 IVF_PQ 索引(請參見圖 6)。而 GPU 在這種情況下表現更好。當 nlist = 100 時,IVF_PQ 在 CPU 上平均計算時間約為 86 分鐘。但計算時間隨著 nprobe 值的增加而變化很大(當 nprobe = 5 時為 51 分鐘,而當 nprobe = 20 時為 128 分鐘)。NVIDIA A100 GPU 能夠將性能提升了4 至17倍(當 nprobe 較大時,速度提升更高)。前文也提到,通過其量化技術,IVF_PQ 算法還可以減少內存占用。這樣看來,如果結合 GPU 加速方案,能夠得到一個計算上更可行的 ANN 搜索解決方案。
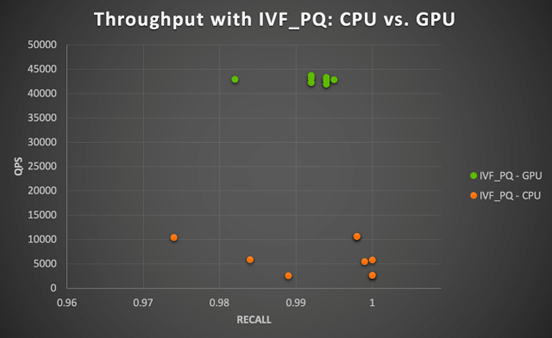
圖6. 在 NVIDIA A100 GPU 上運行 Milvus IVF_PQ 算法的 GPU 加速比(用戶-商品相似性搜索)
與圖 5 類似,圖 7 顯示了使用 IVF_PQ 測試的所有參數組合的召回率-吞吐量間的 tradeoff。我們仍然可以看到在 ANN 搜索中,為了提高吞吐量,可能需要稍微犧牲一些準確性,尤其是在使用 GPU 的情況下。也就是說,我們可以在 GPU 的計算性能上保持相當高的水平,同時實現高召回率。
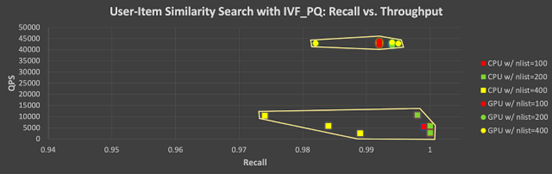
圖7. 使用 IVF_PQ 索引在 CPU 和 GPU 上測試的所有參數組合及其對應召回率-吞吐量 tradeoff(用戶 vs 商品)。
結論
最后,和大家分享一些思考。
現代推薦系統復雜和多階段的特質對每個環節的性能和效率都有很高的要求。因此,大家可以考慮在推薦系統流程中使用以下兩個關鍵功能:
- NVIDIA Merlin 及其 Merlin Systems 庫:您能夠輕松插入高效的 GPU 加速向量搜索引擎 Milvus。
- 使用 GPU 加速計算,用諸如 RAPIDS RAFT 等技術來進行向量數據庫索引和 ANN 搜索。

上述測試結果表明,本文所提出的 Merlin-Milvus 集成方案在訓練和推理方面都非常高效且比其他方案更簡單。而且,這兩個框架都在積極開發中,每個版本都會添加許多新功能,例如,Milvus 新增了基于 GPU 加速的向量數據庫索引。向量相似性搜索是計算機視覺、大語言模型系統、推薦系統等工作流程中的關鍵組成部分,因此十分推薦大家嘗試使用 Milvus 向量數據庫。
最后,要感謝 Zilliz/Milvus 和 Merlin 以及 RAFT 團隊為完成這個項目和這篇博客文章所做出的貢獻。當然,如果大家在自己的推薦系統或其他工作流程中使用了 Merlin 和 Milvus, 也歡迎和我們分享。