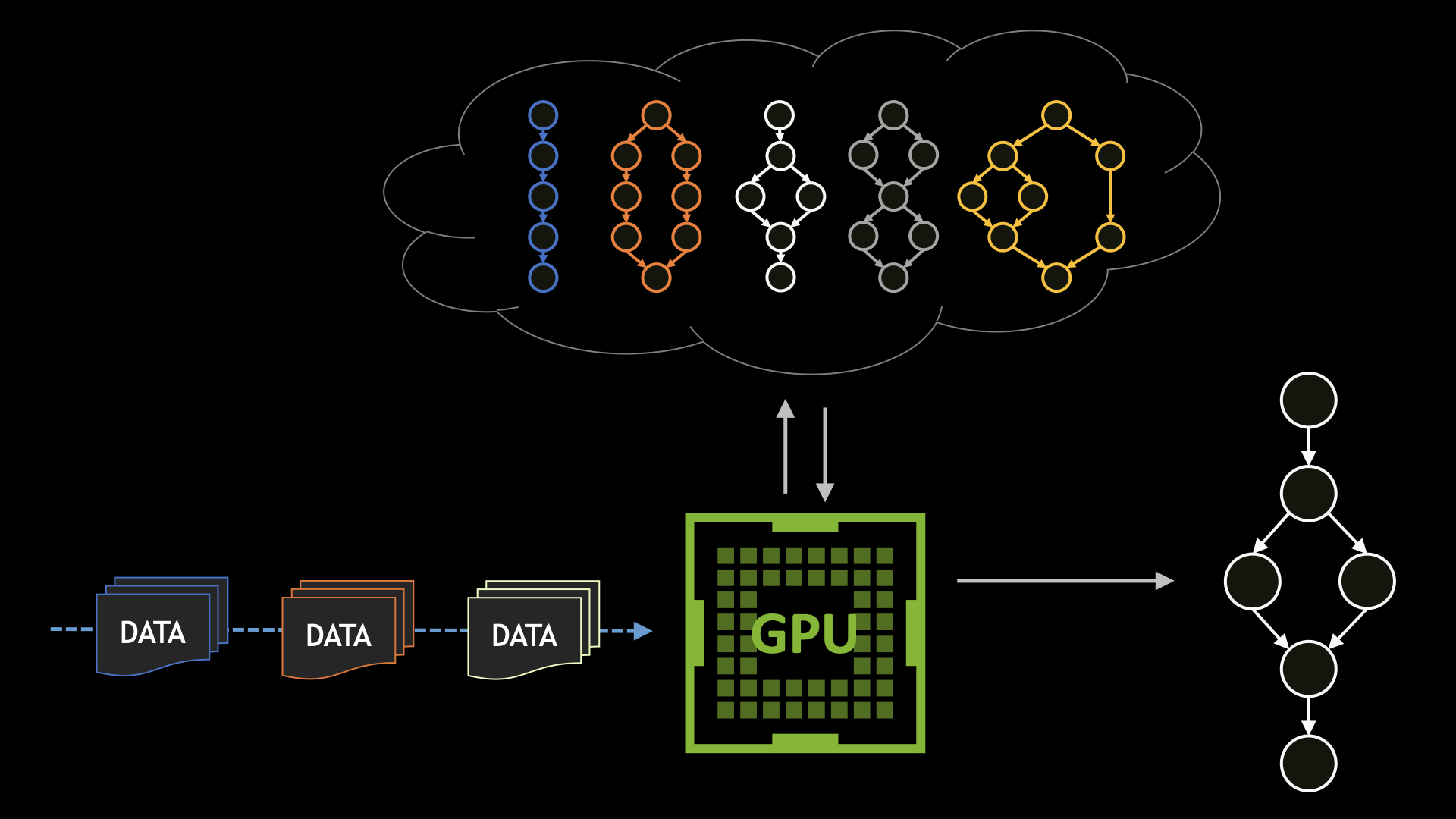
CUDA 圖形通過將用戶操作定義為任務圖(可以在單個操作中啟動),顯著減少了啟動大量用戶操作的開銷。提前了解工作流使 CUDA 驅動程序能夠應用各種優化,這在通過流模型啟動時無法執行。
然而,這種性能是以靈活性為代價的:如果事先不知道整個工作流,則 GPU 執行必須中斷,才能返回 CPU 做出決定。
CUDA 設備圖啟動通過基于在運行時確定的數據使任務圖能夠從正在運行的 GPU 內核高效地啟動來解決這個問題。 CUDA 設備圖形發射提供了兩種不同的發射模式:發射和忘記,以及尾部發射,以實現廣泛的應用和使用。
這篇文章演示了如何使用設備圖形啟動和兩種啟動模式。它以設備端工作調度程序為例,它解壓縮文件以進行數據處理。
設備圖初始化
執行任務圖涉及以下四個步驟:
- 創建圖形
- 將圖形實例化為可執行圖形
- 將可執行圖形的工作描述符上載到 GPU
- 啟動可執行圖形
通過將啟動步驟與其他步驟分離, CUDA 能夠優化工作流,并使圖形啟動盡可能輕。為了方便起見,如果沒有明確調用上傳步驟, CUDA 也將在第一次啟動圖形時將上傳步驟與啟動步驟相結合。
為了從 CUDA 內核啟動圖形,必須首先在實例化步驟中初始化圖形以用于設備啟動。此外,在可以從設備啟動設備之前,設備圖必須已通過手動上傳步驟或通過主機啟動隱式上傳到設備。下面的代碼執行主機端步驟以設置設備調度程序示例,顯示了兩個選項:
// This is the signature of our scheduler kernel
// The internals of this kernel will be outlined later
__global__ void schedulerKernel(
fileData *files,
int numFiles,
int *currentFile,
void **currentFileData,
cudaGraphExec_t zipGraph,
cudaGraphExec_t lzwGraph,
cudaGraphExec_t deflateGraph);
void setupAndLaunchScheduler() {
cudaGraph_t zipGraph, lzwGraph, deflateGraph, schedulerGraph;
cudaGraphExec_t zipExec, lzwExec, deflateExec, schedulerExec;
// Create the source graphs for each possible operation we want to perform
// We pass the currentFileData ptr to this setup, as this ptr is how the scheduler will
// indicate which file to decompress
create_zip_graph(&zipGraph, currentFileData);
create_lzw_graph(&lzwGraph, currentFileData);
create_deflate_graph(&deflateGraph, currentFileData);
// Instantiate the graphs for these operations and explicitly upload
cudaGraphInstantiate(&zipExec, zipGraph, cudaGraphInstantiateFlagDeviceLaunch);
cudaGraphUpload(zipExec, stream);
cudaGraphInstantiate(&lzwExec, lzwGraph, cudaGraphInstantiateFlagDeviceLaunch);
cudaGraphUpload(lzwExec, stream);
cudaGraphInstantiate(&deflateExec, deflateGraph, cudaGraphInstantiateFlagDeviceLaunch);
cudaGraphUpload(deflateExec, stream);
// Create and instantiate the scheduler graph
cudaStreamBeginCapture(stream, cudaStreamCaptureModeGlobal);
schedulerKernel<<<1, 1, 0, stream>>>(files, numFiles, currentFile, currentFileData, zipExec, lzwExec, deflateExec);
cudaStreamEndCapture(stream, &schedulerGraph);
cudaGraphInstantiate(&schedulerExec, schedulerGraph, cudaGraphInstantiateFlagDeviceLaunch);
// Launch the scheduler graph - this will perform an implicit upload
cudaGraphLaunch(schedulerExec, stream);
}
這里需要注意的是,設備圖形可以從主機或設備啟動。因此,可以向調度器傳遞與在主機上啟動相同的cudaGraphExec_t句柄,以便在設備上啟動。
點火忘記發射
調度器內核根據傳入的數據分派工作。對于工作調度,首選的啟動方法是“點火后忘記啟動”。
當使用 fire and forget launch 啟動圖形時,將立即發送該圖形。它獨立于啟動圖和使用 fire and forget 模式啟動的后續圖執行。因為工作會立即執行,所以對于調度程序調度的工作,最好是“啟動即忘”,因為它會盡快開始運行。 CUDA 引入了一個名為 stream 的新設備端,以執行一個圖的點火和忘記啟動。請參見下面的簡單分派器示例。
enum compressionType {
zip = 1,
lzw = 2,
deflate = 3
};
struct fileData {
compressionType comprType;
void *data;
};
__global__ void schedulerKernel(
fileData *files,
int numFiles
int *currentFile,
void **currentFileData,
cudaGraphExec_t zipGraph,
cudaGraphExec_t lzwGraph,
cudaGraphExec_t deflateGraph)
{
// Set the data ptr to the current file so the dispatched graph
// is operating on the correct file data
*currentFileData = files[currentFile].data;
switch (files[currentFile].comprType) {
case zip:
cudaGraphLaunch(zipGraph, cudaStreamGraphFireAndForget);
break;
case lzw:
cudaGraphLaunch(lzwGraph, cudaStreamGraphFireAndForget);
break;
case deflate:
cudaGraphLaunch(deflateGraph, cudaStreamGraphFireAndForget);
break;
default:
break;
}
}
還需要注意的是,圖形啟動可以是嵌套的和遞歸的,因此可以從 fire 和 forget 啟動中調度其他設備圖形。雖然在本示例中未示出,但是正在解壓縮文件數據的圖形可以在數據完全解壓縮后分派更多的圖形來對該數據進行進一步處理(例如,圖像處理)。設備圖流是分層的,就像圖本身一樣。
尾部發射
CUDA 工作異步啟動到 GPU ,這意味著啟動線程必須明確等待工作完成,然后才能使用任何結果或輸出。這通常是使用諸如cudaStreamSynchronize或cudaStreamSynchronize的同步操作從 CPU 線程完成的。
GPU 上的啟動線程不可能通過cudaDeviceSynchronize等傳統方法同步設備圖形啟動。相反,當需要操作順序時,應使用尾部發射。
當一個圖被提交用于尾部發射時,它不會立即執行,而是在發射圖完成后執行。 CUDA 將所有動態生成的工作封裝為父圖的一部分,因此尾部啟動也將在執行之前等待所有生成的 fire 和 forget 工作。
無論尾部發射是在任何發射之前還是之后發出的,這都是正確的。尾部發射本身按照它們排隊的順序執行。一個特殊情況是自動重新啟動,其中當前運行的設備圖被排隊以通過尾部啟動重新啟動。一次只允許一次待定的自動重新啟動。
使用 tail launch ,您可以通過反復重新啟動前一個調度器內核,從而有效地在執行流中創建循環,從而將其升級為完整的調度器內核:
__global__ void schedulerKernel(
fileData *files,
int numFiles,
int *currentFile,
void **currentFileData,
cudaGraphExec_t zipGraph,
cudaGraphExec_t lzwGraph,
cudaGraphExec_t deflateGraph)
{
// Set the data ptr to the current file so the dispatched graph
// is operating on the correct file data
*currentFileData = files[currentFile].data;
switch (files[currentFile].comprType) {
case zip:
cudaGraphLaunch(zipGraph, cudaStreamGraphFireAndForget);
break;
case lzw:
cudaGraphLaunch(lzwGraph, cudaStreamGraphFireAndForget);
break;
case deflate:
cudaGraphLaunch(deflateGraph, cudaStreamGraphFireAndForget);
break;
default:
break;
}
// If we have not finished iterating over all the files, relaunch
if (*currentFile < numFiles) {
// Query the current graph handle so we can relaunch it
cudaGraphExec_t currentGraph = cudaGetCurrentGraphExec();
cudaGraphLaunch(currentGraph, cudaStreamGraphTailLaunch);
*currentFile++;
}
}
請注意,重新啟動操作如何使用cudaGetCurrentGraphExec檢索當前正在執行的圖形的句柄。它可以重新啟動自己,而不需要自己的可執行圖的句柄。
在自動重新啟動時使用尾部啟動具有額外的效果,即在下一次調度程序內核重新啟動開始之前同步(等待)調度的 fire 和 forget 工作。一個設備圖一次只能有一次待啟動(加上一次自動重新啟動)。為了重新啟動剛剛發送的圖形,您需要確保先前的啟動首先完成。執行自我重新啟動可以實現這一目標,這樣您就可以為下一次迭代調度所需的任何圖形。
設備與主機啟動性能的比較
此示例與主機啟動的圖形相比如何?圖 1 比較了各種拓撲的啟動延遲、尾部啟動延遲和主機啟動延遲。
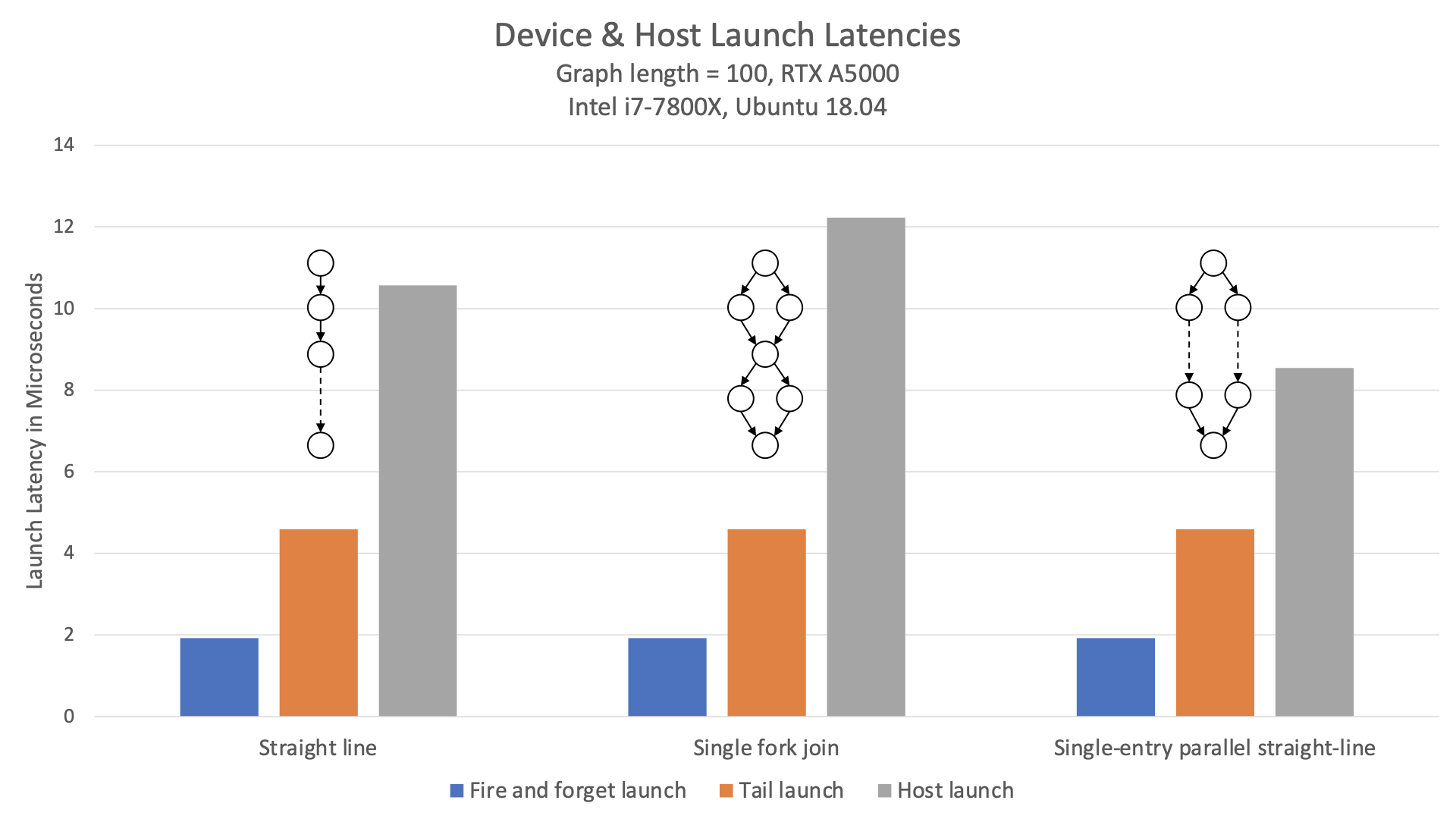
該圖表顯示,不僅設備端啟動延遲比主機啟動延遲低 2 倍以上,而且還不受圖形結構的影響。每個給定拓撲的延遲都是相同的。
如圖 2 所示,設備啟動也可以更好地擴展到圖形的寬度。
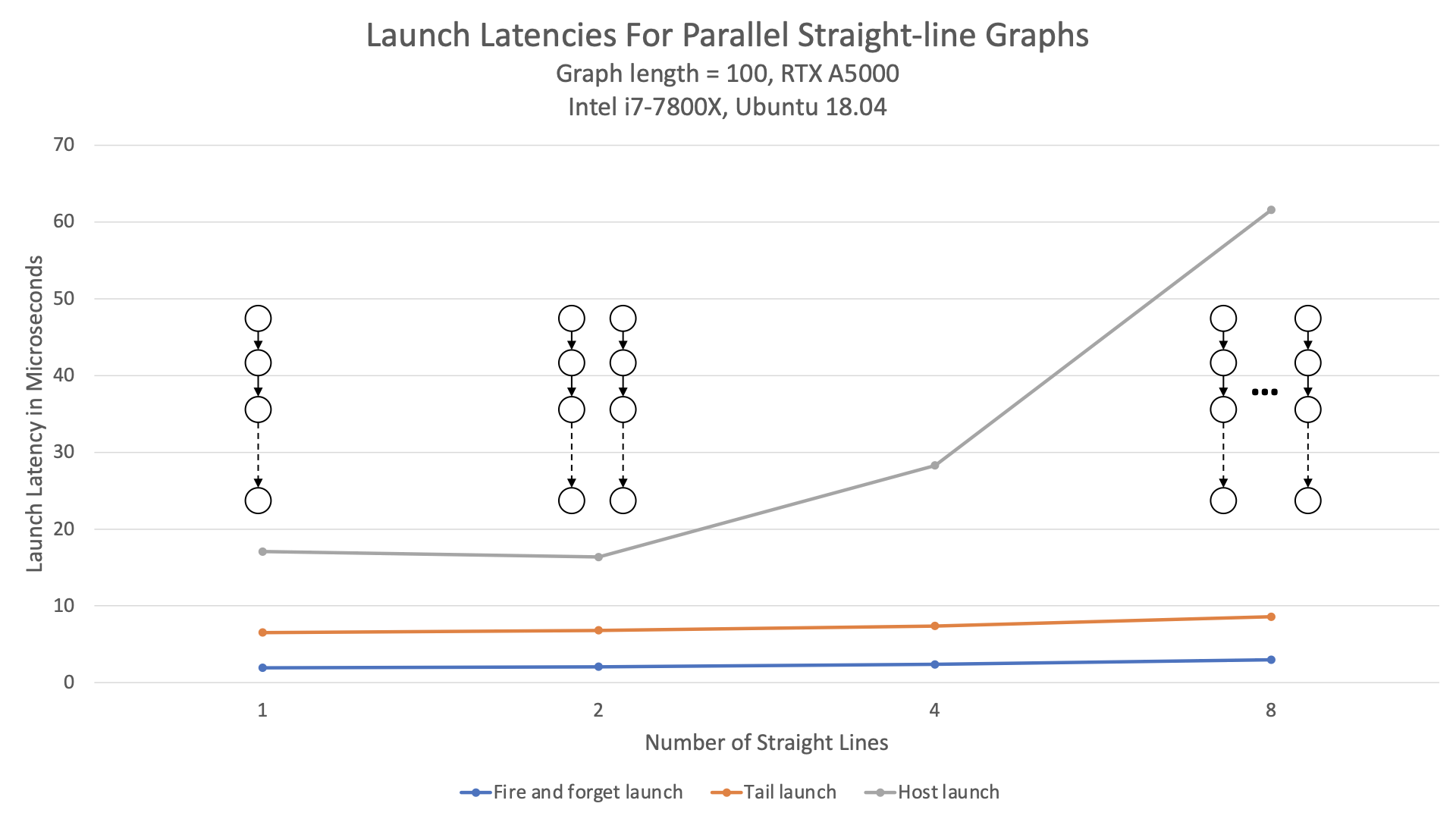
與主機啟動相比,無論圖表中的并行度如何,設備啟動延遲幾乎保持不變。
結論
CUDA 設備圖啟動提供了一種在 CUDA 內核內實現動態控制流的高效方式。雖然本文中給出的示例提供了一種開始使用該功能的方法,但它只是該功能使用方式的一個小表示。
有關更多文檔,請參閱編程指南的 device graph launch 部分。要嘗試設備圖形啟動, download CUDA Toolkit 12.0 。
?