量子電路模擬?是設計量子就緒算法的最佳方法,因此您可以在強大的量子計算機可用時立即利用它們。
NVIDIA cuQuantum 是一個 SDK ,它使您能夠利用不同的方式來執行量子電路模擬。 cuStateVec ,一個為狀態向量量子模擬器構建的高性能庫,依賴于在 GPU 存儲器中保存量子狀態向量。它的內存需求按 O ( 2 ^ N )進行縮放, N 表示量子位的數量。當你開始擴展到超過 40 個量子位時,這可能會非常昂貴。
為了減輕使用狀態向量方法的量子電路模擬的存儲器需求的指數縮放,可以使用張量網絡作為替代方案。你可以通過用增加的計算換取減少的空間來模擬更大的量子電路。
cuTensorNet 使您可以利用 NVIDIA GPU 上的張量網絡方法,與其他替代方案相比,提供了更高的可擴展性和更好的性能。盡管最近在加速張量收縮路徑發現方面取得了進展,但隨著電路尺寸在深度或寬度上的增加,精確張量網絡收縮的成本仍然會變得難以控制。
一種系統地保持張量網絡模擬所需資源可控制的策略是使用近似算法。本文詳細介紹了 cuTensorNet v2.0.0 中支持近似張量網絡模擬的新功能。
cuTensorNet 的進一步尺度近似張量網絡模擬
從 2.0.0 版開始, cuTensorNet 庫提供單個 GPU 計算原語,以加速近似張量網絡模擬。由于感興趣的量子問題在大小和復雜度上都會有很大的差異,研究人員開發了高度定制的近似張量網絡算法,以解決各種可能性。
為了實現與這些框架和庫的輕松集成, cuTensorNet 提供了一組 API 來涵蓋以下常見用例:
- 張量 QR
- 張量 SVD
- 閘門拆分
這些原語使您能夠加速和縮放不同類型的量子電路模擬器。利用這些方法模擬量子計算機的一種常見方法是矩陣積態( MPS ),也稱為 tensor train 。
分解
矩陣的 QR 分解可以通過將張量的多個維度合并為行維度,將其余維度合并為列維度,從而推廣到高維張量。生成的 Q 和 R 矩陣可以進一步展開為張量,從而將輸入張量有效地拆分為兩個操作數。
張量 QR
我們介紹了 cutensornet TensorQR ,這是一個 API ,主要用于移動近似張量網絡中的正交中心,包括 MPS 、投影糾纏對狀態( PEPS )等。
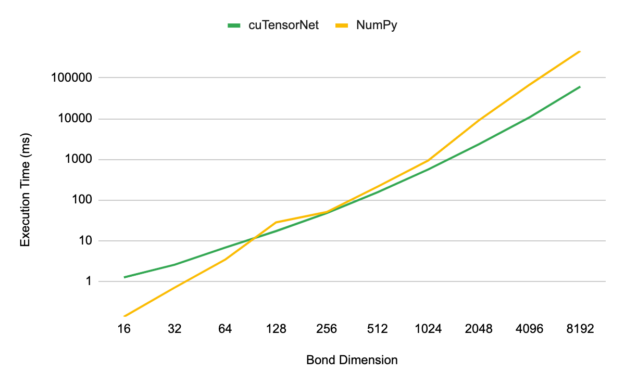
對于基準測試,我們使用 NVIDIA A100 80GB GPU 上的 QR ,檢查了分解第 3 級 MPS 張量的性能,形狀(D, 2, D),其中 D 表示 MPS 的鍵尺寸。對于 cuTensorNet 和基于 D 的等效( CPU )實現,分解的執行時間作為 D 的函數進行測量,以進行比較。所有 CPU 性能結果均使用相同的 EPYC 7742 CPU 完成,使用所有芯。
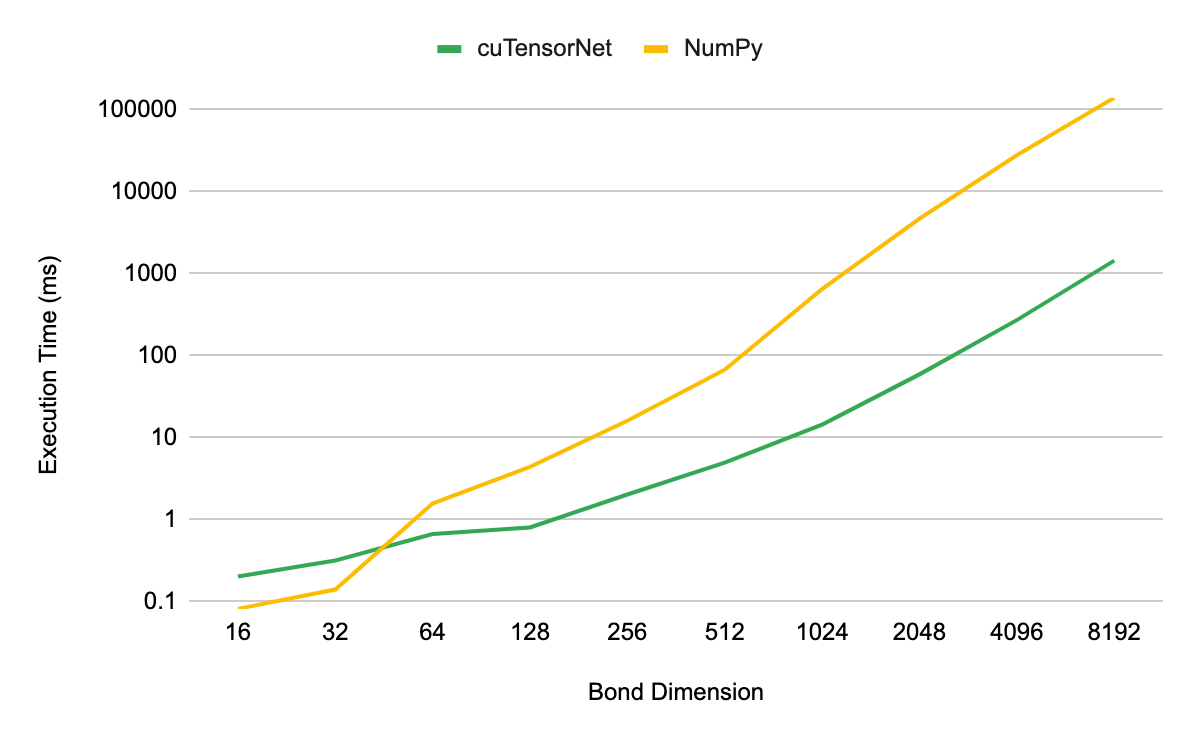
圖 1 顯示,當使用大于 32 的鍵維度時, cuTensorNet 比基于 CPU 的 NumPy 實現產生了數量級的加速。在 8192 的鍵維度上,您可以看到 CPU 實現的加速高達 96 倍。
張量 SVD
張量 SVD 的定義和用途與前面描述的張量 QR 相似。分解得到的奇異值包含有關量子系統的重要信息。例如,量子態的奇異值與基礎量子電路的馮·諾依曼糾纏熵直接相關。對于弱到中等糾纏的量子系統,可以截斷奇異值的尾部,以降低計算成本,同時保持模擬的高精度。
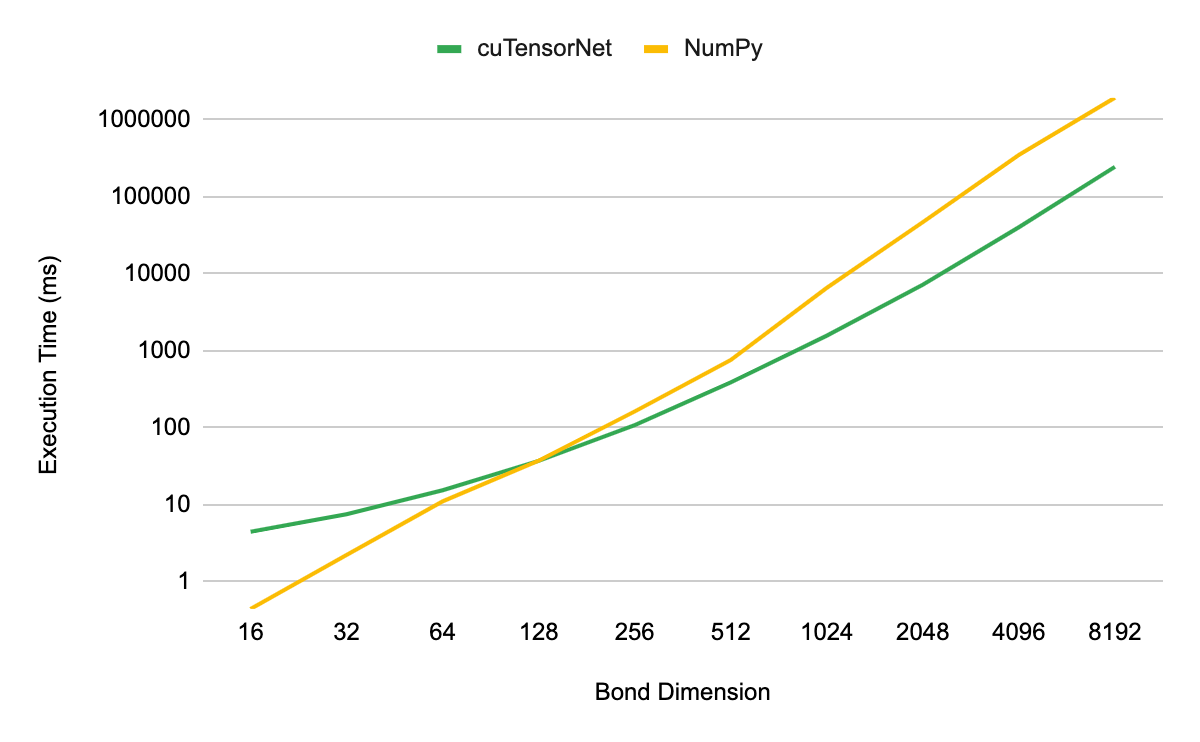
張量 SVD 性能的測量方法與張量 QR 相同。我們發現,當模擬維度大于 128 的鍵時, cuTensorNet 實現提供了性能優勢。當放大到 8192 維時,我們看到了 7.5 倍的加速。
將量子電路轉換為 MPS 表示
在量子電路模型中,當一個 2 量子比特的門操作數應用于一對連接的張量時,你可以執行一系列操作,將門吸收到兩個連接的張量上,同時保持固定的拓撲結構。
這種類型的操作形成了構建量子電路的 MPS 或 PEPS 表示的基礎。在執行張量 SVD 時,可以將截斷作為過程的一部分,以保持計算成本可控制。例如,通過在所有 2 量子比特門上迭代使用該技術,可以實現量子電路的近似 MPS 模擬(圖 3 )。
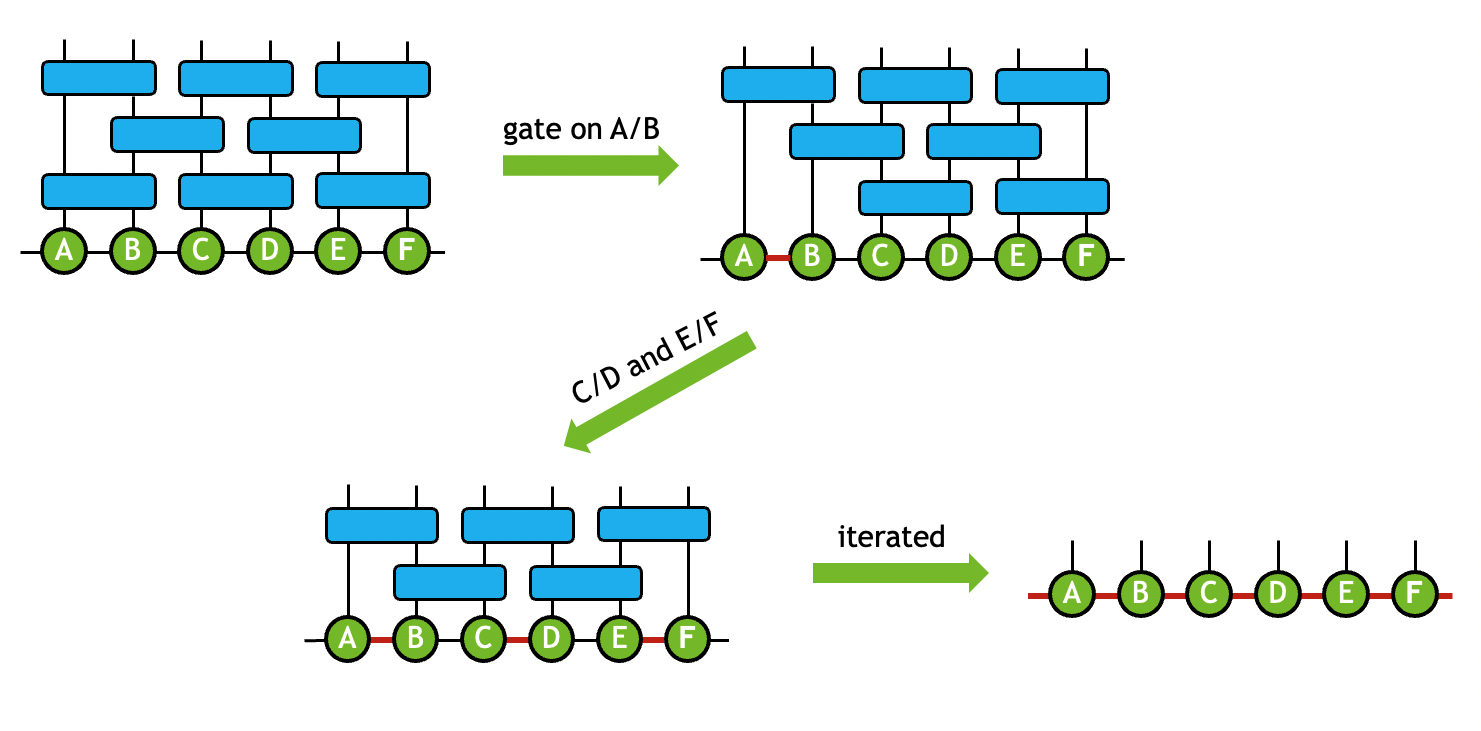
張量網絡可以通過門分裂函數將 2 量子比特門吸收到連接的張量上來簡化。通過迭代這個過程,生成 MPS ,然后可以收縮 MPS 以模擬量子電路。 這降低了網絡連接的復雜性,是 MPS 量子電路仿真的價值基石。您可以利用截斷張量 SVD 進一步降低網絡大小和計算成本。在多次迭代這個過程之后,您將得到一個 MPS ,它可以收縮以模擬量子電路操作。
閘門分裂
使用 cuTensorNet 使用近似張量網絡方法實現量子電路模擬所需的最后一個組件是 2.0.0 版中引入的 gate split 功能。該團隊提供了一些示例,展示了如何在 cuQuantum GitHub repo 中最好地單獨使用這些組件,此外還有一個 具體樣本?,它使用這些組件來實現 MPS 量子模擬。
該函數的性能通過檢查構建最終 MPS 的最后一個也是成本最高的步驟的執行時間作為結合維度的函數來測試。當超出 128 的鍵尺寸時,您可以開始看到利用 GPU 進行 MPS 模擬的優勢。
在 8192 的鍵合維度下,與同一數據中心級別 CPU 上的標準 NumPy 實現相比, NVIDIA A100 80GB GPU 上的 cuTensorNet 的加速約為 7.8 倍。
開始使用 cuTensorNet 進行量子模擬
cuTensorNet v2.0.0 現已推出。您可以通過 conda-forge 、 pip 或 cuQuantum installers 訪問它。要快速開始新功能,請參見 Approximation Setting: SVD Options 。有關詳細指南,請參閱 code samples 。要請求功能或報告錯誤,請聯系 GitHub 上的 NVIDIA/cuQuantum 。
有關詳細信息,請參閱以下內容 量子計算資源:
- Introduction to Approximate Tensor Network Operations
- Best-in-class Quantum Circuit Simulation at Scale with NVIDIA cuQuantum
- NVIDIA cuQuantum and QODA Adoption Accelerates
- NVIDIA GTC ’23 Quantum Computing Sessions
?