這篇文章是 optimizing end-to-end AI 系列文章的第四篇。 有關更多信息,請參閱以下帖子:
- End-to-End AI for NVIDIA-Based PCs: An Introduction to Optimization
- End-to-End AI for NVIDIA-Based PCs: Transitioning AI Models with ONNX
- End-to-End AI for NVIDIA-Based PCs: ONNX Runtime and Optimization
正如在 End-to-End AI for NVIDIA-Based PCs 系列的上一篇文章中所解釋的, ONNX Runtime 中有多個執行提供程序( EP ),它們支持針對給定部署場景使用特定于硬件的功能或優化。本文介紹了 CUDA EP 和 TensorRT EP ,它們使用了高度優化的 NVIDIA 推理庫和各自的硬件功能,如 Tensor Core 。
除了 NVIDIA 硬件上的最佳性能外,這還允許在多個操作系統甚至數據中心、 PC 和嵌入式( NVIDIA Jetson )硬件上使用相同的 EP 。由于這些 EP 是特定于 NVIDIA 的,因此這是獲得 FP8 精度或 NVIDIA Ada Lovelace architecture 中的 transformer 引擎等新硬件功能的最快途徑。
CUDA EP 和 TensorRT EP 之間的區別?
您可能會問,為什么 ONNX Runtime 中甚至有兩個 NVIDIA EP ?雖然它們都使用相同的后端( CUDA )與 GPU 驅動程序通信,但它們有不同的方式來構建和執行 ONNX 圖。
CUDA 步驟
CUDA EP 使用 cuDNN inference library ,其基于神經網絡的粒度操作塊。這樣的構建塊可以類似于卷積或融合算子;例如卷積+激活+歸一化。
使用融合運算符的好處是減少了全局內存流量,這通常是激活函數等廉價操作的瓶頸。這樣的操作塊可以通過窮舉搜索或根據 GPU 選擇內核的啟發式來選擇。
窮舉搜索僅在部署設備上的第一次推斷期間進行,因此使得第一次推斷比以下推斷慢。這導致始終對特定塊使用性能最高的實現。
TensorRT 步驟
TensorRT EP 也可熔斷此類操作塊。同時,它評估整個圖形并收集所有可能的路徑以執行圖形。
通過優化整個圖和可能的重新排序操作,優化的潛力更大。然后對評估的可能執行路徑進行分析,并選擇性能最佳的執行路徑,并將其保存為所謂的引擎。
這些引擎不僅表示圖形的操作列表,還表示其權重和執行所需的所有信息。對于大型 ONNX 模型,在這樣的圖形級別上進行優化和分析可能需要幾分鐘的時間。徹底的 cuDNN 搜索只評估小的網絡構建塊,使其搜索速度更快。
cuDNN 只評估自己的內核,而 NVIDIA TensorRT 策略跨越包括 cuDNN 在內的多個庫。另一個重要因素是 TensorRT 可以為網絡內部的中間緩沖區分配的工作空間內存。
當涉及到執行時, TensorRT 通常可以提供更快的執行,因為它保證為整個圖而不僅僅是子部分選擇最佳執行路徑。這顯然是以這樣高的引擎創建時間為代價的,因此需要考慮一些部署問題。
在 TensorRT 8.5 及更高版本中, cuDNN 和 cuBLAS 內核是可選的添加,以減少 TensorRT 庫的部署大小。目前, ONNX Runtime 使用 TensorRT 8.4 ,沒有公開的選項來啟用或禁用特定庫。
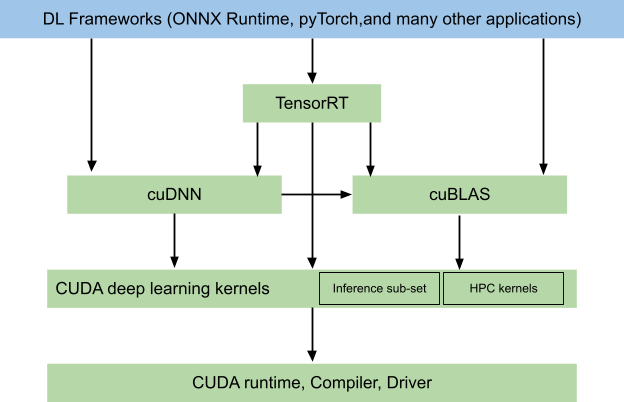
部署注意事項
為了部署 CUDA EP ,您只需提供相應的庫和 ONNX 文件。為了在設置時間和推理性能之間進行權衡,您可以使用 cudnn_conv_algo_search 屬性在啟發式和窮舉內核搜索之間進行選擇。
對于 TensorRT EP ,有更多的考慮因素。不僅要傳送 ONNX 文件,而且要傳送為該 ONNX 生成的引擎,以省略在用戶硬件上構建模型。
由于構建過程需要時間,用戶構建不應該在第一次推斷時進行,而是應該在應用程序安裝期間或在應用程序第一次啟動時使用相應的提示進行。
為了緩存生成的引擎以供以后使用,以下設置尤為重要。請注意,這樣生成的引擎不僅特定于 ONNX 文件,還特定于 GPU 體系結構(計算能力)。
trt_options.trt_engine_cache_enable = 1; trt_options.trt_engine_cache_path = "/path/to/cache"
幸運的是,這兩個提供程序都基于 CUDA ,并且非常可互換,正如您在本文提供的示例應用程序中看到的那樣。稍后可以很容易地更改決定。
示例應用程序
本文提供的示例應用程序可以在 NVIDIA/ProViz-AI-Samples GitHub repo 上找到。它演示了一個具有 AI 超分辨率模型的簡單照片處理管道。它沒有用戶界面。相反,它是處理圖像文件夾的命令行專用工具。
除了運行推理之外,它還演示了如何將預處理和后處理集成到這樣的管道中。樣本中的預處理和后處理很簡單,但可以通過其他 CUDA 加速庫(如 NPP 、 CV-CUDA 或 OpenCV )輕松擴展。在本例中,它是從 NCHW 到 NHWC 的數據格式轉換,作為自定義 CUDA 內核。
該示例的關鍵方面是使用單獨的流將數據復制到 GPU 和從 GPU 復制數據,并進行處理。由于 GPU 能夠同時通過 PCI 總線復制數據以進行計算,這將隱藏引入的復制延遲,并使您能夠在 GPU 忙時加載下一個圖像。
對于連續圖像,只有第一個圖像具有上載延遲,只有最后一個圖像具有下載延遲。其余部分通過管道隱藏(圖 2 )。我們為應用程序添加了 NVTX 范圍,以便于性能分析。
當前,如果未事先編譯 feature branch ,則 ONNX Runtime 無法顯示 CUDA 工作的異步執行。示例中的 README 解釋了如何使用自定義二進制文件而不是預編譯的二進制文件。
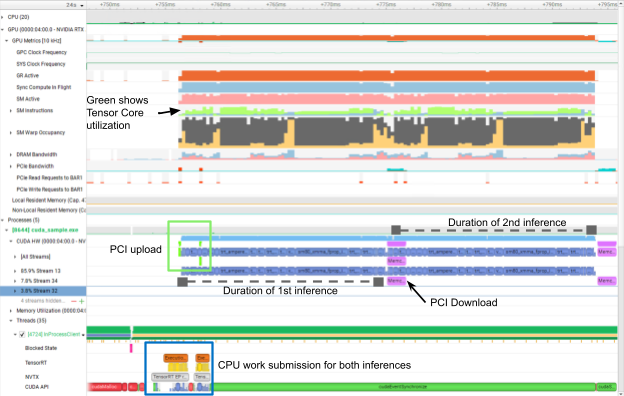
在圖 2 中,第二次 PCI 上傳和第一次 PCI 下載隱藏在 CUDA 內核執行之后(藍色)。這樣,兩個推論之間就沒有差距了。此外,您可以在 CPU 部分看到用兩個 NVTX 范圍標注的 CPU 占用的時間有多少,從而為其他工作釋放了資源。
以下是需要強調的其他幾個設置決策:
- CUDA 圖
- TensorRT 工作空間大小
- NHWC 格式
- FP16 和 FP8
CUDA 圖
CUDA 圖減少了網絡內所有內核的 CPU 啟動開銷。雖然第一次發布有捕獲 CUDA 圖的開銷,但所有以下推論都從中受益。
性能增益的大小在很大程度上取決于所使用的網絡。對于正在處理多幀的視頻處理工作負載,值得嘗試 CUDA 圖。
雖然在兩個 EP 上通常都可以使用 CUDA 圖,但它僅在 CUDA 到enable_cuda_graph上作為本地會話創建參數公開。
TensorRT 工作空間大小
TensorRT 工作空間大小是一個經常不清楚的參數,但卻是 TensorRT 的一個重要參數。由于 TensorRT 可以重新排列圖形中的操作以進行優化,因此可能需要更多內存來存儲中間結果。
該值由工作空間大小控制,告訴引擎構建器除了引擎重量和輸入之外, TensorRT 還可以分配多少字節。用這個參數進行實驗并用推理大小來權衡速度是有意義的。
類似的參數可用于 CUDA EP cudnn_conv_use_max_workspace but serves a ,含義略有不同,因為這僅涉及卷積張量上的中間緩沖區或填充,而不是新的中間緩沖。
NHWC 格式
NHWC 格式的輸入非常適合 NVIDIA 上的 Tensor Core GPU 。由于 ONNX 僅支持 NCHW 格式,因此必須使用技巧啟用 NHWC 作為輸入張量。將輸入維度設置為 NHWC ,并在 CUDA 或 TensorRT EP 刪除的輸入之后插入 Transpose 操作(圖 3 )。
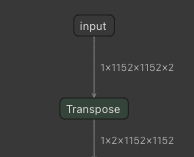
在圖 3 中,將 NHWC 的 Transpose 層添加到 NCHW 可以將 NHWC 張量作為輸入,盡管 ONNX 僅支持 NCHW 。
FP16 和 FP8
FP16 和 FP8 等操作精度對于 GPU 上的最佳性能尤為重要。在 TensorRT EP 中,必須在會話創建期間使用以下屬性顯式啟用它們:
OrtTensorRTProviderOptions trt_options{};
trt_options.trt_fp16_enable = 1;
trt_options.trt_int8_enable = 1;
有關詳細信息,請參見 ONNX Runtime Performance Tuning 。
結論
閱讀本文后,您應該了解如何使用 NVIDIA 后端通過 ONNX Runtime 高效部署 ONNX 模型。這篇文章為如何圍繞這一點構建最佳管道提供了指導。
雖然示例沒有顯示 TensorRT 的實際部署,但它可以保存生成的引擎以供以后使用。如圖所示,您可以模板化整個管道以快速交換 TensorRT 和 CUDA EP 。
如果您對這些主題有任何進一步的問題,請訪問 NVIDIA 開發者論壇或加入 NVIDIA Developer Discord 。對于示例代碼中的錯誤或問題,請在 NVIDIA/ProViz-AI-Samples 上提交 GitHub 問題。
要閱讀本系列的第一篇文章,請參閱 End-to-End AI for NVIDIA-Based PCs: An Introduction to Optimization 。
有關更多信息和訪問 NVIDIA 技術,請參閱 NVIDIA AI for Accelerating Creative Applications 。
?