這篇文章是關于 優化端到人工智能?的系列文章中的第五篇。
NVIDIA TensorRT 是一種在 NVIDIA 硬件上部署光速推理的解決方案。有了人工智能模型架構, TensorRT 可以在部署前使用,以過度搜索最有效的執行策略。
TensorRT 優化包括重新排序圖中的操作,優化權重的內存布局,以及將操作融合到單個內核以減少 VRAM 的內存流量。要應用這些優化, TensorRT 必須具有完整的網絡定義及其權重。
評估的策略在 TensorRT 引擎中序列化,該引擎與應用程序一起提供,以在生產中實現最佳推理性能。在部署過程中,除了這個引擎之外,不需要其他任何東西來執行網絡。
包含已編譯的內核和對文件的序列化使該引擎僅與相同 計算能力?的 GPU 兼容。該文件也特定于 TensorRT 版本,但將與 8.6 之后的未來版本兼容。
生成性能良好且正確的發動機
網絡圖定義及其權重可以從 ONNX 文件中解析,也可以使用 NetworkDefinition API 手動構建網絡。手動構建圖形提供了對 TensorRT 最細粒度的訪問,但也需要付出最大的努力。
在給定 ONNX 文件上評估 TensorRT 的一種快速方法是使用 trtexec 。該工具還可以用于生成引擎文件,該文件可以稍后通過--saveEngine選項與 Python 或 C ++ API 一起部署。運行以下命令以創建引擎:
trtexec –onnx="model.onnx" –saveEngine="engine.trt"
當您通過 ONNX Runtime 使用trtexec時,只會暴露 TensorRT 或 TensorRT API 提供的一些 TensorRT 本機構建功能。有關通過 ONNX Runtime 的 TensorRT 的更多信息,請參閱 TensorRT Execution Provider 。
在這篇文章中,我簡要討論了使用trtexec從 ONNX 文件中獲取高性能引擎所需的內容。大多數命令行選項可以很容易地轉換為 TensorRT C ++/ Python API 函數。
為了研究 TensorRT 的性能、精度或兼容性,有用的工具包括 polygraph 或 trex 。如果圖中的操作不是 supported by TensorRT ,則可以 write plugins 來支持引擎中的自定義操作。
在執行自定義運算符之前,請評估該操作是否可以通過其他 ONNX 運算符的組合來實現。
精確
TensorRT 性能與各自的操作精度 INT8 或 FP16 和 FP32 高度相關。
將trtexec與 ONNX 文件一起使用時,當前沒有使用 ONNX 中指定精度的選項。但是,您可以啟用 TensorRT 來將權重轉換為相應的精度,并評估推理成本。使用--fp16或--int8。較低的精度通常會導致更快的執行,因此這些權重更有可能在生成的引擎中選擇。
降低數值精度可能會影響模型質量,因此可以使用--layerPrecisions選項手動標記要以更高精度執行的特定圖層。為了通過使用張量核心獲得最佳性能,重要的是要有 tensor alignment ,例如 FP16 的八個元素。這不僅適用于 TensorRT ,而且適用于 ONNX optimization 。
當型號需要 FP32 精度時,默認情況下, TensorRT 仍在 NVIDIA Ampere 架構及更高版本上啟用 TF32 ,但可以使用--noTF32禁用。當使用 TF32 時,卷積的被乘數被四舍五入到最接近的 FP16 當量。保留了 FP32 的指數,因此也保留了其動態范圍。在這些乘法運算之后,使用 FP32 對卷積乘法運算的結果求和。有關更多信息,請參閱 TensorFloat-32 in the A100 GPU Accelerates AI Training, HPC up to 20x 。
輸入格式
結合使用的精度,使用--inputIOFormats和--outputIOFormats更改 I / O 緩沖區類型也很有用。
由于張量核心需要 HWC 布局,如果可能的話,在該布局中攝取數據可能是有益的。這樣, TensorRT 就不必進行內部轉換,尤其是在 FP16 中已經存在數據的情況下。如果 HWC 和 FP16 中有數據,請運行以下命令進行編譯:
--inputIOFormats=fp16:hwc --outputIOFormats=fp16:hwc
CHW 和 HWC 也支持所有其他精度。
工作區大小
正如我前面提到的, TensorRT 有不同的策略來執行圖中的操作。例如,通過加載完整內核,可以在沒有中間緩沖區的情況下執行 2D 卷積。
對于大內核,在兩次 1D 卷積過程中執行卷積是有意義的,需要中間緩沖區。使用trtexec中的– memPoolSize 參數來指定 TensorRT 可以超額分配的最大 VRAM 數量。例如,–-memPoolSize=workspace:100將中間緩沖區的大小限制為 100 MB 。用這個值進行實驗可以幫助您在推理延遲和 VRAM 使用之間找到平衡。
有關優化 TensorRT 推理成本的更多信息,請參閱 Optimizing TensorRT Performance .
部署目標
在找到使用 TensorRT 為網絡提供服務的理想方式后,歸根結底是如何部署該模型。
為此,確定必須滿足的需求并比較策略是很重要的。這些都會隨著部署目標的變化而發生重大變化:服務器、嵌入式或工作站。
對于服務器和嵌入式部署場景,硬件種類通常是有限的,這使得將專用引擎與二進制一起運送成為一個有吸引力的解決方案。
本系列文章的重點是工作站部署,必須考慮各種各樣的系統。在開發過程中,最終用戶工作站是完全未知的,這使得它成為最困難的部署場景。
TensorRT 在工作站上面臨的挑戰有兩方面。
首先,根據人工智能模型的復雜性,在用戶設備上編譯引擎可能是一個漫長的過程(從幾秒鐘到幾分鐘),例如,這可能隱藏在安裝程序中。理想情況下, GPU 應在發動機生成期間處于怠速狀態,因為推斷是在[Z1K1’上計時的,并且選擇了性能最佳的。在 GPU 上運行任何其他任務同時會扭曲時序并導致次優執行策略。
其次, TensorRT 引擎特定于特定的計算能力(例如,對于 NVIDIA Ampere 和 NVIDIA Ada Lovelace 架構)。對于單個模型,您需要運送多個預編譯的引擎來支持多個 GPU 。當您試圖從 GPU 中擠出最佳推理性能時,您必須為每個 GPU SKU (例如 4080 、 4070 和 4060 )提供一個引擎,而不是為整個計算能力提供一個。運送許多相同型號的發動機是違反直覺的。這通常是不可行的,因為每個發動機都已經擁有了所有需要的重量,而且這只會使二進制裝運量增加。
基于這些挑戰,有兩種解決方案最適合工作站:
- 裝運預制發動機
- 運送預先填充的定時緩存
對于這兩種方法,在部署之前必須在所有受支持的 GPU 體系結構上編譯引擎。
請注意,這些解決方案不僅僅是第一次部署時的考慮因素,因為工作站硬件可能會發生變化。如果您決定將 GPU 升級到最新一代,則必須生成一個新的引擎。
裝運預制發動機
運送預構建的引擎對于服務器或嵌入式設備特別有用,通常是最好的解決方案。在這些場景中,硬件是已知的,并且可以將適合該硬件的引擎包含在部署二進制文件中。
對于工作站來說,運送所有所需的發動機通常是不可行的。必須在安裝期間或請求特定功能時執行下載。
對于此下載,您必須查詢 GPU 的計算能力并下載相應的引擎。在這種情況下,除了共享庫之外, TensorRT AI 部署根本不會影響應用程序的交付規模。例如, ONNX 文件形式的原始權重和網絡定義不必發貨。
通常, TensorRT 引擎比其對應的 ONNX 文件小得多。這樣做的明顯缺點是無法進行離線安裝。如今,這不一定是個大問題。
| Name | Engine size (MB) |
| RoBERTa | 475 |
| Fast Neural Style Transfer | 3 |
| sub-pixel CNN | 0 |
| YoloV4 | 125 |
| EfficientNet-Lite4 | 25 |
運送預先填充的定時緩存
首先,我想解釋什么是定時緩存,以及如何獲取定時緩存。
在構建引擎時,可以評估評估的執行計劃的推斷時間。可以通過trtexec的--timingCacheFile選項將此計時的結果保存到計時緩存中,以便以后重用。
定時緩存不必是特定于型號的。事實上,我建議對所有 TensorRT 構建過程使用系統范圍的定時緩存。每當需要內核定時時,進程都會檢查定時緩存,并跳過定時或擴展定時緩存。這大大縮短了發動機的制造時間!
定時緩存通常只有幾 MB 大,甚至不到 1MB 。這使得在應用程序的初始二進制文件中包含多個緩存成為可能,并大大減少了構建時間。
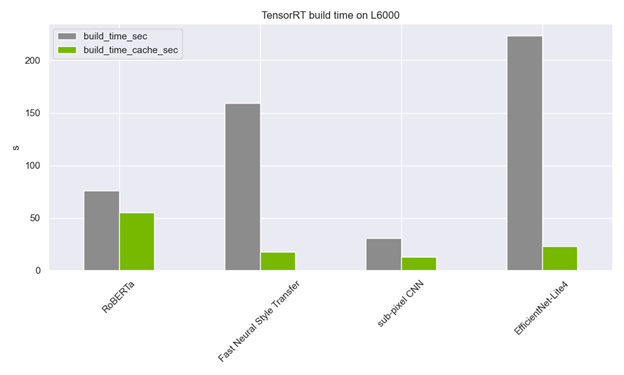
仍然需要在多個計算功能上預編譯所有引擎以填充緩存。但是,對于裝運,只需要一個小的附加文件。
與引擎一樣,理想的情況是每一個 GPU 都有一個緩存,但也可以在整個計算能力中進行 ignore those mismatches 部署。有了這個文件,在用戶端構建引擎是一個僅限 CPU 的操作,可以在安裝期間完成,而不用擔心定時期間會出現繁忙的 GPU 。使用這種運送定時緩存和 ONNX 模型的方法,可以在用戶設備上實現可控的引擎構建過程,而無需按需下載文件。
使用新的啟發式算法選擇(--heuristic標志)可以進一步加速。它目前只修剪了不太可能是最快的卷積策略,但它將在未來的版本中擴展到其他操作。
結論
這篇文章展示了在不運送大量二進制文件的情況下將 TensorRT 引擎部署到工作站的選項。這些選項還可以避免在繁忙的情況下讓您經歷耗時且可能不正確的構建過程 GPU 。
本文中提到的所有trtexec選項都可以在trtexec的 開源代碼?中找到,也可以在 C ++或 Python API 文檔中搜索相應的功能。
閱讀后,您應該能夠決定哪種方法是應用程序的最佳部署選擇,并在二進制大小和用戶設備上的計算時間之間找到平衡。請注意,在多個模型上混合使用策略也是一種選擇。
對于常用的模型,您可能希望在安裝程序中使用定時緩存對其進行編譯。對于并非所有用戶都需要的其他型號,請按需下載相應的 ONNX 或 TensorRT 引擎。
在我們的論壇 AI & Data Science 中了解有關 TensorRT 部署的更多信息。
從 3 月 21 日至 23 日免費參加 GTC 2023 ,并觀看我們的 AI for Creative Applications 課程。
?