人工智能模型的性能在很大程度上受到所使用計算資源的精度的影響。較低的精度可以提高處理速度和減少內存使用,而較高的精度可以獲得更準確的結果。在精度和性能之間找到正確的平衡對于優化人工智能應用程序至關重要。
NVIDIA GPU 配備了 Tensor Core 等專用硬件,已成為加速人工智能工作負載的關鍵組件。為了充分利用它們的功能,重要的是要滿足某些限制,并基于特定的人工智能應用程序優化硬件。
在這篇文章中,我們討論了如何通過從 FP32 (單精度浮點格式)轉換到 FP16 (半精度浮點數格式)來優化 AI 的 GPU 。我們介紹了使用 FP16 的優勢、轉換模型的方法,以及這種轉換對人工智能應用程序的質量和性能的影響。
初始性能:一個簡單的未優化模

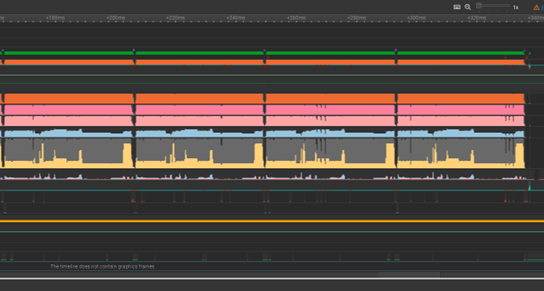
從 ONNX 格式的簡單未優化模型開始。 Nsight Systems 的配置文件顯示,四次運行的執行時間為 173 毫秒。盡管這可能看起來很快,但這是針對單個圖像的。想象一下,如果你像攝影師經常要做的那樣,大量處理 500 張圖像,這幾乎需要一分鐘半的時間。
從 FP32 過渡到 FP16
目前,該模型采用 FP32 精度,每個浮點值使用 32 位。這可能比必要的更精確。通過轉換到 FP16 ,您可以啟用張量內核并提高浮點吞吐量。
Python ONNX 模塊提供兩種解決方案:Float_to_float16以及自動混合精度。
Float_to_float16 方法
位于onnxconverter_common這個Float_to_float16方法可以將模型中的所有浮點值轉換為 FP16 。
import onnxfrom onnxconverter_common.float16 import convert_float_to_float16model_FP32 = onnx.load("model.onnx")model_FP16 = convert_float_to_float16(copy.deepcopy(model_FP32))onnx.save(model_FP16, "model_FP16.onnx") |
如果原始模型中的重量超過 FP16 的動態范圍,則會出現溢出。
自動混合精度方法
任何不需要的行為都可以通過使用自動混合精度方法來克服。也可在中找到onnxconverter_common,此方法采用混合精度轉換。該方法只轉換 FP16 不影響輸出的層,并且需要測試數據和可選的驗證方法。
import onnximport numpy as npfrom onnxconverter_common.auto_mixed_precision import auto_convert_mixed_precision# Could also use rtol/atol attributes directly instead of thisdef validate(res1, res2): for r1, r2 in zip(res1, res2): if not np.allclose(r1, r2, rtol=0.01, atol=0.001): return False return Truemodel_FP32 = onnx.load("model.onnx")feed_dict = {"input": 2*np.random.rand(1, 3, 128, 128).astype(np.float32)-1.0}model_amp = auto_convert_mixed_precision(model_FP32, feed_dict, validate)onnx.save(model_amp, "model_amp.onnx") |
FP16 提高了性能
在使用第一種轉換方法后,該模型現在只需 42 毫秒即可運行,比以前快了 4 倍。對于 500 張圖像,這將花費從接近 90 秒到僅 21 秒的時間。
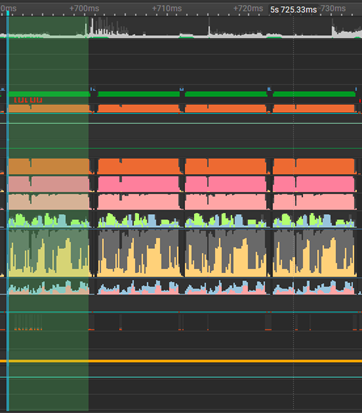
質量比較: FP32 與 FP16
擔心精度降低會導致質量下降?從并排圖像比較中可以看出(圖 4 ), FP32 和 FP16 模型輸出的去噪圖像是相同的。盡管使用了較低精度的方法,但它們之間沒有明顯的視覺差異。

結論
通過只需幾行額外的代碼轉換到 FP16 ,我們實現了 4 倍的加速。這啟用了 Tensor 內核,提高了數據吞吐量,同時減少了視頻內存的使用。
準備好優化你的人工智能了嗎?有關詳細信息,請參閱NVIDIA/ProViz-AI-SamplesGitHub 回購并親自嘗試。如果您有任何問題,請聯系數據處理開發者論壇。
?